
基于branch and bound插入的large neighborhood search

代码黑科技的分享区

一、前言
今年开年那会还在做一个课题的实验,那时候想用large neighborhood search来做一个问题,但是后来发现常规的一些repair、destroy算子效果并不是很好。后来才知道,large neighborhood search以及它的衍生算法,这类框架给人一种非常通用的感觉,就是无论啥问题都能往里面套。
往往的结果是套进去效果也是一般。这也是很多刚入行的小伙伴经常喜欢干的事吧,各种算法框架套一个问题,发现结果不好了就感觉换下一个。最后复现了N多个算法发现依然no process,这时候就会怀疑人生了。其实要想取得好的performance,肯定还是要推导一些问题特性,设计相应的算子也好,邻域结构也好。
好了,回到正题。当时我试了好几个large neighborhood search算子,发现没啥效果的时候,心里难受得很。那几天晚上基本上是转辗反侧,难以入眠,当然了是在思考问题。然后一个idea突然浮现在我的脑瓜子里,常规的repair算子难以在问题中取得好的performance,是因为约束太多了,插入的时候很容易违背约束。

在不违背约束的条件下又难以提升解的质量,我就想能不能插入的啥时候采取branch and bound。遍历所有的可能插入方式,然后记录过程中的一个upper bound用来删掉一些分支。
感觉是有搞头的,后来想想,这个branch的方法以及bound的方法似乎是有点难设计。然后又搁置了几天,最后没进展的时候突然找了一篇论文,是好多年前的一篇文章了。里面详细讲解了large neighborhood search中如何利用branch and bound进行插入,后来实现了以下感觉还可以。感觉这个方法还是有一定的参考价值的,因此今天就来写写(其实当时就想写了,只不过一直拖到了现在。。。)
二、large neighborhood search关于这个算法,我在此前的推文中已经有过相应的介绍,详情小伙伴们可以戳这篇的链接进行查看:
自适应大邻域搜索(Adaptive Large Neighborhood Search)入门到精通超详细解析-概念篇
我把其中的一段话摘出来:
大多数邻域搜索算法都明确定义它们的邻域。在LNS中,邻域是由和方法隐式定义的。方法会破坏当前解的一部分,而后方法会对被破坏的解进行重建。方法通常包含随机性的元素,以便在每次调用方法时破坏解的不同部分。
那么,解的邻域就可以定义为:首先通过利用方法破坏解,然后利用方法重建解,从而得到的一系列解的集合。LNS算法框架如下:

有关该算法更详细的介绍可以参考Handbook Of Metaheuristics这本书2019版本中的Chapter 4 Large Neighborhood Search(David Pisinger and Stefan Ropke),文末我会放出下载的链接。
关于destroy算子呢,有很多种,比如随机移除几个点,贪心移除一些比较差的点,或者基于后悔值排序移除一些点等,这里我给出文献中的一种移除方式,Shaw (1998)提出的基于进行移除:

假设需要从解中所有的移除个,它首先随机选择一个放进(已经移除的列表)(第1行),然后迭代地(3–6行)移除剩下的个。每次这样的迭代都会先从中随机选择一个,并根据相关标准对其余未移除的进行排序(第3-4行)。在第5行中计算要插入的新的下标,然后插入到中(第6行),直到迭代结束。关联度的定义如Shaw(1998)所述:
其中,customer 和 在不同的路径中时,否则为0。
三、branch and bound上面讲了Large Neighborhood Search以及介绍了一个方法,下面就是重头戏,如何利用branch and bound进行插入了。
3.1 branch
其实插入的分支方式还是挺好设计的,这玩意儿呢我将也比较难讲清楚,我就画图好了,还是基于VRP问题示例,其他问题类似,假如我们现在有这样一个解:
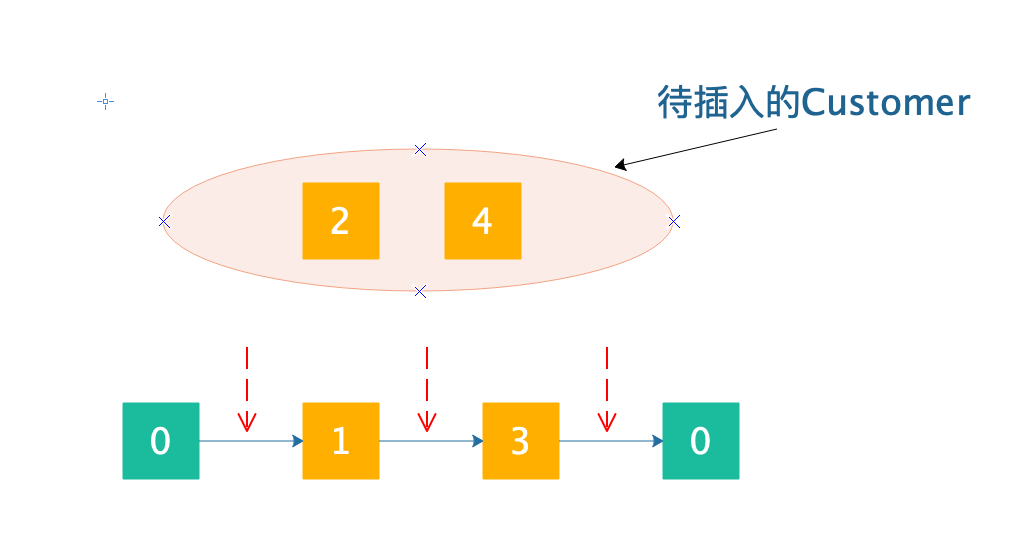
为了演示我就不画太多点太多路径了,免得大家看得心累。
红色箭头就是能够插入的位置。现在,假如我们插入(由于branch and bound是需要遍历所有可能的插入组合,因此先插入哪个后插入哪个都是可以的,但是分支定界的速度可能会受到很大的影响,这个咱们暂时不讨论):
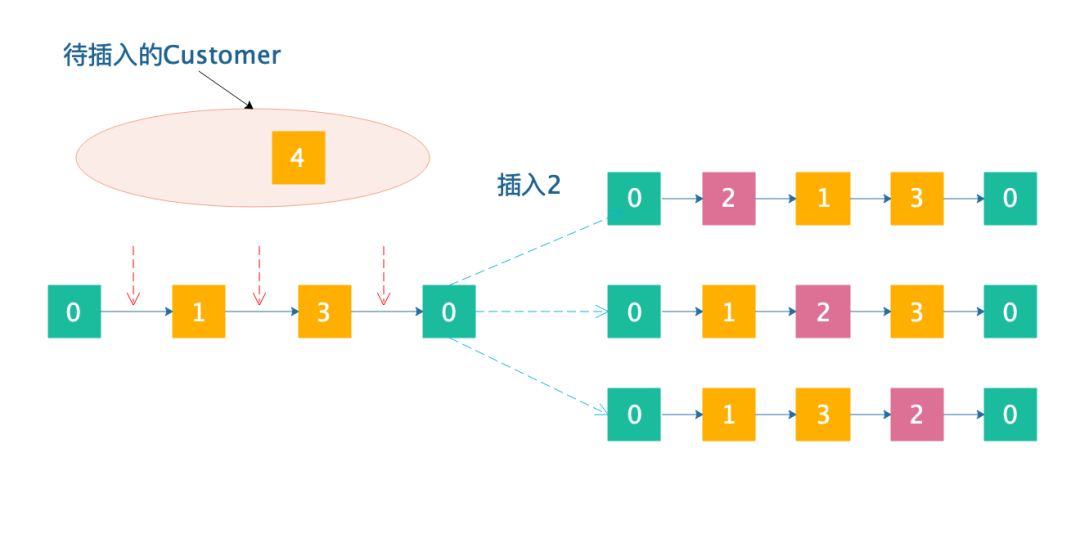
为了让大家看得更加清楚,我把的位置用粉红色给标记出来了,一共有3条分支,有个候选的位置就有多少条分支。
现在,还剩下,插入的时候,我们需要继续进行分支:
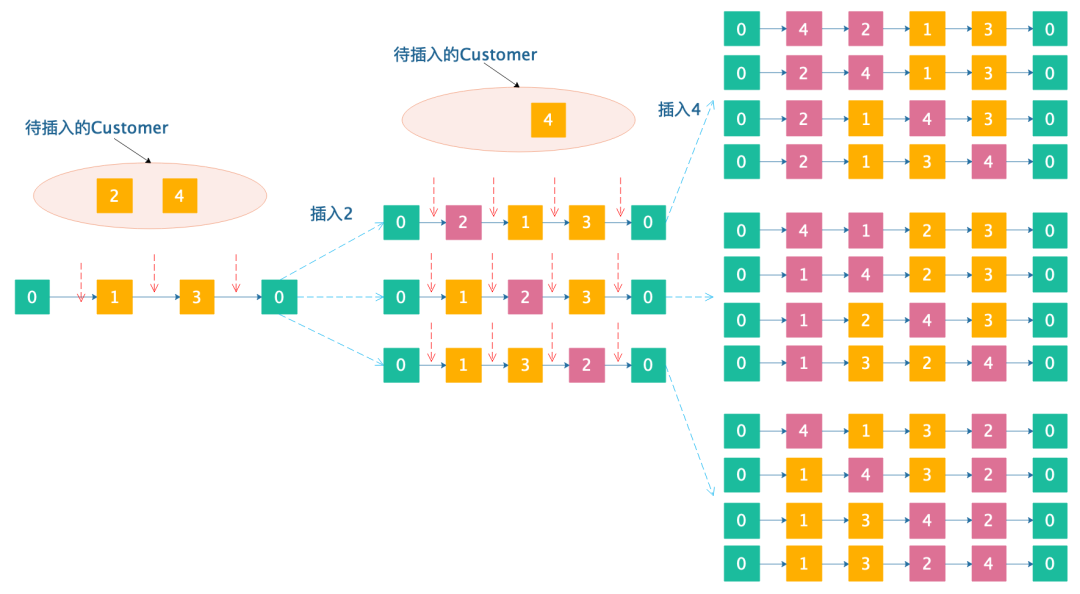
55~画分支树真是画死我啦(大家一定要给个赞,点个在看呀~),可以看到,最后每条路径就是一个完成的解。在两个点的插入两个点最后分支完成的居然有12个!!!大家可以自行脑补下,在90个点的中插入10个点最终形成的分支会有多少。毫无疑问会很多很多,多到你无法想象。下面是DFS搜索分支树的过程:

如果要插入的客户组为空,则可以认为所有客户已经插入到solution中,形成了一个,因此判断找到的一个upper bound是否比最优的upper bound还要好,是的话就对upper bound进行更新。否则,它会选择插入效果最好的客户,这会使目标函数下降得最大(Shaw 1998中也使用了这种启发式方法)。然后,对所有插入客户后形成的分支按照lower bound进行排序,从lower bound低的分支开始继续往下分支(可以算是一种加速的策略)。同样,请注意,该算法仅探索其lower bound比upper bound更好的分支。
3.2 bound
开始之前大家想想bound的难点在哪里呢?首先想想bound中最重要的两个界:upper bound和lower bound:
- lower bound是指搜索过程中一个partial solution(比如上图插入后形成的3个)的目标值,因为并不能算完整的一个解,继续往下的时候只可能增加(最小化问题)或者减少(最大化问题),因此它的意思是说当前支路的最终形成解的目标值下界(最终目标值不可能比这个lower bound更好)。
- upper bound是指搜索过程中找到的一个feasible solution(比如上图插入后形成的12个中满足所有约束的就是)的目标值,如果存在某支路的lower bound比upper bound还要差,那么该支路显然是没有继续往下的必要了,可以剪去。
显然可以使用LNS在destroy之前的解的目标值作为upper bound,因为我们总是期望找到比当前解更好的解,才会去进行destroy和repair。现在的问题是如何对一个的lower bound应该怎样计算。下面讲讲几种思路:
(1) 文献中给出的思路,利用最小生成树:


这个方案我试了,但是找到的lower bound实在是太低了,这个lower bound只考虑了距离因素,但问题中往往还存在时间窗等约束。因此这个方法在我当时做的问题中只能说聊胜于无。
(2) 按照greedy的方法将所有未插入的Customer插入到他们最好的位置上,形成一个,然后该的目标值作为lower bound。
但是这个lower bound是有缺陷的,因为很难保证不会错过某些比较有潜力的分支。
(3) 直接利用当前的的目标值作为lower bound,也比较合理。但是该值往往太低了,这可能会导致要遍历更多的分支,消耗更多时间。
以上就是一些思路,至于有没有更好的bound方法,我后面也没有往下深究了。当时实现出来以后效果是有的,就是时间太长了,然后也放弃了。
当然这篇paper后面也给了一个利用LDS进行搜索以加快算法的速度,这里就不展开了,有空再说。感兴趣的小伙伴可以去看看原paper,我会放到留言区的。
四、代码环节代码实现放两个,一个是我当时写的一个DFSEXPLORER,采用的是思路2作为bound的,(代码仅仅提供思路)如下:
private void DFSEXPLORER5(LNSSolution node, LNSSolution upperBound, int dep) {
Queue queue = new LinkedList();
LNSSolution s_c_ = node;
queue.add(s_c_);
int es = 1;
while (!queue.isEmpty()) {
s_c_ = queue.remove();
//v是一个完整的解
if(s_c_.removalCustomers.isEmpty()) {
if(s_c_.cost < upperBound.cost && Math.abs(s_c_.cost-upperBound.cost)>0.001) {
//System.out.println("new found > "+s_c_.cost+" feasible = "+s_c_.feasible());
upperBound.cost = s_c_.cost;
upperBound.routes = s_c_.routes;
}
}else {
//System.out.println("l > "+s_c_.removalCustomers.size() + " cost = "+s_c_.cost);
double minIDelta = Double.POSITIVE_INFINITY;
int minIndex = -1;
Customer c=null;
for(int i = 0; i < s_c_.removalCustomers.size(); ++i) {
Customer cu = s_c_.removalCustomers.get(i);
double d1 = s_c_.minInsertionDeltas[cu.getCustomerNo()];
if(minIDelta > d1) {
minIDelta = d1;
c = cu;
minIndex = i;
}
}
ArrayList neighborI_c = new ArrayList();
for( int i = 0; i < s_c_.routes.length; ++i) {
Route route = s_c_.routes[i];
if(!MyUtil.checkCompatibility(c, route.getAssignedVehicle())) {
continue;
}
for (int j = 0; j <= route.getCustomersLength(); j++) {
LNSSolution s_i = s_c_.solClones();
s_i.insertCustomer(s_i.routes[i], s_i.removalCustomers.get(minIndex), j, minIndex);
//updateIDAfterOneInserted(s_i, s_i.routes[i]);
//s_i.calcLowerBound();
double o_c = s_i.lb;
updateInsertionDelta(s_i);
double n_c = s_i.lb;
//if(o_c != n_c)System.out.println("o = "+o_c+" n = "+n_c);
neighborI_c.add(s_i);
}
}
Collections.sort(neighborI_c);
for(LNSSolution s:neighborI_c) {
//System.out.println("lBound "+s.lb+" upperBound = "+upperBound.cost);
//updateInsertionDelta(s);
//s.calcLowerBound();
if(s.lb < upperBound.cost /*&& dep > 0*/) {
//System.out.println("lBound "+s.lb+" upperBound = "+upperBound.cost);
//System.out.println(s.removalCustomers.size());
queue.add(s);
es++;
dep--;
}
}
}
}
//System.out.println(es);
}
第二个是GitHub上找到的一个人复现的,我已经fork到我的仓库中了:
https://github.com/dengfaheng/vrp
这个思路bound的思路呢没有按照paper中的,应该还是用的贪心进行bound。看起来在R和RC系列的算例中效果其实也一般般,因为用了LDS吧可能。下面是运行的c1_2_1的截图:
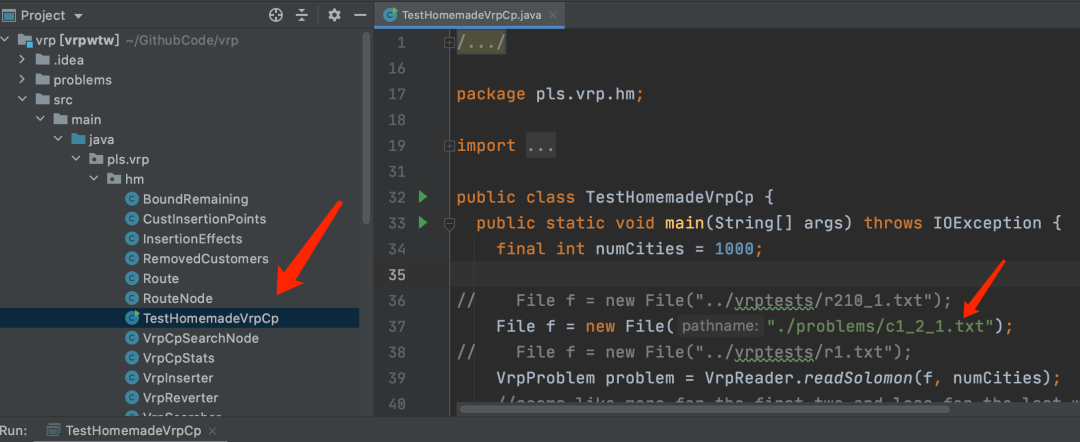
导入idea或者eclipse后等他安装完依赖,运行下面的文件即可,更改算例的位置如图所示:
这个思路是直到借鉴的,大家在用LNS的时候也可以想想有什么更好的bound方法。
好了,这就是今天的分享了。可能有很多地方没写的很明白,因为涉及的点太多了我也只能讲个大概提供一个思路而已。大家来了就帮我点个在看再走吧~
推荐阅读:
干货 | 学习算法,你需要掌握这些编程基础(包含JAVA和C++)
记得点个在看支持下哦~
