
【机器学习】特征工程的这些基本功你都会了吗
1引言
特征是什么?为什么需要工程设计?
基本上,所有机器学习算法都是将一些输入数据转化为输出。这些输入数据包括若干特征,通常是以由列组成的表格形式出现。
而算法往往要求输入具有某些特性的特征才能正常工作。因此,出现了对特征工程的需求。
特征工程至少有两个目标,
构建适合机器学习算法要求的输入数据。 改善机器学习模型的性能。
根据《福布斯》的一项调查,数据科学家把 80% 左右的时间花在数据收集、清晰以及预处理等数据准备上。
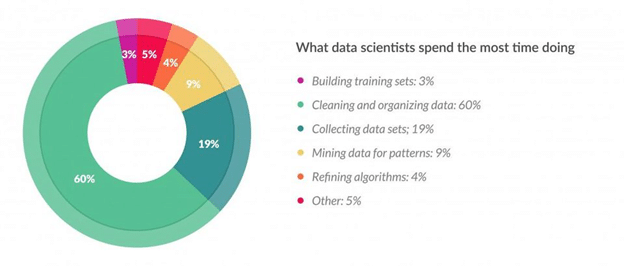
这点显示了特征工程在数据科学中的重要性。因此有必要整理一下特征工程的主要技术。本篇通过 Pandas 和 Numpy 等库来实际操练。
import pandas as pd
import numpy as np
获得特征工程专业知识的最佳方法是对各种数据集试验不同的技术,并观察其对模型性能的影响。
本文主要介绍以下几个方面,
1、数据插补 2、处理异常值 3、分箱操作 4、对数转换 5、独热编码 6、分组操作 7、特征拆分 8、缩放操作 9、日期处理
2数据插补
缺失值是为机器学习准备数据时可能遇到的最常见问题之一。缺少值的原因可能是人为错误、数据流中断、隐私问题等。无论是什么原因,缺少值都会影响机器学习模型的性能。
一般来说,机器学习算法不接受包含缺失值的输入,而有一些机器学习平台会自动删除包含缺失值的行,但这样做往往会降低模型性能。
处理缺失值的最简单方案是删除行或整个列。没有最佳的删除阈值,但是可以使用 70% 作为阈值,并尝试删除缺失值高于此阈值的行和列。
threshold = 0.7
# Dropping columns with missing value rate higher than threshold
data = data[data.columns[data.isnull().mean() < threshold]]
# Dropping rows with missing value rate higher than threshold
data = data.loc[data.isnull().mean(axis=1) < threshold]
.数值插补
缺失值插补法,与缺失值删除法比较起来是一个更好的选择,至少它可以保持数据的规模不变。但是,插补法需要考虑插补什么值。
首先,你可以考虑列中缺失的默认值。例如,你有一列仅有 1 和 nan,行中的 nan 可能就是 0。另一个例子,你有一个列表示上个月客户访问的次数,缺失值可能也是 0。
产生缺失值的另一个原因是在连接大小不同的表时格引入的,此时插补 0 也可能是个合理的做法。
除了用默认值插补缺失值外,还有一个比较有效的做法就是使用列的中位数插补缺失值,而不是平均值,因为中位数比均值更为稳健。
# Filling all missing values with 0
data = data.fillna(0)
# Filling missing values with medians of the columns
data = data.fillna(data.median())
.类别插补
用列中出现次数最多的值替换缺失值是处理类别型数据时的一个不错的选择。但是,如果该列中的值是均匀分布的,则使用 Other 类别插补可能更加合理。
# Max fill function for categorical columns
data['column_name'].fillna(data['column_name'].value_counts().idxmax(), inplace=True)
3处理异常值
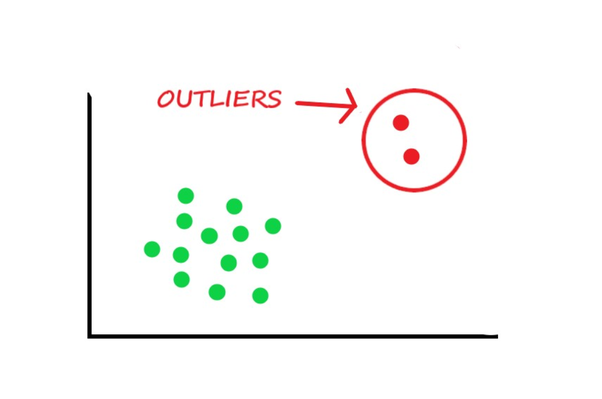
在提到如何处理异常值之前,检测异常值的最佳方法是直观地展示数据。所有其他统计方法都容易犯错误,而将异常值可视化则有机会进行高精度的决策。
正如我所提到的,统计方法不够精确,但另一方面,它们却具有优势,而且速度很快。在这里,我将列出两种处理异常值的不同方法。这些将使用标准差和百分位来检测异常值。
.基于标准差的异常值检测
如果某个值与平均值的距离大于
# Dropping the outlier rows with standard deviation
factor = 3
upper_lim = data['column'].mean () + data['column'].std () * factor
lower_lim = data['column'].mean () - data['column'].std () * factor
data = data[(data['column'] < upper_lim) & (data['column'] > lower_lim)]
此外,可以使用
.基于百分位的异常值检测
检测异常值的另一种统计方法是使用百分位。你可以从顶部或底部划分某些区间中的值作为异常值。这再次需要设置百分比这个阈值,这取决于数据分布。
此外,一个常见的错误是根据数据范围使用百分位。换句话说,如果你的数据范围是 0 到 100,则前 5% 的值不是 96 到 100 之间的值。这里的前 5% 表示值不在数据量的第 95 个百分点之内。

# Dropping the outlier rows with Percentiles
upper_lim = data['column'].quantile(.95)
lower_lim = data['column'].quantile(.05)
data = data[(data['column'] < upper_lim) & (data['column'] > lower_lim)]
.设限与丢弃
处理异常值的另一种方法是将其设置为上限,而不是丢弃。这样做可以保留数据规模,并且对于最终模型性能来说可能会更好。
另一方面,设上限封顶可能会影响数据的分布,因此也不要过于吹捧它。
# Capping the outlier rows with Percentiles
upper_lim = data['column'].quantile(.95)
lower_lim = data['column'].quantile(.05)
data.loc[(df[column] > upper_lim), column] = upper_lim
data.loc[(df[column] < lower_lim), column] = lower_lim
4分箱
分箱可以应用于类别型数据和数值型数据。
# Numerical Binning Example
Value Bin
0-30 -> Low
31-70 -> Mid
71-100 -> High
# Categorical Binning Example
Value Bin
Spain -> Europe
Italy -> Europe
Chile -> South America
Brazil -> South America
分箱的主要动机是使模型更加健壮并防止过拟合,但同时也会降低性能。每次分箱不仅会牺牲信息,也会使得数据更加规范化。
性能与过拟合之间的权衡是分箱过程的关键。
对于数值型特征,除了一些明显的过拟合的情况外,分箱对于某种算法可能是多余的,因为它对模型性能有影响。 然而,对于类别型特征,低频标签可能会对统计模型的鲁棒性产生负面影响。因此,为这些不太频繁的值分配一般类别有助于保持模型的鲁棒性。例如,数据大小为 100,000 行,则将计数少于 100 的标签合并到 Other之类的新类别可能是一个不错的选择。
# Numerical Binning Example
data['bin'] = pd.cut(data['value'], bins=[0,30,70,100], labels=["Low", "Mid", "High"])
value bin
0 2 Low
1 45 Mid
2 7 Low
3 85 High
4 28 Low
# Categorical Binning Example
Country
0 Spain
1 Chile
2 Australia
3 Italy
4 Brazil
conditions = [
data['Country'].str.contains('Spain'),
data['Country'].str.contains('Italy'),
data['Country'].str.contains('Chile'),
data['Country'].str.contains('Brazil')]
choices = ['Europe', 'Europe', 'South America', 'South America']
data['Continent'] = np.select(conditions, choices, default='Other')
Country Continent
0 Spain Europe
1 Chile South America
2 Australia Other
3 Italy Europe
4 Brazil South America
5Log 对数变换
对数变换是特征工程中最常用的数学变换之一,它的好处有,
它有助于处理偏度不为 0 的数据,并且在转换后,分布变得更接近正态分布。 在大多数情况下,数据的数量级在不同范围内是不同的。例如,年龄 15 和 20 之间的数量差异并不等于年龄 65 和 70 之间的数量差异。就年份而言,是的,它们是相同的,但是对于其他方面,年轻年龄的 5 年差异意味着更高的数量差异。这种类型的数据来自乘性过程,对数变换将起到规范化(normalize)数量差异的作用。
由于数量差异的归一化,模型变得更加健壮,因此它也减少了异常值的影响。
需要注意的是,你要应用对数变换的数据必须是正值,否则会出现错误。另外,可以在转换数据之前将 1 加到数据中,用于确保变换后的输出值也是正的。
Log(x+1)
# Log Transform Example
data = pd.DataFrame({'value':[2,45, -23, 85, 28, 2, 35, -12]})
data['log+1'] = (data['value']+1).transform(np.log)
# Negative Values Handling
# Note that the values are different
data['log'] = (data['value']-data['value'].min()+1) .transform(np.log)
value log(x+1) log(x-min(x)+1)
0 2 1.09861 3.25810
1 45 3.82864 4.23411
2 -23 nan 0.00000
3 85 4.45435 4.69135
4 28 3.36730 3.95124
5 2 1.09861 3.25810
6 35 3.58352 4.07754
7 -12 nan 2.48491
6独热编码
独热编码是机器学习中最常见的编码方法之一。此方法将一列中的值分布到多个标记列,并为其分配 0 或 1。这些二进制值表示类别和编码之间的关系。
该方法将算法难以正确理解的分类型数据更改为数值格式,并使你可以在不丢失任何信息的情况下对类别数据进行分组。

.Why 独热编码?
如果该列中有 N 个不同的值,则将它们映射到 N-1 个二进制列就足够了,因为可以从其他列中扣除该缺失值。如果我们手中的所有列都等于 0,则缺失值必须等于 1。这就是为什么将其称为独热编码的原因。但是,我将使用 Pandas 的 get_dummies 函数给出一个示例,此函数将一列映射到多个列。
encoded_columns = pd.get_dummies(data['column'])
data = data.join(encoded_columns).drop('column', axis=1)
7分组操作
在大多数机器学习算法中,每个实例对应训练数据集中的一行,而不同列对应不同特征。这种形式的数据称为整齐(tidy)数据。
整齐数据集易于操作、建模和可视化,并具有特定的结构: 每个变量是一列,每个观察值是一行,每种类型的观察单位是表格。
诸如涉及事务处理之类的数据集由于一个实例对应多行数据而很少适合整齐数据的定义。在这种情况下,我们按实例对数据进行分组,然后每个实例仅由一行代表。
按操作分组的关键是确定特征的聚合函数。对于数值型特征,平均值和求和函数通常是不错的选择,而对于分类型特征,则较为复杂。
.分类特征分组
建议使用三种不同的方式来聚合分类特征:
第一种是选择频率最高的标签。换句话说,这是分类特征的 max 操作,但是普通的 max 函数通常不返回此值,因此你需要自己定义,例如使用 lambda 函数。
data.groupby('id').agg(lambda x: x.value_counts().index[0])
第二种选择是制作数据透视表(pivot table)。这种方法与上一步骤中的编码方法类似,略有不同。代替二值符号,可以将其定义为分组列和编码列之间的值的聚合函数。如果你打算超越二值标记列并将多重特征合并为更有用的聚合特征,那么这将是一个不错的选择。(该方法与 Pandas 中另一个函数 groupby 作用类似,可以结合下图例子来理解这一点。)
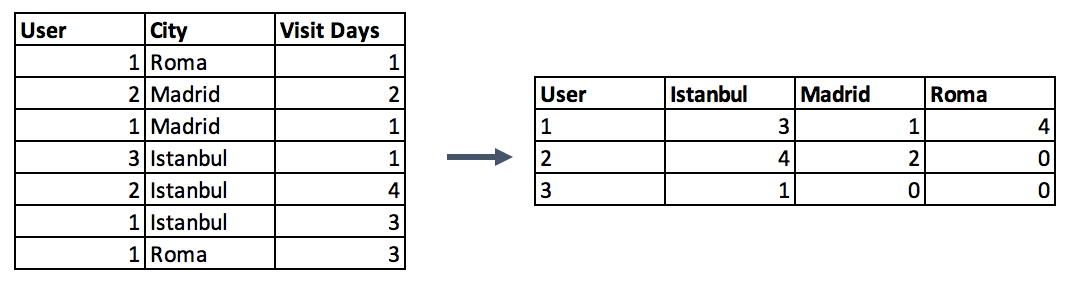
# Pivot table Pandas Example
data.pivot_table(index='column_to_group', columns='column_to_encode', values='aggregation_column', aggfunc=np.sum, fill_value = 0)
最后一种分类特征分组方案是在应用独热编码后应用分组函数 group by。此方法将保留所有数据(在上面第一种方案中,会丢失一些数据)。与此同时,还将编码列从分类转换为数值。可以阅读下一部分以了解数值特征分组的说明。
.数值特征分组
在大多数情况下,数值特征使用求和以及均值函数分组。根据特征的含义,两者都是可取的。例如,如果要获取比率列,则可以取二值列的平均值。在同一示例中,sum 函数可用于获得总数。
# sum_cols: List of columns to sum
# mean_cols: List of columns to average
grouped = data.groupby('column_to_group')
sums = grouped[sum_cols].sum().add_suffix('_sum')
avgs = grouped[mean_cols].mean().add_suffix('_avg')
new_df = pd.concat([sums, avgs], axis=1)
8特征拆分
拆分特征是使它们在机器学习中发挥作用的好办法。很多时候,数据集包含一些字符串列,这就违反了整齐数据的原则。通过将列的可用部分提取成新特征,有利于
让机器学习算法能够理解它们。 可以将它们分箱和分组。
通过发掘潜在信息来提高模型性能。
split 函数是一个不错的选择,但是,没有一种适用于拆分所有特征的通用方法。它取决于列的特性以及如何拆分它。让我们通过两个示例对其进行介绍。
首先,一个可用于拆分普通名字列的简单 split 函数,
data.name
0 Luther N. Gonzalez
1 Charles M. Young
2 Terry Lawson
3 Kristen White
4 Thomas Logsdon
# Extracting first names
data.name.str.split(" ").map(lambda x: x[0])
0 Luther
1 Charles
2 Terry
3 Kristen
4 Thomas
# Extracting last names
data.name.str.split(" ").map(lambda x: x[-1])
0 Gonzalez
1 Young
2 Lawson
3 White
4 Logsdon
上面的示例通过仅使用第一个和最后一个词来处理长度超过两个单词的名字,这使该函数在遇到极端情况时具有鲁棒性,在处理此类字符串时应考虑到这一方法。
split 函数的另一个使用场景是提取两个字符之间的字符串部分。以下示例显示了通过在一行代码中连续使用两个 split 函数来实现此情况的方法。
# String extraction example
data.title.head()
0 Toy Story (1995)
1 Jumanji (1995)
2 Grumpier Old Men (1995)
3 Waiting to Exhale (1995)
4 Father of the Bride Part II (1995)
data.title.str.split("(", n=1, expand=True)[1].str.split(")", n=1, expand=True)[0]
0 1995
1 1995
2 1995
3 1995
4 1995
9缩放
在大多数情况下,数据集的数值特征没有特定范围,并且彼此不同。在实际中,如果要求年龄列和收入列具有相同的数值范围肯定会让人觉得没道理。但是如果站在机器学习的角度来看的话,该如何比较这两个数值特征呢?
缩放解决了这个问题。经过缩放过程后,连续特征的范围变得相同。对于许多算法来说,此过程不是强制性的,但应用起来效果可能很好。但是,基于距离计算的算法(例如 k-NN 或 k-Means)需要具有可缩放的连续特征作为模型输入。
有两种基本的数据缩放方式。
.归一化
归一化(或 min-max 归一化)在 0 到 1 之间的固定范围内缩放所有值。
此变换不会更改特征的分布,并且由于标准差降低,异常值的影响会增加。因此,建议在该归一化之前处理异常值。
data = pd.DataFrame({'value':[2,45, -23, 85, 28, 2, 35, -12]})
data['normalized'] = (data['value'] - data['value'].min()) / (data['value'].max() - data['value'].min())
value normalized
0 2 0.23
1 45 0.63
2 -23 0.00
3 85 1.00
4 28 0.47
5 2 0.23
6 35 0.54
7 -12 0.10
.标准化
标准化(或 z-分数规范化)在考虑标准差的同时缩放特征值。如果特征的标准差不同,则它们的范围也将彼此不同。这减少了特征中异常值的影响。
在以下标准化公式中,
data = pd.DataFrame({'value':[2,45, -23, 85, 28, 2, 35, -12]})
data['standardized'] = (data['value'] - data['value'].mean()) / data['value'].std()
value standardized
0 2 -0.52
1 45 0.70
2 -23 -1.23
3 85 1.84
4 28 0.22
5 2 -0.52
6 35 0.42
7 -12 -0.92
10提取日期
尽管日期列通常给有关模型目标值提供了很多有用信息,但它们在机器学习学习中往往被忽略。日期可以以多种格式显示,这使得算法很难理解,即使将日期简化为 01-01-2017 之类的格式也是如此。
如果不处理日期列,那么在这些值之间建立序数关系对于机器学习算法来说是非常具有挑战性的。在这里,建议对日期进行三种预处理,
将日期部分提取到不同的列中: 年、月、日等。 根据年、月、日等提取当前日期和这些列之间的时间差。
从日期中提取一些特定特征: 工作日的名称,是否周末、是否休假等。
如果将日期列按上述方法提取出新的列,则它们的信息将会被更合理地表达出来,并且机器学习算法可以轻松地理解它们。
from datetime import date
data = pd.DataFrame({'date':
['01-01-2017',
'04-12-2008',
'23-06-1988',
'25-08-1999',
'20-02-1993',
]})
# Transform string to date
data['date'] = pd.to_datetime(data.date, format="%d-%m-%Y")
# Extracting Year
data['year'] = data['date'].dt.year
# Extracting Month
data['month'] = data['date'].dt.month
# Extracting passed years since the date
data['passed_years'] = date.today().year - data['date'].dt.year
# Extracting passed months since the date
data['passed_months'] = (date.today().year - data['date'].dt.year) * 12 + date.today().month - data['date'].dt.month
# Extracting the weekday name of the date
data['day_name'] = data['date'].dt.day_name()
date year month passed_years passed_months day_name
0 2017-01-01 2017 1 2 26 Sunday
1 2008-12-04 2008 12 11 123 Thursday
2 1988-06-23 1988 6 31 369 Thursday
3 1999-08-25 1999 8 20 235 Wednesday
4 1993-02-20 1993 2 26 313 Saturday

⟳英文链接⟲
Emre Rençberoğlu: https://towardsdatascience.com/feature-engineering-for-machine-learning-3a5e293a5114
推荐阅读
决策树可视化,被惊艳到了! 开发机器学习APP,太简单了 200 道经典机器学习面试题总结 卷积神经网络(CNN)数学原理解析 收手吧,华强!我用机器学习帮你挑西瓜 为了这个GIF,我专门建了一个网站 【保姆级教程】白嫖老外的云服务器
三连在看,月入百万👇