5月29日, DataFunSummit——多维分析架构峰会“HTAP 引擎论坛”如约而至,本论坛由腾讯云数据库技术总监李跃森老师出品。同时,论坛上,腾讯云数据库高级工程师陈再妮带来了主题为“TDSQL在HTAP领的探索与实践”的演讲分享,以下为分享回顾。
随着信息技术的不断发展,同时驱动催生许多新的业务场景,数据库领域也不例外。在当前大数据、云计算等信息化技术推动下,数据库诞生许多类型。关于数据库的分类,第一种分类方式是,可以按照数据库的业务场景划分。一般我们在谈论数据库的时候,首先会问数据库是OLAP还是OLTP?OLAP,即在线分析型处理。OLAP的第一个特点是数据量比较大,一般会要求PB级或者更大的数据量,数据量大了以后,对存储的成本会比较敏感,对数据压缩也会有一定的要求。OLAP业务系统的并发量不会特别的高,但OLAP场景下查询一般都会比较复杂,每个查询需要消耗大量的资源,会要求多个用户之间的查询要减少相互之间的影响,进行资源隔离。类似产品还是比较多的,比如:TeraData、SybaseIQ、GreenPlum、HP Vetica、AWS Redshift,以及现在比较流行的ClickHouse等。OLTP,即在线事务型处理。在线事务处理数据量相对较小,普遍时延要求高并发低时延。OLTP业务系统都是我们核心的业务系统,包括银行、保险、电信这样的实时在线的业务,业务特点决定对容灾能力有一些突出的要求,一般来讲要求99.999%以上的可用性。传统上来讲,我们一般讲数据库都是指:Oracle、IBM DB2、Informix、MySQL,以及PostgreSQL这样的一些数据库。这两年还兴起一个数据库概念叫做HTAP,即混合事务处理和在线分析型数据库。基本的思路是能够在单集群内部同时处理OLAP和OLTP两类业务。
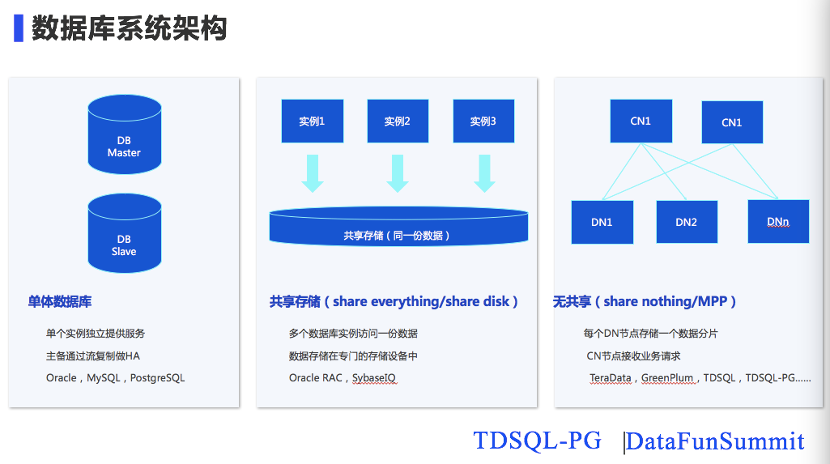
数据库的架构经过多年的演进,大概有三种架构。第一种是单体数据库,所谓单体数据库就像之前我们经常提到的Oracle、PostgreSQL、MySQL这种单机的数据库,单个实例能够提供独立的服务,主备机通过流复制来做HA,这是传统的架构。第二种是共享存储架构,多个数据库实例同时访问一份存储,数据是存储在专门的存储设备中,这里的存储设备一般是指磁盘阵列或者类似于这样专用的存储设备,Oracle RAC是典型这样的架构。第三种是无共享,也就是我们常说的MPP。每个DN节点存储一个数据分片,在DN节点之上会有另外一层节点,这层节点在不同的数据库中有不同的名字,但是它的作用其实是一样的,都是接收业务请求,然后分发,同时对业务请求进行返回。TeraData、GreenPlum、TDSQL都是属于这种架构。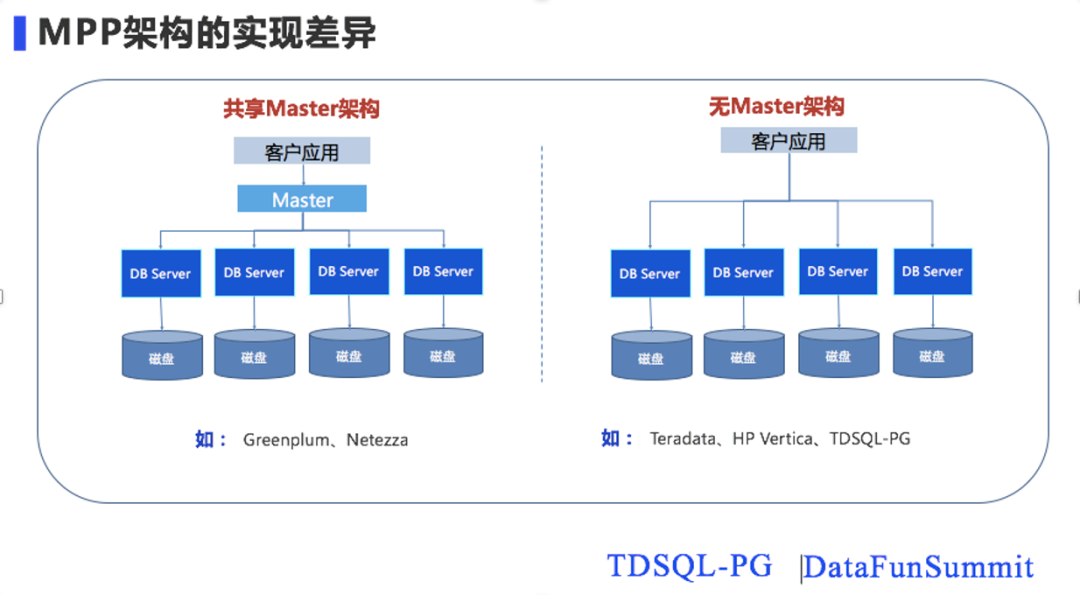
MPP的架构在实现上又可以分为有共享master和无共享master 2类:有共享master的架构,应用程序连接master进行访问,典型的代表产品有Greenplum、Netezza。无共享master的都会有多个对等的访问入口节点供前端应用程序连接访问,典型的代表产品有teradata,hp vertica, TDSQL也是属于无master架构。相对于共享Master架构来说,无共享Master结构有几个特点: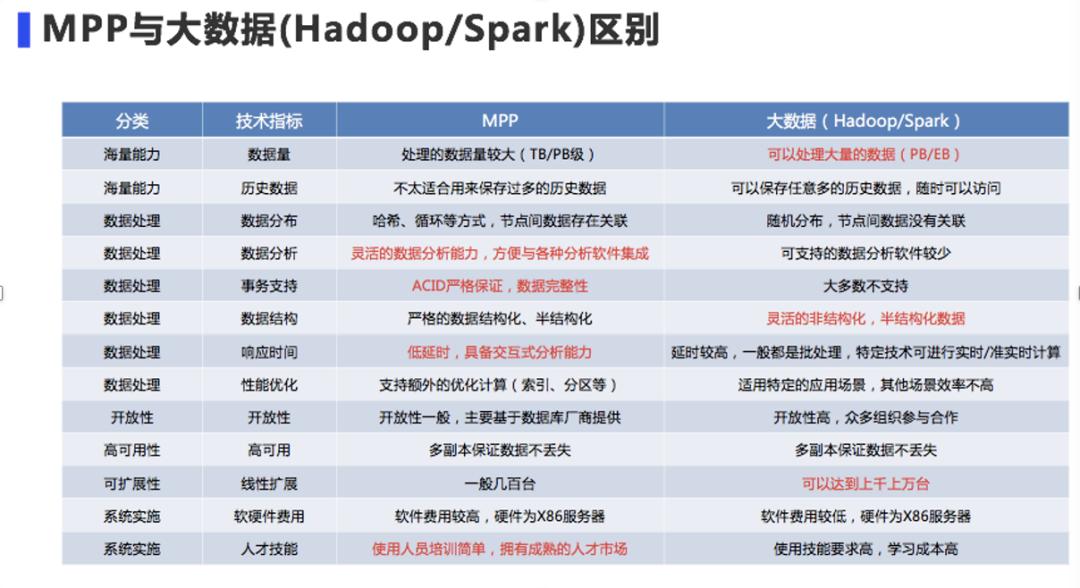
MPP架构的数据库与以hadoop/SPARK为代表的大数据系统的区别在于:大数据技术主要解决的是处理大数据容量,一般可到PB级甚至EB级的数据量,其绝大多数是非结构化/半结构化类型的数据,机器规模可达到上千上万台,在批处理、流处理方面有优势。但在关联分析领域仍有不足,市场上鲜少有可集成的分析软件。而MPP解决的主要是结构化数据,在稳定性、事务ACID严格性、复杂数据处理、关联分析、响应速度等方面具有传统优势,其灵活的数据分析能力,方便与各种分析软件集成。MPP架构的数据库,使用主要是SQL,因此对使用人员培训简单,拥有成熟的人才市场。而相对来说大数据技术对使用人员技能要求较高,学习成本也会更高。企业用户可结合自己的业务特点选择适合自己的技术。
TDSQL-PG 是腾讯基于开源PostgreSQL自主研发的新一代分布式企业级HTAP数据库引擎,全面兼容 PostgreSQL,高度兼容 Oracle 语法。产品采用无共享架构,支持行列混合存储,在提供大型数据仓库处理能力的同时还能完整支持分布式事务ACID能力。
TDSQL-PG经历10余年打磨,可以分为如下几个阶段:单机时代,作为腾讯大数据平台TDW的一个补充,弥补了小数据分析能力的不足;随着业务的发展,单机PostgreSQL的瓶颈逐步凸显,促使团队推出具有良好扩展性和SQL兼容能力的V1版本,并在2015年春节上线微信支付商户系统。后来,TDSQL-PG面向企业市场开放,在V2版本内核支持三权分立,加密脱敏等多项安全特性,在2018年实现数字广东等多个标杆客户应用;TDSQL-PG V3版本定位HTAP,并在2019年上线PICC集团核心业务。去年发布的V5版本内核具备Oracle兼容和读写分功能,并投产上线运营商系统。
- 第一个是业务特征,如果业务满足这些特征,那TDSQL-PG是非常适合的——在数据量上,OLTP超过1T,OLAP场景数据量超过5T;并发连接数超过2000,峰值业务100w/s;需要在线水平扩展能力;此外还需要同事兼顾OLTP以及OLAP的HTAP场景;并且需要严格的分布式事务保证;
- 第二个是业务的场景,TDSQL-PG在HTAP场景、地理信息系统,以及实时高并发、数据库国产化等场景也是很好的选择。
TDSQL-PG采用share nothing的MPP架构,具备良好的扩展性和性能。其整体物理架构分三个部分:图中的左侧上层GTM是事务管理器,它主要是提供全局事务的信息,同时管理全局对象。另外图中右侧上层Coordinator(协调节点CN),它主要提供业务访问入口。协调节点中每个节点之间是对等的,也就是说业务访问这三个节点里面的任何一个,它得到的结果都会是相同的,而且访问这个节点,事务的一致性能够得到保证。图中间的数据交互总线将整个分布式集群的各个节点的数据有机的联合起来,负责整个集群中所有节点数据的交互。图中下层是数据节点,数据节点有些是我们实际存储数据的地方;每个数据节点会存储一份本地的Local元数据,同时还有本地的数据分片,所有数据分片组合起来形成完整的用户数据集。最左边和最下层主要是管控系统的功能,负责对集群节点资源分配,监控告警、运维管理等。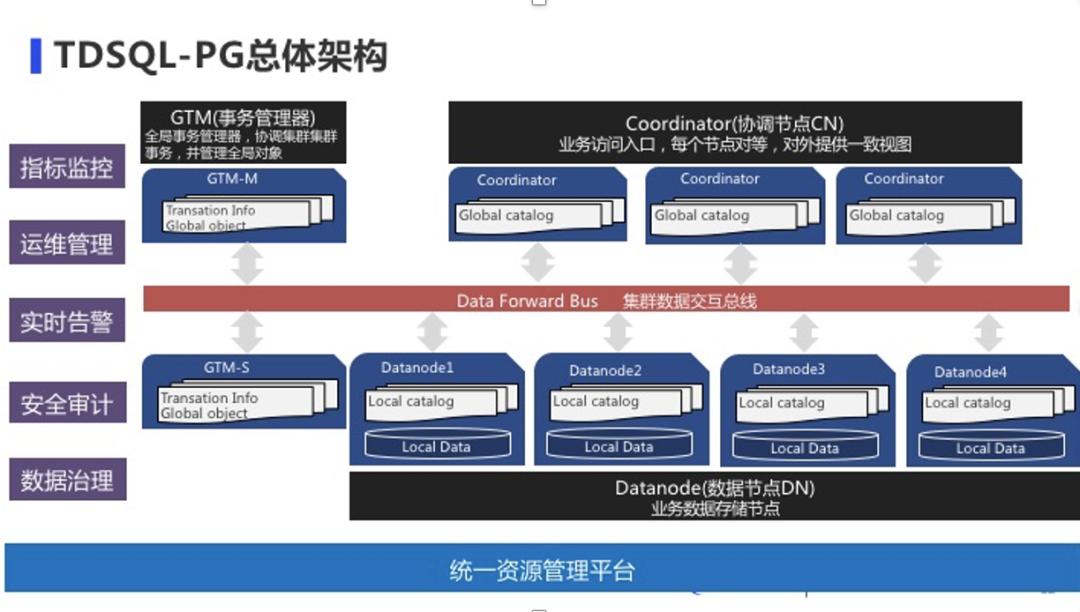
分布式数据库关心的一个很重要的问题就是查询问题,在MPP架构下每个DN的数据都是不完整的。为了完成一个完整的分布式查询,需要对策略进行选择。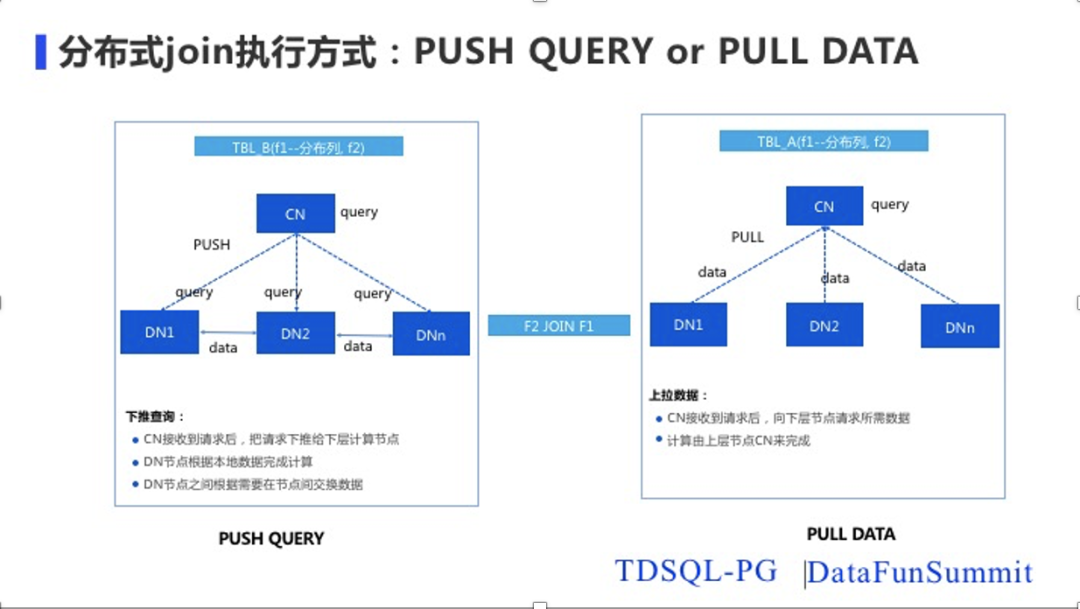
这里策略主要有两种:一种是PUSH QUERY,通过把它的查询下推到DN节点上去, SQL在DN上执行,把数据返回给CN。另外一种方式就是PULL DATA,也就是通过把DN节点上的数据拉取到CN上通过CN来完成所有的计算。数据量较大的时候, PUSH QUERY效率会高很多,PULL DATA在一些数据量比较小的时候,效率会比较好。TDSQL-PG里面两种方式都会有,真正执行时会根据优化器来选择PUSH QUERY或者PULL DATA。
在业务分析场景下,通常会有 2 个或者多个表关联(join)的逻辑,这个在单机实例 中,是一个简单的操作,但是在集群模式下,由于数据分布在 1 个或者多个物理节点中,处理起来也会相对复杂。在很多分布式解决方案中,join 会把数据拉取到一个节点,进行关联计算,这样不仅耗费了大量的网络资源,而且语句的耗时会很高。TDSQL-PG通过多种方式来对 分布式 join 进行高效的计算。下面我们来简单介绍一下 TDSQL-PG分布式 join 的实现原理。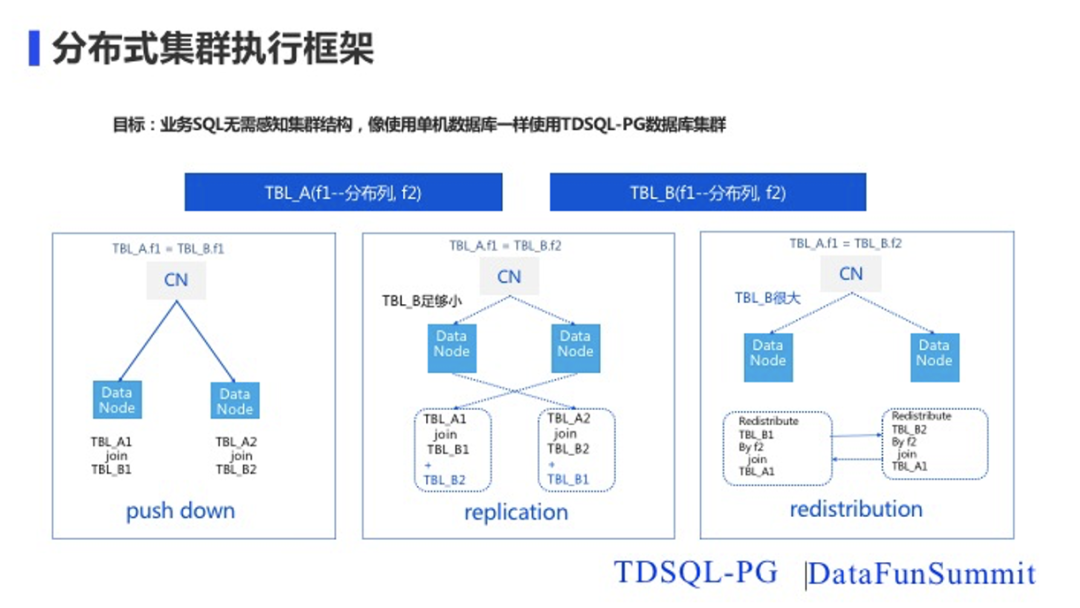
为了介绍原理,我们通过两张表举例子。其中 TBL_A 有两列 f1,f2,其中 f1 为分布 key, TBL_B 也有两列 f1,f2,其中 f1 也为其分布 key。
join 可下推到数据节点的情况,可分为如下两类情况:参与 join 的两张表的 join key 与表的分布 key 相同时,join 可以下推到数据节点进行,例如示例的 SQL 参与 join 的 key 为 TBL_A.f1 以及 TBL_B.f1,这两个 key 也分别为 TBL_A、TBL_B 的分布 key,由于不同的表的数据分布算法是一致的,那么同一 id 的数据位于同一个节点中,那么每个节点单独完成 join 过程,将结果进行汇总即可。分布表与复制表的关联,我们假设 TBL_A 很大,但是 TBL_B 表为一张小表,那么也可以用到 TDSQL-PG的复制表特性,将 TBL_B 定义为复制表,那么 TBL_B 在每个数据节点都有一个完整的副本,join 也是可以下推到每个数据节点自行进行 join 计算, TDSQL-PG的协调节点完成结果的汇总。 接下来讨论最复杂,也就是 join 不可下推的场景:两张表 TBL_A,TBL_B 数 据量都很大,执行的语句为:select * from TBL_A join TBL_B on TBL_A.f1 = TBL_B.f2;该语句不满足前面提到的可下推的两种情况,也即B表 join key 与 分布 key 不一致,也不存在一张小表。前文提到了很多分布式解决方案会把数据拉取到一个节点,进行关联计算,TDSQL-PG并没有采用这种耗费资源且性能不高的方法。那么 TDSQL-PG是如何处理这种情况的呢?在介绍处理方式之前,先介绍一下 TDSQL-PG的分布式执行原理。首先在执行方式上, 协调节点接收到用户的 SQL 请求,会根据收集到的集群的统计信息,生成最优的集群级的分布式查询计划,并下发到参与计算的数据节点上进行执行,也就是说协调节点下发的是执行计划,数据节点负责执行该计划。在数据交互上,数据节点之间建立了高效数据交换通道,数据节点之间可以高效的进行交换数据,这个数据交换的过程在 TDSQL-PG里 称之数据重分布(data redistribution)。有了高效的全局查询计划以及数据重分布的技术支撑,TDSQL-PG就能很容易的发挥并行计算的优势,高效的完成 join 的过程。而在这个例子里面是按照B表的f2字段来进行重分布,来完成整个查询的。为了在一套集群里同时实现 OLTP 以及 OLAP 的融合,那么我们需要做到以下几点:- OLAP 以及 OLTP 业务访问的是同一份数据;
- 资源隔离,保证 OLAP 业务不影响 OLTP 业务的性能;
- 可以针对 OLTP 以及 OLAP 业务做不同的优化。
TDSQL-PG为了实现 OLAP 及 OLTP 的融合采用了如下图的方案,核心思想有如下几点: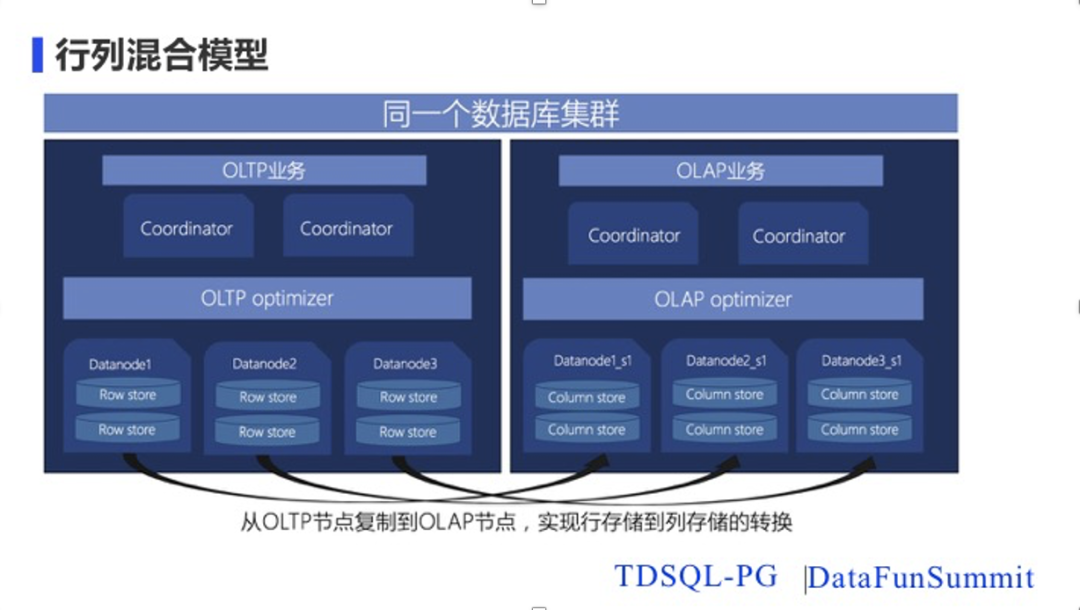
- 在集群的 coordinator 节点提供 OLTP 以及 OLAP 两个平面视角。
- OLTP 业务运行在 datanode 主节点上,OLAP 业务运行在 datanode 节点的备节 点上,二者的数据同步采用流复制的方式来进行。
- OLTP 以及 OLAP 平面针对不同的负载采用合适的存储格式。

作为HTAP系统,TDSQL-PG是支持行列混合存储的:- 按行存储格式,数据按照逻辑顺序相同的方式来来进行文件存储,一行中的所有列数据按照顺序存储在物理磁盘上,这种格式的好处很明显——如果同时访问一行中的多列数据时,一 般只需要一次磁盘 IO,比较适合 OLTP 类型的负载。
- 按列存储格式,表中的每列数据存储为一个独立的磁盘文件,比如例子中,“姓名”, “部门”,“年龄”……每列中的数据都为一个独立的数据文件,这种格式在一次需要访问表中少数列时相比行存能够节省大量的磁盘 IO,在聚合类场景下尤其高效,因此多用在 OLAP 类系统中。
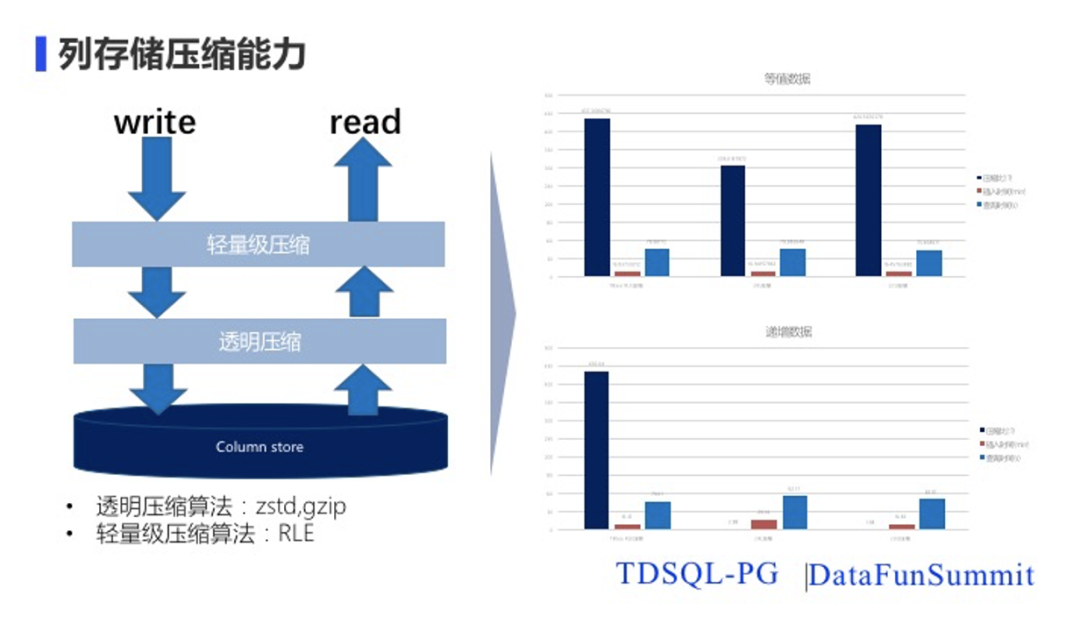
行存储是 TDSQL-PG的基本存储格式,为了支持高效的 OLAP ,TDSQL-PG也提供了完整的列存混合储能力,业务可以根据自己的需要对写入数据库中的数据选择需要的存储格式。第一种是轻量式压缩。轻量式压缩方式首先感知到数据的具体内容,从而针对数据的特点来选用不同的压缩办法提高压缩比,降低业务的成本,当前我们支持RLE的压缩方式。
第二种是透明压缩。这种压缩方式是直接使用包括zstd和gzip直接进行压缩,这种压缩对数据的存储内容没有明确的要求,可以对任何的信息进行压缩。通过数据压缩,可以把数据的体积大幅度减少,一方面减少用户的使用成本,另一方面可以在大量查询分析的时候减少IO访问量,提升我们的查询效率。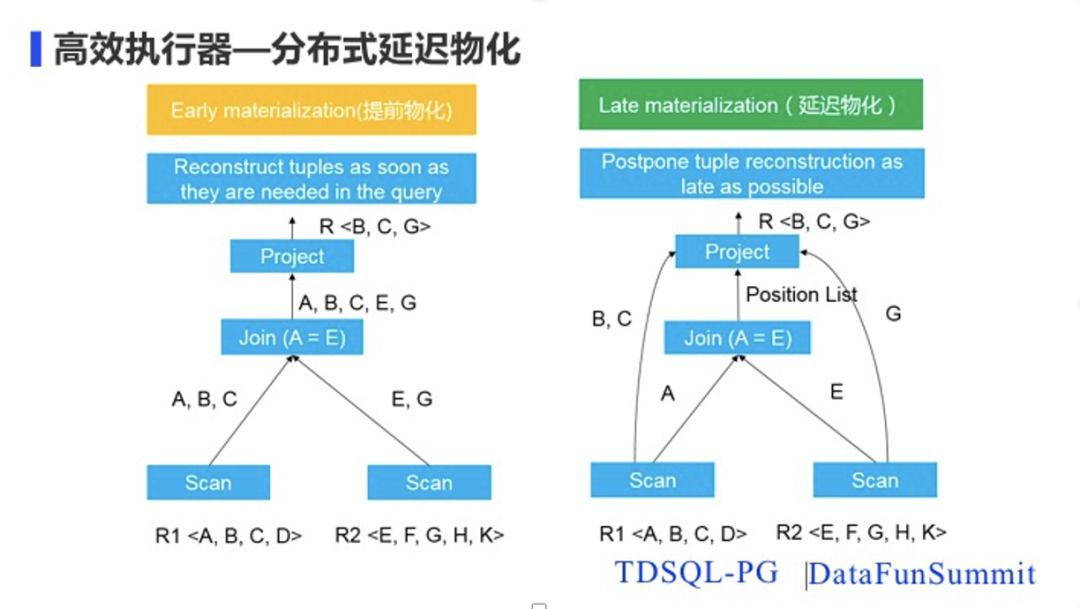
在执行引擎这一层,TDSQL-PG在调研了业界的技术趋势和技术的发展方向之后,在引擎里引入了延迟物化。相对于延迟物化,就是一般常见的提前物化。提前物化就是左边图所示的这样,一开始所需要的投影列和join列都扫描传递上去,这种尤其在选择率非常低时会造成内存cache和网络中非常多的无效数据,增大了cache miss和降低网络数据数据交换的效率。延迟物化会在下层进行Scan的时候,将需要join的列和物理元组的位置信息传到上层节点。只有等上层节点完成Join关联后,在投影阶段再根据满足条件的记录的位置信息从下层拉取需要的数据信息,进而透到外面,从而达到构建元组属性最少、生成元组最少的效果,这种方式可以大幅度地减少cache miss,节省CPU的计算开销和网络IO的开销。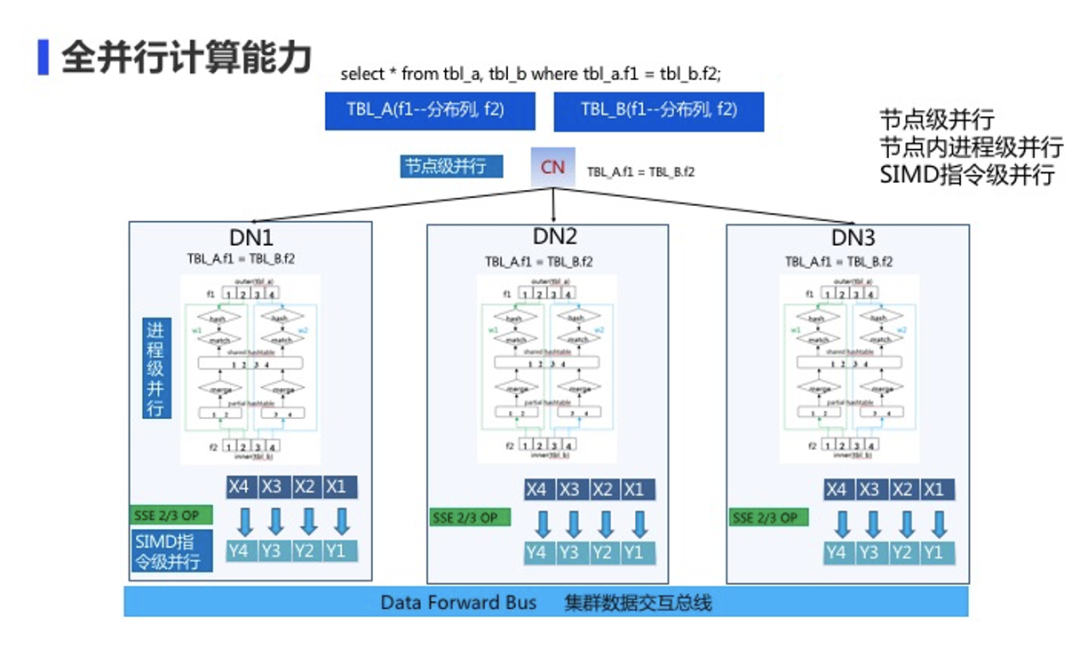
对数据库来说最关键的一点的无疑是高性能计算。以下介绍TDSQL PG在高速并行计算方面的工作。
第一层节点级并行:所谓节点级的并行是,系统拿到一个查询之后,会把查询分发给各个不同的DN,通过DN之间分片区的查询来完成节点级并行;
第二是进程级并行:执行器拿到分配后把算子并行化,即尽量使用允许更多CPU资源来完成查询工作,通过多CPU方式提升查询的效率;
第三层是指令级并行:包括对于CPU的特殊指令、SMD指令等,通过简单的算术运算或者求值,以及通过指定值的优化和并行来提升查询效率。
TDSQL-PG 通过这三层并行去满足复杂查询、实时计算的高性能要求。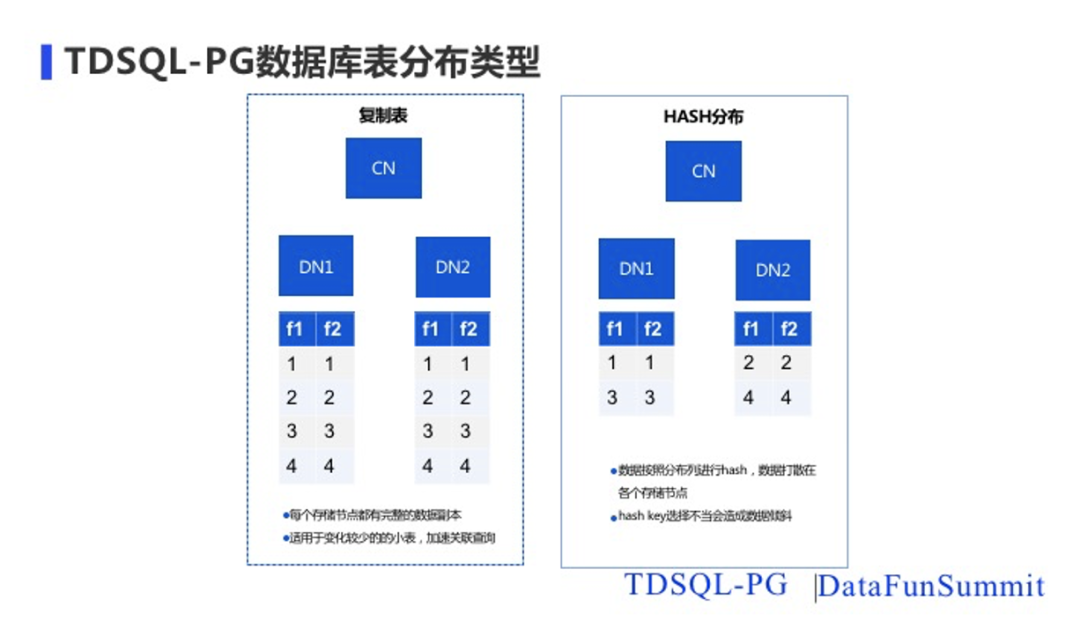
在分布式场景下,我的数据在集群里面如何分布,怎么把数据分片存在我们的分布式集群的各个节点里面去,TDSQL-PG里面叫选择表的分布类型,当前支持2种:第一种是复制表,在集群里面的指定节点上,每个节点都会有数据的完整副本,这样的表特别适合一些变化比较小的小表,对于一些关联查询的加速查询是比较有用的。第二种是HASH分布表,就是把数据写入的存储节点时进行hash打散到不同的节点上去。
但是TDSQL-PG的hash表的数据分布和其他数据库都不一样:其他数据库系统一般都是按照分布键的值hash后对DN节点hash取余后存入对应DN节点,但是TDSQL-PG在数据路由上引入了shard map,取余分母的不是真正的DN节点数而是shard数(一般为2048或者4096,远大于节点数),这样计算出来的值我们叫做shardid, 每个DN节点对应有哪些shardid,我们通过shardmap进行存储。比如这个例子里面的shard数是2048,有2个DN节点,DN1上存储奇数的sharedid数据,DN2上存储偶数的shardid数据。为什么这么做呢,因为考虑到后续的一个扩容问题。
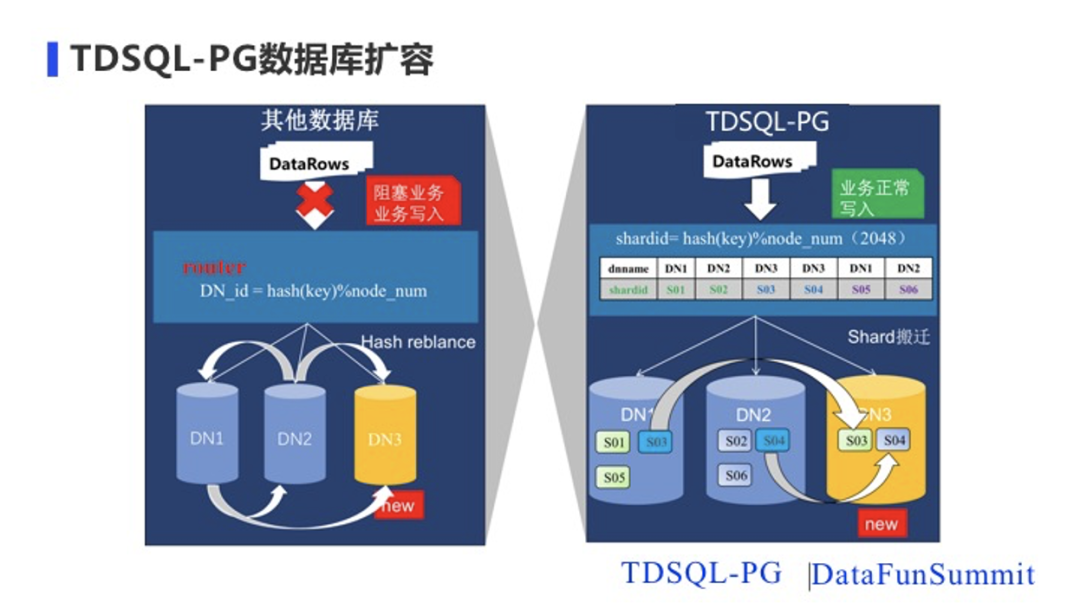
其他数据库系统的数据分布方式,在进行扩容时因为新加了DN3节点,系统的node数量发生了变化,因此数据路由方式也会发生变化,系统中已有的所有数据要重新按照新路由方式进行hash reblance,当数据量比较大时,这个过程会比较久,而且这个过程是需要阻塞前端业务写入的。TDSQL-PG因为引入了shard map,扩容新加了DN3后,只需将原有DN1和DN2上的某些shardid(在这个例子中是s03 s04)数据搬迁过来就行,其他不相关的shardid不发生任何变化,这个过程前端业务可以正常写入,shard搬迁在拷贝完s03 s04存量后可以自动追新写入的增量数据,当追上后刷新一下shard map的路由信息,将s03 s04的映射到新加DN3节点。后续访问到这个shard信息时去DN3获取。此过程对业务完全透明,不影响业务的正常写入。通过上述的这种方式,TDSQL-PG可以方便地做到弹性扩容、缩容、负载均衡,而且可以做到此过程完全业务无感知。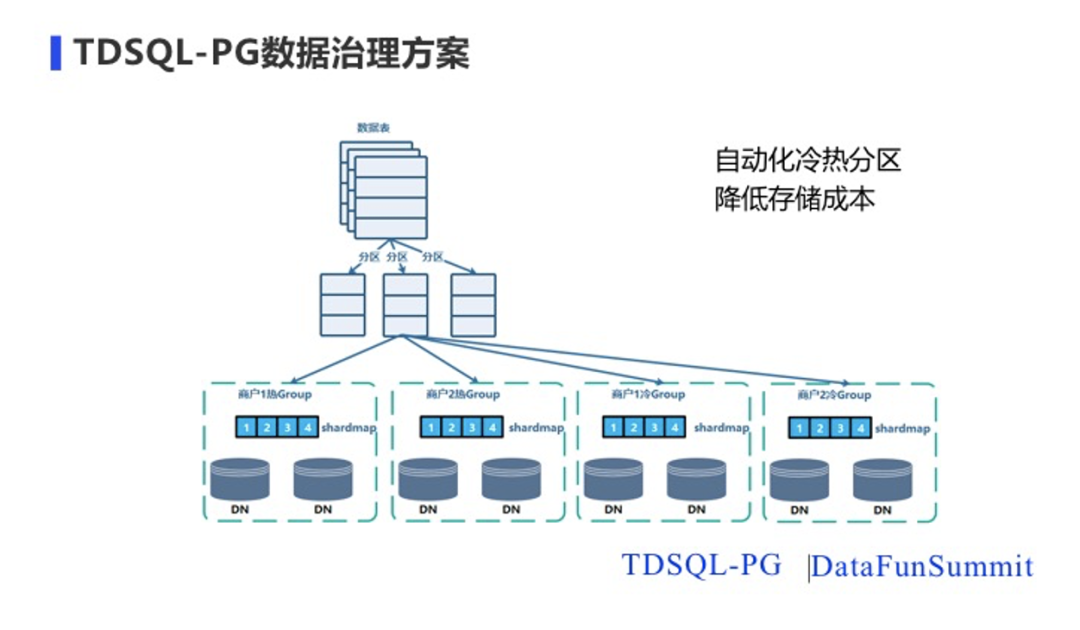
在数据治理方面,因为TDSQL PG支持range、list 、hash 、高性能等间隔分区。TDSQL-PG可通过分区表的方式,将不同子分区存储到不同的节点组,不同节点组关联着不同的机器。通过这样的方案可以将热数据存储在配置好的机器上,冷数据存储在稍微差点的机器上,以此来实现冷热数据的分级存储,降低用户数据的存储成本。
1. 微信支付

TDSQL-PG是在2015年初替换微信支付原有分库分表集群上线,支撑微信支付从每天500万笔到每天超过10亿笔,保证业务稳定性和连续性 ,这里就使用到了数据治理功能。图中最上面是我们CLB,是腾讯内部的一个负载均衡的组件。CLB下面是我们的接入节点CN。在DN数据存储上近4个月的数据存储在配置好的设备上主要使用的是SSD的设备,保证数据访问性能,4个月前的数据存储在普通设备上降低了存储成本。此外还用了大小商户策略,解决不同体量商户数据倾斜问题,有效保证系统的稳定运行。通过这种方式之后,把我们整个业务成本降低到了四分之一左右,帮助业务降低四分之三的成本。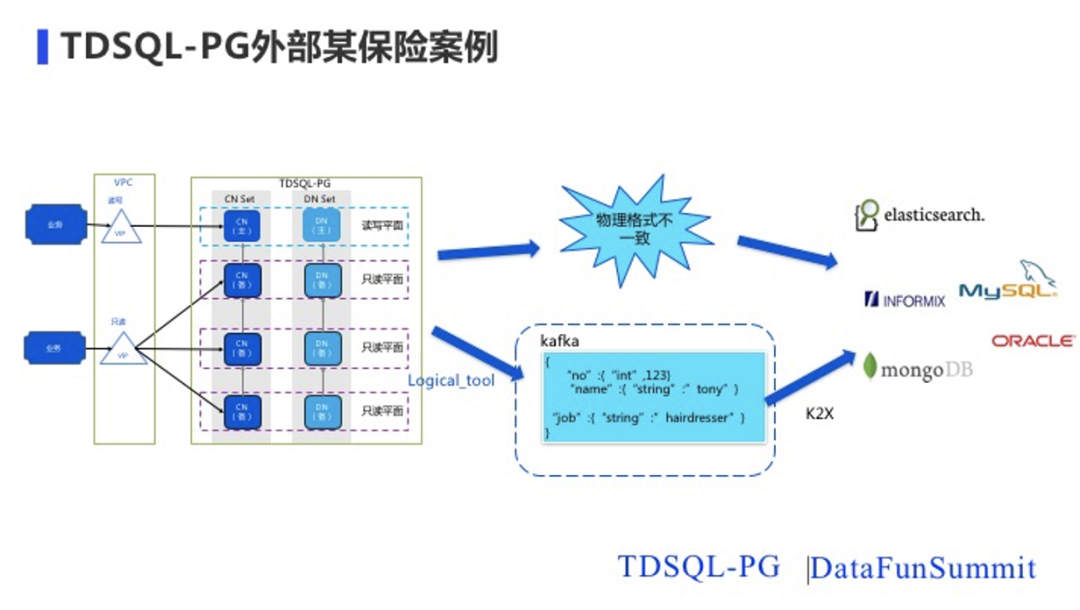
在外部我们有一个比较大的保险公司,然后上线了非常多的实例在跑保险的核心业务,这里只展示了我们的部署架构。我们分为两个平面,一个是读写平面,一个是只读平面。读写平面,业务通过VIP来提供读写能力。我们的只读平面通过业务VIP在多个节点做负载均衡,提供一个业务的只读能力。TDSQL-PG的数据在生成之后,我们还需要把这个数据同步到我们其他的一些系统里面去,比如说ES、INFORMIX、MONGODB或者说Oracle。TDSQL-PG在往这个后面同步数据的时候,其实我们是先通过自己的逻辑解析的数据,把数据解析成了Json格式,通过Kafka同步过去。在2020年在第七次全国人口普查项目中,腾讯云数据库TDSQL支持了十亿级用户数据,以及海量超级大表关联高并发统计查询的场景要求。从第七次全国人口普查开始第一天起,系统每秒查询率(QPS)就猛增到7万,峰值一举达到了11万左右。七人普项目涉及的多张超级大表关联高并发统计查询,其每张表中存放了超过20亿+条记录。如果其中一个表单用来存放平均50万字的书籍,可以放下超过1000万本,一个人终其一生也读不完。在项目里TDSQL-PG承担了非常繁重的分析任务,同时兼具实时数据写入和海量数据计算分析的能力。