
Spring Kafka:@KafkaListener 单条或批量处理消息
来源:csdn.net/ldw201510803006/article/details/116176711
消息监听容器
1、KafkaMessageListenerContainer
由spring提供用于监听以及拉取消息,并将这些消息按指定格式转换后交给由@KafkaListener注解的方法处理,相当于一个消费者;
看看其整体代码结构:
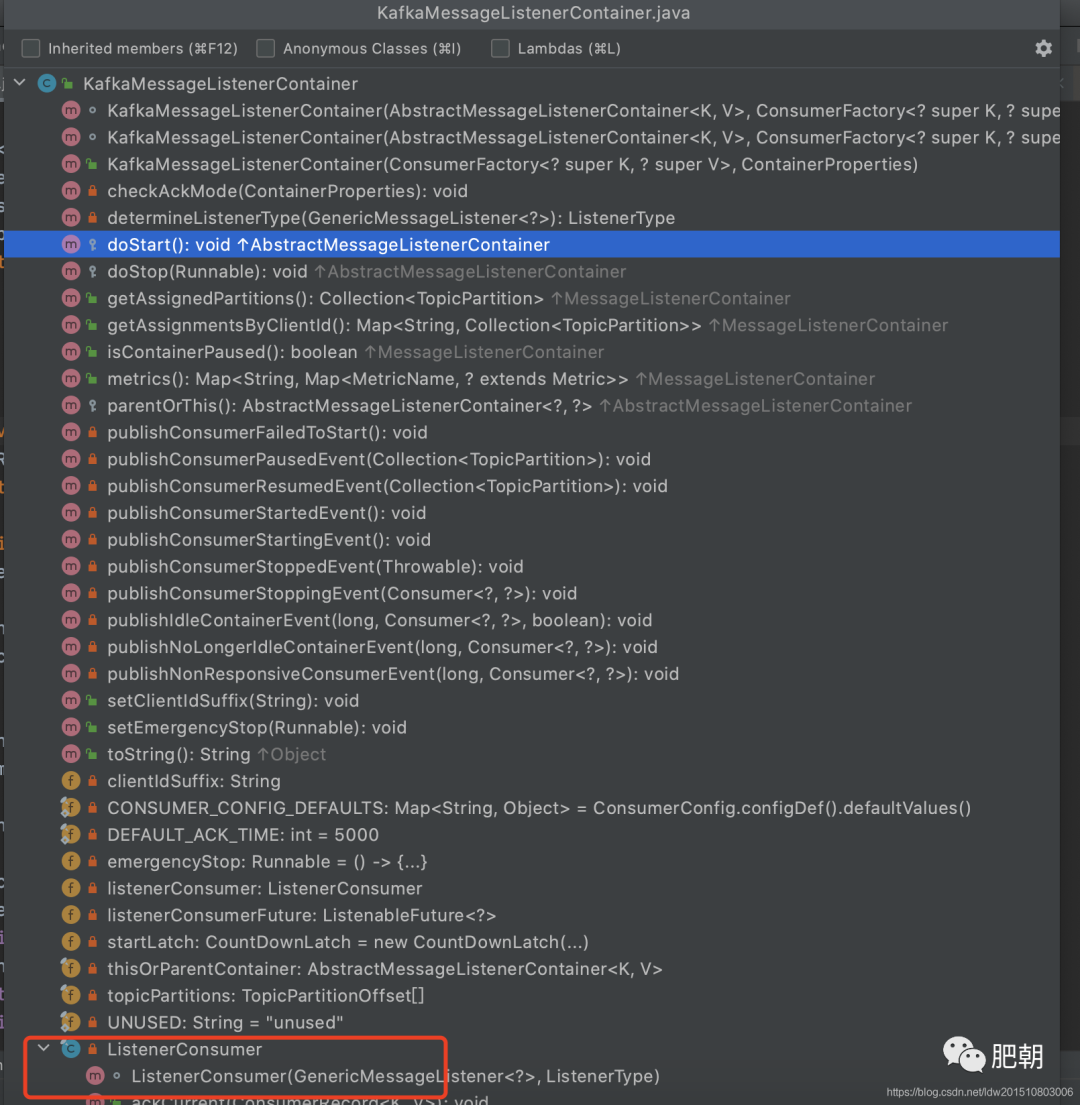
可以发现其入口方法为doStart(), 往上追溯到实现了SmartLifecycle接口,很明显,由spring管理其start和stop操作; ListenerConsumer, 内部真正拉取消息消费的是这个结构,其 实现了Runable接口,简言之,它就是一个后台线程轮训拉取并处理消息 在doStart方法中会创建ListenerConsumer并交给线程池处理 以上步骤就开启了消息监听过程
KafkaMessageListenerContainer#doStart
protected void doStart() {
if (isRunning()) {
return;
}
if (this.clientIdSuffix == null) { // stand-alone container
checkTopics();
}
ContainerProperties containerProperties = getContainerProperties();
checkAckMode(containerProperties);
......
// 创建ListenerConsumer消费者并放入到线程池中执行
this.listenerConsumer = new ListenerConsumer(listener, listenerType);
setRunning(true);
this.startLatch = new CountDownLatch(1);
this.listenerConsumerFuture = containerProperties
.getConsumerTaskExecutor()
.submitListenable(this.listenerConsumer);
......
}
KafkaMessageListenerContainer.ListenerConsumer#run
public void run() { // NOSONAR complexity
.......
Throwable exitThrowable = null;
while (isRunning()) {
try {
// 拉去消息并处理消息
pollAndInvoke();
}
catch (@SuppressWarnings(UNUSED) WakeupException e) {
......
}
......
}
wrapUp(exitThrowable);
}
2、ConcurrentMessageListenerContainer
并发消息监听,相当于创建消费者;其底层逻辑仍然是通过KafkaMessageListenerContainer实现处理;从实现上看就是在KafkaMessageListenerContainer上做了层包装,有多少的concurrency就创建多个KafkaMessageListenerContainer,也就是concurrency个消费者
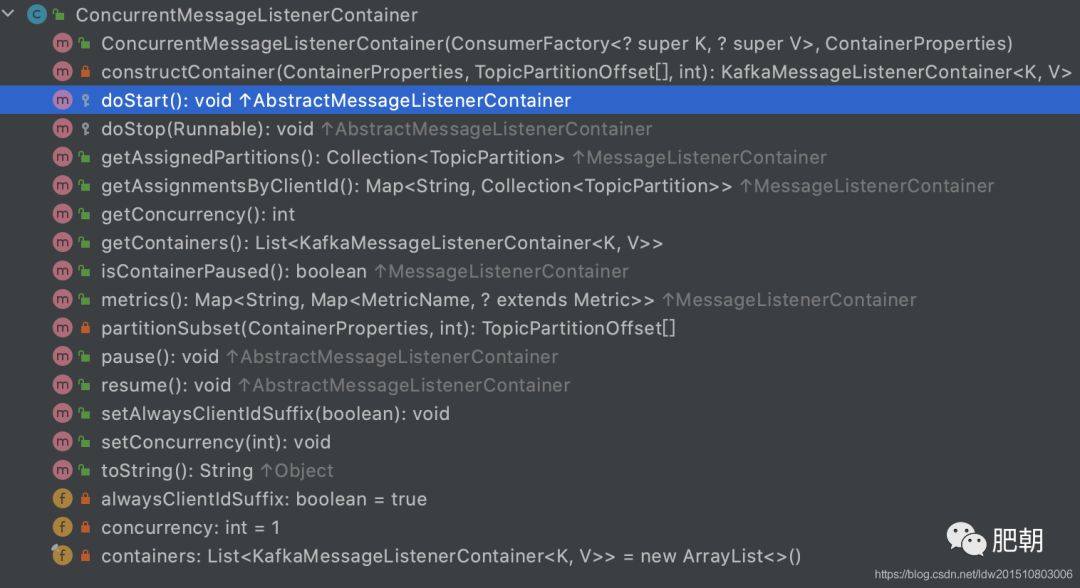
ConcurrentMessageListenerContainer#doStart
protected void doStart() {
if (!isRunning()) {
checkTopics();
......
setRunning(true);
for (int i = 0; i < this.concurrency; i++) {
KafkaMessageListenerContainer container =
constructContainer(containerProperties, topicPartitions, i);
String beanName = getBeanName();
container.setBeanName((beanName != null ? beanName : "consumer") + "-" + i);
......
if (isPaused()) {
container.pause();
}
// 这里调用KafkaMessageListenerContainer启动相关监听方法
container.start();
this.containers.add(container);
}
}
}
@KafkaListener底层监听原理
上面已经介绍了
KafkaMessageListenerContainer的作用是拉取并处理消息,但还缺少关键的一步,即 如何将我们的业务逻辑与KafkaMessageListenerContainer的处理逻辑联系起来?
那么这个桥梁就是@KafkaListener注解
KafkaListenerAnnotationBeanPostProcessor, 从后缀BeanPostProcessor就可以知道这是Spring IOC初始化bean相关的操作,当然这里也是;此类会扫描带@KafkaListener注解的类或者方法,通过 KafkaListenerContainerFactory工厂创建对应的KafkaMessageListenerContainer,并调用start方法启动监听,也就是这样打通了这条路…
Spring Boot 自动加载kafka相关配置
1、KafkaAutoConfiguration
自动生成kafka相关配置,比如当缺少这些bean的时候KafkaTemplate、ProducerListener、ConsumerFactory、ProducerFactory等,默认创建bean实例
2、KafkaAnnotationDrivenConfiguration
主要是针对于spring-kafka提供的注解背后的相关操作,比如 @KafkaListener; 在开启了@EnableKafka注解后,spring会扫描到此配置并创建缺少的bean实例,比如当配置的工厂beanName不是kafkaListenerContainerFactory的时候,就会默认创建一个beanName为kafkaListenerContainerFactory的实例,这也是为什么在springboot中不用定义consumer的相关配置也可以通过@KafkaListener正常的处理消息
生产配置
1、单条消息处理
@Configuration
@EnableKafka
public class KafkaConfig {
@Bean
KafkaListenerContainerFactory>
kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.setConcurrency(3);
factory.getContainerProperties().setPollTimeout(3000);
return factory;
}
@Bean
public ConsumerFactory consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
}
@Bean
public Map consumerConfigs() {
Map props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, embeddedKafka.getBrokersAsString());
...
return props;
}
}
@KafkaListener(id = "myListener", topics = "myTopic",
autoStartup = "${listen.auto.start:true}", concurrency = "${listen.concurrency:3}")
public void listen(String data) {
...
}
2、批量处理
@Configuration
@EnableKafka
public class KafkaConfig {
@Bean
public KafkaListenerContainerFactory batchFactory() {
ConcurrentKafkaListenerContainerFactory factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.setBatchListener(true); // <<<<<<<<<<<<<<<<<<<<<<<<<
return factory;
}
@Bean
public ConsumerFactory consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
}
@Bean
public Map consumerConfigs() {
Map props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, embeddedKafka.getBrokersAsString());
...
return props;
}
}
@KafkaListener(id = "list", topics = "myTopic", containerFactory = "batchFactory")
public void listen(List list) {
...
}
3、同一个消费组支持单条和批量处理
场景:
生产上最初都采用单条消费模式,随着量的积累,部分topic常常出现消息积压,最开始通过新增消费者实例和分区来提升消费端的能力;一段时间后又开始出现消息积压,由此便从代码层面通过批量消费来提升消费能力。
只对部分topic做批量消费处理
简单的说就是需要配置批量消费和单条记录消费(从单条消费逐步向批量消费演进)
假设最开始就是配置的单条消息处理的相关配置,原配置基本不变 然后新配置 批量消息监听KafkaListenerContainerFactory
@Configuration
@EnableKafka
public class KafkaConfig {
@Bean(name = [batchListenerContainerFactory])
public KafkaListenerContainerFactory batchFactory() {
ConcurrentKafkaListenerContainerFactory factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
// 开启批量处理
factory.setBatchListener(true);
return factory;
}
@Bean(name = [batchConsumerFactory])
public ConsumerFactory consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
}
@Bean(name = [batchConsumerConfig])
public Map consumerConfigs() {
Map props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, embeddedKafka.getBrokersAsString());
...
return props;
}
}
注意点:
如果自定义的ContainerFactory其beanName不是kafkaListenerContainerFactory,spring会通过KafkaAnnotationDrivenConfiguration创建新的bean实例,所以需要注意的是你最终的@KafkaListener会使用到哪个ContainerFactory 单条或在批量处理的ContainerFactory可以共存,默认会使用beanName为kafkaListenerContainerFactory的bean实例,因此你可以为batch container Factory实例指定不同的beanName,并在@KafkaListener使用的时候指定containerFactory即可
总结
spring为了将kafka融入其生态,方便在spring大环境下使用kafka,开发了spring-kafa这一模块,本质上是为了帮助开发者更好的以spring的方式使用kafka @KafkaListener就是这么一个工具,在同一个项目中既可以有单条的消息处理,也可以配置多条的消息处理,稍微改变下配置即可实现,很是方便 当然,@KafkaListener单条或者多条消息处理仍然是spring自行封装处理,与kafka-client客户端的拉取机制无关;比如一次性拉取50条消息,对于单条处理来说就是循环50次处理,而多条消息处理则可以一次性处理50条;本质上来说这套逻辑都是spring处理的,并不是说单条消费就是通过kafka-client一次只拉取一条消息 在使用过程中需要注意spring自动的创建的一些bean实例,当然也可以覆盖其自动创建的实例以满足特定的需求场景
最近熬夜给大家准备了非常全的一套Java一线大厂面试题。全面覆盖BATJ等一线互联网公司的面试题及解答,由BAT一线互联网公司大牛带你深度剖析面试题背后的原理,不仅授你以鱼,更授你以渔,为你面试扫除一切障碍。

资源,怎么领取?
扫二维码,加我微信,备注:面试题
一定要备注:面试题,不要急哦,工作忙完后就会通过!
评论