
【Python】发现了一个好用到爆的数据分析利器
关于streamlit-aggrid
我们知道用Streamlit模块来进行web应用的开发真的非常的方便,但是在展示表格方面则显得十分地简陋,只有两个简单的接口函数,分别是st.table(df)和st.dataframe(df),对于字段较多的表格数据的展示非常的不友好,今天小编就来介绍一款Streamlit的插件,streamlit-aggrid,它的基础功能包括
数据排序 表格样式的调整 数据的筛选 翻页 等等
首先我们先通过pip命令下载该模块
pip install streamlit-aggrid
我们先来写一个简单的demo,看一下该模块到底能实现哪些功能,代码如下
import pandas as pd
import streamlit as st
from st_aggrid import AgGrid
st.set_page_config(page_title="网飞(Netflix)的电影数据分析", layout="wide")
st.title("网飞(Netflix)的电影数据分析")
shows = pd.read_csv("netflix_titles.csv")
AgGrid(shows)
output
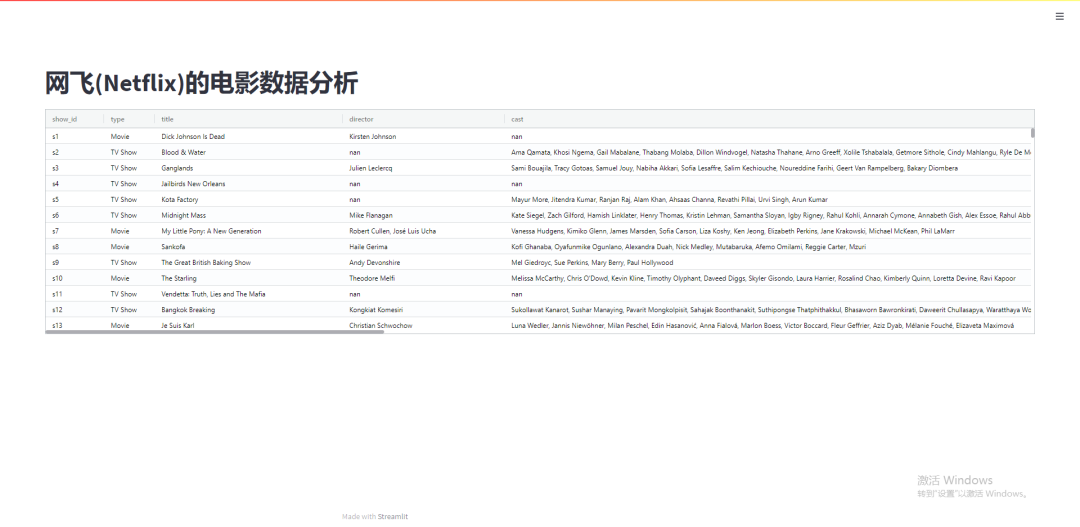
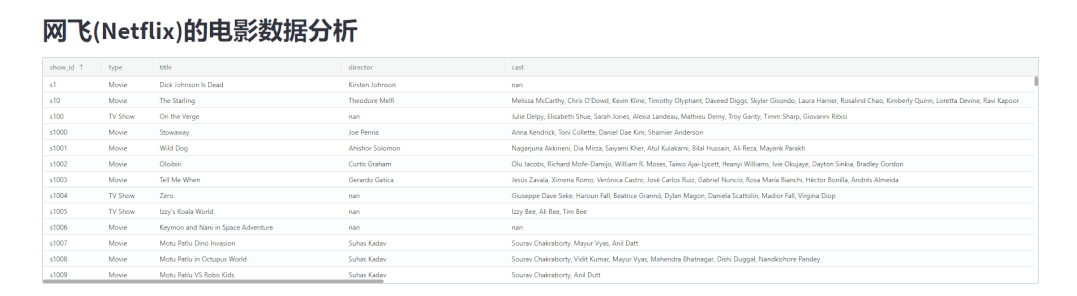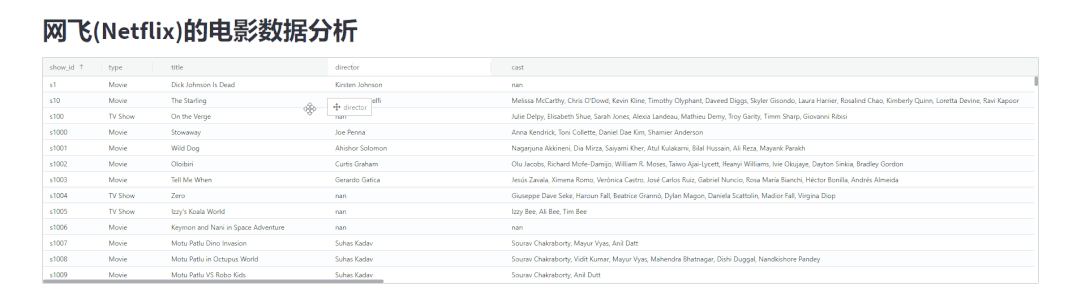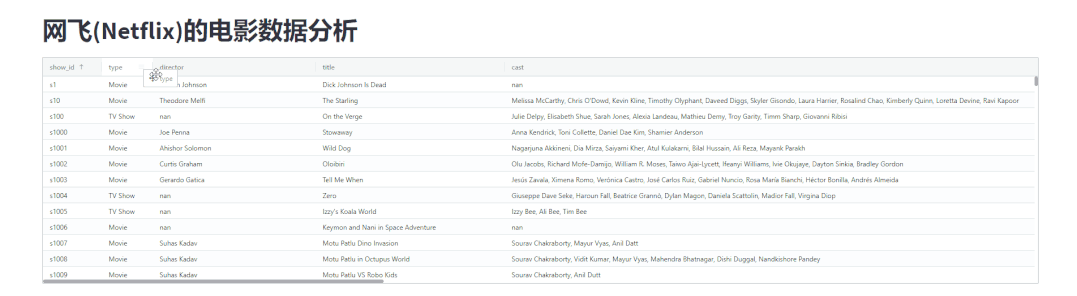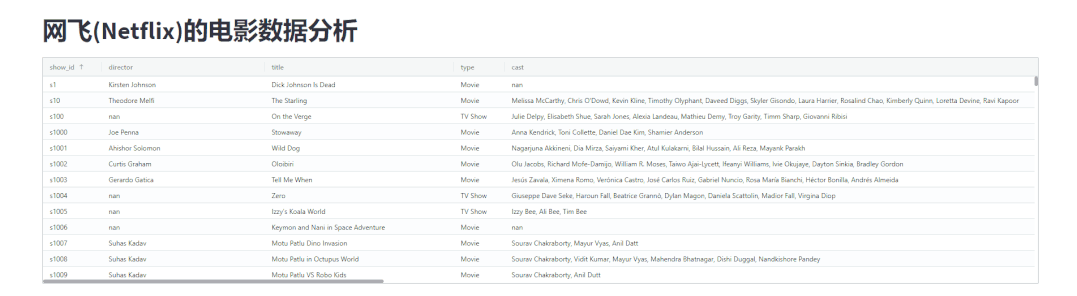
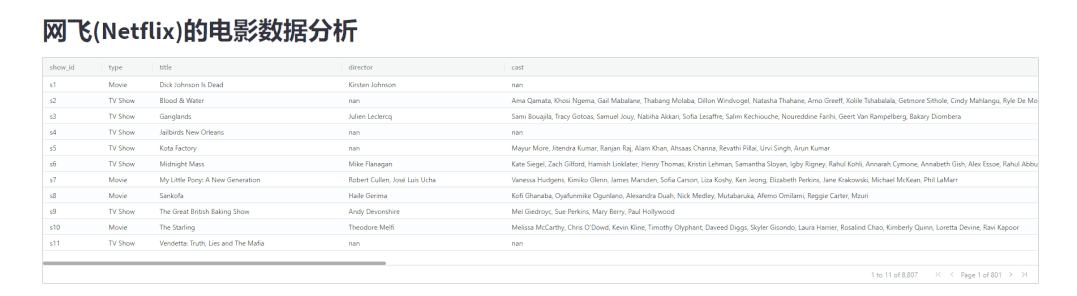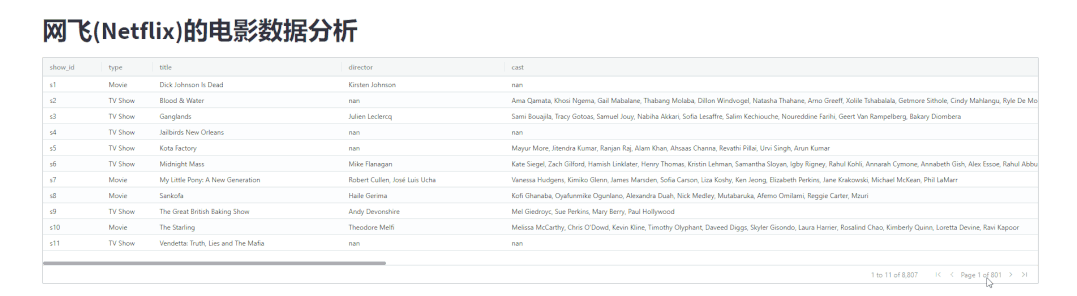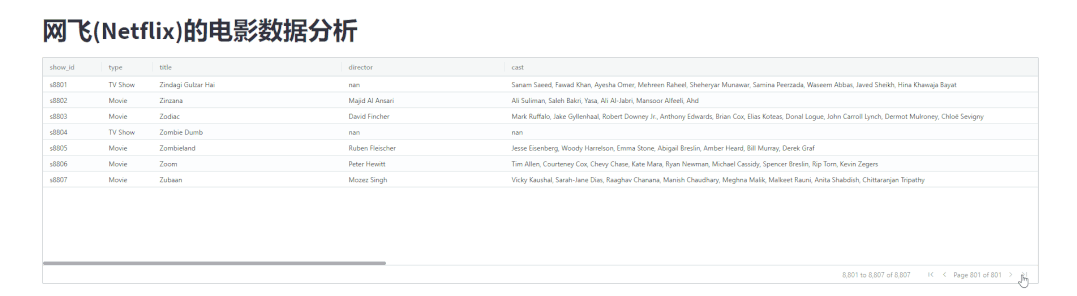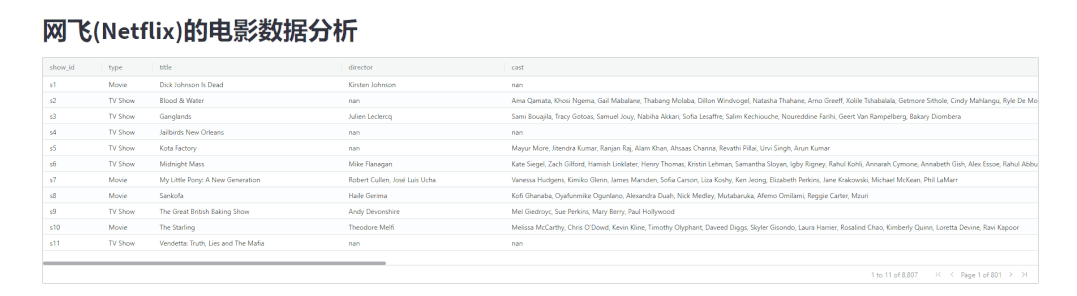
st.dataframe(shows)出来的结果相比,发现调用streamlit-aggrid模块展示出来的表格更加美观,如下图所示

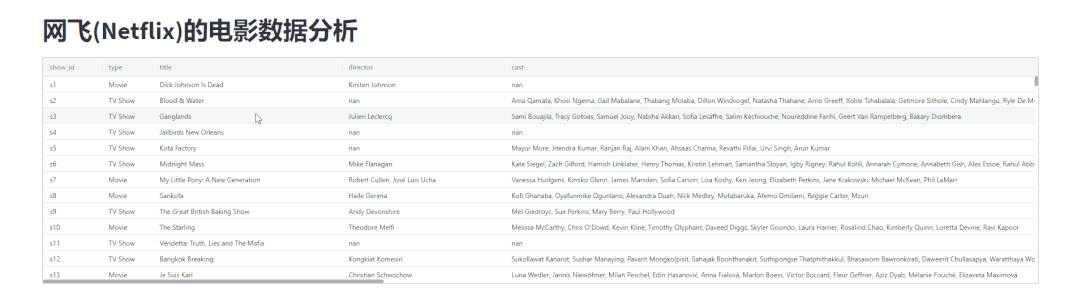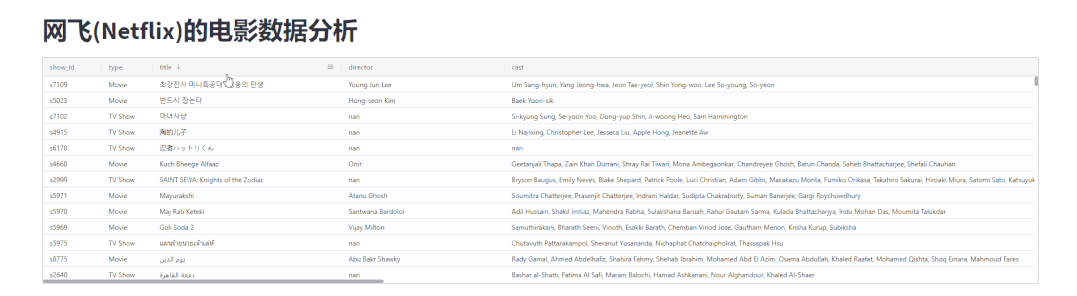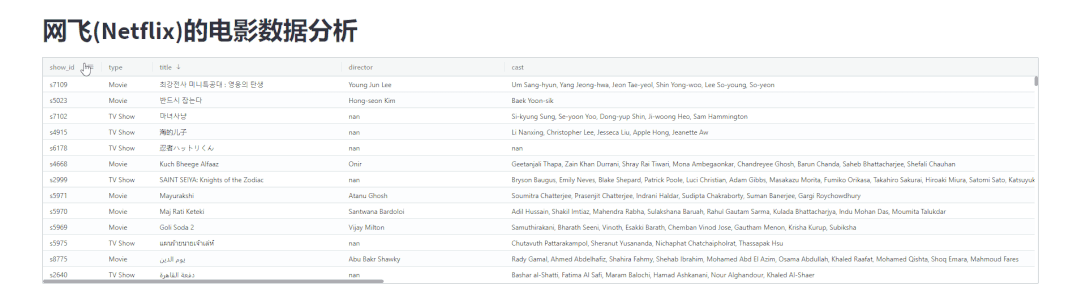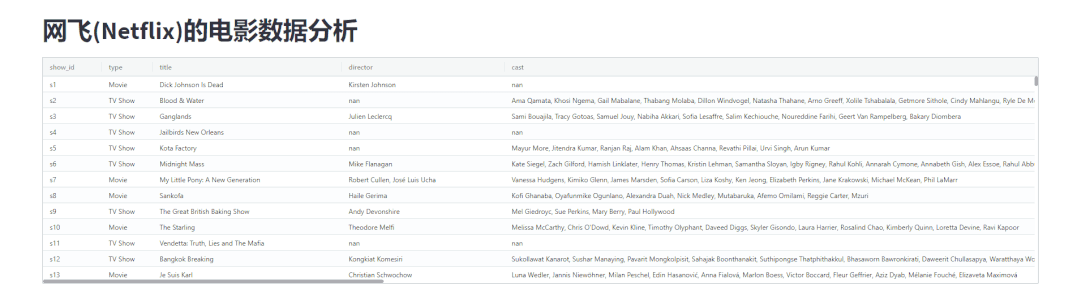
当然我们还能够给数据进行排序,如下图所示
并且还可以根据指定的条件来进行数据的筛选,如下图所示
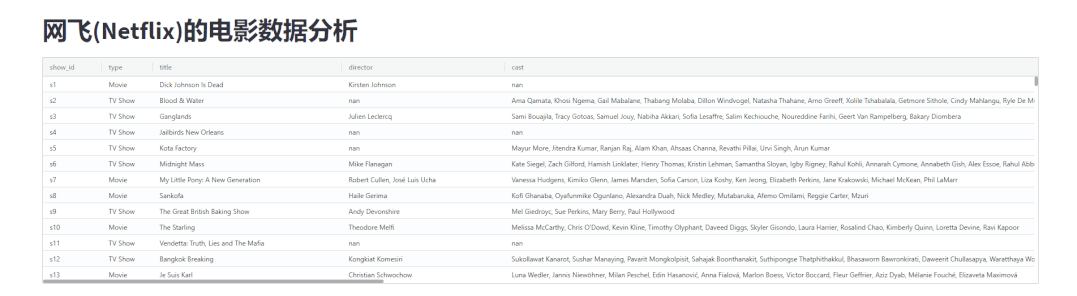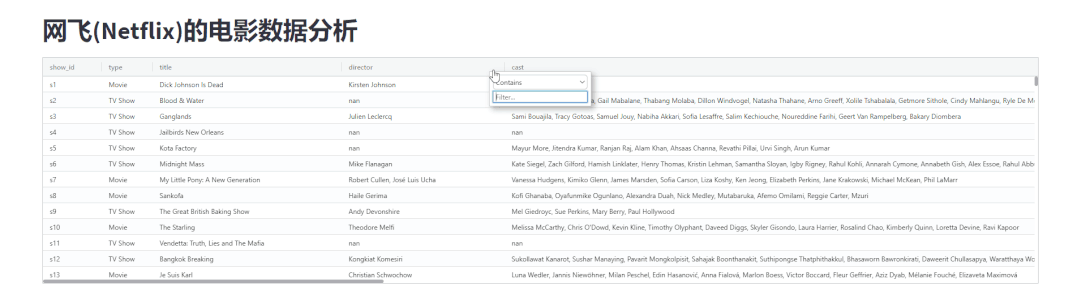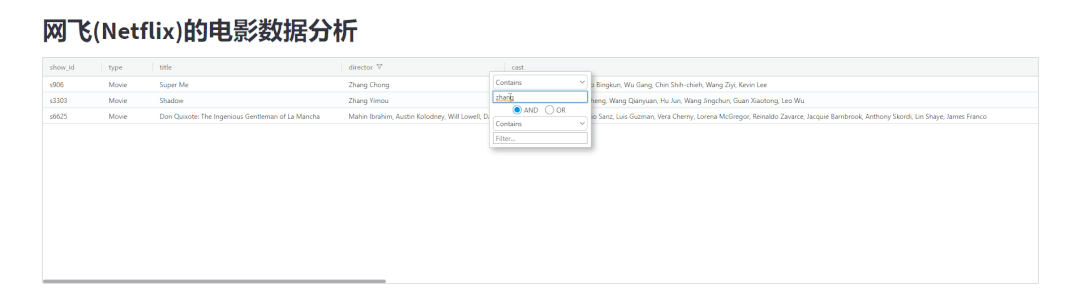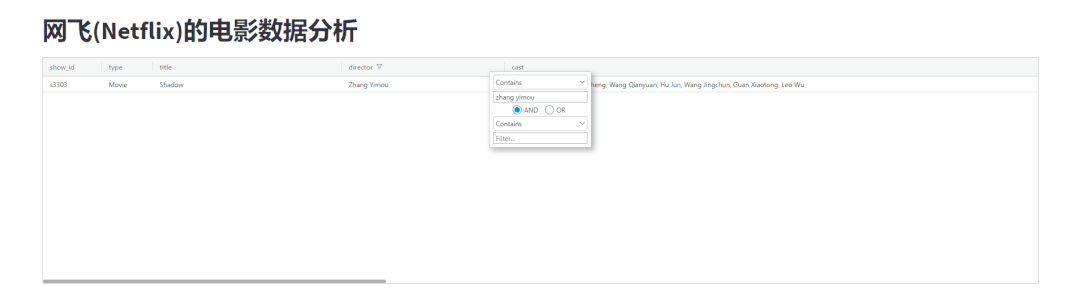
我们还可以按照自己的喜好来拖拽表格当中的每一列的数据,调整表格的顺序
更多操作
翻页
streamlit-aggrid模块展示出来的表格数据还支持翻页操作,代码如下import pandas as pd
import streamlit as st
from st_aggrid import AgGrid
from st_aggrid.grid_options_builder import GridOptionsBuilder
st.set_page_config(page_title="网飞(Netflix)的电影数据分析", layout="wide")
st.title("网飞(Netflix)的电影数据分析")
shows = pd.read_csv("netflix_titles.csv")
gb = GridOptionsBuilder.from_dataframe(shows)
gb.configure_pagination()
gridOptions = gb.build()
AgGrid(shows, gridOptions=gridOptions)
output
分组统计
groupby分组统计来streamlit-aggrid模块当中也可以轻松地实现,代码如下import pandas as pd
import streamlit as st
from st_aggrid import AgGrid
from st_aggrid.grid_options_builder import GridOptionsBuilder
st.set_page_config(page_title="网飞(Netflix)的电影数据分析", layout="wide")
st.title("网飞(Netflix)的电影数据分析")
shows = pd.read_csv("netflix_titles.csv")
gb = GridOptionsBuilder.from_dataframe(shows)
gb.configure_pagination()
gb.configure_side_bar()
gb.configure_default_column(groupable=True, value=True, enableRowGroup=True, aggFunc="sum", editable=True)
gridOptions = gb.build()
AgGrid(shows, gridOptions=gridOptions, enable_enterprise_modules=True)
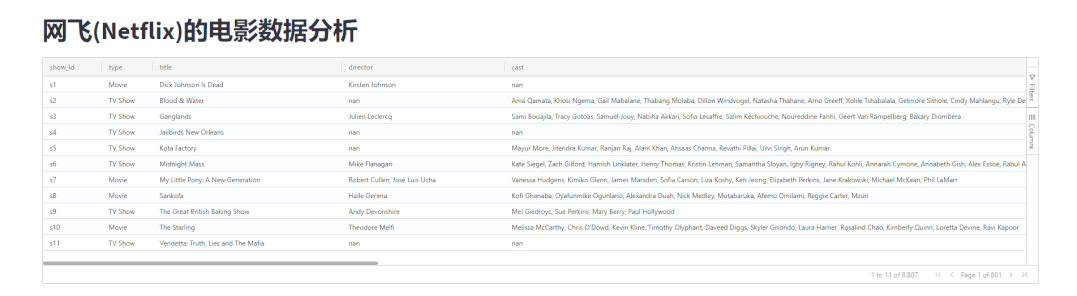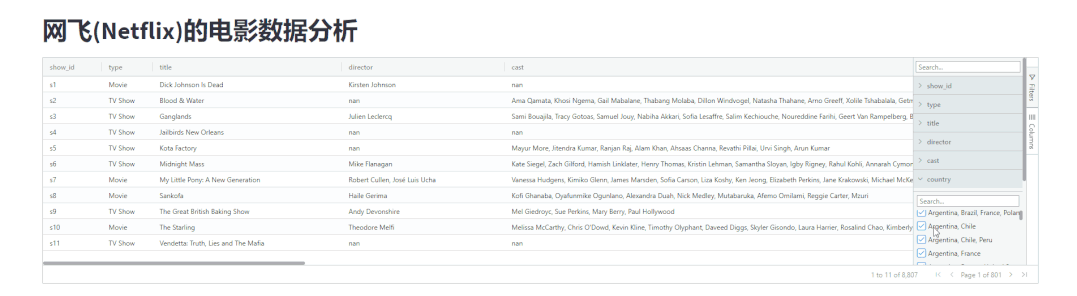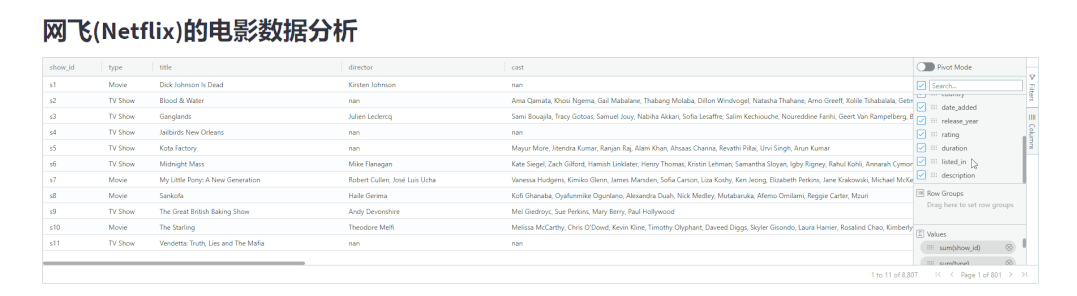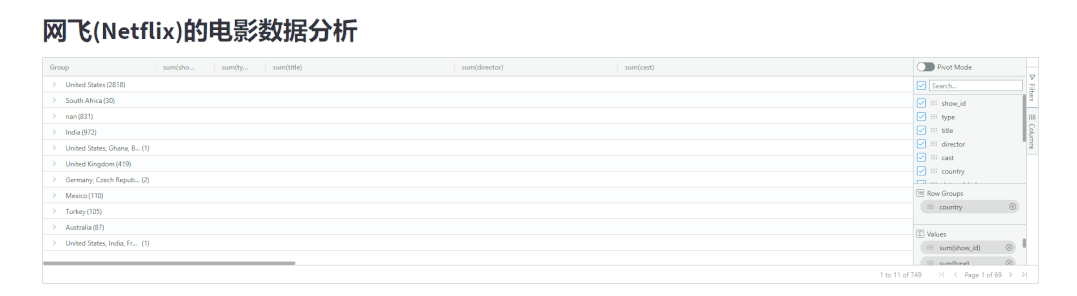
高亮表格数据
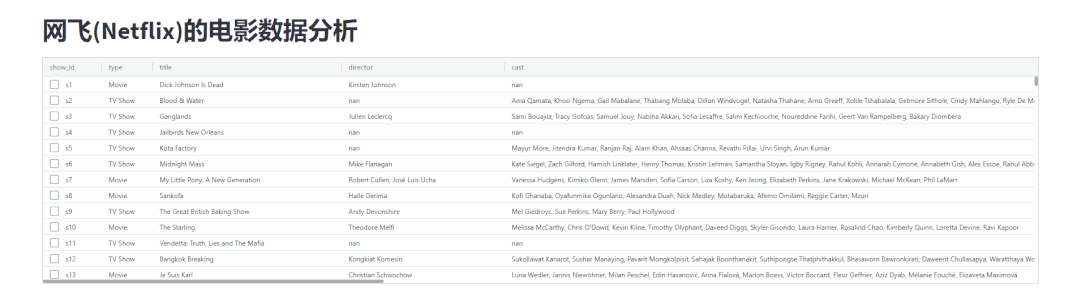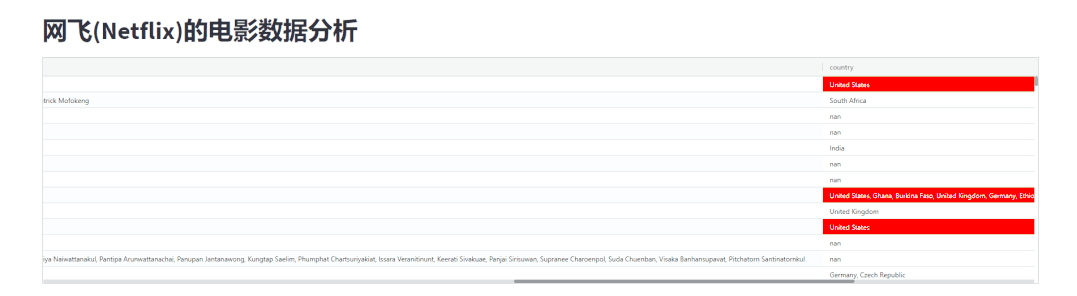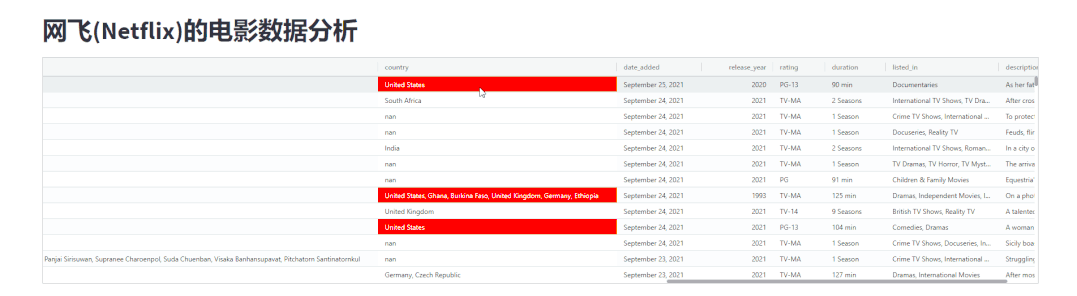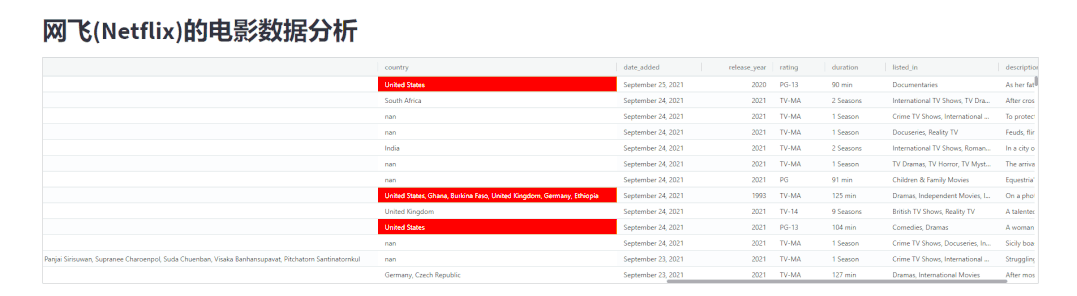
在Pandas模块当中我们可以给指定的数据高亮显示,那么同样地在streamlit-aggrid模块当中也可以实现,代码如下
shows = pd.read_csv("netflix_titles.csv")
gb = GridOptionsBuilder.from_dataframe(shows)
cellsytle_jscode = JsCode(
"""
function(params) {
if (params.value.includes('United States')) {
return {
'color': 'white',
'backgroundColor': 'red'
}
} else {
return {
'color': 'black',
'backgroundColor': 'white'
}
}
};
"""
)
gb.configure_column("country", cellStyle=cellsytle_jscode)
gridOptions = gb.build()
data = AgGrid(
shows,
gridOptions=gridOptions,
enable_enterprise_modules=True,
allow_unsafe_jscode=True
)
我们将国家为“美国”的电影数据用红色高亮显示出来,如下图所示
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 机器学习交流qq群955171419,加入微信群请扫码