深入理解Java内存模型,应对35K的面试足够了
共 6988字,需浏览 14分钟
·
2021-05-20 00:22
点击“开发者技术前线”,选择“星标🔝”
让一部分开发者看到未来

Java并发是一个很大的主题,包含很多方面的知识。本文从内存模型的角度分析,从概念理论上尽量精确理解Java内存模型,及其对并发的影响。
文章目录
一. 引入 1. 并发的概念 二. 内存模型的理解 1. 什么叫内存模型 2. 顺序一致性模型 3. happens-before 模型 4. Java内存模型 及 “因果关系”(Causality) 三. 提炼理念 1. 技术层次观念与思想方法的互通 2. executed 和 exhibit 的区别,及双向视图
一. 引入
1. 并发的概念
并发听起来是一个计算机术语,但计算机技术毕竟才发展百年,起初理念一定是来源于生活的。
比如在打饭窗口排队打饭,顾客排队的时候是空闲的,而打饭阿姨是忙碌的。没有并发的情况下,一个阿姨对应所有顾客,效率很慢。如果增加窗口同时进行,会成倍提高效率。当然,严格来讲这个情景可以叫“并行”,当每个菜盆在同一时间只有一个勺子可以打饭的时候才叫做“并发”。其中便包含了并发与并行的区别。由此可见,并发最原始的动力就是:充分利用长板,补齐短板,把空闲的东西利用起来,提高效率。
特别的,在计算机技术领域。从冯·诺依曼提出计算机的五大组成部分开始,后来进一步抽象到主要由CPU、内存和I/O组成运转的体系,一直存在的问题就是速度差异巨大且一直存在,表现为 CPU 的速度 > 内存的速度 > I/O 设备的速度。为了充分开发利用计算机的潜能,体系结构、操作系统、编译程序等都做出了改变,比如CPU多核、流水线技术、进程线程概念、数据库中的事务处理等,足见这是一个普适的理念。
有得必有失。在成倍提高效率的同时,并发也引入了新的问题。主要包括:
缓存导致的可见性问题
切换执行导致的原子性问题
重排序导致的有序性问题
这三个问题在很多文章中都有介绍,在此就不多赘述。为了解决这些问题,就引出了本文重点内存模型的概念。
二. 内存模型的理解
1. 什么叫内存模型
“These semantics do not describe how a multithreaded program should be executed. Rather, they describe the behaviors that multithreaded programs are allowed to exhibit.”
2. 顺序一致性模型
在顺序一致性模型里,所有动作以全序(程序顺序)的顺序发生,与程序顺序一致;而且,每个对变量 v 的读操作 r 都将看到写操作 w 写入 v 的值,只要符合:
执行顺序上 w 在 r 之前 执行顺序上不存在这样一个 w’ ,w 在 w’ 之前且 w’ 在 r 之前。
3. happens-before 模型
happens-before 是我们提及JMM最常讨论的一个词,happens-before 规则在JSR-133中是通过 synchronized-with 边缘来辅助定义的。许多资料上将其总结为6条规则,实际上JSR-133中有更多。
首先来说 Synchronizes-With 边缘的规则定义。关于“边缘”这个词,英文原文中就是用的“Synchronizes-With Edges”来表述的,我意会的意思就像如果没有这个边缘,语句的执行是在一个平面上的,是可以来回换且不影响的,但是一旦出现这个边缘,就上了一个台阶,和前一个平面是不能互通的。或者理解成“border”这个词,有点界限的意思。
如果存在以下七种情况,就认为存在Synchronizes-With 边缘。而只要存在Synchronizes-With 边缘,就存在happens-before关系。
“monitor锁定规则”:某个monitor上的解锁动作 synchronizes-with 所有后续在其上的锁定动作; “volatile变量规则”:对volatile变量v的写操作 synchronizes-with 所有后续任意线程对v的读操作; “线程启动规则”:用于启动一个线程的动作 synchronizes-with 该新启动线程中的第一个动作; “线程终止规则”:线程T1的最后一个动作 synchronizes-with 线程T2中任一用于探测T1是否终止的动作; “线程中断规则”:如果线程T1中断了线程T2,T1的中断操作 synchronizes-with 任意时刻任何其它线程(包括 T2)用于确定 T2 是否被中断的操作; “默认值规则”:为每个变量写默认值(0,false或null)的动作 synchronizes-with 该线程中的第一个动作; “对象终结规则”:调用对象的终结方法时,会隐式的读取该对象的引用。从一个对象的构造器末尾到该引用的读取之间存在一个 synchronizes-with 边缘;
在Synchronizes-With 边缘的基础上,还加入了两条,程序顺序规则和传递性规则,这两条是最基本的。
“程序顺序规则”:如果 x 和 y 是 同一个线程中的动作,且在程序顺序上 x 在 y 之前,那么有 x happens-before y; “传递性规则”:happens-before 是传递闭包的。换而言之,如果 x happens-before y,且 y happens-before z,那么可以得到 x happens-before z。
这9条共同定义了happens-before规则,满足这些的就可以说满足happens-before规则,具有了happens-before关系。
如果一个动作 happens-before 另一个动作,则第一个对第二个可见,且第一个排在第二个之前。这在JSR-133中是一种非正式语义(Informal Semantics),是易于理解的。
happens-before已经是一种很强的保证了,所以我们经常说,一个操作是happens-before另一个操作的,就说明是可见的、顺序的、原子的。但是很多网上的理解都说happens-before就是Java内存模型的规则,这个当然是错误的。happens-before也是一种模型而已,它离真正的Java内存模型还差那么一点点。
4. Java内存模型 及 “因果关系”(Causality)

其中用了很多符号和公式以及集合知识来表示线程的行为和行为之间的关系,但是太过复杂。确实只有这样他才能称之为一个规范、一个标准,是严密的经得起推敲验证的,有兴趣的读者可以自行研究。当然了,JSR-133也知道大多数人看不懂,给了一些解释,我们已经有了刚才两个模型的知识铺垫,可以迂回地去理解Java内存模型。
JSR-133原文目录如下图:

举一个JSR -133给出的官方示例,如下图:
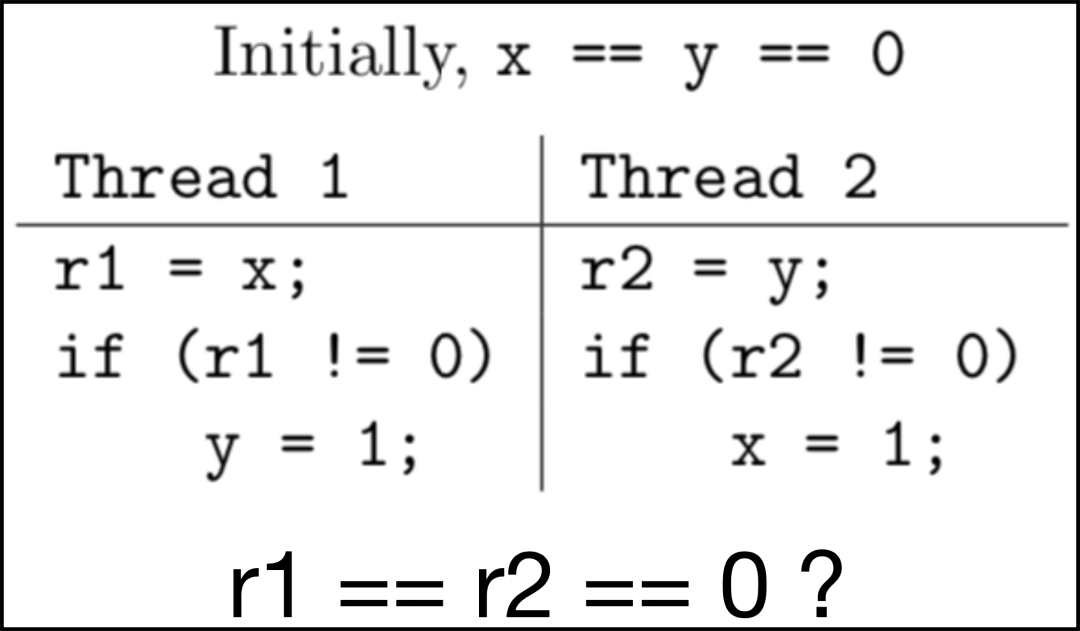

happens-before 内存模型下,这里在执行 r1 = x 的时候,已经看到了 x = 1 的执行结果。我们会感到奇怪,赋值在 if 里,为什么会已经看到了x = 1的写操作结果。
因为程序这样表现没有违反 synchronizes-with 或 happens-before 边缘,是完全符合happens-before模型规定的,允许每个读操作看到其它线程写的值。读者可能会对上一节第8条程序顺序规则产生疑问,但是上述执行顺序确实已经遵守了单线程中的程序顺序规则。因为 r1 = x 并没有看到 y = 1 的执行结果,r2 = y 也没有看到 x = 1 的执行结果,这才是单线程的程序顺序规则。这个问题笔者当时也纠结了一周,直到读了很多遍原文才明白。r1 = x 读操作 和 x = 1 写操作是两个线程的事情,按照happens-before模型单线程的程序顺序规则是不相互制约的。
顺便一提,这里是解释“标准”或者说“规范”的一个绝佳的例子。还记得那句话吗, should be executed 和 are allowed to exhibit。happens-before 包括JMM都只是一种规范理论,而不去管能不能实现或者怎么样实现(真实情况可能由于多级缓存可能由于重排序也可能先执行再决定是否回滚等,这些都是实现层面的事情)。在此处,由于遵守了 happens-before 规则的约定,所以此顺序的任意读操作可以看到任意写操作的结果,也就看到了x = 1的写操作结果。总的来说,要从一个内存模型而不是内存模型实现的角度去理解它。
说回JMM,这种执行顺序是 happens-before 允许的,但JMM不允许,也就是上述的因果关系。所以,happens-before 模型可以理解为JMM的真子集,它们的差别就是因果关系(Causality)。
因果关系正式的表述是:
因果关系解决 什么时候一个顺序靠前的读操作 被允许看到 顺序靠后的写操作的执行结果(在 happens-before 基础上):
如果一个写操作无论在何种排序中都会被执行,则可以被较早看到;
如果一个写操作依赖于先前的某些读操作才会被执行,则不可以被较早看到。
具体到我们的代码,什么样的操作算是因果关系呢。其实我们的程序也就三种过程结构,顺序结构、选择结构、循环结构。在其中用到判断因果关系的地方,比如 if else, switch case等,用语义去理解就可以。
比如如果感到幸福你就拍拍手,拍手的前提是感到幸福,这就是因果关系,是符合我们正常认知的,不用在写代码的时候刻意在意。
综上,对JMM的理解总结如下图: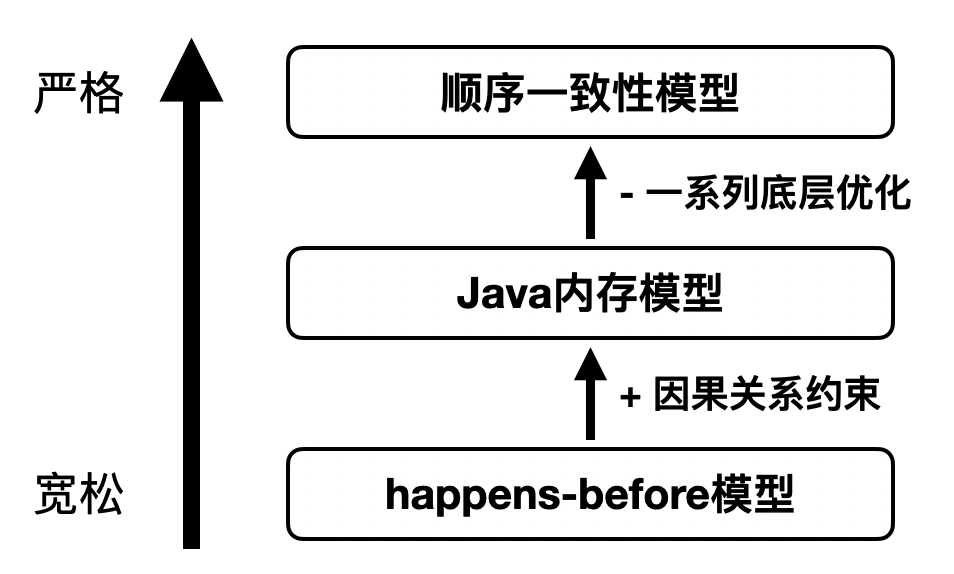
我们终于可以比较全面地来理解Java内存模型了。Java内存模型是什么?上图是笔者总结JSR-133之后认为的干货。首先Java内存模型是一种共享内存方式的内存模型,它比起顺序一致性模型这种理想化模型要宽松很多,从编译到底层执行部分各个层次都做了不同程度的优化。和它最贴近的是happens-before内存模型,两者只相差一个因果关系的约束。在因果关系的前提下,只要它满足happens-before,就是JMM允许的。
在我们的编程中,尤其要注意上一节所说的 happens-before 的第 1- 7 条规则。
了解JMM之后,我引用一个网上流传类似的图,看一下JMM在各种内存模型中处于什么样的位置。
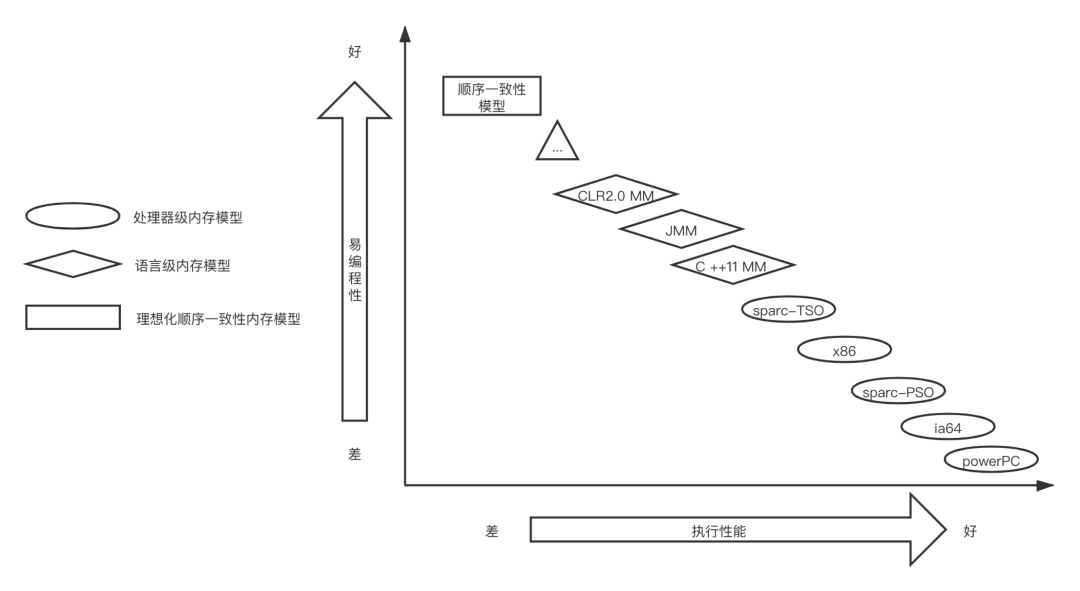
有两个可以说互斥的指标在约束着内存模型们。一般来说,易编程性越好,就是要注意的并发的坑越少,这个内存模型的执行性能就会越差。最极端的例子是顺序一致性模型,完全不用考虑这个变量会不会同时被两个线程操作之类的问题。当然我们不可能用这样的理想模型,因为我们对于执行性能是有很大要求的。菱形的是语言级别的内存模型,JMM相比C的内存模型会更严格一些,执行性能也会差一些。虽然语言级别的内存模型已经做了一些优化,但是处理器级别的内存模型还是会秒杀他们,对于用户不能感知的优化会更多。
三. 提炼理念
1. 技术层次观念与思想方法的互通
类似并发这样的思想在计算机技术的每一个层次都会用到。比如在CPU层为了并发用到了多级缓存,会产生不一致的问题,MESI协议在这一层解决了这个问题,给了CPU使用者一个统一的视图。但是在上层,如操作系统、汇编语言、高级语言等层次也会用到缓存等提高效率,这时候MESI不能解决这些层次的问题,需要该层次对应的解决办法,如高级语言层次的Java内存模型。
2. executed 和 exhibit 的区别,及双向视图
内存模型对于开发者强调的概念是如何表现,就像一个黑盒展现给人们的输入输出视图。JMM协调了底层硬件和上层开发者之间相反的需求,形象表示如下图: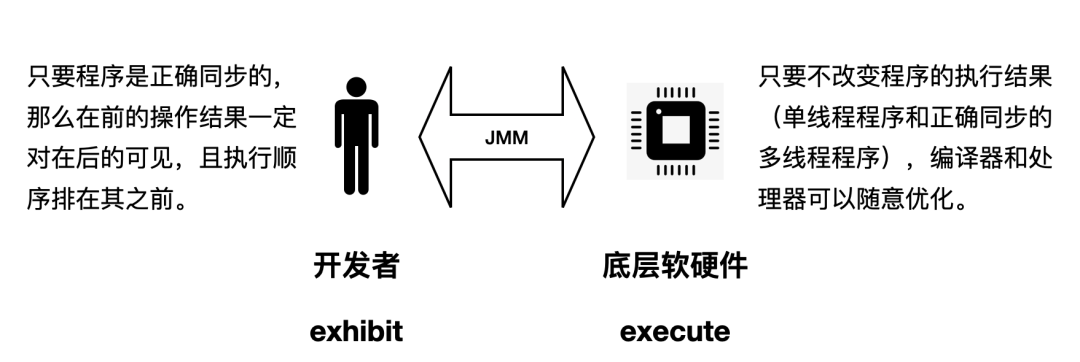
JMM做出了双向承诺:
从Java开发者的视角,希望内存模型易于理解、易于编程,所以希望基于一个强内存模型来编写代码。JMM向开发者提供保证,只要程序是正确同步的(满足A happens-before B 和因果关系),那么A的操作结果一定对B可见,且A的执行顺序排在B之前。虽然这么说是骗我们的,但是我们心甘情愿被骗了。 从编译器和处理器的视角,希望内存模型对其优化的束缚越小越好,这样就可以尽可能提高性能,所以希望实现一个弱内存模型。JMM遵循一个基本原则:只要不改变程序的执行结果(单线程程序和正确同步的多线程程序),编译器和处理器可以随意优化。这里的“正确同步”就是指如volatile、synchronized等规定的具体规则,不多赘述。
本文主要从内存模型理论的角度,分析了内存模型的概念和侧重点,运用逼近的方法理解Java内存模型,尤其深入了“因果关系”的概念,帮助大家了解 happens-before 模型和JMM的区别。同时浅析了JMM中涉及的技术理念。具体实践方面有更多的问题需要学习探究,如volatile、synchronized底层原理与应用方法、并发相关JUC类库等,可以继续深入研究。
最后给读者整理了一份大厂面试真题,需要的可扫码加我微信获取。

前线推出学习交流群,加群一定要备注: 研究/工作方向+地点+学校/公司+昵称(如大数据+上海+上交+可可) 根据格式备注,可更快被通过且邀请进群,领取一份专属学习礼包
扫码加助理微信进群,内推和技术交流,大佬们零距离