
当卷积网络遇上事件检测 (经典论文解读)

0 前情提要
上一篇文章从初号机暴走的角度介绍了何为事件抽取,以及一个简单的事件抽取模型,后续本专栏将会解读以往论文,持续深入分析事件抽取任务,有疑问的伙伴可以后台留言哦。
今天介绍的是第一个把卷积网络(CNN)用于事件检测的工作。
论文标题:
Event Detection and Domain Adaptation with Convolutional Neural Networks
论文链接:
https://www.aclweb.org/anthology/P15-2060.pdf
1 克服痛点
一篇论文之所以存在价值,是因为能够解决以往研究工作无法解决的痛点。
在这个工作之前,事件检测采用的是传统特征工程方法,会带来以下的问题:1)越充分的特征所需的特征工程越复杂,付出的成本也就越多;2)构造特征的步骤会带来错误传递问题。
卷积网络可以自动抽取文本特征,不需要复杂的特征工程,自然不存在上述的问题。
2 任务定义
事件检测任务可以说是事件抽取任务的简化版本,只需要检测出文本中是否存在特定类型的事件,例如:
“A police officer was killed in New Jersey today“
句子中,“killed“是”死亡“事件的触发词,该句子存在”死亡“事件。
既然是检测一个句子是否存在、以及存在何种事件类型,那么事件检测任务可以看作文本多分类任务,仅仅需要对句子进行语义编码,然后对其进行事件类型分类即可。
2015年,Nguyen和Grishman将CNN引进事件检测任务,实现了从传统特征工程方法到深度学习方法的跨越。
3 模型细节

在输入数据处理层面,对每个输入文本设置一个固定的长度31,截断超出的部分以及填充缺失的部分,每个输入文本对应一个事件类型的分类标签。
预训练词向量使用word2vec[1]初始化,位置编码向量和BIO实体类型编码向量随机初始化。输入字符通过查表获取向量编码,在模型训练过程中,这3个向量矩阵的参数随着网络更新优化至最佳性能。
4 数据集
作者采用的是ACE 2005语料库,该语料库存在下载权限,需要自行去官网(https://www.ldc.upenn.edu) 获取数据集权限。该数据集有33种事件子类型以及“无事件”,因此一共有34种分类标签。
5 实验分析
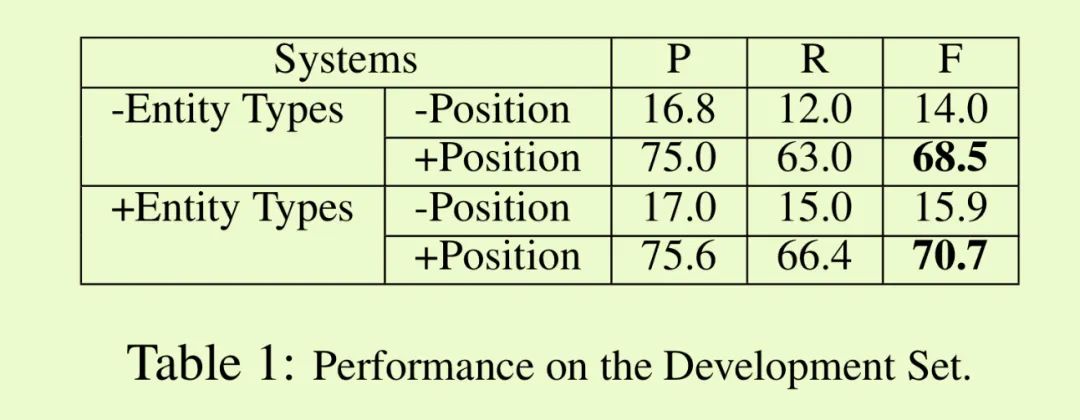
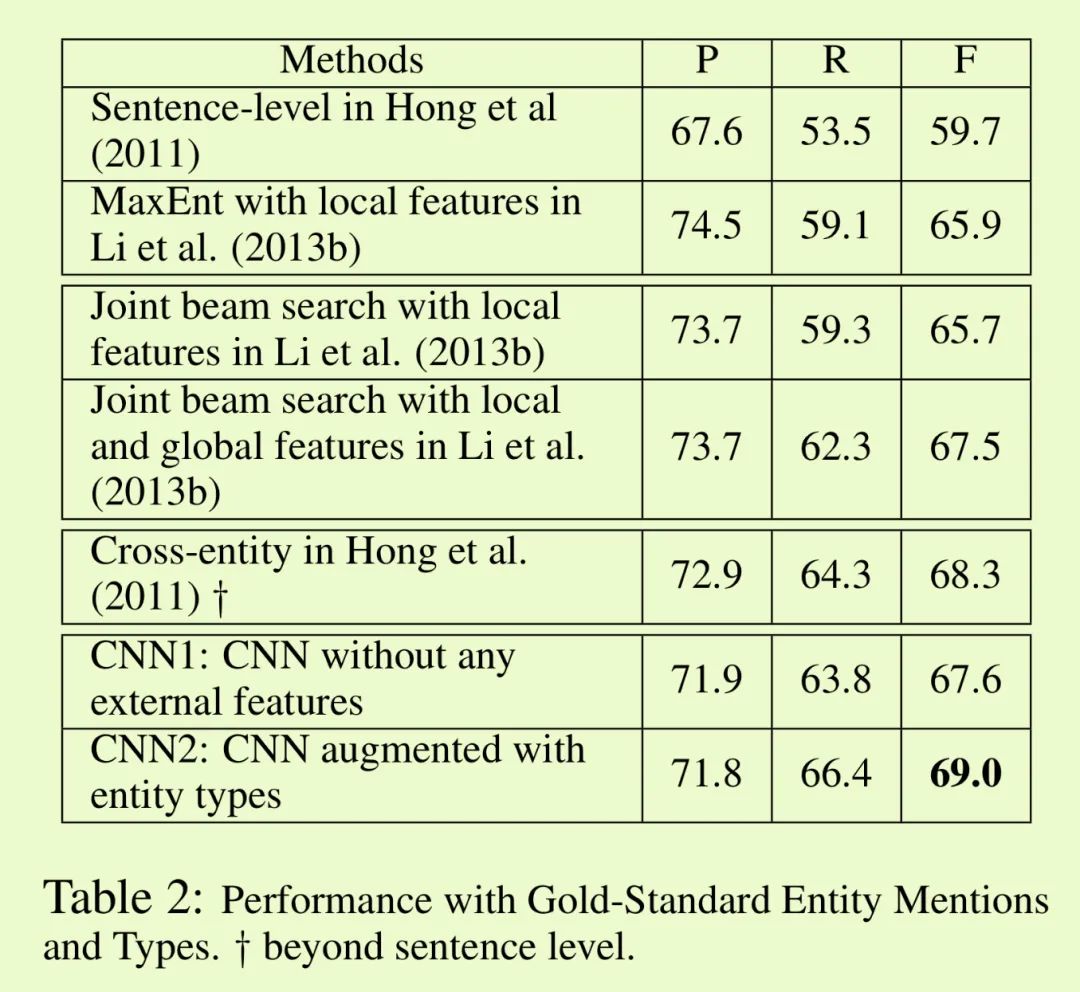
为了验证提出的CNN事件检测模型的效果,作者进行了不同模型的对比实验。CNN2(添加实体类型编码信息的CNN模型)实现了最优的性能。
CNN1(没有添加实体类型编码信息的CNN模型)的性能也比绝大多数对比模型的性能更优。
6 领域适应实验结果
特征工程本质上存在领域适应问题,在源领域进行的复杂的特征工程往往无法用于目标领域。
为了探究CNN方法用于事件检测任务的领域适应性问题,作者进行了一系列对比实验,将ACE 2005数据集中的“broadcast news“和“newswire”文本作为源领域,将“broadcast conversation”、“telephone conversation”和“webblogs”文本作为目标领域。通过在源领域训练模型,目标领域测试模型来评估模型的领域适应性问题。

推 荐 阅 读
参 考 资 料
[1] Tomas Mikolov, Greg Corrado, and Jeffrey Dean. 2013. Distributed Representations of Words and Phrases and their Compositionality. In Proceedings of NIPS.
欢 迎 关 注
由于微信平台算法改版,订阅号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们帮我们点【在看】。星标具体步骤:
(1)点击页面最上方“NLP情报局”,进入主页
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦
感谢支持❤️
原创不易,有收获的话请帮忙点击分享、点赞、在看🙏