
【深度学习】从R-CNN到Mask R-CNN的思维跃迁
01
R-CNN

在那个时间点,基于深度学习的卷积神经网络开始屠榜ImageNet,R-CNN的思路非常直接,既然在图像分类方向上卷积神经网络效果这么好,那么如果把一张图的所有目标抠出来,一个一个送入CNN,不就可以将CNN和目标检测任务结合起来使用了,于是R-CNN就诞生了。
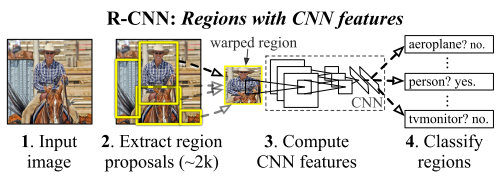
训练流程:
1.先在ImageNet上对CNN进行supervised pre-training。
2.然后在PASCAL VOC 2012数据集上进行domain-specific fine-tuning,即把ImageNet的1000分类层替换成21分类层(20个目标类加上1个背景类,因为region proposal会多产生一个背景类)进行fine-tuning。
3.然后将21分类层替换成每个类别一个线性SVM分类器(即总共21个SVM),然后进行分类训练。
4.最后加上边界框回归分支,进行定位训练。
推理流程:
1.先对输入图片使用selective search抽取2000个region proposals。
2.然后将region proposals一个一个送入CNN进行计算。
3.最后使用SVM分类器和边界框回归分支得到最终的类别和定位。
(ps: 由于后续的Faster R-CNN没有再沿用selective search和SVM,这里就不细讲了)
贡献
另外R-CNN还有一个容易被忽略的重要贡献,R-CNN之前的方法是先unsupervised pre-training,然后fine tuning,而R-CNN是第一个提出先supervised pre-training,然后fine tuning用于下游任务(说句题外话,现在的self-supervised是要重新使用usupervised pre-training的方式啊)。
最终,R-CNN在PASCAL VOC 2012数据集上比起之前的方法提升了30%。R-CNN奠定了目标检测的总体框架,开辟目标检测领域region proposal+CNN范式的新时代。
同时R-CNN埋下了两个伏笔
伏笔一
将R-CNN和OverFeat进行比较,提到OverFeat比R-CNN速度快9倍,主要是因为OverFeat的region proposals是作用在CNN后的feature map上的,CNN参数共享大大提高region proposals的并行性。
伏笔二
R-CNN中提到,SVM可能不是必须的,可能可以精简训练流程。
02
Fast R-CNN

Fast R-CNN针对R-CNN的两个伏笔进行了改进,通过CNN并行处理所有region proposal,并且同时训练分类和定位。
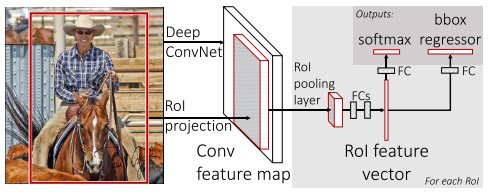
训练流程:
1.先在ImageNet上进行pre-training。
2.然后在PASCAL VOC数据集上进行分类和定位多任务的fine-tuning。
在训练流程上,相对于R-CNN直接将2,3,4步骤合并成一个步骤完成,大大降低了训练的复杂程度。
推理流程:
1.先将整张图片送入CNN得到feature map。
2.然后对feature map进行selective search,得到region of interest(RoI)。
3.然后将每个RoI送入RoI pooling转化成相同维度的向量。
4.最后通过两个独立的FC,预测出类别和位置。
在推理流程上,相比于R-CNN,送入CNN的是整张图片,selective search是在更小分辨率的feature map上进行的,大大减少了计算量。
下面详细讲一下Fast R-CNN的两个部分:RoI pooling和Multi-task loss。
RoI pooling
将不同尺寸大小的RoI进行维度上的对齐,可以统一进行multi-task的训练和推理。
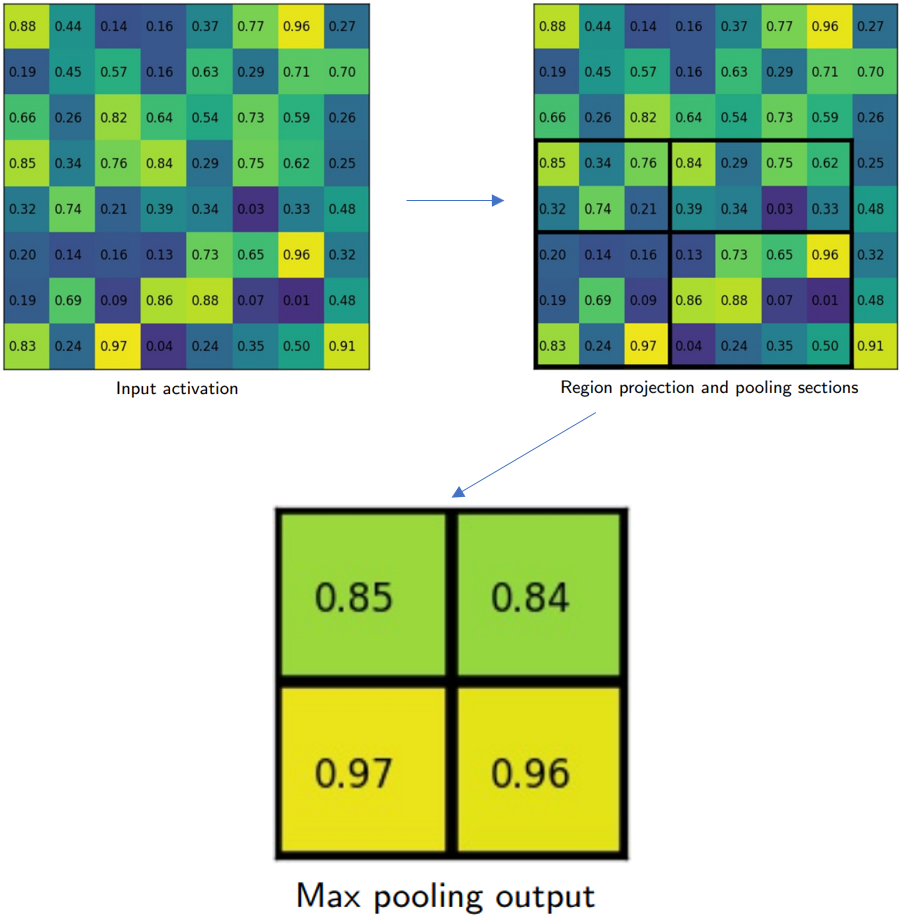
RoI pooling如图所示。以RoI pooling后尺寸变成2x2为例,右上图的黑色矩形框对应一个RoI(h,w=5,7),RoI需要分成4个bin,由于RoI pooling切分bin的时候需要对划分尺寸进行量化(h//2=2,w//2=3),所有第一个bin包含2x3个像素,第二个bin包含2x4个像素,第三个bin包含3x3个像素,第四个bin包含3x4个像素。最后对每个bin中的像素进行max pooling得到最终的2x2 feature map。
Multi-task loss
Fast R-CNN有两个输出层。第一个输出是每个RoI的离散概率分布,总共K+1个类别(其中一个是背景类),概率表示为
假设gt的类别为u,gt的边界框为v。我们用多任务loss来联合训练分类和边界框回归:
其中
其中边界框回归loss为:
贡献
Fast R-CNN极大的简化了R-CNN的训练流程,可以端到端的训练检测器,为后续Faster R-CNN的出现奠定了基础。
Fast R-CNN同样埋下了伏笔
伏笔
Fast R-CNN指出region proposal部分还是计算量太大了,导致速度不能进一步提高。
03
Faster R-CNN

虽然Fast R-CNN极大加快了检测器的推理速度,但是region proposal部分仍然是检测器进一步提升速度的瓶颈。于是,Faster R-CNN针对Fast R-CNN埋下的伏笔,设计了RPN和Anchor两个新组件,来改善region proposal提取RoI的质量,同时提升检测器的精度和速度。
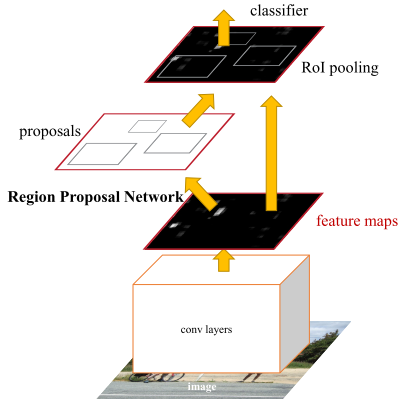
训练流程:
1.通过ImageNet pre-trained model初始化CNN,然后端到端fine-tuning RPN部分。
2.固定住RPN,然后通过RPN产生的region proposal来训练Fast R-CNN部分。
3.固定住CNN和Fast R-CNN来fine-tuning RPN网络。
4.固定住CNN和RPN来fine-tuning Fast R-CNN网络。
相当于是对RPN和Fast R-CNN两个部分交替进行训练,因为使用了RPN,导致训练难度增加,比起Fast R-CNN训练过程更加复杂了(后续开源代码对Faster R-CNN训练流程进行了简化,可以同时训练RPN和Fast R-CNN)。
推理流程:
1.先将图片输入CNN得到featmap。
2.然后通过RPN产生RoI。
3.然后将每个RoI送入RoI pooling转化成相同维度的向量。
4.最后通过两个独立的FC,预测出类别和位置。
下面详细讲一下Faster R-CNN的三个部分:Region Proposal Networks、Anchors和Loss Function。
Region Proposal Networks
Faster RCNN则抛弃了传统的滑动窗口和SS方法,直接使用RPN生成检测框,这也是Faster R-CNN的巨大优势,能极大提升检测框的生成速度。
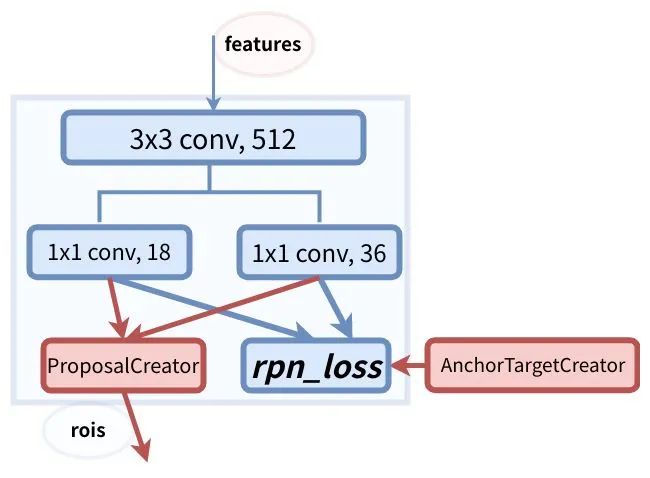
上图是RPN网络的具体结构。RPN网络分成2个分支,一个分支通过softmax分类得到所有anchors的分类分数,另一个分支用于计算所有anchors的边界框回归偏移量,以获得精确的proposal。最后在ProposalCreator通过分类分数和偏移量来得到合适的proposals。
Anchors
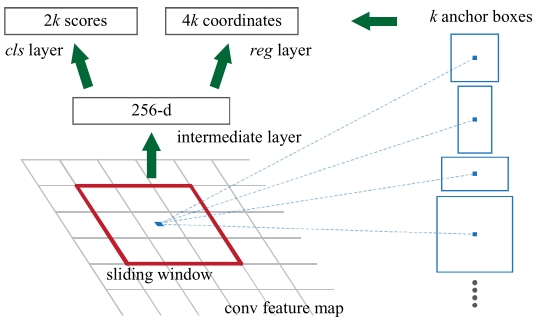
Faster R-CNN中在feature map的每个位置都设置了三种尺度三种长宽比的anchor,总共9种。
anchor数量对RPN输出维度产生的变化如图所示
原文中使用的CNN网络是ZF,CNN最后的conv5层num_output=256,对应生成256张特征图,所以相当于feature map每个点都是256-dimensions。
在conv5之后,做了3x3卷积保持num_output=256,相当于每个点又融合了周围3x3的空间信息。
在conv5 feature map的每个位置上设置k个anchor(默认k=9),而每个anhcor要分positive和negative,所以每个点由256d feature转化为cls=2k scores;而每个anchor都有(x, y, w, h)对应4个偏移量,所以reg=4k coordinates。
训练时在合适的anchors中随机选取128个postive anchors+128个negative anchors进行训练。
Loss Function
Faster R-CNN训练时有4个损失函数,函数形式跟Fast R-CNN的损失函数相似:
1.RPN 分类损失:anchor是否为前景(二分类)
2.RPN位置回归损失:anchor位置微调
3.RoI 分类损失:RoI所属类别(21分类,多了一个类作为背景)
4.RoI位置回归损失:继续对RoI位置微调
四个损失相加作为最后的损失,反向传播,更新参数。
贡献
Faster R-CNN设计的RPN和anchor可以极大提升region proposal质量,同时极大提升了检测器的精度和速度。Faster R-CNN是R-CNN系列的集大成者,能够用近乎实时的速度检测物体,让目标检测在更多场景应用成为可能。
04
Mask R-CNN

Faster R-CNN的RoI pooling是粗粒度的空间量化特征提取,不能做输入和输出pixel-to-pixel的特征对齐,并且不能直接应用于实例分割。于是Mask R-CNN提出用RoIAlign来替代RoI pooling,得到pixel-to-pixel的特征对齐,并且在Faster R-CNN框架的基础上简单的增加了一个mask分支就能实现实例分割。
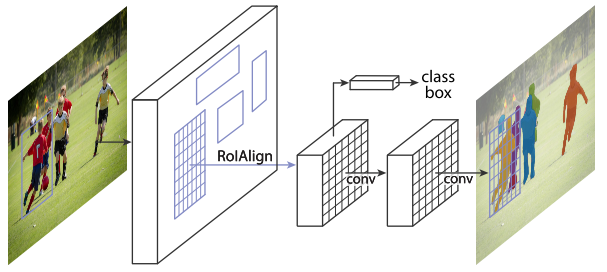
训练流程:
1.先在ImageNet上进行pre-training。
2.然后在COCO数据集上进行分类、定位和分割三个任务fine-tuning。
推理流程:
1.先将图片输入CNN得到featmap。
2.然后通过RPN产生RoI。
3.然后将每个RoI送入RoI pooling转化成相同维度的向量。
4.最后通过两个独立的FC,预测出类别和位置,同时通过mask分支预测出分类分数前N个RoI的分割mask。
下面详细讲一下Mask R-CNN的三个部分:Region Proposal Networks、Anchors和Loss Function。
Network Architecture
Mask R-CNN把抽取特征的CNN部分定义为backbone,把分类、回归和分割部分定义为head。Mask R-CNN把ResNet第4个stage出来的feature定义为ResNet C4,同时Mask R-CNN还探索了更加有效的FPN网络。
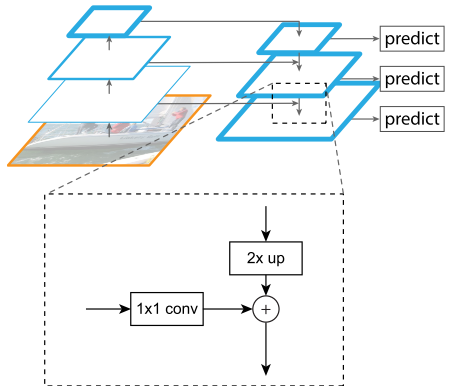
FPN结构如图所示。FPN采用自顶向下结构,通过横向连接构建网络内部特征金字塔。FPN可以根据anchor的尺度大小分配特征层,从不同特征层提取RoI特征。
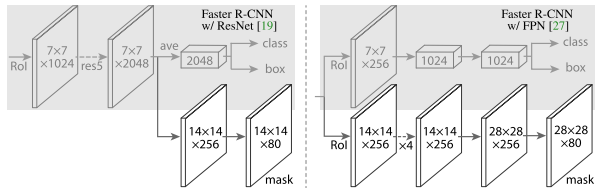
head结构如图所示。ResNet C4的backbone后面增加了一个stage5,然后进行分类、回归和分割。FPN的backbone将FPN结构收集到的RoI直接送入两个分支,然后进行分类、回归和分割。
其中分割分支,通过deconv来得到更大分辨率的feature map,从而得到更精确的mask预测结果,分割分支的最终feature map通道数等于类别数,每个通道预测一种类别的mask。最终多任务的损失函数为
RoIAlign
分割需要pixel-to-pixel对齐的RoI特征,这促使Mask R-CNN设计了RoIAlign来替代RoI pooling。
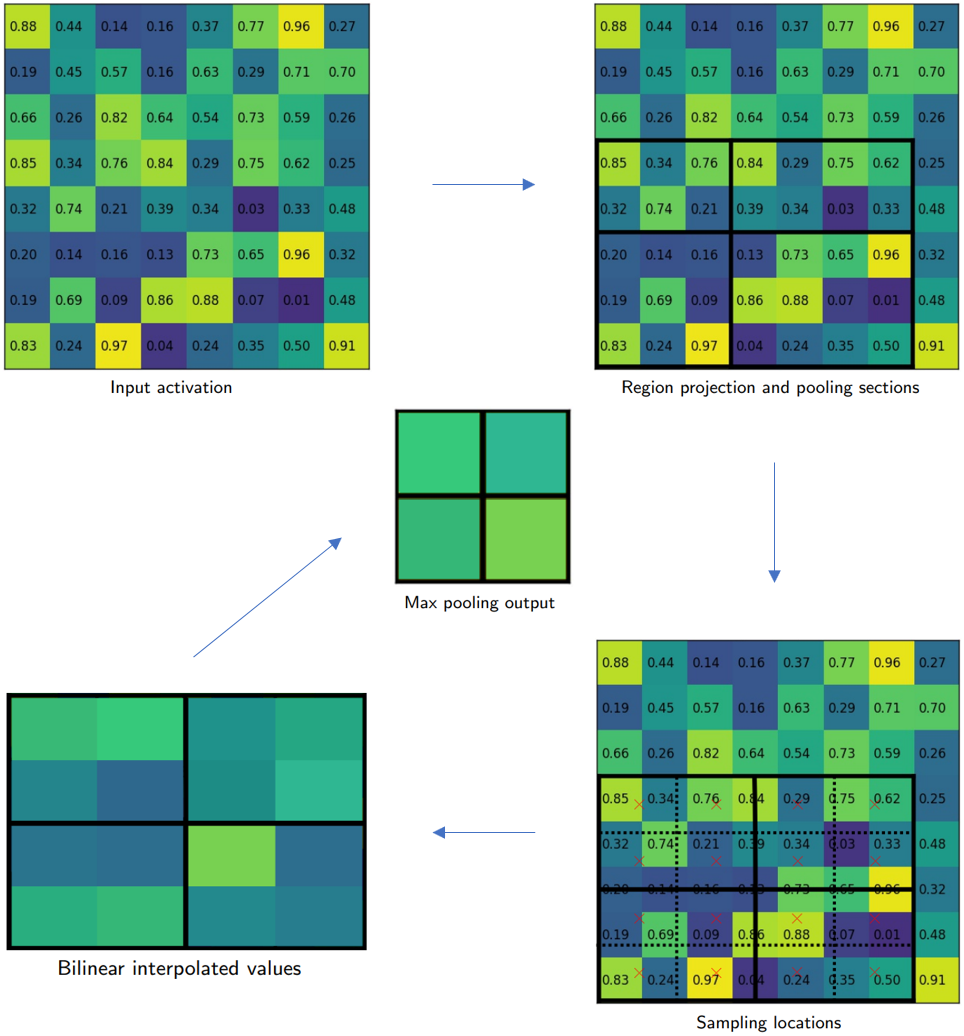
RoIAlign如图所示。切分bin的时候和RoI pooling有所不同,避免了量化带来的误差,保证pixel-to-pixel的对齐。如右下图,RoIAlign切分bin的时候不进行量化,每个bin划分成2x2(4个红色x标记),每个红色x通过最相邻的4个像素值进行双线性插值计算,得到每个bin的4个插值,最后通过max pooling得到最终的2x2 feature map。
贡献
Mask R-CNN完美地展现了Faster R-CNN的易拓展性和强大的检测能力。但是Mask R-CNN最重要的贡献其实是提高了人们对实例分割任务思维上的认知。从现在看,先检测后分割的思路似乎非常简单,但是在Mask R-CNN出现之前,实例分割大多数都是bottom-up的思路,而Mask R-CNN是top-down的思路,在当时如何在检测框架中简洁优雅的嵌入实例分割是很困难的。
详细的讨论可以看周博磊大佬当年的回答https://www.zhihu.com/question/51704852/answer/127120264
Mask R-CNN最终夺得ICCV 2017 Best Paper。Mask R-CNN即使放到现在也依然是王者,再次感受一下Mask R-CNN的强大

R-CNN/Fast R-CNN/Faster R-CNN/Mask R-CNN比较
这里祭出我的多年珍藏(slides放在公众号了,回复R-CNN自取)
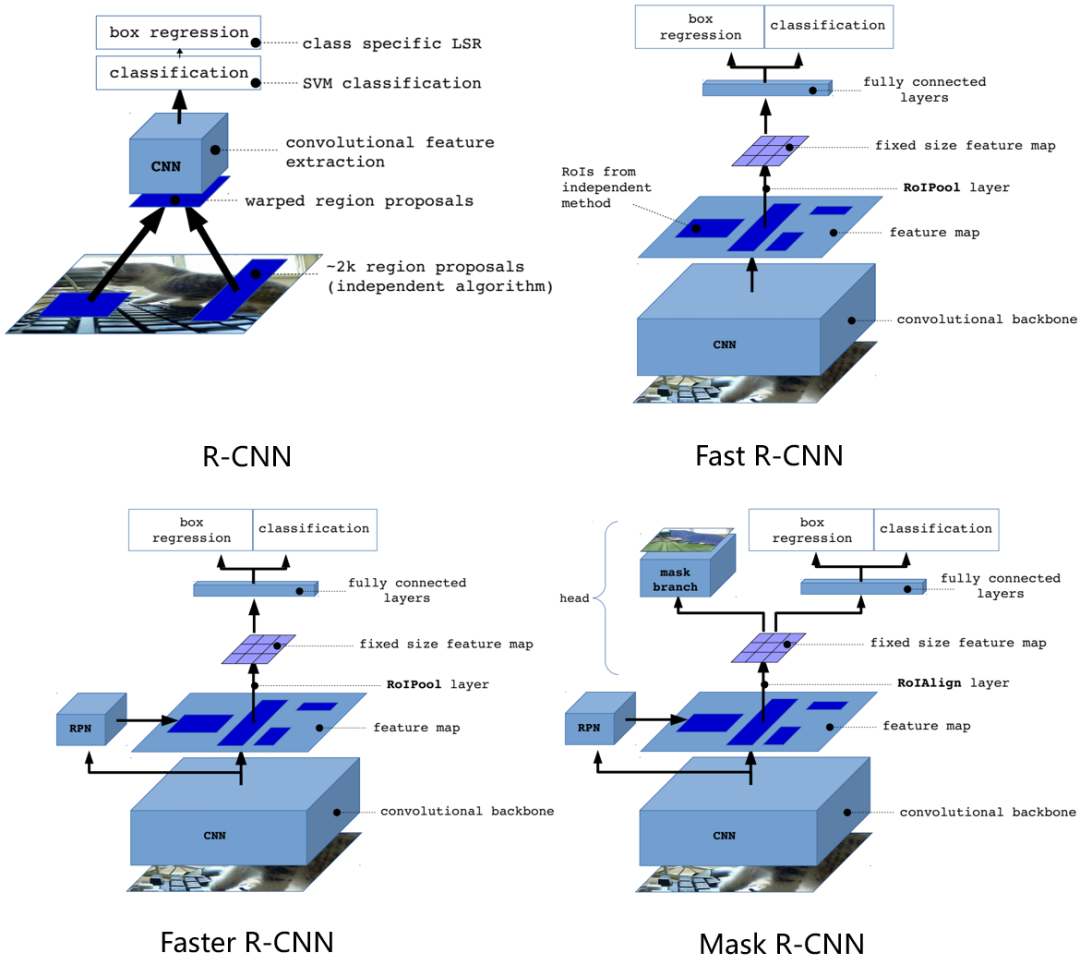
从上图可以清清楚楚的看出从R-CNN到Mask R-CNN框架是如何演变的。
可以分成两个支线看:训练流程和推理框架。
训练流程上
R-CNN -> Fast R-CNN极大精简了目标检测框架的训练流程,从4个独立训练流程精简成了2个独立训练流程。
Fast R-CNN -> Faster R-CNN因为RPN网络的引入,导致训练流程重新变成了RPN和Fast R-CNN交替训练4次(后续开源代码将RPN和Fast R-CNN联合训练了)。
Faster R-CNN -> Mask R-CNN又转变成了2个独立训练流程。
推理框架上
R-CNN -> Fast R-CNN提取RoI进行并行化处理,将分类和定位看成一个多任务,并设计RoI pooling来进行特征对齐。
Fast R-CNN -> Faster R-CNN提出RPN来对region proposal部分进行加速,并且提出anchor来适应不同形态的目标。
Faster R-CNN -> Mask R-CNN增加一个mask分支,展示了Faster R-CNN的易拓展性,并且设计了RoIAlign进行pixel-to-pixel的对齐。
05
总结
整个R-CNN系列非常经典,阵容极其华丽(RBG、何恺明、任少卿等等)。从传统视觉到深度学习,RGB简单直接的应用CNN构造了R-CNN检测器,开启基于深度学习的目标检测新时代;从R-CNN到Fast R-CNN、Faster R-CNN通过实验观察和思考,发现问题,解决问题;Mask R-CNN在已有领域,通过简单设计改造,从目标检测任务迁移到实例分割任务。无论是从设计思维,洞察力和科研敏锐性上,都无可挑剔。(ps:R-CNN的文章,看起来粗糙,实则干货满满;现在的文章都一个模子刻出来的一样,看起来精致,实则同质化严重)
最后,我想说的是计算机视觉中,从R-CNN到Mask R-CNN的思维跃迁是我最爱看的“小说”章节。
Reference
[1] Rich feature hierarchies for accurate object detection and semantic segmentation
[2] Fast R-CNN
[3] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
[4] Mask R-CNN
另外再推荐几篇Faster R-CNN的blog,非常精彩
https://zhuanlan.zhihu.com/p/31426458
https://zhuanlan.zhihu.com/p/145842317
https://zhuanlan.zhihu.com/p/32404424
往期精彩回顾
本站qq群851320808,加入微信群请扫码: