爱奇艺视频如何使用微服务的?
共 5537字,需浏览 12分钟
·
2020-07-27 19:34
点击“开发者技术前线”,选择“星标?”
在看|星标|留言, 真爱


一次小的需求,评估由此产生的影响成本超过开发需求本身。
系统几经交接或升级,接口文档丢失或跟代码严重不符。
每天疲于排查线上问题和修复线上数据,没有精力代码优化。
由于创建/开发/部署新服务的成本,不断的将无关的功能添加到臃肿的服务。
线上服务一个功能或者中间件的中断,导致整个系统不能提供服务。
每次新功能的技术选型总需要迎合现有系统的技术架构做让步。
如何拆分服务,服务拆分时,主要考虑的因素
如何选择微服务框架,微服务技术选型时,主要考虑的因素
我们选用的微服务框架/公共组件原理及解决的问题
业务拆分,微服务化的核心目标之一是业务逻辑内聚,系统边界清晰,便于需求迭代、代码重构和应对变化。所以,大部分时候,服务拆分基于业务划分,如果两个业务模块拆分后,频繁交互,相互依赖,接口定义复杂,则不适合拆分。
重要程度,服务重要程度不同,可用性要求,技术架构,保障级别都会不同。例如,同样是修改视频的操作,控制视频上下线的播控服务和记录视频历史修改的操作记录系统,放到两个独立的服务里,会更合适。
代码复用,对于相同的代码逻辑,不同于公共JAR包依赖,微服务是以独立部署的方式实现代码复用,当公共逻辑发生改变时,只需要升级一个服务而不是所有依赖该JAR包的服务。例如,统一网关服务,作为所有服务的访问入口,为微服务体系内所有服务提供统一鉴权和过滤逻辑。
历史包袱,微服务化不可回避的问题是,遗留系统如何微服务化。鉴于我们大部分系统都是Spring MVC项目或者Spring Boot项目,所以,我们选用Spring Cloud作为微服务框架,对于遗留系统接入成本和开发人员学习成本都很低。另外,对于少量老的RPC服务,我们通过代理服务统一封装,将其纳入微服务体系内,降低服务调用成本。
核心诉求,有关微服务访问协议,以Spring Cloud为代表的HTTP和以gRPC为代表的二进制协议各有利弊,HTTP规范通用,使用成本低;二进制协议性能更高,节省带宽。我们结合自身的业务特点,相比对性能的严苛要求,更看重较高的开发效率和更快的需求迭代,所以,选择更适合我们的Spring Cloud。
框架成熟度,Spring Cloud在业界也有很多成功企业案例,文档丰富,社区活跃,而且提供了包括服务注册与发现,负载均衡,声明式接口调用,服务熔断,链路跟踪等组件的微服务化完整解决方案。相比之下,近两年新兴起的基于服务网格的微服务框架值得期待,但在成功落地案例和生态成熟度方面,还稍显不足。
使用成本,技术选型另一个要考虑的因素是使用成本,包括使用新技术的学习成本,独立部署服务的运维成本等。我们推进微服务化落地同时,公司服务云的同学提供了大量公共服务组件。其中包括基于Zipkin的链路跟踪系统Rover,基于Flume+ES+Kibana的日志收集系统Venus,基于携程Apollo的分布式配置中心等。为此,我们通过集成他们(而不是重复造轮子)解决微服务化过程中的部分公共问题。

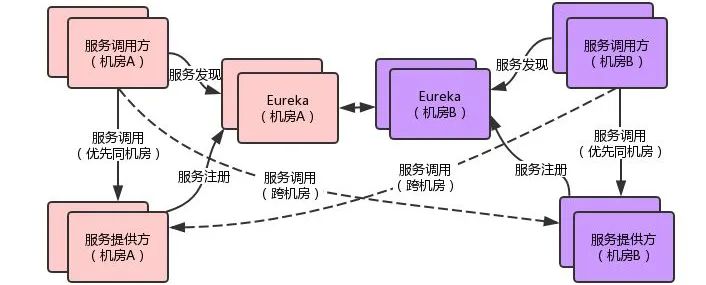
注册中心&负载均衡,服务提供方在注册中心动态注册和注销服务,服务调用方从注册中心发现服务提供方实例列表,并通过负载均衡策略,从中选择一个实例进行访问。我们使用Eureka实现服务注册和发现,使用Ribbon提供客户端负载均衡和重试。通过选用区域感知的负载均衡策略,实现同机房优先访问的跨机房高可用部署方案。
分布式配置中心,微服务通过接入公司配置中心实现配置的集中管理和动态刷新。集中管理一方面可以实现同一服务内,不同实例间的配置共享,另一方面,可以实现不同服务间公共配置的统一管理,比如注册中心的访问地址,框架相关的默认配置等。动态刷新实现服务不重启的情况下,修改配置后,配置立即生效,比如根据实时流量,动态调整分布式限速和Hystrix线程池参数等。
统一网关服务,网关服务作为整个微服务体系的统一入口,提供动态路由配置,资源访问控制和接口级限速。所有注册到注册中心的服务,都可以通过网关,提供对外一致的服务,体系内服务的升级和重构,对服务调用方透明。
接口文档生成,为简化服务提供方编写接口文档的工作,支持需求快速迭代和拥抱变化,我们通过集成Swagger用于接口文档自动生成。开发人员只需定义接口和接口对象,就可以自动生成接口文档并可以直接发起测试,同时支持通过添加注解进行参数校验。
声明式接口调用,微服务化的副作用之一是服务调用更加频繁,为简化服务调用,我们使用Feign支持声明式接口调用。服务调用方只需声明本地接口或者直接引用远端服务定义的接口,无需编写实现,就可以像调用本地方法一样,调用远端服务。

服务熔断,微服务使用Hystrix实现链路熔断和降级服务,使用Hystrix dashboard实时监控Hystrix监控项。所有对外发起调用的地方,都使用HystrixCommand进行包装,防止因为单个服务故障导致其他服务级联故障。我们通过自动内置或使用注解的方式,降低使用Hystrix的门槛。

容器化部署,容器化是微服务的最佳载体,也是云原生应用的标配。我们使用Spring boot开发微服务,并部署到私有云QAE容器中,简化服务开发部署成本的同时,支持横向弹性扩容。公共组件选型时,我们通过选择云原生组件(比如Prometheus)或者简单改造适配(比如XXL-JOB),不破坏整个服务的云原生特性。
持续集成/部署,微服务通过对接公司持续集成工具QCI支持一键构建和部署。提交代码到gitlab后,自动触发构建打包,并上传至QAE应用,节省持续集成时间。
日志收集,日志是我们排查故障和检查程序运行状态的最主要的手段。我们使用统一的日志工具类格式化日志输出,无缝对接Venus日志收集,并将日志引流到专有ES集群,最终在Kibana集中展示和统计分析。
链路跟踪,链路跟踪用于快速定位跨系统调用问题。我们通过集成Spring Cloud Sleuth和公司链路追踪系统Rover,实现跨系统链路跟踪。对于体系内最常用的2种交互方式,Http同步调用和RocketMQ异步消息,自动内置链路跟踪功能。

Metrics监控,Mettics监控用于了解服务运行情况和线上流量分布,可以发现系统潜在问题,并为后续需求迭代和业务决策提供参考。我们引入奇眼/Kibana用作基于日志的Metrics监控统计,同时基于Prometheus实时监控报警也在落地实践中。

健康检查&报警,Metrics监控是基于日志的,如果应用本身有问题,没有产生日志或日志收集本身有问题(断流或延迟),基于日志的监控、统计、报警都会失效。为此,我们针对使用服务云提供的奇眼指针探测,定时检查服务health端点,服务不可用时,第一时间报警通知。
分布式一致性,服务拆分带来的分布式事务复杂性是微服务化最大副作用之一。业界有很多解决方案,比如2PC,TCC,消息事务等,我们结合业务特点,选用基于消息的最终一致性方案,简单有效,只需各个事务参与方保证业务幂等。
分布式限速&分布式锁&分布式调度,我们开发了基于Redis的分布式限速组件,用于在服务入口和资源受限的场景保护我们的系统。基于ZooKeeper的分布式锁,用于解决分布式场景下相同资源的访问冲突题。引入XXL-JOB,用于解决分布系统中的定时调度问题。
提升效率&降低成本,微服务化的目标之一是提升效率和降低成本。微服务化过程中,不同的服务,业务上虽然是相互独立的,但是具有很多相同的横切性关注点。为此我们在微服务的全生命周期的各个阶段,引入多个公共组件来解决这些共性问题。比如,创建服务时,我们使用脚手架,一键生成项目原型;开发服务时,大量使用Spring Boot的自动配置和起步依赖简化开发;提供服务时,使用Swagger自动生成接口文档;调用服务时,使用Feign的声明式接口调用……
服务幂等&重试,分布式系统中,服务调用是最常见的操作。因为两方面的原因,服务调用失败的情况在所难免:一是当服务生产者状态由可用变为不可用,由于各种原因,服务消费者并不能立刻感知到;二是由于各种原因,例如网络抖动,JVM GC,资源受限等导致的访问超时。也就是说,我们不可能保证服务调用百分百成功。服务调用失败后,简单有效的补偿方案是,客户端增加重试。另一方面,服务调用方访问超时,服务提供方处理未必是失败的,为了避免生产者多次处理同一请求产生错误数据,服务提供方必须要做到业务幂等。
资源隔离&限制,我们在进行系统设计和编码时,必须意识到,任何资源都是有限的。比如数据库连接数量,线程数量,接口QPS限速,如果存在多个使用方共享资源的情况,就会出现一个使用方耗尽资源导致其他使用方无资源可用。对于常规的资源隔离,业界有好多最佳实践,比如Hystrix隔离,线程池,连接池使用等,对于系统中使用的其他资源,为避免因为共用资源而相互影响,最好也使用独立的资源。比如大到独立的存储,中间件,小到独立的队列等。
服务监控&数据可视化,微服务化的团队中,比较直接的职责划分方式是,按照服务进行划分,每个人对服务的全生命周期负责,从服务构建,开发测试,打包部署,到运维监控。开发人员编码阶段就应该为后期运维监控做必要的日志埋点,系统上线后,开发人员也应该关注线上运行情况和数据分布,并以此作为后期系统优化和需求迭代参考,促进DevOps形成闭环。
服务高可用&自修复,随着微服务化推进,每个人可能负责几个甚至更多微服务,因为各种原因,单次服务调用失败,甚至短时间内个别服务不可用不可避免,我们不应该每天疲于修复由于服务不可用而出现的数据不一致。提高服务的可用性以及实现故障恢复后系统自修复,总是值得的。为此,我们从存储到中间件,从提供服务到调用服务,从资源隔离到跨机房部署,多个维度进行了高可用方案选型和设计。
写在最后:
最后给读者整理了一份大厂面试真题,需要的可扫码回复“大厂面试”获取。

后台回复“面试” “资料” 领取一份干货,数百技术面试手册等你 开发者技术前线 ,汇集技术前线快讯和关注行业趋势,大厂干货,是开发者经历和成长的优秀指南。