
记一次曲折的多资源文件拆分折腾过程(3)—— 在 windows 下用 linux 神器 gdb 调试 git
前言
在前面两篇文章 记一次曲折的多资源文件拆分折腾过程(1) 和 记一次曲折的多资源文件拆分折腾过程(2)中,已经把折腾过程中遇到的问题都弄清楚了。因为对这个问题印象太深刻了,而且 git 又是开源的,于是特地翻看了 git 的源码,并且在 windows 上用 gdb 简单调试了一波。
说明: 本篇文章适合
geek阅读,全是一些源码查看及编译环境+调试的总结。
git 源码下载
在 github 上找到 git for windows 的仓库,https://github.com/git-for-windows/git,使用如下命令克隆下来即可。
# 说明:可能需要科学上网才能正常克隆
# 如果只想获得最新的提交可以使用下面的命令
git clone --depth 1 https://github.com/git-for-windows/git.git
# 如果想克隆所有提交集,执行下面的命令
git clone https://github.com/git-for-windows/git.git
当然,也可以直接下载压缩包。在 git 仓库的主页的右上侧有一个名为 Code 的按钮,点击后,会弹出一个悬浮框,里面有几个选项,其中一个是 Download ZIP 按钮,点击此按钮即可下载压缩好的代码。
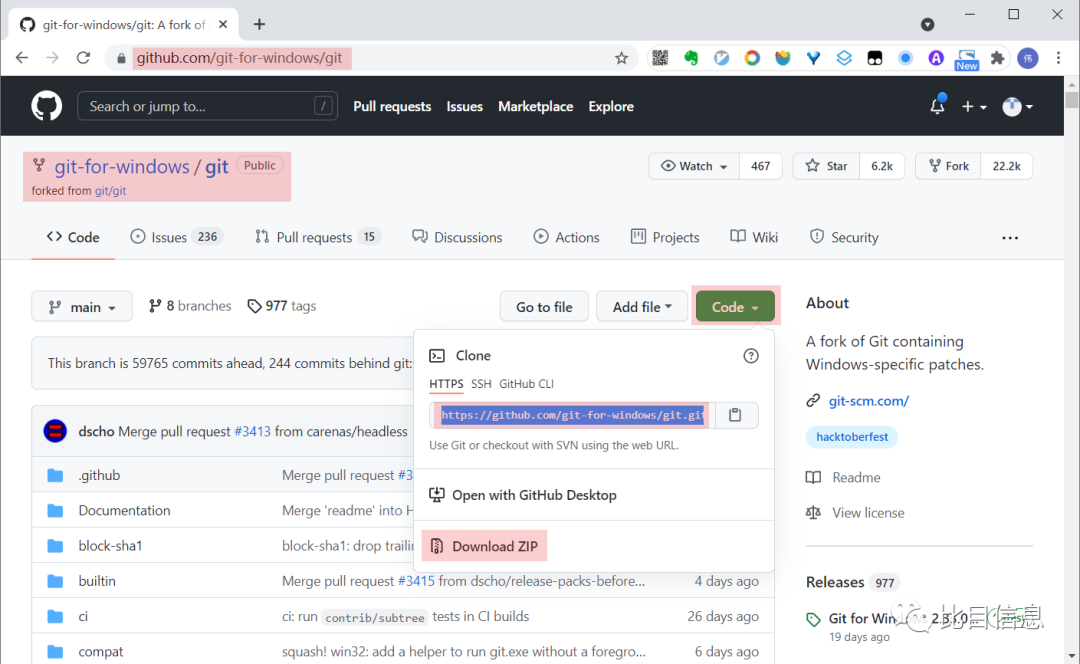
说明:
git-for-windows/gitfork自git/git,也可以从 https://github.com/git/git 下载。如果仅仅想查看代码的话,可以通过此方式下载。如果想调试
git的话,不必在这里手动下载,可以通过后面介绍的sdk init git进行下载。
明确目标
主要有两点疑惑需要解答。
为什么在 .gitattributes中把.rc的working-tree-mode设置成UTF-16LE后,在执行git add的时候会报错,提示设置成UTF-16?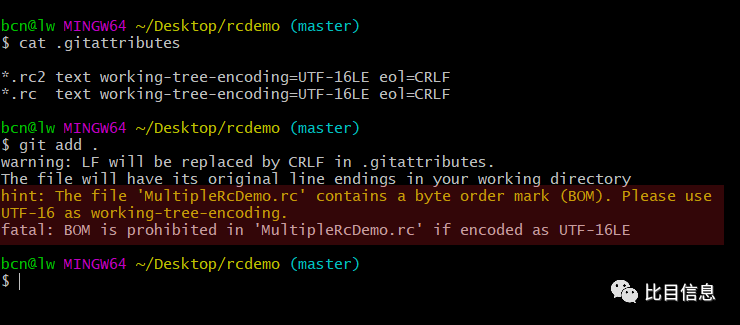
执行 git checkout .的时候,是否会把utf8编码的内容转换成working-tree-encoding中指定的编码格式吗?
查看代码
本以为很简单就能找到关键代码,但是代码复杂度远超过最初的预想。不过好在整个代码组织结构还是非常清楚规范的 —— 基本上每个子命令都有一个对应的 .c 文件,比如 add 对应的文件是 builtin\add.c。对应的功能入口函数名以 cmd_ 开头,加上命令名,比如 add 命令对应的入口函数是 cmd_add。
查看
git add对应的代码执行流程,确认在哪里做的检查,并报的警告。git add命令对应的入口函数是builtin/add.c中的cmd_add。刚开始查看的时候,是从
cmd_add看起的,因为这个是git add对应的入口函数。由于对git源码不熟悉,花费了很长时间,于是转换思路,从报错信息往回找。搜索提示中的关键字contains a byte order mark (BOM).,很快就搜到了关键函数——convert.c中的static int validate_encoding(const char *path, const char *enc, const char *data, size_t len, int die_on_error)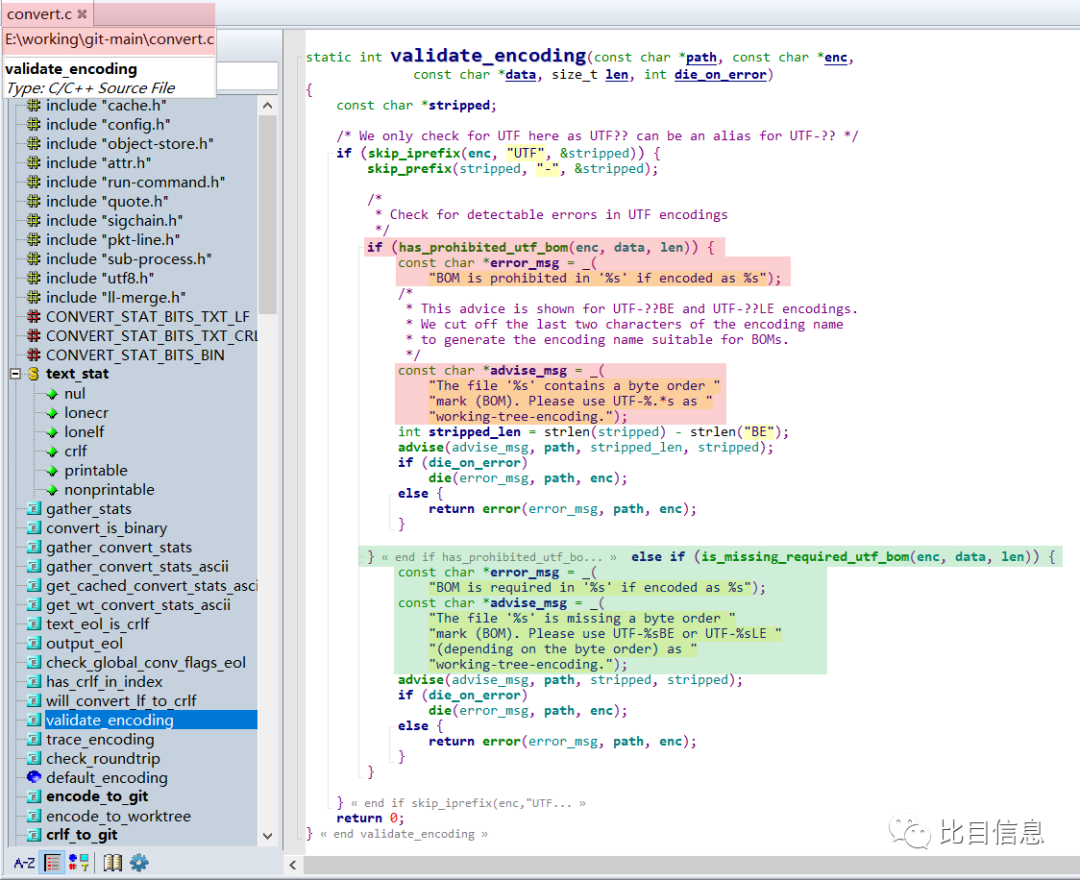
validate_encoding 从代码上看,是进入到了
has_prohibited_utf_bom(enc, data, len)对应的分支中。按住ctrl,用鼠标点击对应的函数,就跳转到了对应函数的实现。对应的实现在utf8.c中。摘录如下: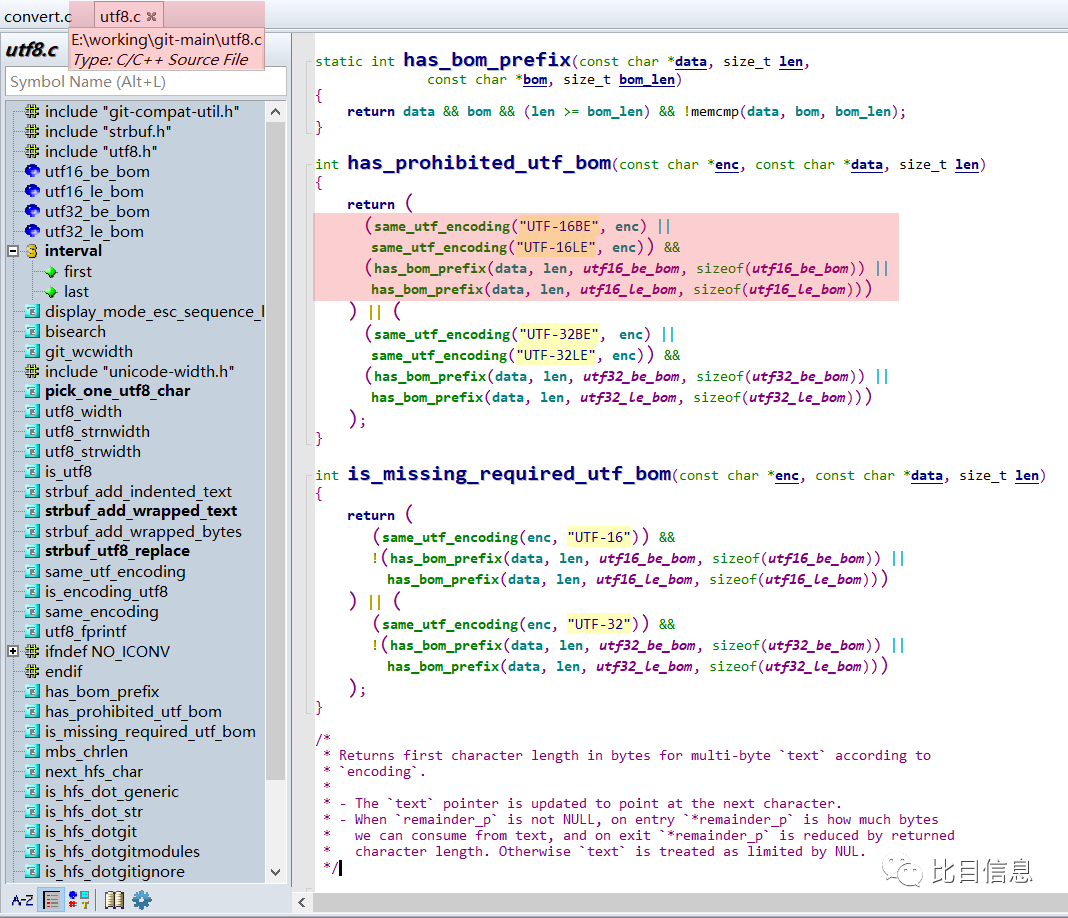
has_prohibited_utf_bom 大概意思是,如果指定了
UTF-16BE或者UTF-16LE(另外一个分支是UTF-32BEUTF-32LE)并且在文件中检测到了对应的BOM头,就报错。对应的BOM头定义如下:static const char utf16_be_bom[] = {'\xFE', '\xFF'};
static const char utf16_le_bom[] = {'\xFF', '\xFE'};
static const char utf32_be_bom[] = {'\0', '\0', '\xFE', '\xFF'};
static const char utf32_le_bom[] = {'\xFF', '\xFE', '\0', '\0'};.rc文件中确实有utf16_be_bom。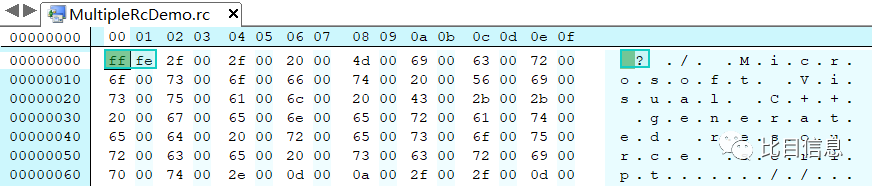
show-rc-bom-header 看来,如果
working-tree-encoding指定为UTF-16LE或UTF-16BE,那么文件中不能包含BOM头。也就是说UTF-16LE/BE对应的文件应该是不包含BOM头的。值得注意的是,
validate_encoding()函数中还做了另外一个判断,也就是is_missing_required_utf_bom()。如果working-tree-encoding指定为UTF-16, 那么必须指定UTF-16LE或者UTF-16BE。找到了最关键的函数,向上找一找谁调用了这个函数,可以在
validate_encoding()上,右键,选择Lookup References...就可以查看所有引用此函数的地方了,后面会多次用到这个方法,这里放一张动态图,后面就不赘述了。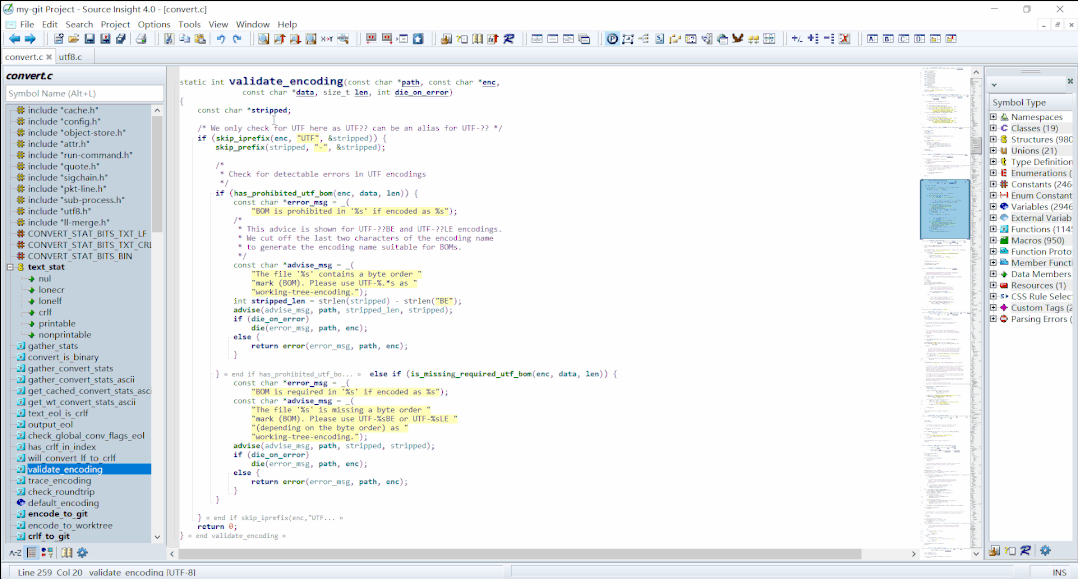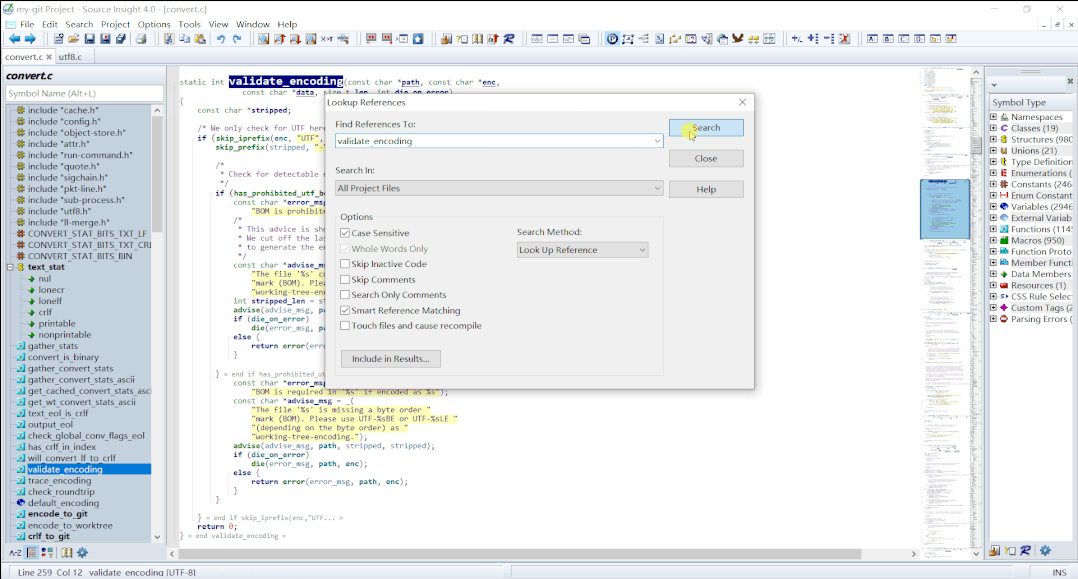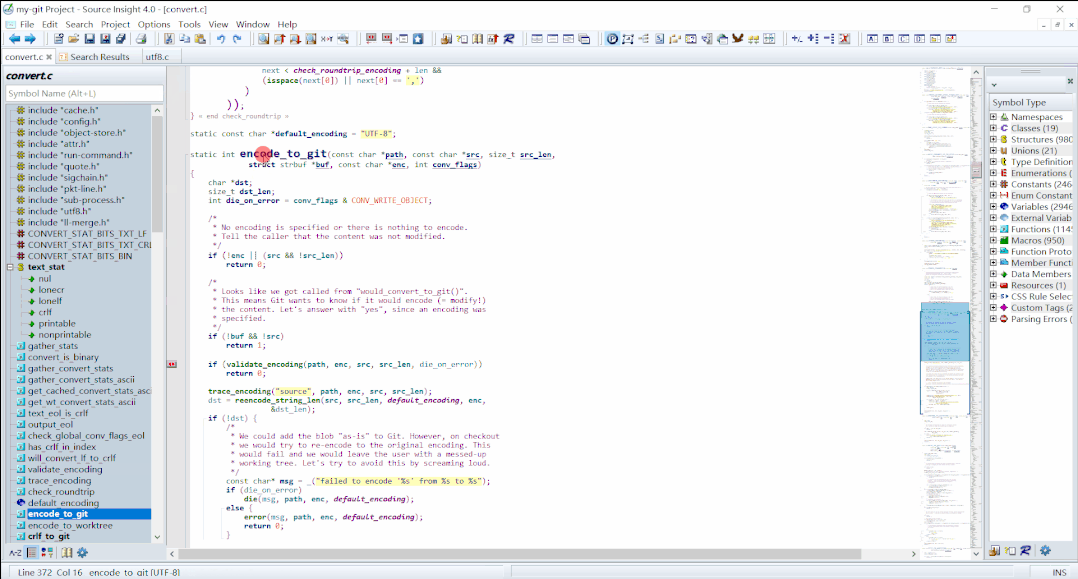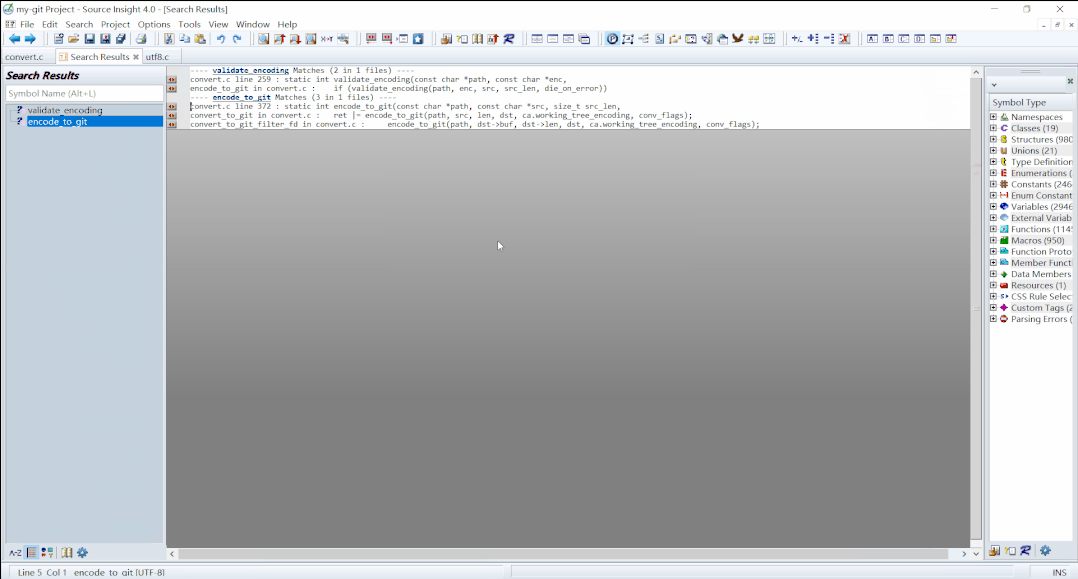
lookup-references 说明:如果已经有了搜索结果,
Source Insight会提示追加还是覆盖。我一般选的是追加。因为调用链比较长,我挑选了一条可能的调用链,如下:
cmd_add() // builtin/add.c
-> add_files() // builtin/add.c
-> add_file_to_index() // read-cache.c
-> add_to_index() // read-cache.c
-> index_path() // object-file.c
-> index_fd() // object-file.c
-> index_stream_convert_blob() // object-file.c
-> convert_to_git_filter_fd() // convert.c
-> encode_to_git() // convert.c
-> validate_encoding() // convert.c整个过程是使用
Lookup References...从下向上查找的。至此,
git add .对应的调用栈就整理出来了。接下来,需要确定的是:在执行git checkout .时,是否会像文档中描述的那样执行编码转换工作?查看
git checkout .的执行流程,确认是否有编码转换相关调用。与
add一样,checkout命令对应的入口函数也在builtin目录下,对应的文件名是checkout.c,对应的入口函数是cmd_checkout。git restore和git switch对应的入口函数的实现也在这个文件中,而且都调用了checkout_main。查找调用函数的过程中,发现在
entry.c中的write_entry()函数中有如下代码片段/*
* Convert from git internal format to working tree format
*/
if (dco && dco->state != CE_NO_DELAY) {
ret = async_convert_to_working_tree_ca(ca, ce->name, new_blob, size, &buf, &meta, dco);
if (ret && string_list_has_string(&dco->paths, ce->name)) {
free(new_blob);
goto delayed;
}
} else {
ret = convert_to_working_tree_ca(ca, ce->name, new_blob, size, &buf, &meta);
}根据注释可以猜测,这个是把内部存储格式转换成工作目录所需的格式。
最后一个函数是
reencode_string_len(),对应的实现如下: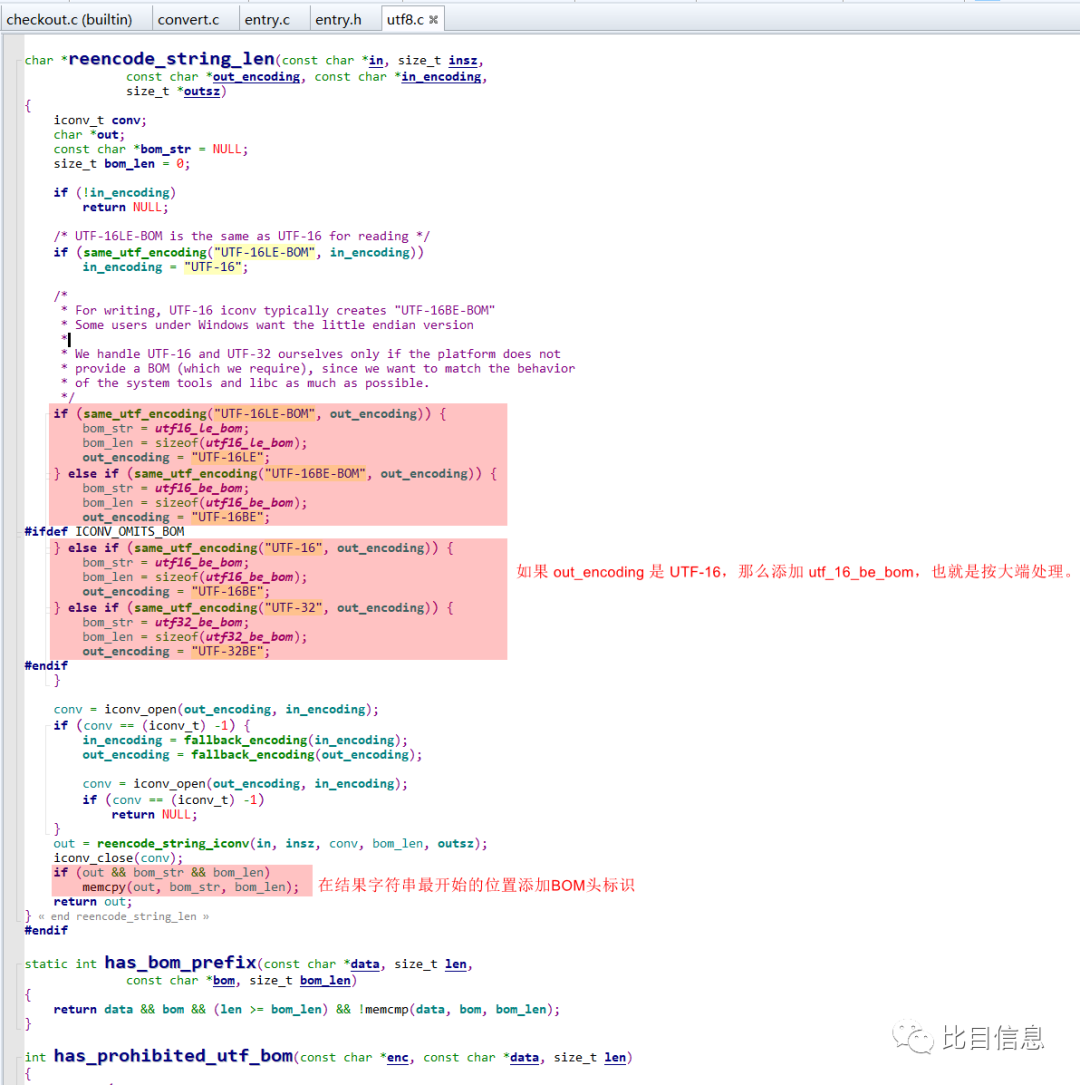
reencode_string_len 可以很明显的发现,
reencode_string_len()在处理out_encoding是UTF-16的时候,直接按大端进行转换。这就是为什么.rc文件的working_tree_encoding设置为UTF-16时,执行git checkout .后,文件编码变成UTF-16BE BOM的原因了。手动整理的调用链如下:
cmd_checkout() // builtin/checkout.c
-> checkout_main() // builtin/checkout.c
-> checkout_paths() // builtin/checkout.c
-> checkout_worktree() // builtin/checkout.c
-> checkout_entry() // builtin/checkout.c
-> checkout_entry_ca() // builtin/checkout.c
-> write_entry() // entry.c
-> convert_to_working_tree_ca() // entry.c
-> convert_to_working_tree_ca_internal() // entry.c
-> encode_to_worktree() // convert.c
-> reencode_string_len() // utf8.c
代码看完了,准确的说应该是猜完了。但是 git 在实际运行的时候是按照上面的流程执行的吗?万一猜错了呢?为了进一步落实打破沙锅问到底的精神,而且作为一个调试爱好者,不通过调试手段确认一下,总觉得是不踏实。而且有源码,不调试一波,实在是浪费。于是,花了半天左右的时间,根据官方文档的提示,趟出了一条调试 git 的路,验证了自己的猜想,踏实!这下能睡个安稳觉了。
调试环境搭建 & 编译
windows并没有自带gdb调试工具。安装好git sdk后,可以在安装目录下找到gdb.exe。能在windows下用linux调试神器,真香!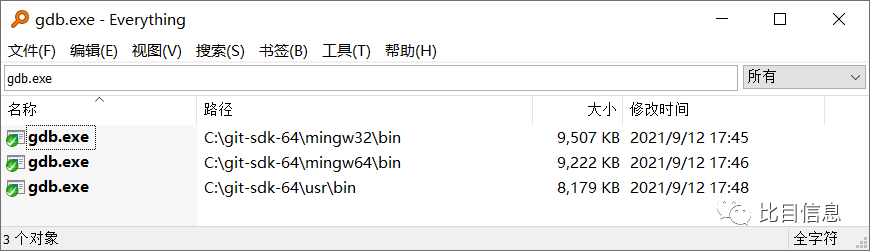
search-gdb-in-disk 从 网上下载的
git应该是release版,不带调试符号。如果直接调试设置断点的话,gdb会报错,提示找不到符号表。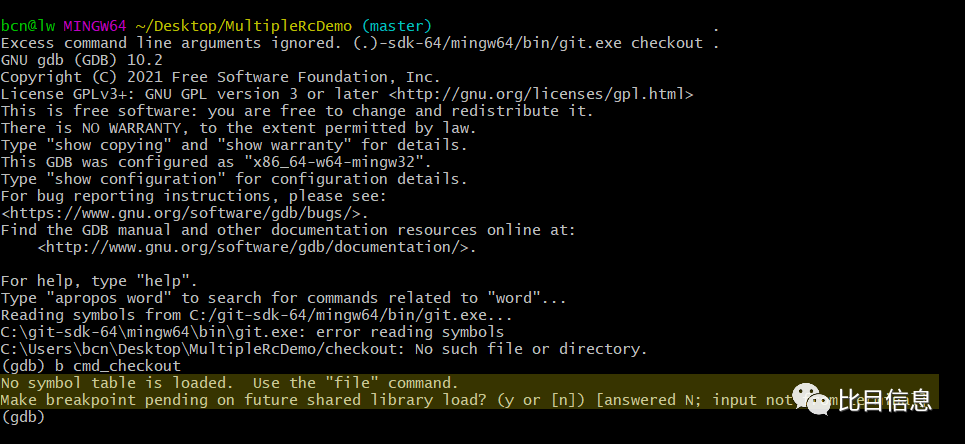
no-symbol-table-load
整个环境搭建过程参照 https://github.com/git-for-windows/git/wiki/Technical-overview 和 https://github.com/git-for-windows/git/wiki/Debugging-Git 进行。
我把整个过程整理如下:
先到下载页面下载
git sdk,我下载的是 64 位 的git-sdk-installer-1.0.8-64.7z.exe。下载好
git sdk安装包后,以管理员权限运行。运行成功后,执行
sdk init git(执行此命令可以帮我们下载git源码,就可以省去手动下载源码的步骤了)。
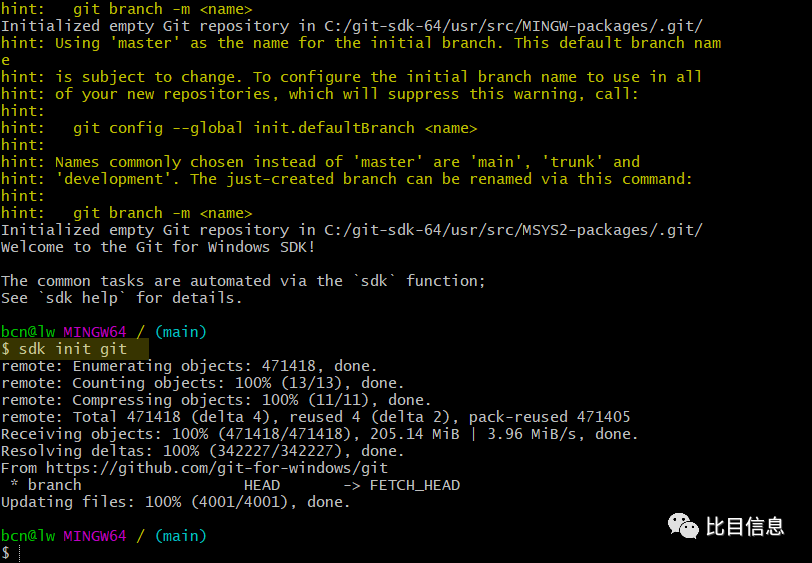
**说明:**在执行
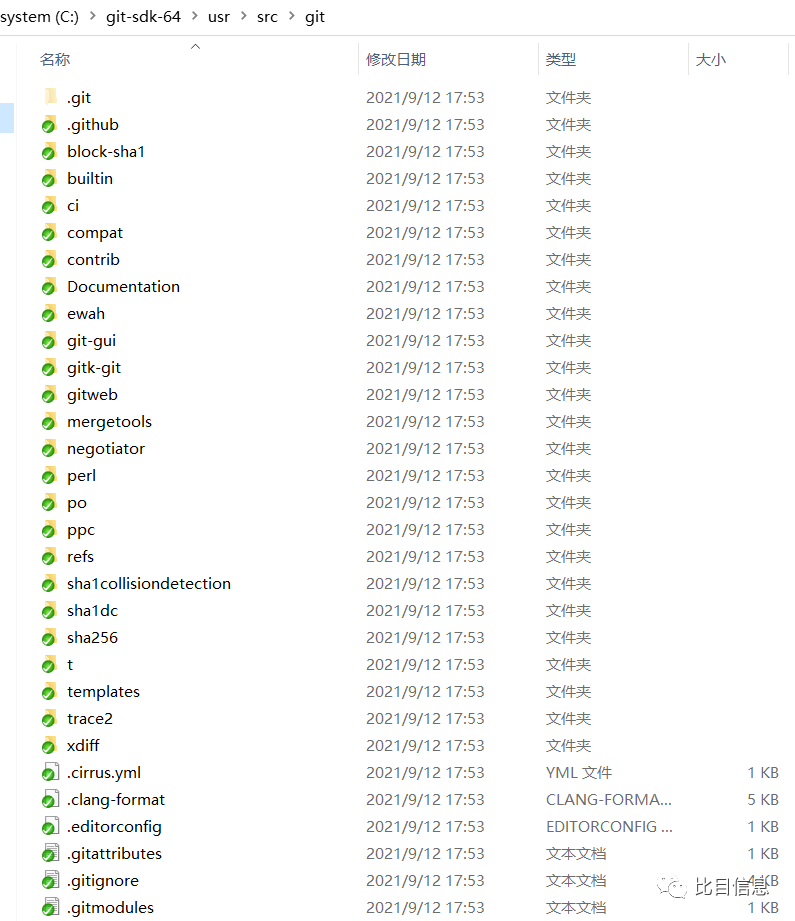
sdk init git之前,目录C:\git-sdk-64\usr\src\git\里面没有源码,执行完sdk init git,这个目录下包含了git的源码文件(带完整历史记录)。如下图:
修改
C:\git-sdk-64\usr\src\git\config.mak文件的文件内容为如下形式:DEVELOPER=1
ifndef NDEBUG
CFLAGS := $(filter-out -O2,$(CFLAGS))
ASLR_OPTION := -Wl,--dynamicbase
BASIC_LDFLAGS := $(filter-out $(ASLR_OPTION),$(BASIC_LDFLAGS))
endif默认下载完之后的内容如下,如果在后续步骤执行
cd usr/src/git && make install的时候什么也没干就结束了的话,可以删除第二行,再试。DEVELOPER=1
SKIP_DASHED_BUILT_INS=YesPlease
ifndef NDEBUG
CFLAGS := $(filter-out -O2,$(CFLAGS))
ASLR_OPTION := -Wl,--dynamicbase
BASIC_LDFLAGS := $(filter-out $(ASLR_OPTION),$(BASIC_LDFLAGS))
endif双击
C:\git-sdk-64\下的git-bash.exe,然后执行cd usr/src/git切换到git目录。注意: 输入的是
linux中的路径分隔符/而不是windows中的路径分隔符\。执行
make install,就可以开始编译了。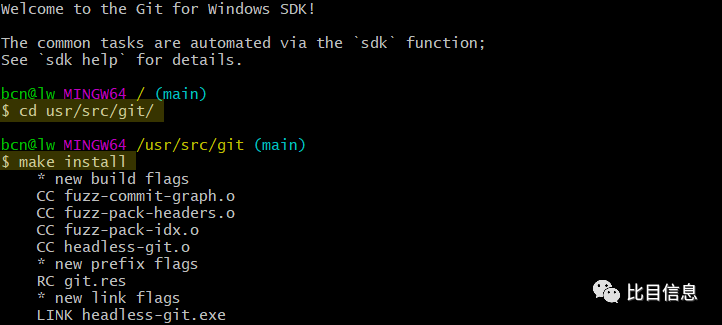
open-sdk-cd-to-usr-src-git-and-make-install 编译结束后,如果一切正常就生成了带符号的
git.exe。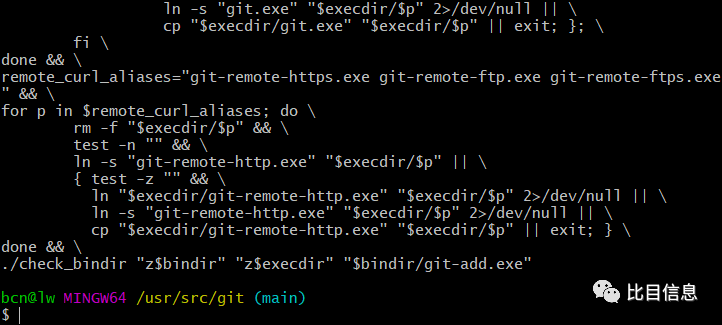
build-success 说明:
生成的 git.exe及几个其它.exe文件会被自动拷贝到C:\git-sdk-64\mingw64\bin\目录下,还会拷贝一些其它文件到对应目录下。可以通过git status查看。虽然生成的是
.exe文件,但是并不会同时生成一个git.pdb文件。生成的文件会在
C:\git-sdk-64\usr\src\git下,但是并不能直接执行此目录下的文件,如果直接执行会报错。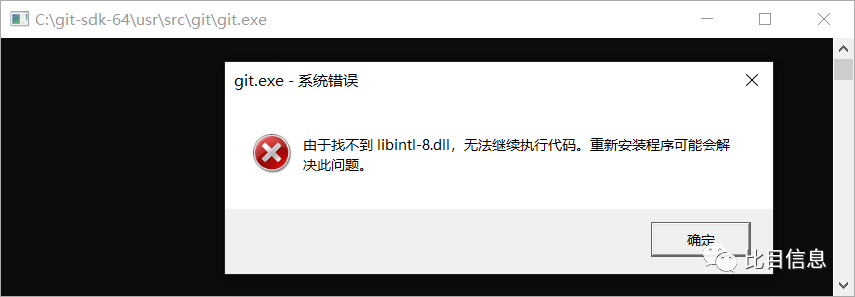
start-git-under-usr-src-git-failed 
newly-built-exe-with-debug-info 使用
gdb调试git。大体用法如下:# debug git checkout .
C:/git-sdk-64/mingw64/bin/gdb.exe --args C:/git-sdk-64/mingw64/bin/git.exe git_cmd options
至此,调试环境已经完全搭建好了,可以开心的调试了。
首先,查看 git add . 的调用过程,明确关键检查逻辑。
明确 git add 逻辑
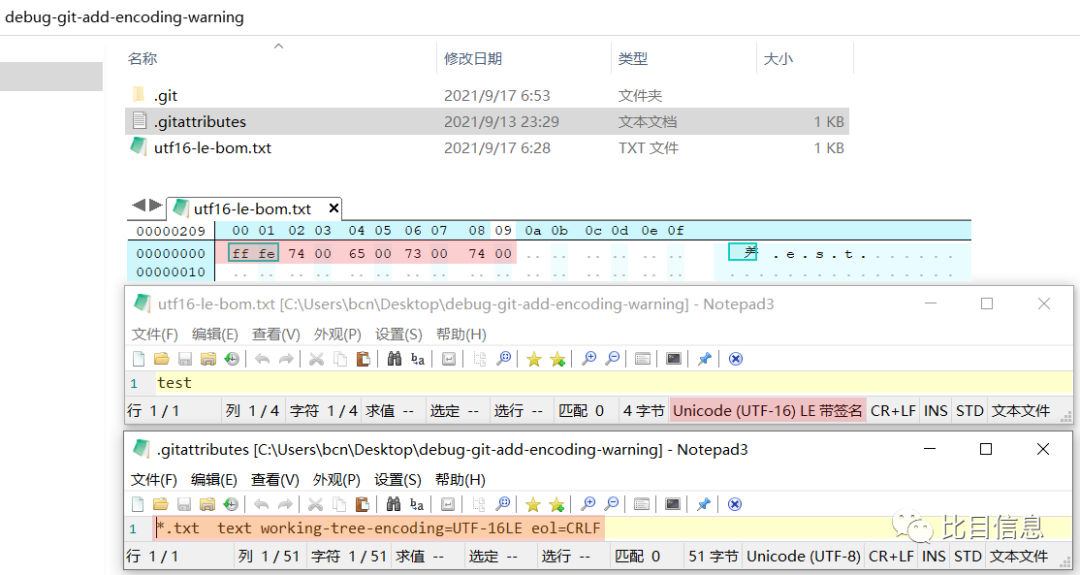
在调试之前,先建立一个简单的测试环境。建立一个 UTF-16LE BOM 编码的文件 utf-l6le-bom.txt,并编辑其内容为 test。设置 .gitattributes 的 working-tree-encoding 为 UTF-16LE,然后执行 git init 初始化仓库,然后就可以使用 gdb 调试 git add . 了。
在打开的 shell 终端中输入如下命令 C:/git-sdk-64/mingw64/bin/gdb.exe --args C:/git-sdk-64/mingw64/bin/git.exe add . 。如果成功,会像下图这样。
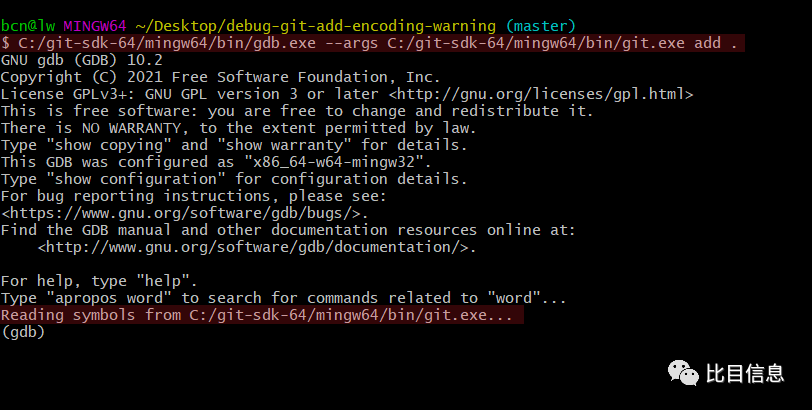
接着为函数 validate_encoding 设置断点,在 gdb 中输入 b validate_encoding(b 是 break 的缩写),提示设置成功后,输入 r (run)使程序重新运行起来。这时候程序应该中断下来了。
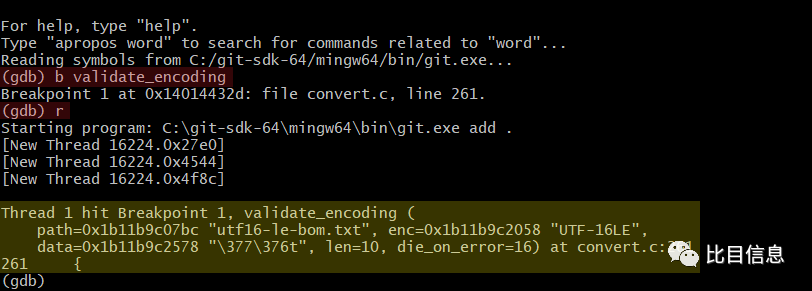
从上图可知,path 的值是 utf16-le-bom.txt,是需要 add 的文件,enc 的值是 UTF16-LE,是 working-tree-encoding 中指定的值。data 应该指向了 utf16-le-bom.txt 中的内容,len 指的是 data 的长度。查看一下 data 的具体内容。
在 gdb 中可以使用 x 命令可以查看内存中的数据(如果对 gdb 命令不不熟悉,可以输入 help cmd,即可查看对应命令的帮助了),输入 x/10bx data 即可查看从 data 开始的 10 个字节的内容了。
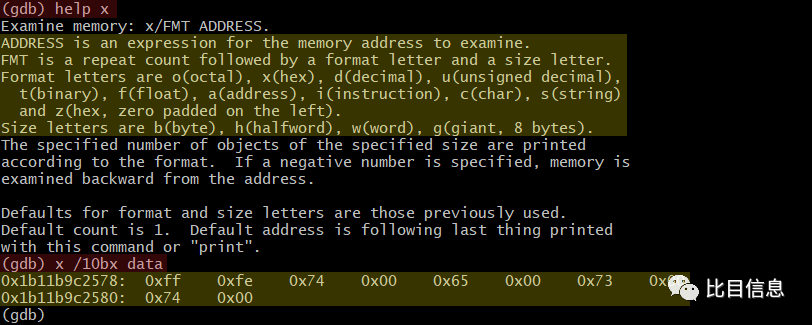
可以看到,文件内容是 UTF-16LE BOM 存储的,与磁盘上的文件内容一致。最后,看一下调用栈与之前查看源码时猜测的调用栈是否一样。输入 bt(backtrace)即可查看调用栈。
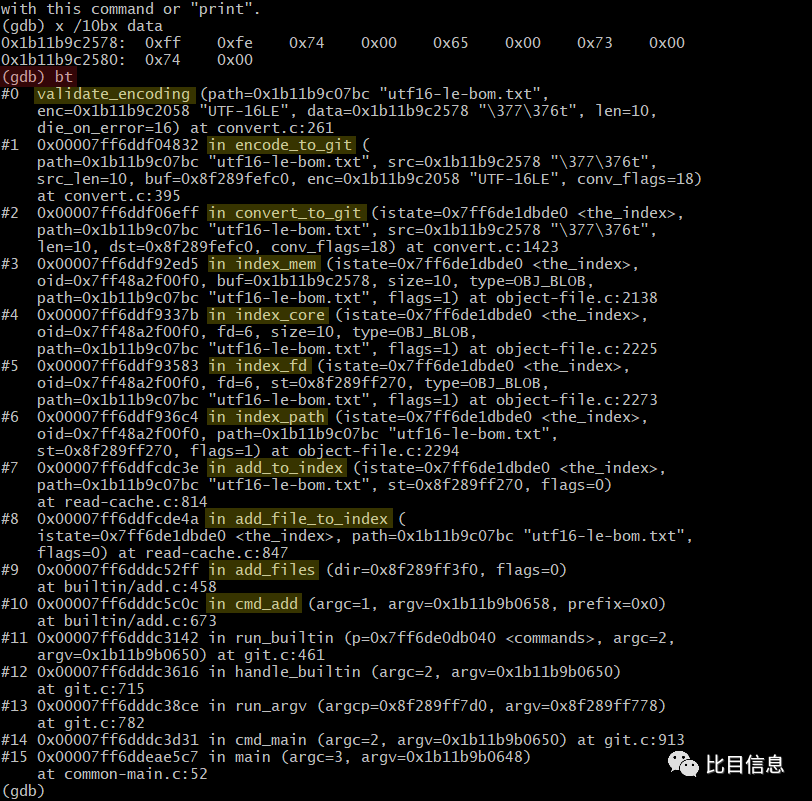
中间一些执行不太一样,不过也差不多,通过源码猜的调用栈应该是在其它情况下运行的。至此,执行 git add 时所做的编码格式检查就检查完了。
接下来,要明确的是执行 git checkout . 的时候是否会调用到编码转换的函数中去,具体传递的参数是什么?
明确 git checkout 逻辑
首先,建立一个 UTF-16LE BOM 编码的文件 utf-l6le-bom.txt,并编辑其内容为 test。设置 .gitattributes 的 working-tree-encoding 为 UTF-16,然后执行 git init && git add . && git commit -m "init"。
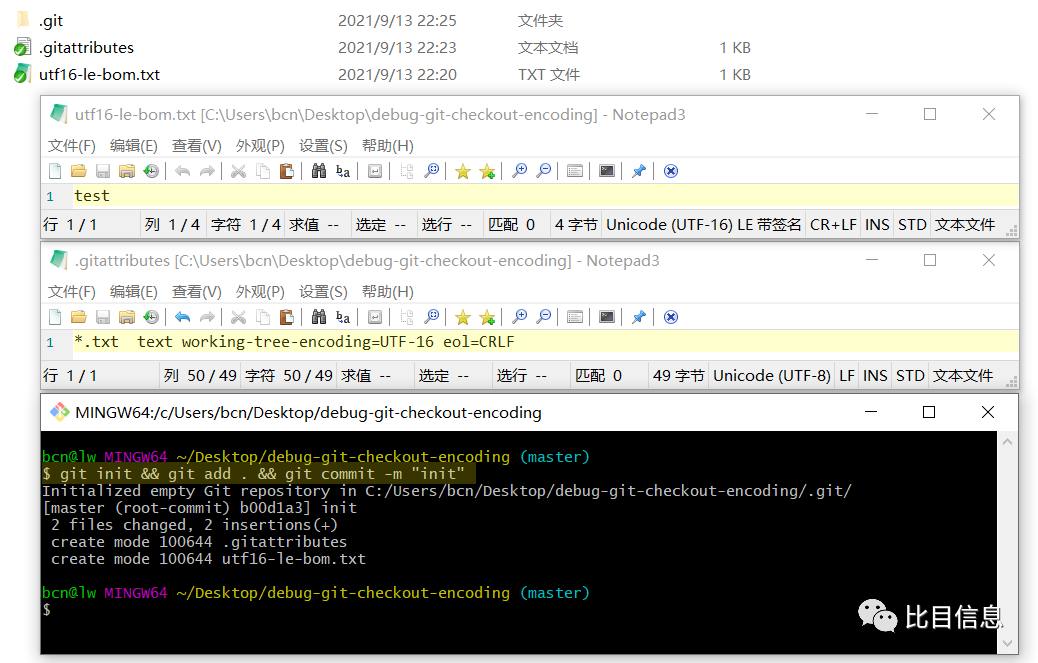
然后修改 utf-16le-bom.txt 的内容为 test1,然后就可以使用 gdb 调试 git checkout . 命令了。
在打开的 shell 终端中输入如下命令
C:/git-sdk-64/mingw64/bin/gdb.exe --args C:/git-sdk-64/mingw64/bin/git.exe checkout .
这里就不贴图了,具体参考上面调试 git add 命令时的贴图。
接着为函数 reencode_string_len 设置断点,在 gdb 中输入 b reencode_string_len,提示设置成功后,输入 r 使程序重新运行起来。这时候程序应该中断下来了。
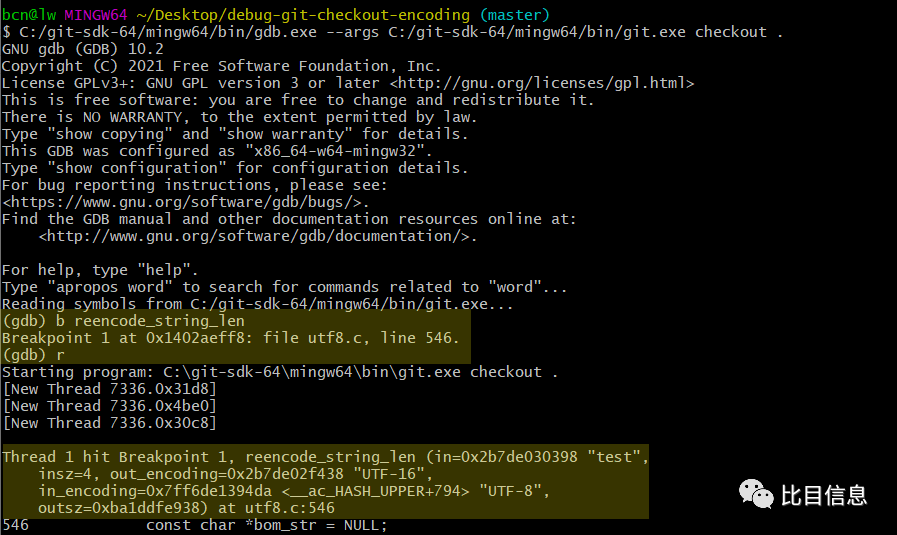
从图中高亮部分可知,关键参数和我们想的一样。in 是 test,也就是第一次提交的内容。insz 是 4,表示传入字符串的长度。out_encoding 是 UTF-16(working-tree-encoding 中指定的编码,写文件到磁盘上的编码)。in_encoding 是 UTF-8( git 内部存储数据时使用的编码)。outsz 保存了传出字符串的长度。结果字符串通过返回值返回。
输入 bt 查看调用栈,如下:
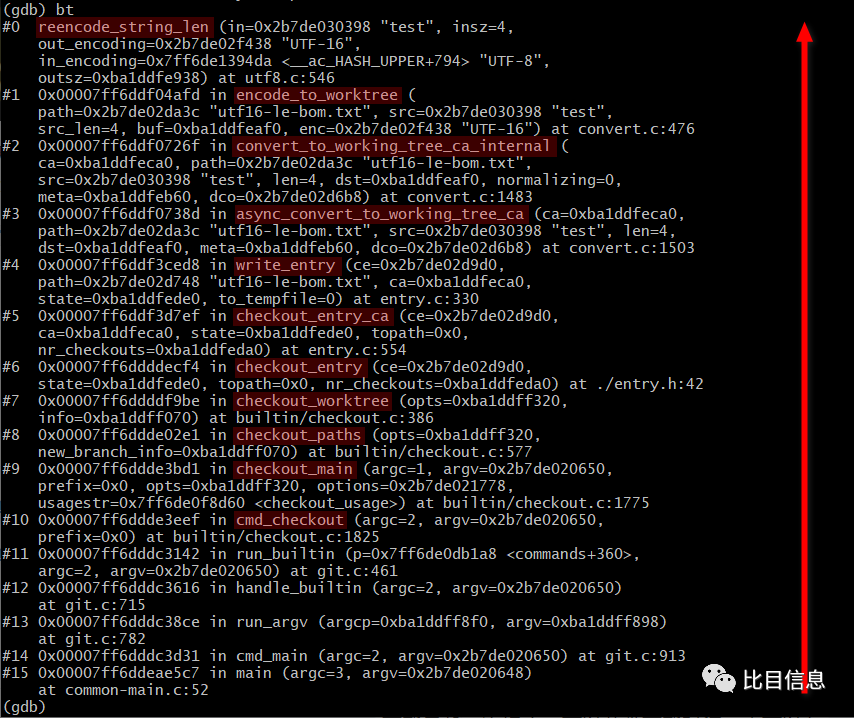
跟之前通过查看源码猜测的完全一样!(我这里只高亮了函数名,在每帧的结尾处,gdb 为我们列出了该函数所在的文件及对应的行数)。
输入 fi (finish) 结束当前函数的运行,观察返回值(返回值保存了转码后的字符串)。有汇编基础的小伙伴儿都知道,一般返回值是放在 rax 中的。输入 x/10x $rax 即可按十六进制显示从 $rax 开始的 10 个字节了,如下图:

可以看到,前两个字节是大端 BOM 头(0xFE 0xFF,小端 BOM 头是 0xFF 0xFE)。执行完命令后,使用十六进制查看器观察到的文件内容与调试时看到的一样,说明把编码转换后的内容写入到了磁盘中。checkout 后,磁盘文件内容下图所示:

如果在调试过程中想查看相关源码,可以输入 l (list) 进行查看。下图是执行 f 0 (frame 0) 切换到 0 号栈帧后,再通过 l 命令查看源码的截图。
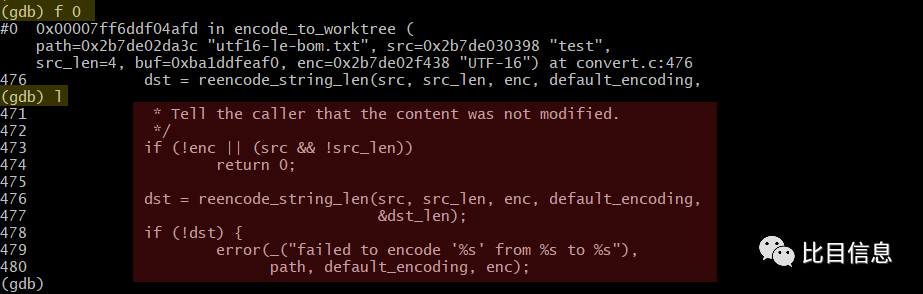
至此,这两个疑惑都得到了圆满的解答!
参考资料
https://github.com/git-for-windows/git/wiki/Technical-overview
https://github.com/git-for-windows/git/wiki/Debugging-Git
https://blog.csdn.net/qq_28351609/article/details/114855630
总结
可以通过 git clone --depth 1 git_repository_url下载最新一次提交,可以节省下载时间。也可以在github上通过Download ZIP按钮下载打好包的源码。Source Insight真是查看代码的神器,尤其是Lookup References...(快捷键是ctrl + /),可以非常方便的查看引用。按住ctrl后,鼠标点击函数可以跳转到函数定义的地方。gdb是linux调试神器。使用b可以设置断点,bt可以查看调用栈,f N可以切换到N号栈帧,x可以查看内存中的数据,i可以查看一些信息,r可以让程序重新运行起来(类似于windbg中的g或者F5),l可以列出相关的源码。working-tree-encoding与文件编码的对应关系我总结到下面的表格中了,供大家参考。
| working-tree-encoding | 签出时的文件编码 | git add 时支持的编码 | 说明 |
|---|---|---|---|
| UTF-16LE | UTF-16 Little Endian (No BOM) | UTF-16 Little Endian (No BOM) | 文件不能带 BOM |
| UTF-16BE | UTF-16 Big Endian (No BOM) | UTF-16 Big Endian (No BOM) | 文件不能带 BOM |
| UTF-16LE-BOM | UTF-16 Little Endian (With BOM) | UTF-16 Little Endian (With BOM) | 需要带 BOM |
| UTF-16BE-BOM | UTF-16 Big Endian (With BOM) | UTF-16 Big Endian (With BOM) | 需要带 BOM |
| UTF-16 | UTF-16 Big Endian (With BOM) | UTF-16 Big(Little) Endian (With BOM) | 需要带 BOM。虽然接受 UTF-16 Little Endian,但是签出时会按 UTF-16 Big Endian处理!会导致编码改变。 |