
AI狂飙70年背后原因大揭秘!时代周刊4张图,揭露算法进化之谜

新智元报道
新智元报道
【新智元导读】《时代周刊》用4张图告诉我们,为什么AI发展的发展不太可能放缓,只可能加快。
在过去的十年里,AI系统发展的速度令人惊叹。
2016年AlphaGo在围棋比赛中击败李世石,就是一个开始。现在,AI已经可以比人类更好地识别图像和语音,通过商学院考试,以及亚马逊的编程面试题。
就在上周,美国参议院司法委员会开展了关于监管AI的听证会。
在会上,著名AI初创公司Anthropic的CEO Dario Amodei表示说:了解AI最重要的一件事,就是知道它的发展速度有多快。

最近,《时代周刊》就发了一篇文章,用四张图告诉我们,AI的发展速度为什么不会放缓。
人类正在被AI超越
下图是SOTA模型在基准测试上相对于人类的表现。
测试的能力分别是手写识别(MNIST)、语音识别(Switchboard)、图像识别(ImageNet)、阅读理解(SQuAD 1.1 & SQuAD 2.0)、语言理解(GLUE)、常识完成(HellaSwag)、小学数学(GSK8k)、代码生成(HumanEval)。
 人类的表现被设定为100%
人类的表现被设定为100%
人们通常会认为,科学和技术进步在根本上是不可预测的,驱动它们的是一种在事后才变得更清晰的洞察力。
但我们可以预见,AI系统的进步是由三个输入(计算、数据和算法)的进步推动的。
过去70年的大部分进步,都是研究人员使用更大的算力训练AI系统的结果。
系统被提供了更多数据,或者存在更强的算法,有效地减少了获得相同结果所需的计算或数据量。
只要了解这三个因素在过去是如何推动了人工智能的进步,我们就会理解为什么大多数AI从业者预计AI的进展不会放缓。
计算量的增加

拥有1000个人工神经元的Mark I,训练一次大概需要7x10^5次操作。
而70多年后OpenAI发布的大语言模型GPT-4,训练一次大概需要21x10^24次操作。
计算量的增加,不仅让AI系统可以从更多的数据中学到更多的示例,而且还可以更详细地对变量之间的关系进行建模,从而得出更准确、更细致的结论。
自1965年以来,摩尔定律(集成电路中的晶体管数量大约每两年翻一番)意味着算力的价格一直在稳步下降。
不过,研究机构Epoch的主任Jaime Sevilla表示,这时的研究人员更专注于开发构建AI系统的新技术,而不是关注使用多少计算来训练这些系统。
然而,情况在2010年左右发生了变化——研究人员发现「训练模型越大,表现效果越好」。
从那时起,他们便开始花费越来越多的资金,来训练规模更大的模型。
训练AI系统需要昂贵的专用芯片,开发者要么构建自己的计算基础设施,要么向云计算服务商付费,访问他们的基础设施。

随着这一支出的不断增长,再加上摩尔定律带来的成本下降,AI模型也能够在越来越强大的算力上进行训练。
据OpenAI CEO Sam Altman透露,GPT-4的训练成本超过了1亿美元。
作为业界的两个顶流,OpenAI和Anthropic已经分别从投资者那里筹集了数十亿美元,用于支付训练AI系统的计算费用,并各自与财力雄厚的科技巨头(微软、谷歌)建立了合作伙伴关系。
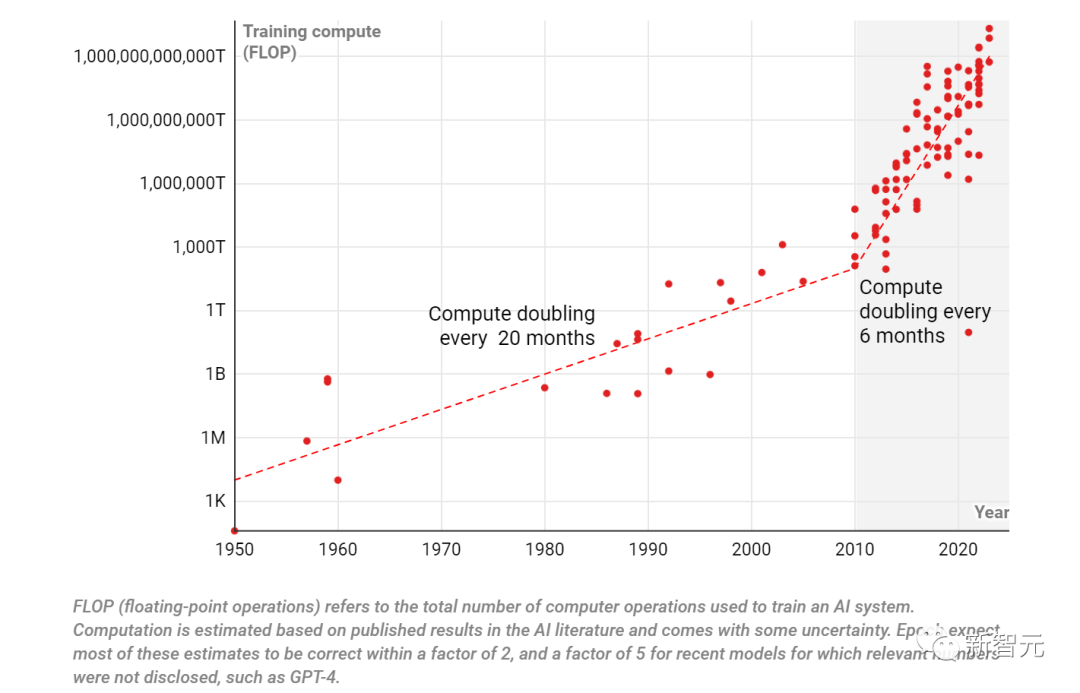 自1950年以来,用于训练AI系统的计算量一直在增加;到2010年,增长率也增加了
自1950年以来,用于训练AI系统的计算量一直在增加;到2010年,增长率也增加了
数据量的增长
无论是单词「home」与单词「run」相邻的可能性,还是基因序列与蛋白质折叠之间的模式,即蛋白质以其三维形态取得功能的过程。

一般来说,数据越多AI系统就有越多信息来建立数据中变量之间准确的关系模型,从而提高性能。
例如,一个被提供更多文本的语言模型将拥有更多以「run」跟随「home」出现的句子示例。因为在描述棒球比赛或强调成功的句子中,这种词序更为常见。
关于Perceptron Mark I的原始研究论文指出,它仅使用了六个数据点进行训练。

论文地址:https://blogs.umass.edu/brain-wars/files/2016/03/rosenblatt-1957.pdf
相比之下,由Meta在2023年发布的大语言模型LLaMA,则使用了约10亿个数据点进行训练——比Perceptron Mark I增加了超过1.6亿倍。
其中,这些数据包括,67%的Common Crawl数据,4.5%的GitHub,以及4.5%的维基百科。
 在过去的70年中,用于训练AI模型的数据量急剧增加
在过去的70年中,用于训练AI模型的数据量急剧增加
训练数据大小是指用于训练AI模型的数据量,表示可供模型学习的示例数。
每个领域都有一个特定的数据点输入单元,例如用于训练视觉模型的图像、用于语言模型的单词,和用于游戏模型的时间步长。这意味着系统只能在同一领域内进行比较。
算法的进步
除了使用越来越多的算力在更多数据上训练AI之外,研究人员还在寻找在寻找如何用更少的资源获得更多的效益。
Epoch的研究发现,「每九个月,更好的算法的引入,相当于让计算预算翻番。」
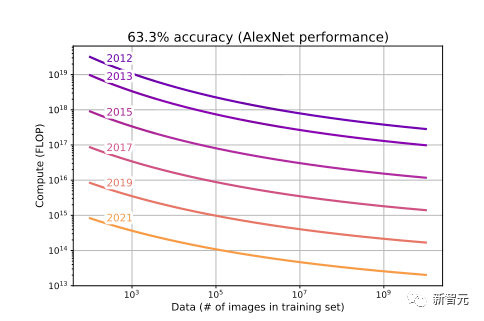
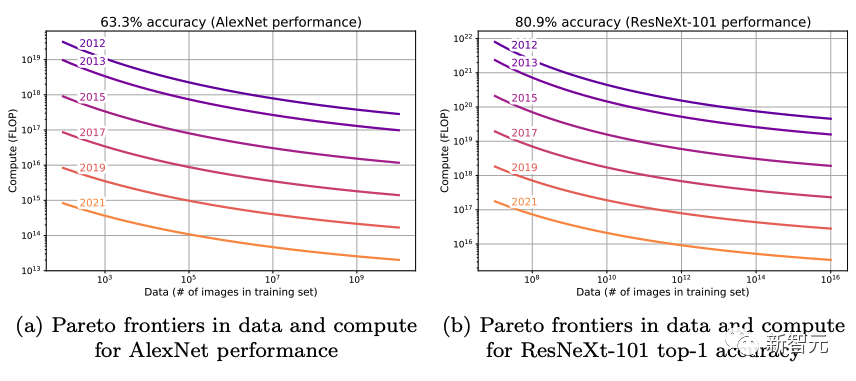 训练模型的帕累托边界,以实现知名模型随时间推移的性能
训练模型的帕累托边界,以实现知名模型随时间推移的性能
而算法进步也就是意味着,模型可以凭借着更少的计算和数据,达到相同的性能水平。
下图是在六个不同年份中,在图像识别测试中达到80.9%的准确度所需的计算量和数据点数。
对于在1万亿个数据点上训练的模型,2021年训练的模型所需的计算量比2012年训练的模型少~16,500倍。
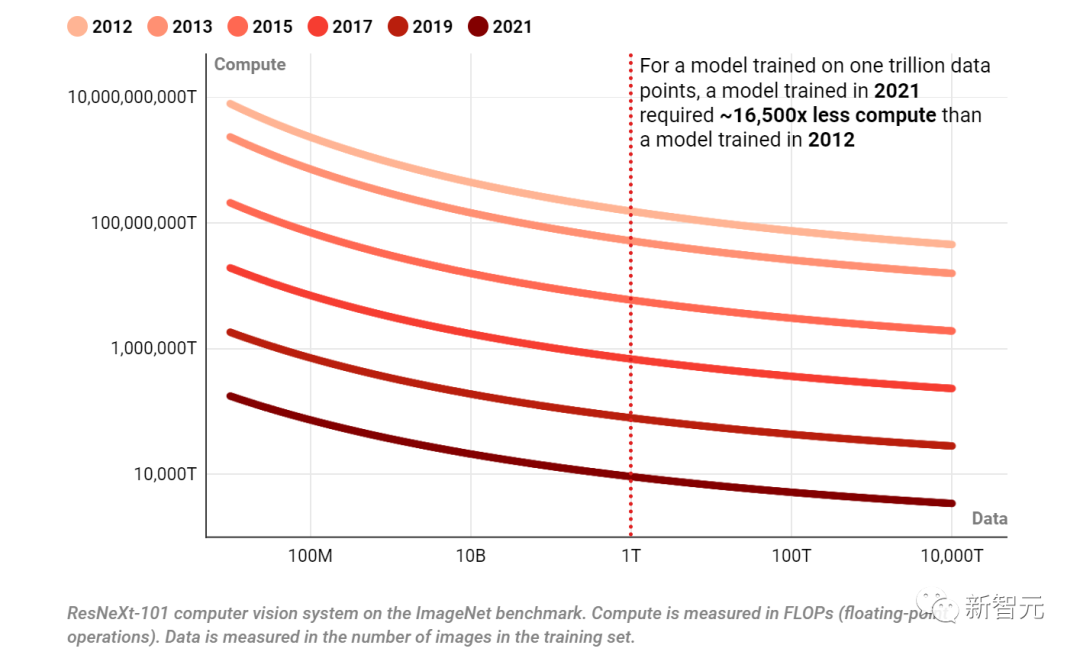 在图像识别测试中,达到80.9%准确率所需的计算量和数据量
在图像识别测试中,达到80.9%准确率所需的计算量和数据量
调查涉及的是ImageNet基准测试上的ResNeXt-101计算机视觉系统,计算以FLOP为单位,数据以训练集中的图像数量来衡量。
AI的下一个阶段
直到个时刻,继续增加计算量只能略微提高性能为止。在此之后,计算量将继续增加,但速度会放慢。而这完全是因为摩尔定律导致计算成本下降。
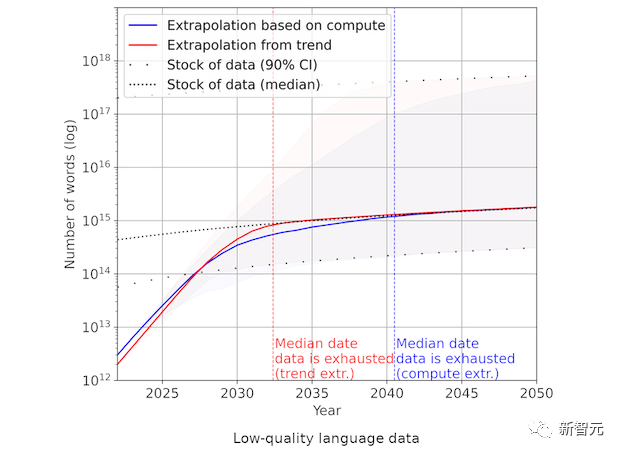
目前,AI系统(如 LLaMA)所使用的数据来自互联网。在以往,能输入AI系统多少数据量,主要取决于有多少算力。
而最近训练AI系统所需的数据量的爆炸性增长,已经超过了互联网上新文本数据的生产速度。
因此,Epoch预测,研究人员将在2026年用尽高质量的语言数据。

不过,开发AI系统的人对这个问题似乎不太担心。
在3月份参加Lunar Society的播客节目时,OpenAI的首席科学家Ilya Sutskever表示:「我们的数据情况还不错。还有很多可用的数据。」
在7月份参加Hard Fork播客节目时,Dario Amodei估计:「在数据不足的情况下,这种扩展可能有10%的几率会受到影响。」
Sevilla也相信,数据的不足并不会阻止AI的进一步发展,例如找到使用低质量语言数据的方法。因为与计算不同,数据不足以前并没有成为AI发展的瓶颈。
他预计,在创新方面,研究人员将很可能会发现很多简单的方法来解决这个问题。
到目前为止,算法的大部分改进,都源于如何更高效地利用算力这一目标。Epoch发现,过去超过四分之三的算法进步,都是被用来弥补计算的不足。
未来,随着数据成为AI训练发展的瓶颈,可能会有更多的算法改进,被用来弥补数据上的不足。
综合以上三个方面,包括Sevilla在内的专家们预计,AI进展将在未来几年内继续以惊人的速度进行。
计算量将继续增加,因为公司投入更多资金,底层技术也变得更加便宜。
互联网上剩余有用的数据将被用于训练AI模型,研究人员将继续找到训练和运行AI系统的更高效方法,从而更好地利用算力和数据。
而AI在这些十年的发展趋势,也将继续延续下去。
当然,这种趋势也让很多AI专家感到担忧。
在参议院委员会听证会上,Anthropic CEO Amodei提出,如果AI再继续进步下去,两到三年内,普通人都可以获得即使是专家也无法获得的科学知识了。
这可能造成的网络安全、核技术、化学、生物学等领域造成的严重破坏和滥用,谁都无法想象。

