
说说 MySQL 子查询

前言
前两天开发找DBA解决一个含有子查询的慢sql,我们通过将其修改为关联查询和添加索引解决。考虑到 大多数开发并没有准确的理解 MySQL 的子查询执行原理。本文介绍如何解决子查询慢查的思路。
原理
首先 知其然,知其所以然。大部分子查询为什么慢?我们得了解 MySQL 关联查询和子查询的处理机制。
MySQL 在处理所有的查询的时候都强行转换为联接来执行,将每个查询包括多表中关联匹配,关联子查询,union,甚至单表的的查询都处理为联接,接着MySQL执行联接,把每个联接再处理为嵌套循环 (nest-loop);
很多使用子查询的人 想当然的认为 子查询会由内到外,先完成子查询的结果, 然后在用子查询来驱动外查询的表,完成查询。例如:select * from test where tid in (select aid from sub_test where gid=3)通常我们会想到该sql的执行顺序为:
a. 先从 sub_test 表中获取 gid=3的记录(3,4,5)
b. 然后和外面的查询做匹配 tid in (3,4,5)。
但是,实际上对于子查询,外部查询的每条符合条件的记录,都会把子查询执行一次。如果遇到子查询查询量比较大或者索引不合理的情况,sql就变慢查。
当我们使用explian查看包含子查询的执行计划时,尤其要注意select_type 字段的内容,如果包含 SUBQUERY , DEPENDENT SUBQUERY 就需要提高警惕。
官方含义为:
SUBQUERY:子查询中的第一个SELECT;
DEPENDENT SUBQUERY:子查询中的第一个SELECT,取决于外面的查询 ,注意如果外部查询的结果集数量比较大,比如几十万上百万,就会执行几十万上百万次子查询,必然造成慢查。
优化策略
MySQL子查询优化策略大致分为:
半连接(semi-join): 半连接优化本质上是把子查询上拉到父查询中,与父查询的表做join/semi-join的操作。关键词上拉。 物化子查询(Materialization):子查询的结果通常缓存在内存或临时表中。 EXISTS strategy:把半连接转换为EXISTS操作。本质上是把父表的条件下推到子查询中关键词下推。
一图胜千言 ,下图展示了 MySQL 针对子查询的优化策略
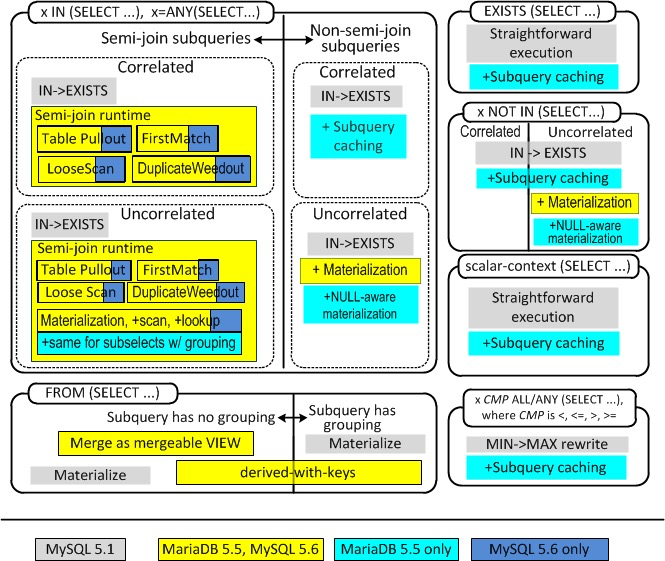
需要对图中做解释的是:
白色区域是常见的 子查询类型, x IN (SELECT ...) ,x= any(select),exists (select )。 白色区域越大说明使用频率越多,比如最常见的子查询是 x IN (SELECT ...) 有颜色的区域表示优化方法和策略,不同颜色代表不同的mysql 分支。
强烈安利 Mariadb 的一系列博客,里面有n篇文章介绍subquery的优化。
书上来的终觉浅,绝知此事要躬行。
优化案例
业务的sql 如下,该sql 执行超过1200ms ,被sql-killer kill掉,影响业务使用。
select app_name,pkg_version,zone,created_at
from activity
where id in (
select MAX(id) AS id
from activity
where zone = 'qa' AND status = 2 AND zanpkg_version != ''
AND namespace = 'qa'
group by app_name,zone)
order by id desc limit 500;
执行计划
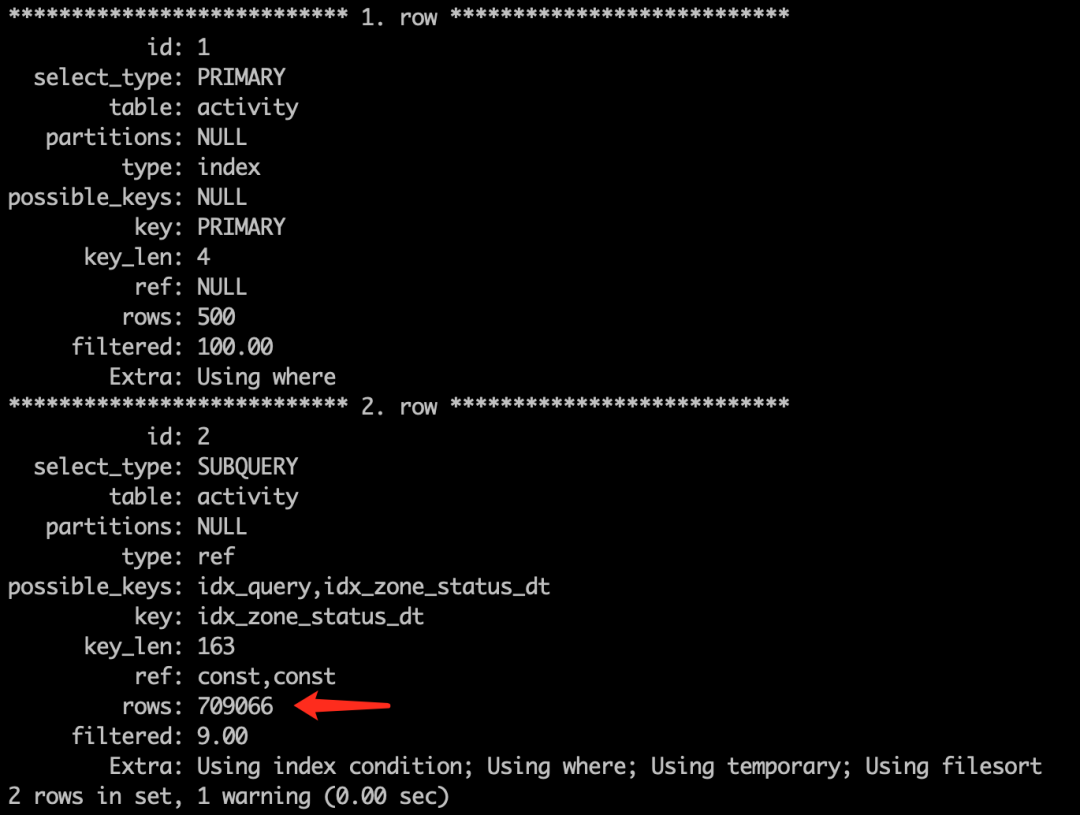
第一步 MySQL 执行 select id, app_name,pkg_version,zone,created_at from activity order by id desc limit 500; 获取一个结果集
第二部 拿第一步中的结果500多行每一个记录去执行 子查询,每次遍历70w行左右。而且子查询里面没有合适的索引。
优化方法
1 where条件中zone=qa是固定值,group by zone 无意义,去掉group by zone。
2 针对 (zone, namespace, status) 加上组合索引。
3 改子查询为关联查询。
select a.app_name, a.zanpkg_version, a.zone, a.created_at
from activity a, ( select MAX(id) AS mid
from activity
where zone = 'qa' AND status = 2 AND zanpkg_version != ''
AND namespace = 'qa'
group by app_name) b
where a.id = b.mid limit 500;
修改之后的sql执行时间在 300-500ms 之间。感觉还是慢,因为要对十几万的数据量做 聚合运算。

参考文章
https://www.cnblogs.com/zhengyun_ustc/p/slowquery3.html https://blog.csdn.net/kk185800961/article/details/49340589
https://blog.csdn.net/fly2nn/article/details/61924636
https://blog.csdn.net/fly2nn/article/details/61924637
https://blog.csdn.net/fly2nn/article/details/61924640
-The End-
往期推荐
推荐一个长期关注于
数据库技术以及性能优化、故障案例分析的公众号