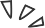语用学如何帮助我们获得更准确地表达

大数据文摘授权转载自AI TIME论道
作者:蒋予捷
语言涌现作为语言学的一个分支,主要研究语言交流的动态性。在对语言动态进行建模时,语言涌现带来更高效的沟通,但是却无法应对短期的语境。而语用学作为语言学的另一个分支,弥补了语言涌现这一缺陷。将二者的计算模型结合起来,语用推理模型融合进涌现的语言系统,是否可以带来更流畅、精确和简洁的表达?
本期AI TIME PhD直播间,我们邀请到了清华大学交叉信息研究院博士生坑易澎分享他的观点。

背景
背景
1.1 语用推理
当人们在沟通的时候,表达的意思是基于语境的。如果听话人脱离语境来理解对话,那么就很有可能误解说话人的意思。语用推理(pragmatic reasoning)就是表述这种现象的语言学术语。更准确的说,语用推理这个词语就是来阐述语言的含义不仅和字面的语义或者语法有关,也和语境有关,另外对话双方相互揣摩的过程也会影响语言含义。
举个例子,如果要描述图1中间的物体使用“blue”这个词还是“circle”这个词更合适?在此语境下,对于听话的一方来说,circle比blue更能明确指代中间物体,说话的一方揣摩到了这一点,所以也会使用circle这个词,尽管blue也是这个物体的重要特征。
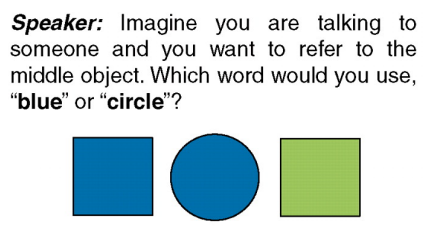 图1 语用推理例子
图1 语用推理例子
1.2 语言涌现
语言涌现(emerging language)是另外一个语言学中的概念。语言涌现顾名思义就是表示人类语言系统的发展。远古时代可能是没有语言或者是有比较低级的语言,通过人们在互相合作过程中不断交流,逐渐演化出如今使用的语言系统。
Lazaridou等人在2018年试图用神经网络构建agent来模拟语言涌现的过程。图2描述了一个听话人和一个说话人通过语言来交流两个物体信息这样一个场景。具体任务就是说话人描述一个物体,然后将描述的信息发送给听话人,听话人试图去了解说话人想要描述哪个物体。
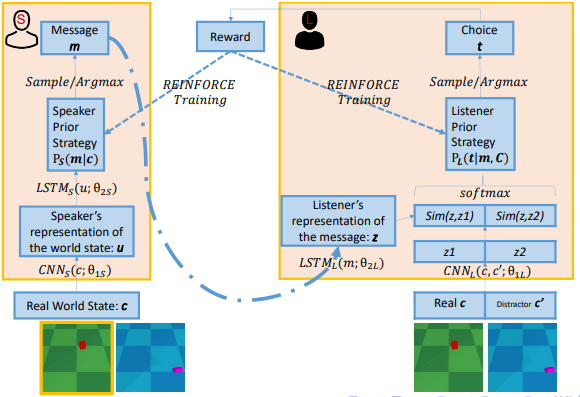 图2 语言涌现的神经网络模拟
图2 语言涌现的神经网络模拟
具体的实现就是每个agent都有一个卷积网络来提取物体的特征,然后通过LSTM或者一些其他的编码和解码的网络来形成语言。在训练时,如果听话人正确地理解了说话人描述的物体,那么双方都会得到正反馈,反之则都得到负反馈。以此在两个agent中发展出一套独有的语言系统。

图3 语言涌现神经网络演化出的语言
最终发展出了图3所示的语言。比如okccc这个词就在描述几乎所有的黄色和白色的物体,而dkccc就是在描述红色和粉色的物体等等。
1.3 互补:语用推理帮助语言涌现
语用推理和语言涌现的共同之处就是说它们都是多个智能体之间互相合作来达到一个有效正确的沟通。不同之处是语用推理主要强调在短期内针对单一具体的对话实例进行推理,而语言涌现则是通过长期大量的对话实例逐渐训练出来的。对应到多体强化学习(MARL)当中,语用推理就相当于stage game,语言涌现相当于stochastic games。
 图4 语言学与多体强化学习的对应
图4 语言学与多体强化学习的对应
这种长期的语言涌现能够给agent带来符合进化的语言习惯,但是却有时无法在理解在特定语境中的语言。而语用推理就能使得对话依赖于语境,那么把短期的语用推理放到长期的语言涌现框架当中,针对每一个具体的对话实例进行优化,是否能带来效果呢?
语用模型
语用模型
2.1 基础语用模型
在Lazaridou等人的基础上,在基本的框架下对每一个具体的实例调整策略,以达到一个更加成功的沟通。同时为了避免语义漂移(language drift),需要说话人和听话人的语言策略差距不能太大。
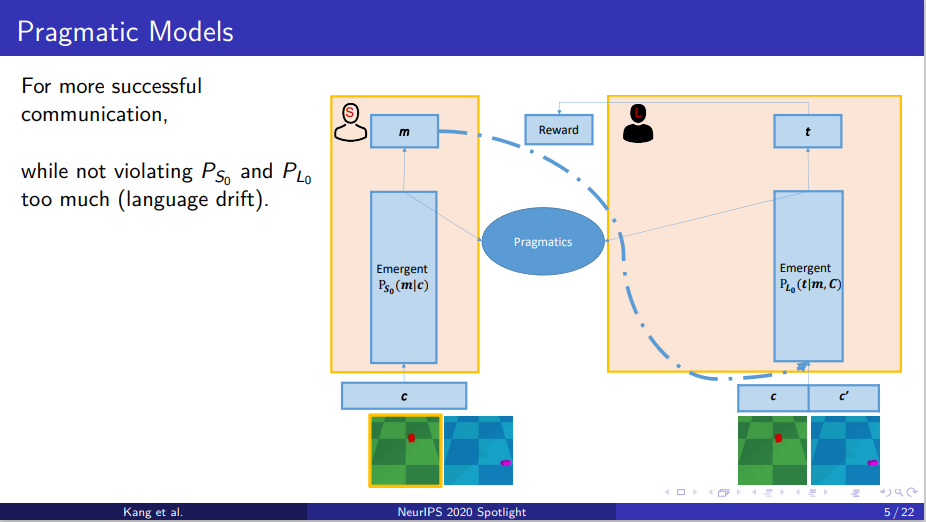 图5 基本的语用模型
图5 基本的语用模型
2.2 单侧语用模型
类似于Andreas和Klein2016年的工作,讲者首先提出了一个比较简单的SampeL模型。在SampleL模型中,听话人根据自己的先验知识来判断说话人给他的信息是哪一个物体。说话人则需要改变自己的策略来让听话人做出正确的决定,但同时不能放弃自己的语言习惯。
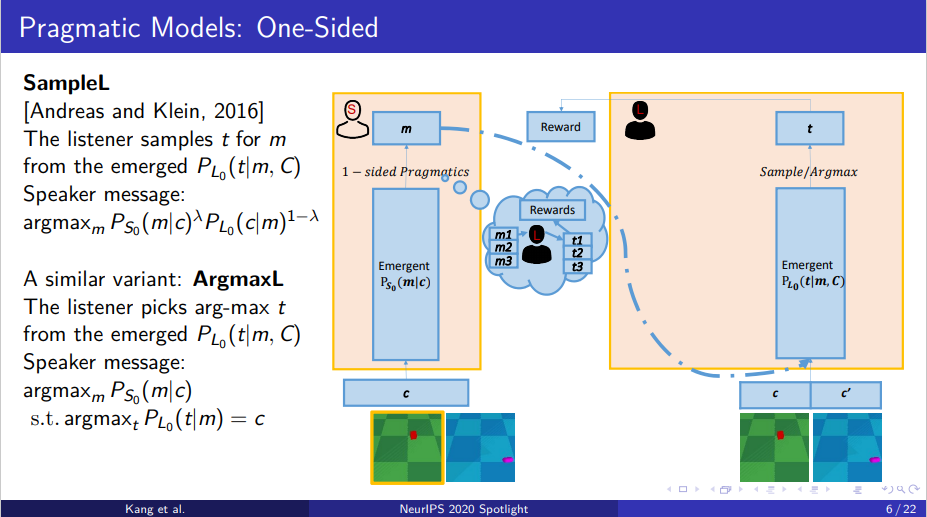 图6 单侧语用模型
图6 单侧语用模型
2.3 双侧语用模型
但是SampleL模型中只有说话人在调整自己的策略,但现实生活中,说话人和听话人都会调整自己的语言来达到更好的沟通。最后得到一个均衡的策略,双方都认可的策略,然后达到正确沟通的目的。
Rational Speech Act(RSA)模型通过贝叶斯条件概率进行策略的迭代。说话人在考虑自己的先验概率的情况下,将听话人的策略当作不变的,以此计算出自己这一轮迭代的策略。听话人也是如此,但是听话人没有考虑自己的先验概率。
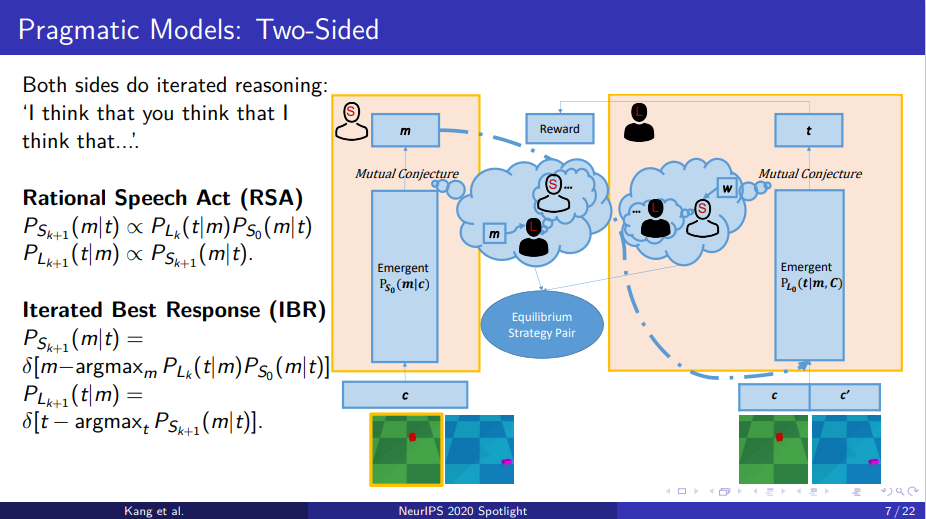 图7 双侧语用模型
图7 双侧语用模型
另一个相似的模型叫做Iterated Best Response(IBR)和RSA模型基本都是一样的,不同在于每轮迭代当中,双方都是选择最优策略,然后把次优的其他的策略置0。
2.4 基于博弈论的语用模型
讲者提出了一个基于博弈论的模型。这样做的理由就是,既然双方想要达到一个关于怎样沟通的共识,那么为何不就把说话人和听话人的策略显式地定义出来,然后找到其中的纳什均衡作为解。说话人的策略就是如何把一个物体映射到的语言消息中,说话者的策略就是每个语言消息应该对应哪个物体。其中的payoff就在于这两个策略是否能带来成功的沟通,并且是否符合之前的语言习惯。
 图8 基于博弈论的语用模型
图8 基于博弈论的语用模型
有了payoff就能建立payoff table并找到其中的纳什均衡。最终如果有单一的纳什均衡或者最优的解,那么这个模型称之为ameTable(GT)。但如果出现了有多个均衡并且无法挑出最优的策略,如何找到最后的解?当一个语言消息在所有的纳什均衡当中都对应的同样的物体,那么听话人和说话人就在这个物体上达成默契了。这个模型称之GameTable-sequential简称为GTS。
实验结果
实验结果
语用模型都是在最初提到的语言涌现模型的基础上改进的 。因为语言涌现模型得出的语言只能分辨颜色,所以为了增加难度,从之前的数据集中挑选出那些相同或颜色相近的物体作为备选物体形成新的数据集来测试语用模型。实验结果如表1所示,其中Acc表示准确性,SP表示涌现出的语言是否符合语言习惯。
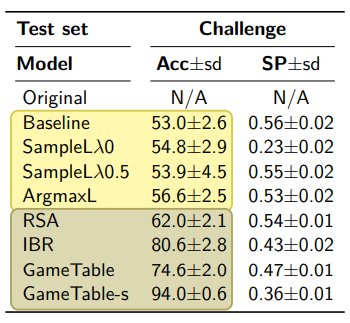
表1 不同语用模型的实验结果
可以看出,所有的语用模型在准确度上都比基本的语言涌现模型高。双侧模型比单侧模型的准确的有明显提高,但是语言习惯的符合程度有所下降。其中GameTable-s模型可以带来最高的准确性,但是代价就是对先验语言习惯符合程度的下降。
 图9 语用模型涌现出的语言
图9 语用模型涌现出的语言
从图9中能看出语言模型让原本比较粗略地涌现出来语言进行一个细化。比如图9左边的三幅图,原来okccc就描述了所有白色或黄色的物体,但是使用了语用模型之后白色的物体很多就被表达成了okdcc,根据物体的颜色细化了语言词汇。相同情况也发生在其他颜色或者位置上面。
虽然准确率很高,但是由于模型在训练的时候双方都是知道对方的语言习惯进行推理,那么这种准确率的提高不就是理所当然的?的确这模型并不十分符合现实。为了让模型更接近现实,双方在训练的时候都对对方建模,把这种虚拟的模型作为自己语言推理的基础。测试改进后的模型得到以下结果。
 表2 改进后与改进前模型训练结果准确率
表2 改进后与改进前模型训练结果准确率
可以看出改进后模型的准确率都是有所下降的,但是准确率依然比语言涌现模型或者是单侧语用模型高。
另一个问题是为什么这些agent必须要遵守一些事先定好的语用规则?解释是RSA还是IBR或者Game Theory都是一种很自然的规则,而且也是在心理学实验中被证实存在的现象。并且在有些情况下,这种语用模型本来就是可以被设定好的,比如在星际争霸二当中,这些 agent想要互相配合去打败对方,他们可以互相沟通,把自己的local Information发给对方,来帮助彼此做出一些决策。
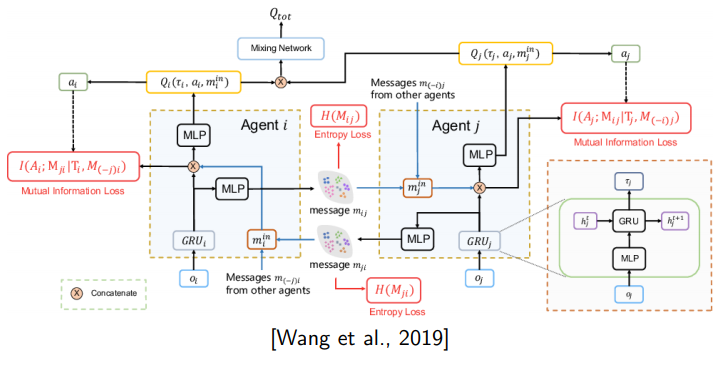 图10 星际争霸二的多体模型
图10 星际争霸二的多体模型
对于agent之间的沟通系统,其实有很简单的语用优化策略,就是每一步agent发送信息的时候,只需要把和上一步的不同之处发过去就好了。那么这本质上就是一种语用规则,这里的语境就是上一步的消息,在这种规则下,那么agent就可以更简洁地进行沟通。
总结
总结


直播回放:
https://b23.tv/A3J0ww
下载本次报告ppt:
http://aitime-lundao.oss-cn-beijing.aliyuncs.com/AitimeReport/20201211/nips1.pdf
Reference: