
干货 | 美团推荐算法工程师岗8道面试题分享!

问题1:各种优化器使用的经验
梯度下降:在一个方向上更新和调整模型的参数,来最小化损失函数。
随机梯度下降(Stochastic gradient descent,SGD)对每个训练样本进行参数更新,每次执行都进行一次更新,且执行速度更快。
为了避免SGD和标准梯度下降中存在的问题,一个改进方法为小批量梯度下降(Mini Batch Gradient Descent),因为对每个批次中的n个训练样本,这种方法只执行一次更新。
使用小批量梯度下降的优点是:
1) 可以减少参数更新的波动,最终得到效果更好和更稳定的收敛。
2) 还可以使用最新的深层学习库中通用的矩阵优化方法,使计算小批量数据的梯度更加高效。
3) 通常来说,小批量样本的大小范围是从50到256,可以根据实际问题而有所不同。
4) 在训练神经网络时,通常都会选择小批量梯度下降算法。
SGD方法中的高方差振荡使得网络很难稳定收敛,所以有研究者提出了一种称为动量(Momentum)的技术,通过优化相关方向的训练和弱化无关方向的振荡,来加速SGD训练。
Nesterov梯度加速法,通过使网络更新与误差函数的斜率相适应,并依次加速SGD,也可根据每个参数的重要性来调整和更新对应参数,以执行更大或更小的更新幅度。
AdaDelta方法是AdaGrad的延伸方法,它倾向于解决其学习率衰减的问题。Adadelta不是累积所有之前的平方梯度,而是将累积之前梯度的窗口限制到某个固定大小w。
Adam算法即自适应时刻估计方法(Adaptive Moment Estimation),能计算每个参数的自适应学习率。
这个方法不仅存储了AdaDelta先前平方梯度的指数衰减平均值,而且保持了先前梯度M(t)的指数衰减平均值,这一点与动量类似。
Adagrad方法是通过参数来调整合适的学习率η,对稀疏参数进行大幅更新和对频繁参数进行小幅更新。因此,Adagrad方法非常适合处理稀疏数据。

问题2:python 垃圾处理机制
在Python中,主要通过引用计数进行垃圾回收;
通过 “标记-清除” 解决容器对象可能产生的循环引用问题;
通过 “分代回收” 以空间换时间的方法提高垃圾回收效率。
也就是说,python采用的是引用计数机制为主,标记-清除和分代收集(隔代回收)两种机制为辅的策略。
问题3:yield 关键字作用
yield是一个类似 return 的关键字,只是这个函数返回的是个生成器,可以节省巨大的时间、空间开销。
问题4:python 多继承,两个父类有同名方法怎么办?
super(Classname,self).methodname()或super(Classname, cls).methodname() 调用"下一个"父类中的方法
1、假设类A继承B, C, D: class A(B, C, D), B/C/D都有一个show()方法
a.调用B的show()方法:
super().show()
super(A, self).show()
b.调用C的show()方法:
super(B,self).show()
c.调用D的show()方法:
super(C,self).show()
2.如果在B类中需要调用C类中的show()方法, 也是一样的
class B:
def show(self):
super(B, self).show()
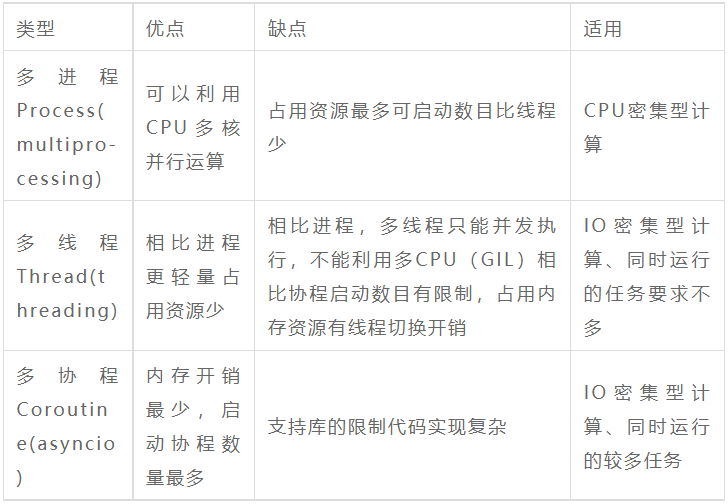
问题5:python 多线程/多进程/协程
问题6:乐观锁/悲观锁
参考:https://zhuanlan.zhihu.com/p/82745364
悲观锁
总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁
乐观锁
总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号机制和CAS算法实现。
两种锁的使用场景
乐观锁适用于写比较少的情况下(多读场景),即冲突真的很少发生的时候,这样可以省去了锁的开销,加大了系统的整个吞吐量。
悲观锁一般适用于多写的场景下。
两种锁的实现方式
乐观锁常见的两种实现方式
乐观锁一般会使用版本号机制或CAS算法实现。
悲观锁的实现方式是加锁,加锁既可以是对代码块加锁(如Java的synchronized关键字),也可以是对数据加锁(如MySQL中的排它锁)。
问题7:coding: 合并两个有序链表
方法一:递归
分两种情况:空链表和非空链表
当其中一个为空链表时,可以直接返回另一个链表
当两个链表都为非空链表时,可以使用下面方法进行递归
代码如下:

时间复杂度:O(m+n)
空间复杂度:O(m+n)
方法二:迭代
首先要设定一个哨兵节点,可以在最后比较容易地返回合并后的链表。
维护一个 pre 指针,根据 l1和 l2 的大小不断更新 prev 的next 指针。
代码如下:

时间复杂度:O(m+n)
空间复杂度:O(1)
问题8:讲下CNN发展史
1、LeNet:
广为流传LeNet诞生于1998年,网络结构比较完整,包括卷积层、pooling层、全连接层,这些都是现代CNN网络的基本组件。被认为是CNN的开端。
2、AlexNet:
2012年Geoffrey和他学生Alex在ImageNet的竞赛中,刷新了image classification的记录,一举奠定了deep learning 在计算机视觉中的地位。这次竞赛中Alex所用的结构就被称为作为AlexNet。
对比LeNet,AlexNet加入了:
(1)非线性激活函数:ReLU;
(2)防止过拟合的方法:Dropout,Data augmentation。同时,使用多个GPU,LRN归一化层。其主要的优势有:网络扩大(5个卷积层+3个全连接层+1个softmax层);解决过拟合问题(dropout,data augmentation,LRN);多GPU加速计算。
3 VGG-Net:
VGG-Net来自 Andrew Zisserman 教授的组 (Oxford),在2014年的 ILSVRC localization and classification 两个问题上分别取得了第一名和第二名,其不同于AlexNet的地方是:VGG-Net使用更多的层,通常有16-19层,而AlexNet只有8层。同时,VGG-Net的所有 convolutional layer 使用同样大小的 convolutional filter,大小为 3 x 3。
4 GoogLeNet:
提出的Inception结构是主要的创新点,这是(Network In Network)的结构,即原来的结点也是一个网络。其使用使得之后整个网络结构的宽度和深度都可扩大,能够带来2-3倍的性能提升。
5 Resnet
ResNet提出了一种减轻网络训练负担的残差学习框架,这种网络比以前使用过的网络本质上层次更深。其明确地将这层作为输入层相关的学习残差函数,而不是学习未知的函数。
在ImageNet数据集用152 层(据说层数已经超过1000==)——比VGG网络深8倍的深度来评估残差网络,但它仍具有较低的复杂度。在2015年大规模视觉识别挑战赛分类任务中赢得了第一。

— 推荐阅读 — 最新大厂面试题
学员最新面经分享
七月内推岗位
AI开源项目论文
NLP ( 自然语言处理 )
CV(计算机视觉)
推荐