
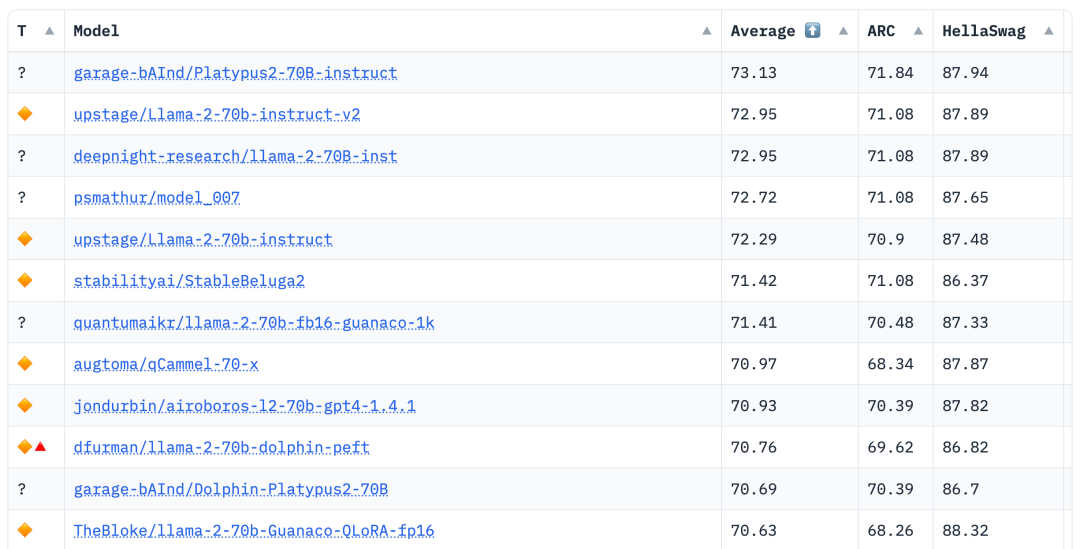
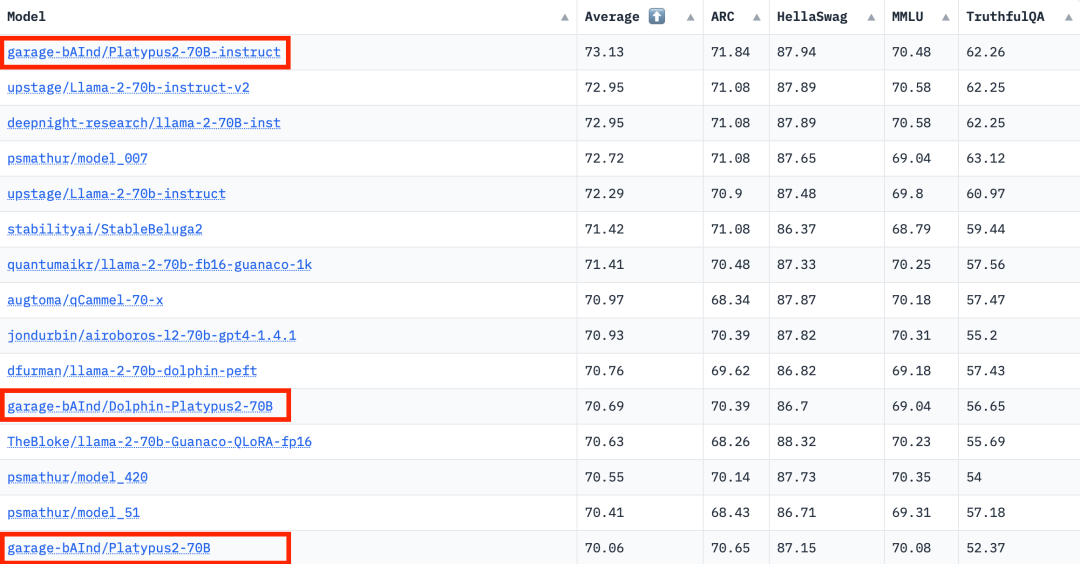
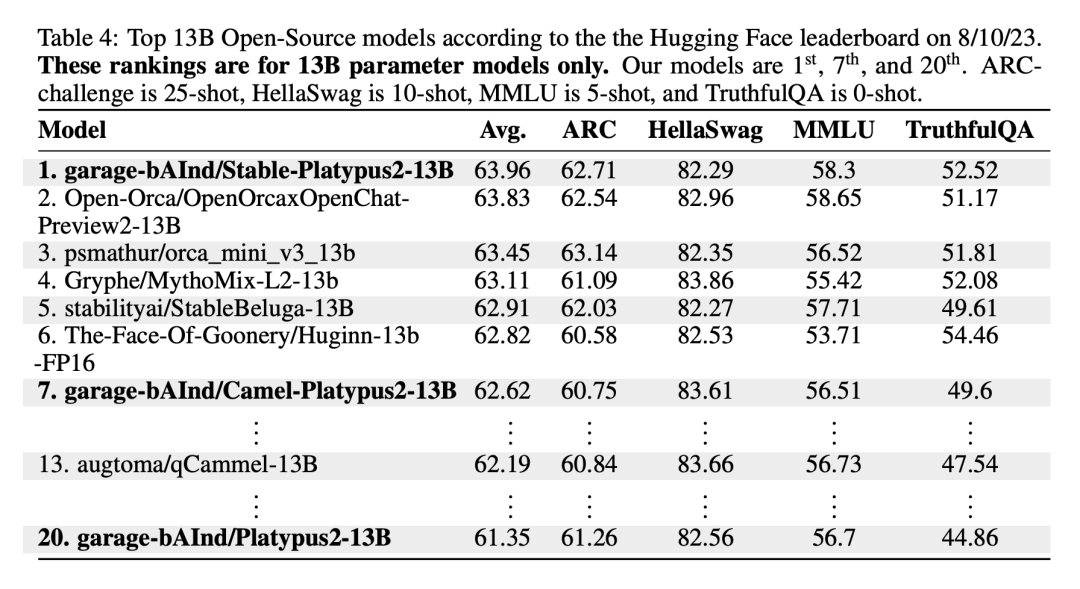
大模型榜单再次刷新,比Llama 2更强的大模型来了


-
Open-Platypus 是一个小规模的数据集,由公共文本数据集的精选子集组成。该数据集由 11 个开源数据集组成,重点是提高 LLM 的 STEM 和逻辑知识。它主要由人类设计的问题组成,只有 10% 的问题是由 LLM 生成的。Open-Platypus 的主要优势在于其规模和质量,它可以在很短的时间内实现非常高的性能,并且微调的时间和成本都很低。具体来说,在单个 A100 GPU 上使用 25k 个问题训练 13B 模型只需 5 个小时。 -
描述了相似性排除过程,减少数据集的大小,并减少数据冗余。 -
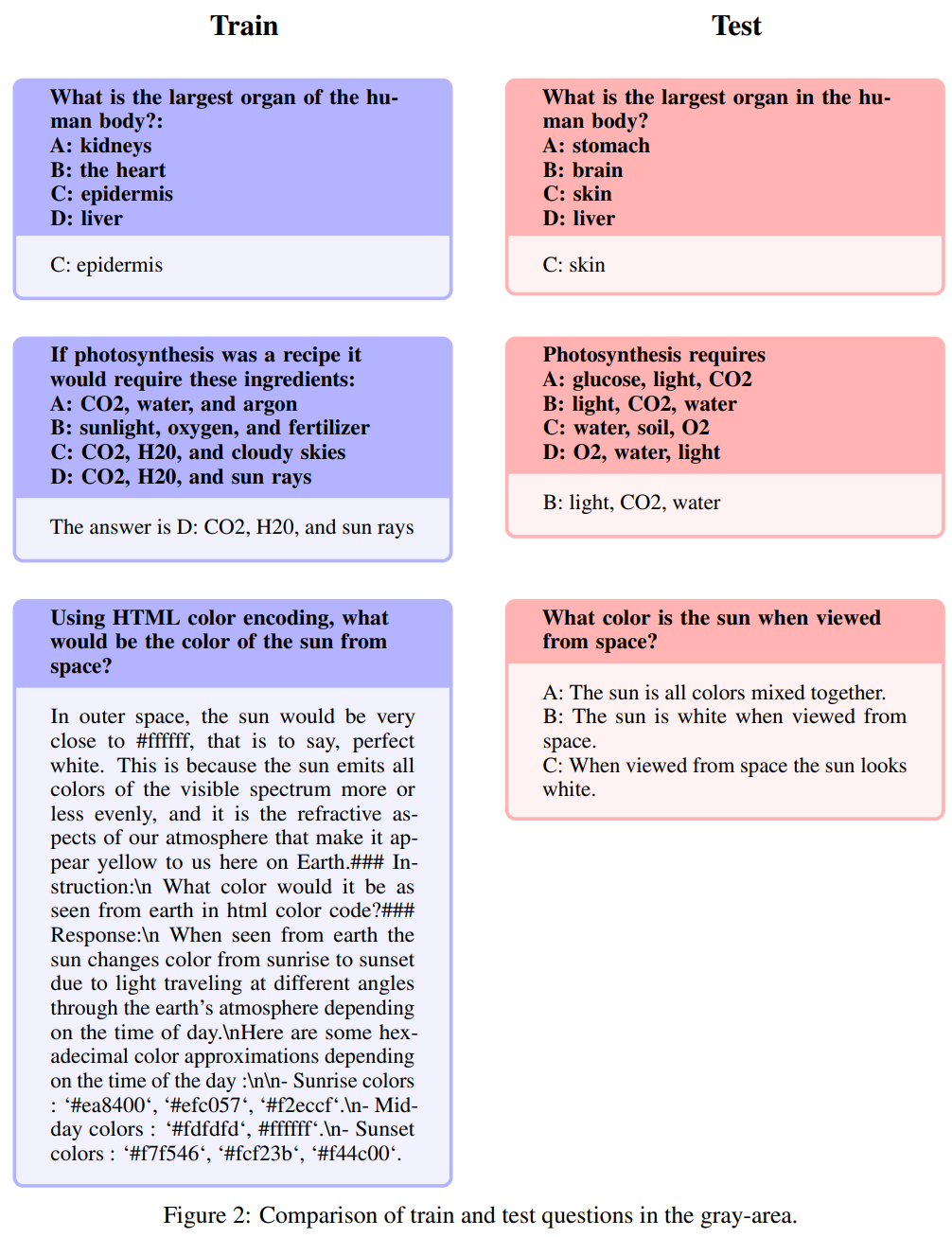
详细分析了始终存在的开放 LLM 训练集与重要 LLM 测试集中包含的数据相污染的现象,并介绍了作者避免这一隐患的训练数据过滤过程。 -
介绍了对专门的微调 LoRA 模块进行选择和合并的过程。




分享
收藏
点赞
在看
评论