
在百度,Spark,Hadoop,Hive ,哪个更香?
众所周知,大数据开发和分析、机器学习、数据挖掘中,都离不开各种开源分布式系统。最常见的就是 Hadoop、Hive、Spark这三个框架了。最近不少朋友有问到关于这些的问题:
大厂里还有在用 Hadoop 吗?感觉都在用 Spark,有些慌!
SQL boy 大厂面试都问什么?Hadoop、Spark、Flink 都搞过!
听说百度只用 Hadoop,为什么不用业界都在用的 Spark !
为什么百度不用SQL支持数据处理,还在写一堆 Hadoop 脚本!
Java 开发需要对大数据了解多少,Hbase、Hive、Spark 这些吗?
不同的业务场景决定了不同的系统架构选型。Hadoop 用于分布式存储和 Map-Reduce 计算,Spark 用于分布式机器学习,Hive 则是分布式数据库。Hive 和 Spark 是大数据领域内为不同目的而构建的不同产品。二者都有不可替代的优势。Hive 是一个基于Hadoop 的分布式数据库,Spark 则是一个用于数据分析的框架。
这就要求技术人不得不掌握各种开源的技术框架。这就会造成顾此失彼,学完易忘、易混淆的情况。为了解决这个问题,这里推荐给大家一个高效学习和开发的宝藏:一份大数据/分布式开发速查表。内容涵盖:Spark、Hadoop 及 Hive 等日常工作中几乎所有的技术知识点。
对比详细却冗长的技术文档,速查表要显得更加便捷与直观。 可以帮大家很轻松的从上面找到具体某项技术的快捷命令与语法,相信能大幅提升开发效率,同时,一些遗忘的知识点也都能通过速查表来快速获取。
由于篇幅原因,下面只展示了速查表的部分内容。无论你是学习进阶,还是日后温习,这套速查表资料都值得好好珍藏。

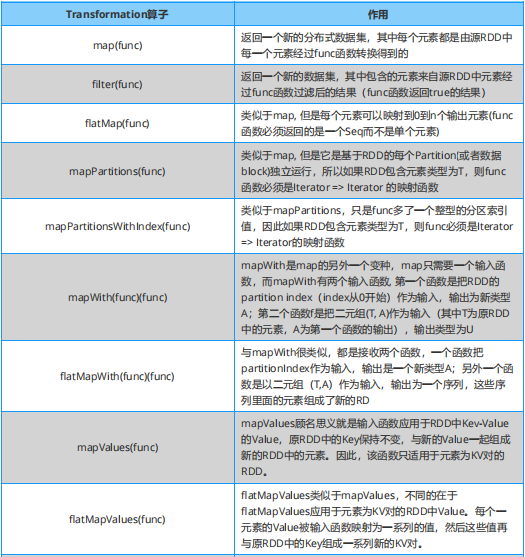
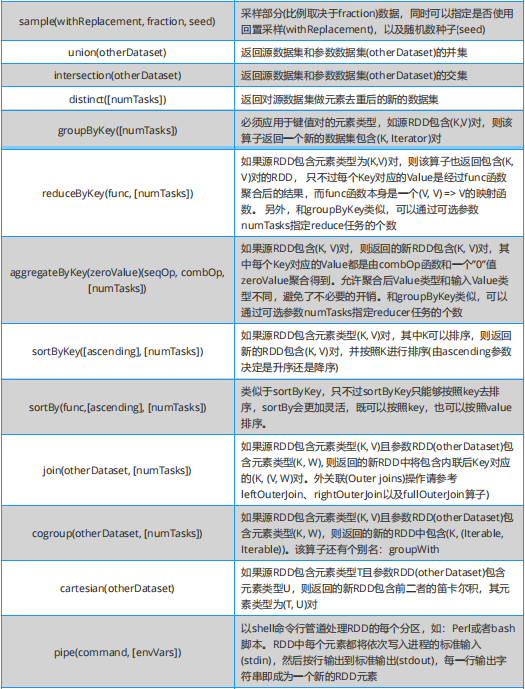
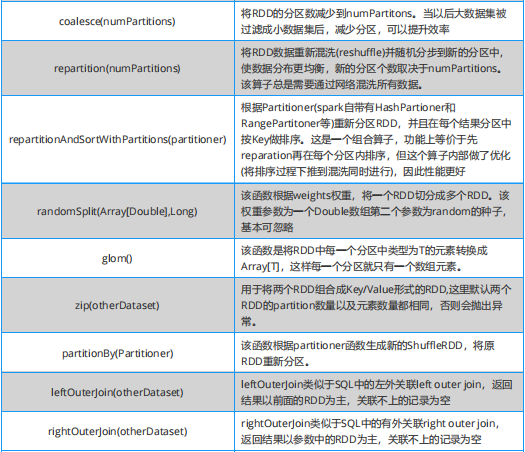
Spark 必知必会:Transformation 算子
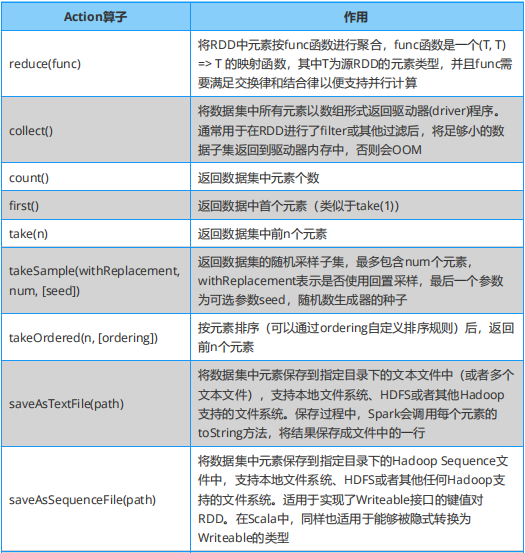
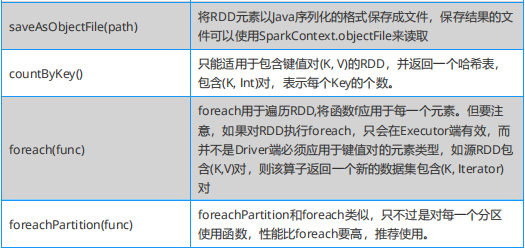
Spark 必知必会:Action算子

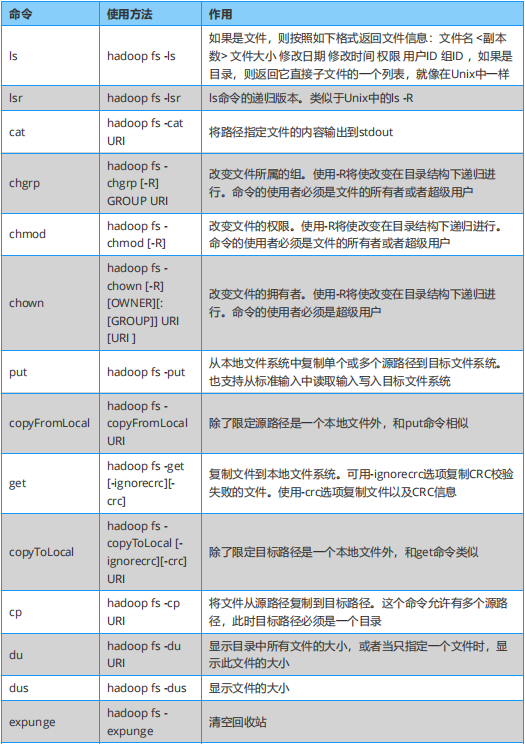
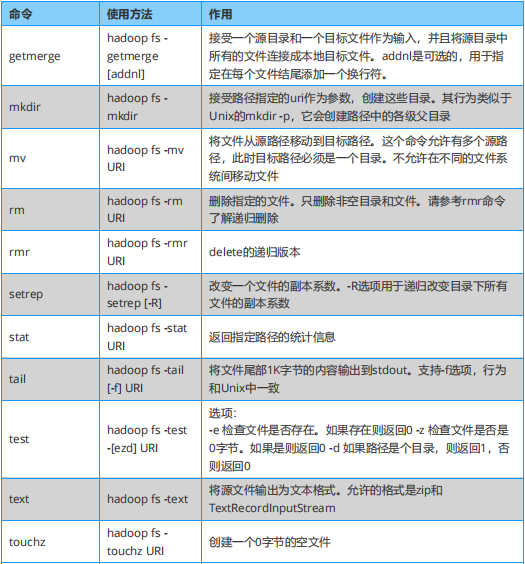
Hadoop 必知必会:Hadoop Shell

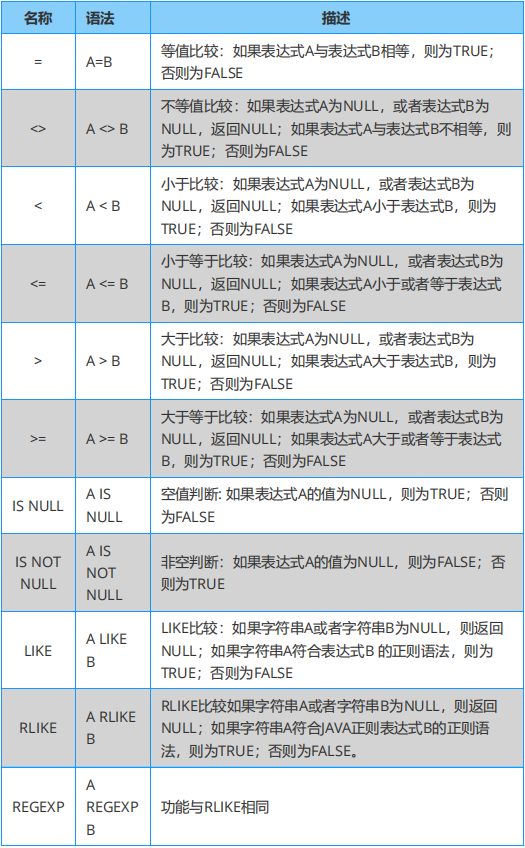
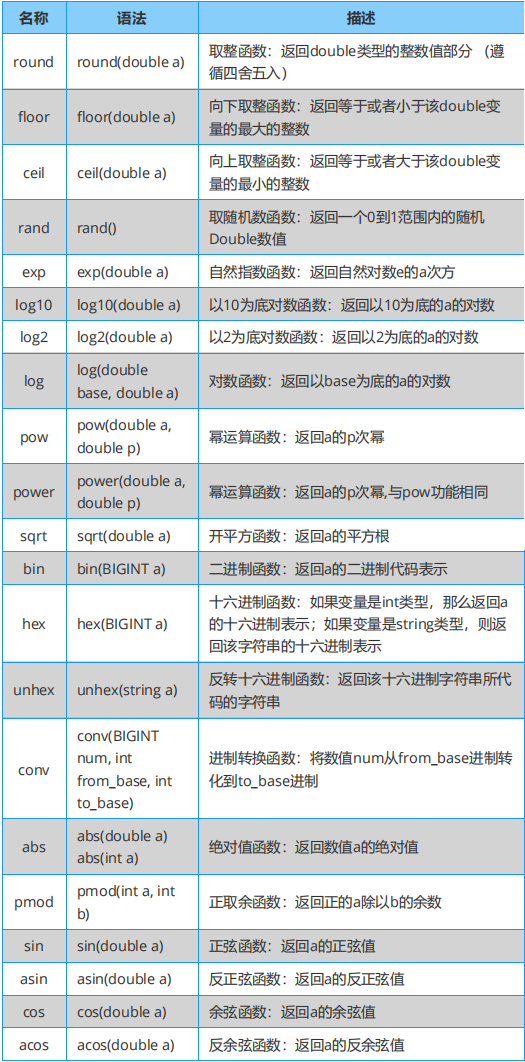
Hive 必知必会:数值计算
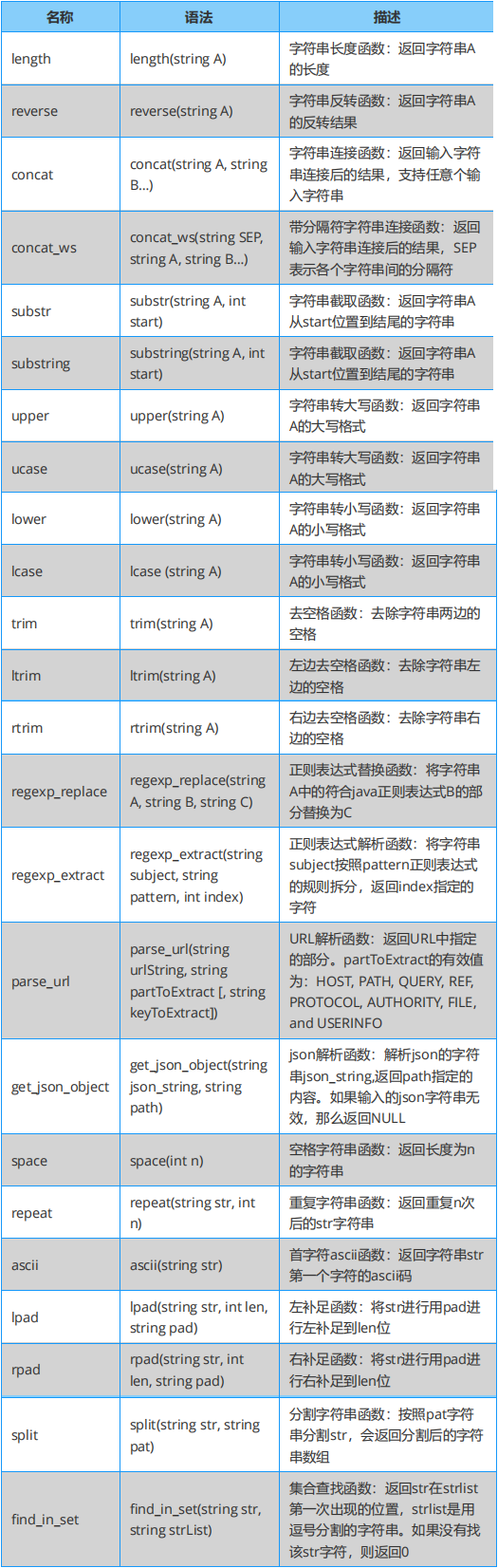
Hive 必知必会:字符串函数
大数据开发代码速查表
高清版全部内容
 扫码加微信,免费领取
扫码加微信,免费领取

(添加人多,请耐心等待)