
Kaggle第一人!详细解读2021 Google地标识别第一名解决方案
共 8728字,需浏览 18分钟
·
2021-11-05 16:28

本文提出了一个有效的端到端大规模地标识别和检索的网络架构。作者展示了如何结合和改进最近在图像检索研究中的概念,并介绍了一种基于EfficientNet和新型Hybrid-Swin-Transformer的局部和全局特征深度正交融合(DOLG)模型,然后详细介绍了如何使用 Step-wise 方法和Sub-Center Arcface with dynamic margin Loss有效地训练这2种架构。此外,作者阐述了一种新的图像识别重排序方法检索。
1简介
谷歌Landmark Dataset v2 (GLDv2)已经成为一个流行的数据集,用于评估用于解决大规模实例级识别任务的架构和方法的性能。原始数据集由超过500万张图片和超过20万个类组成。数据集还提出了一些有趣的挑战,如类的长尾分布、类内变动性和噪声标签。
2019年的获奖方案带来了GLDv2的清洁版本,这是一个子集,包含150万张图像,包含81313个类,将在下面用GLDv2c表示。此外,GLDv2x将用于表示GLDv2的子集,该子集被限制为GLDv2c中存在但未被清除的81313个类。
对于识别,是关于对一组测试图像中的地标进行正确分类,其中有大量的非地标被用作噪声数据。采用全局平均精度(GAP)作为度量指标进行评价。
对于检索,任务是在数据库中找到与给定查询图像相关的类似图像,并使用mean Average Precision@100 (mAP)进行评估。
2本文方法
2.1 DOLG模型
DOLG是一种用于端到端图像检索的信息融合框架(正交Local and Global, DOLG)。该算法首先利用多尺度卷积和自注意力方法集中提取具有代表性的局部信息。然后从局部信息中提取与全局图像表示正交的分量。最后,将正交分量与全局表示法进行互补连接,然后进行聚合生成最终的表征。
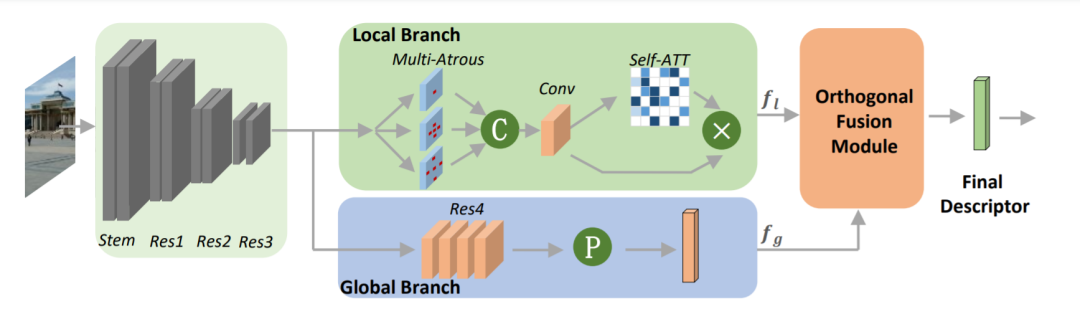
基于ResNet50的DOLG模型的Pytorch实现如下:
class DolgNet(LightningModule):
def __init__(self, input_dim, hidden_dim, output_dim, num_of_classes):
super().__init__()
self.cnn = timm.create_model(
'resnet101',
pretrained=True,
features_only=True,
in_chans=input_dim,
out_indices=(2, 3)
)
self.orthogonal_fusion = OrthogonalFusion()
self.local_branch = DolgLocalBranch(512, hidden_dim)
self.gap = nn.AdaptiveAvgPool2d(1)
self.gem_pool = GeM()
self.fc_1 = nn.Linear(1024, hidden_dim)
self.fc_2 = nn.Linear(int(2*hidden_dim), output_dim)
self.criterion = ArcFace(
in_features=output_dim,
out_features=num_of_classes,
scale_factor=30,
margin=0.15,
criterion=nn.CrossEntropyLoss()
)
def forward(self, x):
output = self.cnn(x)
local_feat = self.local_branch(output[0]) # ,hidden_channel,16,16
global_feat = self.fc_1(self.gem_pool(output[1]).squeeze()) # ,1024
feat = self.orthogonal_fusion(local_feat, global_feat)
feat = self.gap(feat).squeeze()
feat = self.fc_2(feat)
return feat
1、Local Branch
Local Branch的2个主要构建模块是Multi-Atrous卷积层和Self-Attention模块。前者是模拟特征金字塔,可以处理不同图像实例之间的比例变化,后者是利用注意力机制进行建模。这个分支的详细网络配置如图2所示。
Multi-Atrous卷积模块包含3个空洞卷积,以获取具有不同空间感受野的特征映射和一个全局平均池化分支。 将Multi-Atrous卷积输出特征cat起来,然后经过1x1卷积层处理。 将输出的特征传递给Self-Att模块建模每个局部特征点的重要性。 首先使用CNN(1x1)-BN模块对其输入进行处理 然后通过1x1卷积层生成的注意力映射 再通过SoftPlus操作以及L2-Norm对后续特征进行归一化
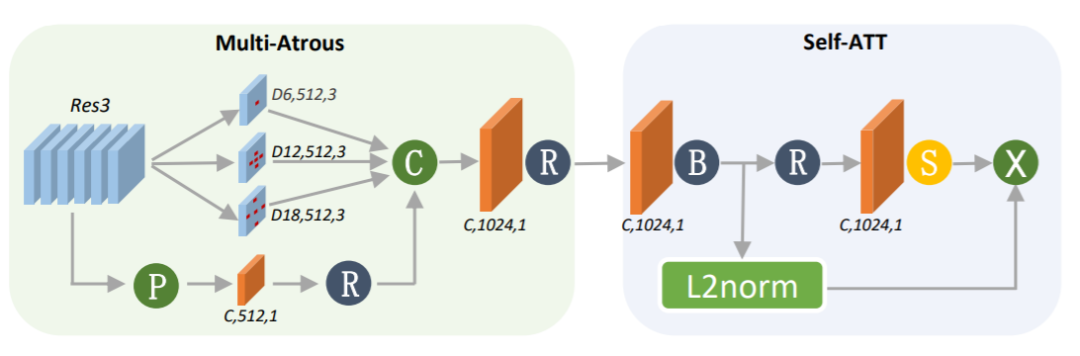
Local Branch的配置。“Ds, c, k”表示空洞率为s,输出通道数为c,kernel-size为k的空洞卷积。“c, c, k”表示输入通道为c,输出通道为c,kernel-size为1的普通卷积。“R”、“B”和“S”分别代表ReLU、BN和Softplus。
Local Branch的Pytorch实现
class MultiAtrous(nn.Module):
def __init__(self, in_channel, out_channel, size, dilation_rates=[3, 6, 9]):
super().__init__()
self.dilated_convs = [
nn.Conv2d(in_channel, int(out_channel/4),
kernel_size=3, dilation=rate, padding=rate)
for rate in dilation_rates
]
self.gap_branch = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_channel, int(out_channel/4), kernel_size=1),
nn.ReLU(),
nn.Upsample(size=(size, size), mode='bilinear')
)
self.dilated_convs.append(self.gap_branch)
self.dilated_convs = nn.ModuleList(self.dilated_convs)
def forward(self, x):
local_feat = []
for dilated_conv in self.dilated_convs:
local_feat.append(dilated_conv(x))
local_feat = torch.cat(local_feat, dim=1)
return local_feat
class DolgLocalBranch(nn.Module):
def __init__(self, in_channel, out_channel, hidden_channel=2048):
super().__init__()
self.multi_atrous = MultiAtrous(in_channel, hidden_channel, size=int(Config.image_size/8))
self.conv1x1_1 = nn.Conv2d(hidden_channel, out_channel, kernel_size=1)
self.conv1x1_2 = nn.Conv2d(out_channel, out_channel, kernel_size=1, bias=False)
self.conv1x1_3 = nn.Conv2d(out_channel, out_channel, kernel_size=1)
self.relu = nn.ReLU()
self.bn = nn.BatchNorm2d(out_channel)
self.softplus = nn.Softplus()
def forward(self, x):
local_feat = self.multi_atrous(x)
local_feat = self.conv1x1_1(local_feat)
local_feat = self.relu(local_feat)
local_feat = self.conv1x1_2(local_feat)
local_feat = self.bn(local_feat)
attention_map = self.relu(local_feat)
attention_map = self.conv1x1_3(attention_map)
attention_map = self.softplus(attention_map)
local_feat = F.normalize(local_feat, p=2, dim=1)
local_feat = local_feat * attention_map
return local_feat
2、Orthogonal Fusion Module
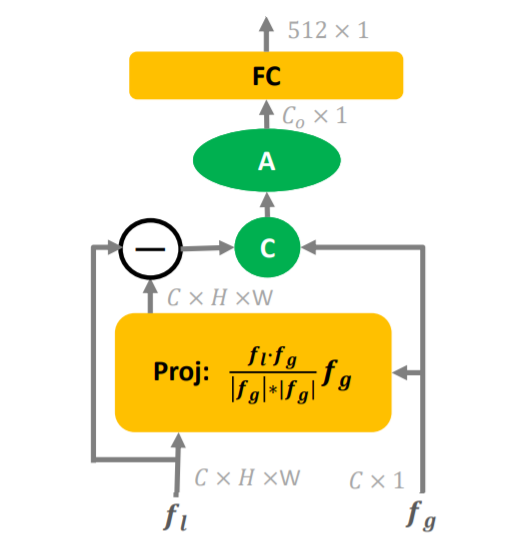
以和为输入,计算每个局部特征点在全局特征上的投影。在数学上,投影可以表示为:
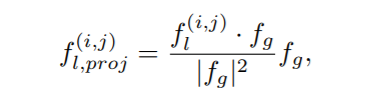
其中,是点积运算,是的L2范数:
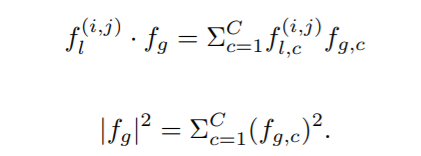
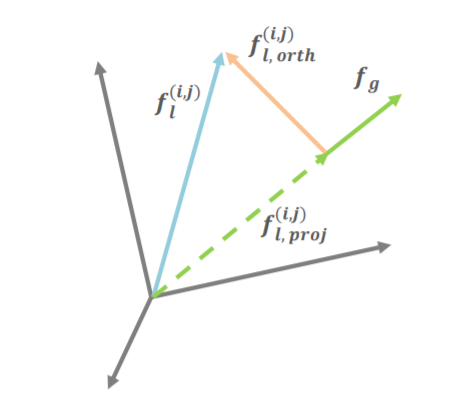
如图3所示,正交分量是局部特征与其投影向量的差值,因此可以通过以下方法得到正交于的分量:
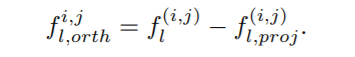
这样,可以提取出一个C×H×W张量,其中每个点都与正交。然后,在这个张量的每个点上加上C×1向量,然后这个新的张量被聚合成的向量。最后,使用一个FC层来生成512×1的特征向量。
这里,利用池化操作来聚合cat的张量,也就是说,图4a中的“A”是当前实现中的池化操作。实际上,它可以被设计成其他可学习的模块来聚合张量。
Orthogonal Fusion Module的Pytorch实现
class OrthogonalFusion(nn.Module):
def __init__(self):
super().__init__()
def forward(self, local_feat, global_feat):
global_feat_norm = torch.norm(global_feat, p=2, dim=1)
projection = torch.bmm(global_feat.unsqueeze(1), torch.flatten(
local_feat, start_dim=2))
projection = torch.bmm(global_feat.unsqueeze(
2), projection).view(local_feat.size())
projection = projection / \
(global_feat_norm * global_feat_norm).view(-1, 1, 1, 1)
orthogonal_comp = local_feat - projection
global_feat = global_feat.unsqueeze(-1).unsqueeze(-1)
return torch.cat([global_feat.expand(orthogonal_comp.size()), orthogonal_comp], dim=1)
2.2 架构之一:纯CNN架构
对于这2个任务方向,作者开发了基于深度学习的网络架构来学习图像描述符,一个是学习高维特征向量以区分更多的类,同时允许类内的可变性。尽管在之前的工作中,全局和局部地标描述符都是分别训练的,并且预测也是以两阶段的方式组合进行的。但也有学者尝试在单一阶段模型中融合全局和局部描述符。
当给定推理条件受限时,作者将重点放在单个图像描述符的单阶段模型上。然而,建模工作将局部特性作为重点,因为它们对地标识别特别重要。
在下文中,提出了2种特别适用于具有噪声数据和高类内变化率的大规模图像识别/检索的体系结构。从概念上讲,两者都使用了基于EfficientNet的卷积神经网络(CNN)和Sub-Center Arcface with dynamic margin(优于经典ArcFace)。
在进行训练时:
1、作者将所有图像调整为正方形大小,并应用shift、scale、rotate和cutout。
2、使用Adam优化+权值衰减+学习率(每个模型学习率不同)
3、遵循在一个warm-up epoch内使用余弦退火学习率机制。
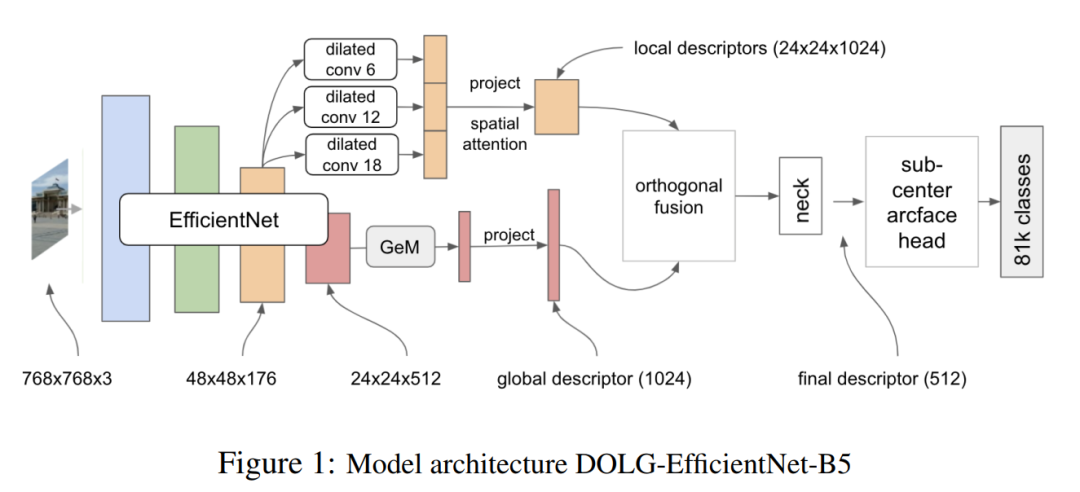
作者基于EfficientNet B5实现了前部分讨论的DOLG模型,但是也做了一些改进来提高性能。
使用在ImageNet上预训练的EfficientNet编码器;
在第3个EfficientNet块之后添加了局部分支,并使用3个不同的空洞卷积提取1024维局部特征(其中每个模型的空洞率不同),Cat输出的3个空洞卷积局部特征,并利用Spatial Attention进行处理得到最终的1024维的局部特征;
然后,将局部特征与全局特征进行正交融合(全局特征是由第4个EfficientNet块输出并GeM池化得到的1024维特征);
使用平均池化操作聚合融合后的特征,然后被输入一个由FC-BN-PReLU组成的Neck输出一个512维的单一描述符。
为了训练,这个单一的描述符被输入到一个Sub-Center(k=3)的ArcFace Head,具有预测81313类的Dynamic Margin。
DOLG-EfficientNet模型是按照3个步骤训练的:
首先,在GLDv2c上使用小图像对模型进行10个epoch的训练;
然后,使用中等大小的图像在噪声更大的GLDv2x上继续训练30-40个Epoch;
最后,使用GLDv2x对大尺寸图像对模型进行微调。
2.3 架构之二:Hybrid-Swin-Transformer with Sub-Center Arcface
第2种架构利用了最近在使用Transformer解决计算机视觉问题方面的进展。在CNN上附加了一个Vision Transformer形成了Hybrid-CNN-Transformer模型。
这里,CNN部分可以解释为一个局部特征提取器,而Transformer部分可以看作一个图神经网络将局部特征聚合到一个单一的向量。
具体步骤:
1、使用EfficientNet提取特征; 2、将第一步输出的特征进行Flatten操作,以适应Transformer的输入; 3、生成一个与Flatten Feature相同shape的Position Embedding与Flatten Feature进行add操作; 4、将Virtual Token与add后的特征进行Cat操作; 5、将cat后的特征作为输入送入Swin-Transformer Block; 6、取出Virtual Token对应位置的描述符送入Neck(Conv-BN-PReLU); 7、将512维的描述符送入Sub-Center ArcFace With Dynamic Head(81313类)进行分类和loss回传。
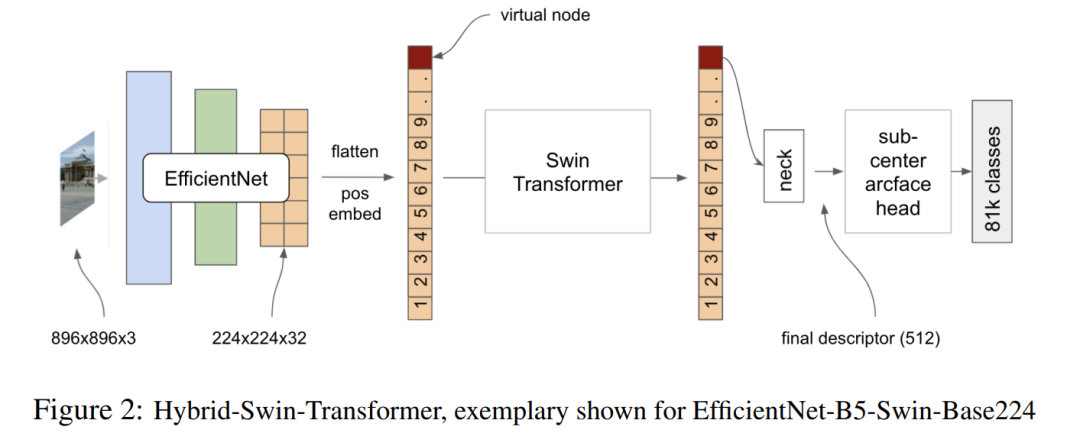
当将在ImageNet上预训练的EfficientNet模型和Swin-Transformer Block组合在一起时,一个详细的训练方法是很重要的,以避免溢出和nan,特别是在使用混合精度时。
作者使用以下4步方法:
第1步:初始化Transformer-Neck-Head部分,使用GLDv2c的小图像进行10个Epoch的训练;
第2步:将Transformer原有的Patch Embedding换成2个EfficientNet Block,冻结之前的Transformer-Neck-Head部分,并在中等大小的图像上对新添加的CNN部分进行一个Epoch的训练;
第3步:使用GLDv2x对整个模型进行30-40个Epoch的训练;
第4步:在CNN和Swin-Transformer之间进一步插入一个预训练的EfficientNet Block,并使用大图像和GLDv2x对整个模型进行微调。
2.4 Ensemble
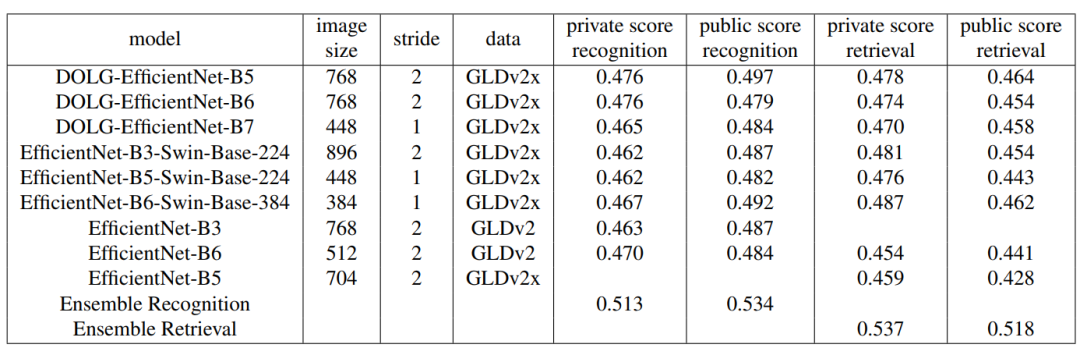
获奖的模型是8个模型的集合,包括3个DOLG和3个Hybrid-Swin-Transformer模型,它们具有不同的EfficientNet主干和输入图像大小。此外,作者还按照谷歌2020地标性识别比赛第3名团队提供的代码和说明对2个EfficientNet模型进行了训练。
表1给出了主干、图像大小、使用的数据和结果得分的概述。对于一些模型,作者没有在最后的训练步骤中增加图像的大小,而是将第1卷积层的stride从(2,2)减小到(1,1),这对于较小的原始图像尤其有利。
2.5 推理预测
对于这2个任务,作者使用了一种预测的检索方法,其中对于每个查询图像,使用L2归一化图像描述符之间的余弦相似度,然后在索引图像数据库中搜索最相似的图像。
在识别任务中,将训练集作为索引图像数据库,并使用最相似列车图像的地标标签作为对给定测试图像的预测。相比之下,为了检索最相似的图像,预定义了一个索引图像数据库。为了增加更多的类内多样性,作者使用完整的GLDv2和来自WIT的地标图像扩展了训练集。
在检索任务中,作者进一步扩展了2019年检索竞赛的索引集。
2.6 检索的后处理
为了在给定的查询图像中检索出最相似的索引图像,作者使用每个模型的512维描述符的余弦相似度对所有索引图像进行排序,从而得到查询索引对分数。
在第一步标签查询和索引图像使用余弦相似度给定的训练集。然而,与Hard Rerank不同的是,作者使用了一种 soft up-rank 过程,即如果查询和索引图像的标签匹配,则将top3索引序列余弦相似度添加到查询索引得分中。
当额外执行一个 soft down-ranking 的过程。如果查询图像和索引图像的标签不匹配,通过减去0.1倍的前3个索引序列余弦相似度来实现向下排序。对于集成中的每个模型,使用上述方法提取每个查询图像的top750索引图像id和相关分数,并将top100作为最终预测之前,对每个图像id进行求和,从而得到6000个分数。
2.7 识别的后处理
使用集成为每个训练和测试图像提取8个512维向量。然后对每个模型类型(DOLG-EfficientNet、Hybrid-Swin-Transformer、pure EfficientNet)的向量进行平均,得到3个512维的向量,然后将它们Cat起来形成一个1536维的图像描述符。利用余弦相似度为每幅测试图像找到最接近的训练图像,并进行后处理重新排序和非地标识别,从而得到最终的预测结果。
3可视化检索结果

4参考
[1].Efficient large-scale image retrieval with deep feature orthogonality and Hybrid-Swin-Transformers