
生成模型那些事:从 VAE 到扩散模型
1. 为什么叫扩散模型
扩散模型的全称是扩散概率模型,通过将真实数据样本扩散到一个简单分布,再从该简单分布中采样生成新的样本,从而实现生成模型的功能。
简单说,就是化繁为简。模型的学习目标是数据呈现或服从的分布,将复杂分布逐步转移到简单分布,再从简单分布开始逐步生成呈复杂分布的数据。 这里可能有些问题:
这里可能有些问题:
1、何为简单,何为复杂?
一般来说,如果一个事物的概率分布很难用简洁的数学公式或模型来表达,那么我们就认为这个事物是复杂的;反之,如果一个事物的概率分布可以用简单的数学公式或模型来表达,那么我们就认为这个事物是简单的。
一般而言,比较简单的分布有如二项分布、均匀分布,以及更加广泛的正态分布。 还有一层含义是随机变量之间的关系,相互独立则为简单,相关性高则为复杂。
还有一层含义是随机变量之间的关系,相互独立则为简单,相关性高则为复杂。
2、扩散模型这个名头又是怎么来的呢?换句话说,为什么叫扩散模型呢?
Sohl-Dickstein 于 2015 年提出扩散模型,当时其正热衷于研究生成模型,同时又对非平衡热力学感兴趣。扩散模型的灵感来自于物理学中非平衡热力学系统的演化过程。在非平衡热力学系统中,系统的熵会随着时间不断增加,最终达到平衡状态。
非平衡热力学也称不可逆过程热力学,一切不可逆过程都是系统某一性质在物系内部的输运过程,其原因是系统的相应的另一性质的不均匀性,如温差引起热传导、浓度差异引起扩散等现象。
就这里涉及的扩散,我们不妨来举一个例子,即一滴紫色墨水在水杯中扩散的过程。起初,它在一个地方形成了一个深色斑点。此时,如果想计算在容器的某个小体积内找到一墨水分子的概率,则需要一个能清晰地模拟初始状态的概率分布,即墨水开始扩散之前的状态。但这个分布很复杂,因此难以从中采样。
然而,最终墨水在整个水杯中扩散,使其变得淡紫。这导致了一个更简单、更均匀的分子概率分布,可以用简单的数学表达式描述。非平衡热力学描述了扩散过程中每一步的概率分布。关键是,每一步都是可逆的,通过足够小的步骤,你可以从简单分布回到复杂分布。 Sohl-Dickstein 受扩散原理启发提出了一种生成建模算法。这个想法很简单:算法首先将数据集中的复杂图像转化为简单的噪声,这类似于从一滴墨水变成扩散后的均匀浅色水,然后让模型学习如何反转该过程,即将噪声转化为图像。
Sohl-Dickstein 受扩散原理启发提出了一种生成建模算法。这个想法很简单:算法首先将数据集中的复杂图像转化为简单的噪声,这类似于从一滴墨水变成扩散后的均匀浅色水,然后让模型学习如何反转该过程,即将噪声转化为图像。
这里有一点比较有趣,那就是非平衡热力学涉及的是不可逆过程,而扩散模型中神经网络学习的偏偏就是那个逆过程。这其实也不难解释,物理上或许不可逆,但逻辑上考虑这个可逆过程自然是没有问题的嘛。
虽然早在 2015 年就发布扩散模型算法,但当时远远落后于 GAN 的效果。虽然扩散模型可以对整个分布进行采样,但图像看起来更糟,而且过程非常慢。在经过大约四五年的慢慢扩散,孕育出如 DDPM、DDIM 等后续工作,让扩散模型这个方向逐渐趋于成熟。 两个分布之间似乎存在很大的鸿沟,那么扩散模型是如何建模两个分布之间的转换呢?这也是跟其他模型,如 VAE 之类的区别所在,在扩散模型中两个分布之间的转化并不是一蹴而就或一步到位的,而是逐步转换。而且,前向扩散中的每一步的转换可以是固定的,是不需要学习的,只有反向扩散过程才是需要学习的。
两个分布之间似乎存在很大的鸿沟,那么扩散模型是如何建模两个分布之间的转换呢?这也是跟其他模型,如 VAE 之类的区别所在,在扩散模型中两个分布之间的转化并不是一蹴而就或一步到位的,而是逐步转换。而且,前向扩散中的每一步的转换可以是固定的,是不需要学习的,只有反向扩散过程才是需要学习的。
2. 与 VAE 的关系
传统的深度生成模型,例如变分自编码器 (VAE) 和生成对抗网络 (GAN),在学习复杂数据分布时面临一些挑战。其中一个主要挑战是难以找到合适的概率分布来精确表示数据。此外,这些模型通常需要大量的训练数据才能获得良好的性能。
2015 年发表的论文 Deep Unsupervised Learning using Nonequilibrium Thermodynamics,提出了一种基于随机微分方程(SDE)的深度生成模型,通过模拟数据分布的扩散过程来进行无监督学习。
受非平衡统计物理学启发,其基本思想是通过迭代前向扩散过程系统地、缓慢地消除数据分布中的结构。然后,学习反向扩散过程,逐步恢复数据分布中的潜在结构。
该算法首先从一个随机噪声状态开始,然后逐渐模拟向目标数据分布的演化过程。在演化过程中,模型会不断学习数据分布的潜在结构,并最终能够生成与目标数据分布相似的样本。
这种模型的优点是具有高度的灵活性和可计算性,但也存在一些缺点,如采样速度慢,训练不稳定,难以拟合复杂的数据分布等。
2020 年发表的论文 Denoising Diffusion Probabilistic Models(简称 DDPM)对原始的扩散模型进行了改进,通过引入变分推断(variational inference)的方法,将扩散过程分解为两个参数化的马尔可夫链,一个是前向(正向)的扰动数据的链,另一个是反向的恢复数据的链。这种方法的优点是可以有效地最大化数据的边缘似然,提高采样的质量和速度,增强模型的泛化能力和稳健性。
可以说 DDPM 是对原始扩散模型的一种扩展和改进,它解决了前者的一些限制和问题,使得扩散模型成为了一种强大的深度生成模型。
¸ VAE 与扩散模型
本文主要讲述 DDPM 中改进的扩散模型。由于扩散模型一方面也是类似于 VAE,因此我们有必要回顾一下 VAE。
对于生成模型,一般不在数据变量 所在空间直接生成数据,因为它往往位于所在空间中的一个低维流形上。因此生成模型也可以看作是对数据流形的一种参数化,参数所在空间在维度上往往比数据空间要低。 这个时候数据 与参数 是一一对应的,也是确定的,因此是确定性生成模型。然而,VAE 和扩散模型不是确定性模型,而是概率生成模型,数据 与参数 并不是一一对应的,而是对应一定概率。此时的 一般称为隐变量,数据变量和隐变量的联合概率记为 。而参数化好比估计后验概率 。
这个时候数据 与参数 是一一对应的,也是确定的,因此是确定性生成模型。然而,VAE 和扩散模型不是确定性模型,而是概率生成模型,数据 与参数 并不是一一对应的,而是对应一定概率。此时的 一般称为隐变量,数据变量和隐变量的联合概率记为 。而参数化好比估计后验概率 。
回到 VAE,我们的目标是要对数据分布进行建模。首先引入隐变量 ,设定模型并最大化
为了便于计算实际中往往是最大化 ,并求后验概率 以及似然 。然后将数据变量和隐变量的联合概率 边缘化并取对数,
然后再通过最大化数据的证据下限(ELBO)来学习模型的参数。
当然,上述只是针对一个数据点,最终是在整个训练集或小批量数据上训练,也就是最大化 。
现在考虑扩散概率模型,相对于 VAE,这里引入的隐变量不是一个,而是一个系列,可以记为 。所有生成变量的相应联合分布由 给出,一般会写成 ,本文的写法主要是为了突出隐变量。
类似于 VAE,我们有,
简单说,扩散模型是一个参数化的马尔可夫链,使用变分推断来训练,以在有限时间步骤内产生与数据匹配的样本。
¸ 分层变分自编码器
扩散模型可以看作一个特殊的分层式马尔可夫变分自编码器。生成过程涉及的是随机变量的转换,但是扩散模型是逐步转换的,不像 VAE 那么一步到位,因此具有更明确的路线图。具体来说,它是一种分层変分自编码器(HVAE)。
分层变分自编码器是 VAE 的推广,可扩展到含有多个层次结构的隐变量系列。其中的隐变量本身被解释为从其他更高级别、更抽象的隐变量生成。
虽然在具有 层结构的一般 HVAE 中,每个隐变量都可以以所有先前的隐变量为条件,但在这里我们重点关注一种特殊情况,称为马尔可夫 HVAE,即MHVAE。在 MHVAE 中,生成过程是一个马尔可夫链;也就是说,层次结构中的转换都是马尔可夫的,其中解码每个隐变量 仅以先前的隐变量 为条件。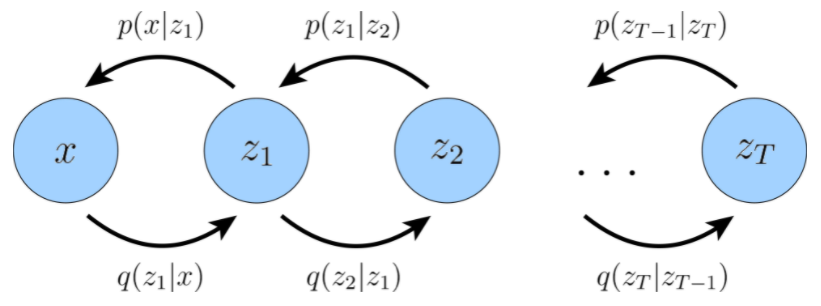 直观和视觉上,这可以看作是简单地将 VAE 堆叠在一起,如上图所示。在数学上,我们将马尔可夫分层变分自编码器的联合分布表示为:
直观和视觉上,这可以看作是简单地将 VAE 堆叠在一起,如上图所示。在数学上,我们将马尔可夫分层变分自编码器的联合分布表示为:
其后验为:
然后,我们可以将 VAE 中的 ELBO 扩展为:
然后,我们可以将式 的联合分布和式 的后验分布代入式 以生成替代形式:
当我们研究变分扩散模型时,这个目标可以进一步分解为可解释的组件。
3. 扩散模型
¸ 前向扩散过程
前向扩散过程对应如下马尔科夫链,
隐变量系列 其中,。我们配上噪声数据和图像数据,就是如下这种图,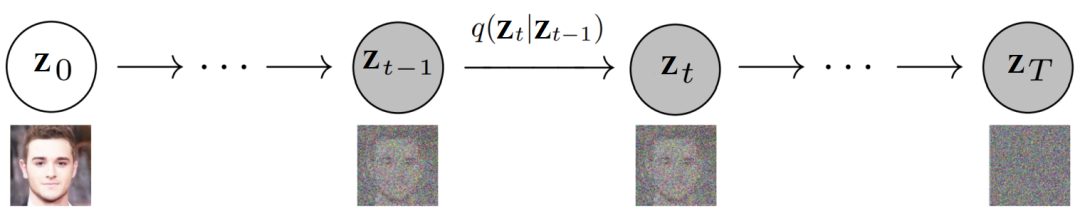 具体来说,前向扩散过程中的分布 定义为一个马尔可夫链,如下所示:
具体来说,前向扩散过程中的分布 定义为一个马尔可夫链,如下所示:
其中, 被称为前向扩散核(FDK),不像在 VAE 中那样需要学习参数,扩散模型(如 DDPM)中采用如下高斯分布,
-
它定义了前向扩散过程中时间步 处当给定图像 后图像 的 PDF。
-
它表示前向扩散过程中每一步用到的“转移函数”。
此处,有几点需要了解,
1)我们首先从数据集中获取图像:。从数学上讲,它相当于从原始(但未知的)数据分布中采样数据点,即 。
2)前向扩散过程的 PDF 是从时间步 开始的单独分布的乘积。
3)前向扩散过程是固定且已知的,因此不需要学习,所以涉及的分布没有写成 。
4)从时间步 到 开始的所有中间加噪图像都称为隐变量,隐变量的维度与原始图像的相同。
5)用于定义 FDK 的 PDF 是正态分布。
6)在每个时间步 ,定义图像 分布的参数设置为:
-
均值: ;
-
协方差:。
重参数化技巧
首先,我们设定一个前向扩散过程,在总共 个步骤中逐步向样本添加少许高斯噪声,产生一系列隐变量 ,,,涉及的步长由一个预设的方差表 给出。
随着步长 变大,数据变量 逐渐失去其可区分的特征。最终当 时, 等价于各向同性的高斯分布。
下面,我们来看一下这一过程中的具体步骤。
先看前向扩散过程中的某一步,,该步骤可以写为,
其中, 以及 。
从上面公式可以看出该步骤是先将 缩小,再加上方差为 的高斯噪声,因此数据 肉眼可见得逐步被转换成标准高斯噪声。
把上式的 换成 ,则有
沿着这个路子不断展开,可得,
其中, 以及 ,,,, 。
注意,公式中涉及到了两个高斯分布 和 的合并操作,结果是一个新的高斯分布 。上式中,使用重新参数化技巧将来自合并后分布的样本表示为 。
上述过程意味着我们可以使用重新参数化技巧在任意时间步对 直接进行采样。也就是说不需要按逐步加噪方式来操作,我们可以一步到位,直接用 表示 ,
值得强调的是,前向扩散过程是预先固定的,因此并没有参数需要学习。需要学习的正是反向扩散过程中的模型参数,下面就来看看是怎么回事。
¸ 反向扩散过程
模型的前向过程是已知了,如果直接能得到反向过程,那整个模型就有了。然而,前向扩散核 的逆步骤 难以计算。那该怎么办呢?定义一个网络去学呗,也就是 。
反向扩散过程,即生成过程,是逆方向上的一个马尔科夫链,其中每个隐变量 仅从前一个隐变量 生成。
同样配上噪声数据和图像数据,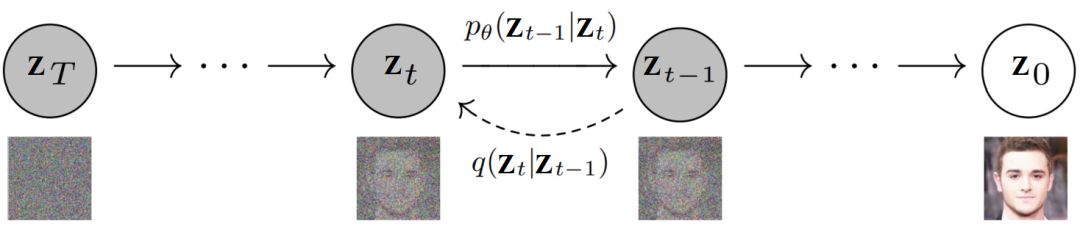 上图中,除了上文提到的前向扩散核 ,还有需要学习的反向扩散核(RDK),
上图中,除了上文提到的前向扩散核 ,还有需要学习的反向扩散核(RDK),
-
它表示给定 后 的 PDF,其中 为逆过程涉及的分布的参数,我们使用神经网络来学习这些参数。
-
它是反向扩散过程中每一步用到的“转移函数”。
我们知道,最终的隐变量的分布 是标准高斯分布。然后我们可以更新马尔可夫 HVAE 的联合分布,而联合分布为:
随着时间步骤的推移,输入数据被逐步加入噪声,直到它变成纯高斯噪声;而扩散模型旨在学习反转这个过程。一旦模型优化好,采样过程就像从 采样高斯噪声一样简单,然后迭代运行 个步骤的去噪转换 ,以生成新的数据 。
¸ 损失函数
目标已经知道了,就是学习一系列反向扩散核,现在就缺损失函数了。
下面,我们主要来看一下在 ELBO 的推导中的关键项。对于任意复杂的马尔可夫 HVAE 中的任意后验,涉及到的 KL 散度项
很难最小化,但在扩散模型中,可以利用高斯转移这个假设来使优化变得容易处理。
由前文可知,我们已经推导出 的公式,当然同时也有 的高斯形式。然后,我们可以将这些公式代入 的贝叶斯法则展开式中,并简化为以下形式:
由此可见, 呈高斯分布,均值 是 和 的函数,方差 是系数 的函数。这些系数 是已知的并且在每个时间步都是固定的。根据上式,我们可以将方差重写为 ,其中:
为了尽可能匹配近似去噪转换步骤 和真实去噪转换步骤 ,我们可以将其建模为高斯分布。此外,由于已知所有 项在每个时间步都被冻结,因此我们可以立即将近似去噪过渡步骤的方差构造为 。然而,我们必须将其平均值 参数化为 的函数,因为 不以 为条件。
然后,利用两个高斯分布之间的 KL 散度为:
在我们这里,可以将两个高斯的方差设置为完全匹配,优化 KL 散度项可以减少两个分布均值之间的差异:
其中, 为 , 为 。换句话说,我们想要优化与 匹配的 ,从式 可以看出,其形式为:
由于 也以 为条件,因此我们可以通过将它设置为以下形式来匹配 :
其中 由神经网络参数化,该神经网络试图从加噪图像 和时间步 中预测原始图像 。
因此,优化问题就简化为:
因此,优化模型归结为学习神经网络去从任意加噪图像中预测原始图像。此外,最小化我们导出的 ELBO 目标在所有加噪水平上的求和项可以通过最小化所有时间步长的期望来近似:
然后可以在时间步长上随机采样的样本进行优化。
另外,最终的损失函数也可以为,
其中, 是一个神经网络,它学习预测源噪声 ,从而确定 和 。根据经验,发现预测噪声会带来更好的性能。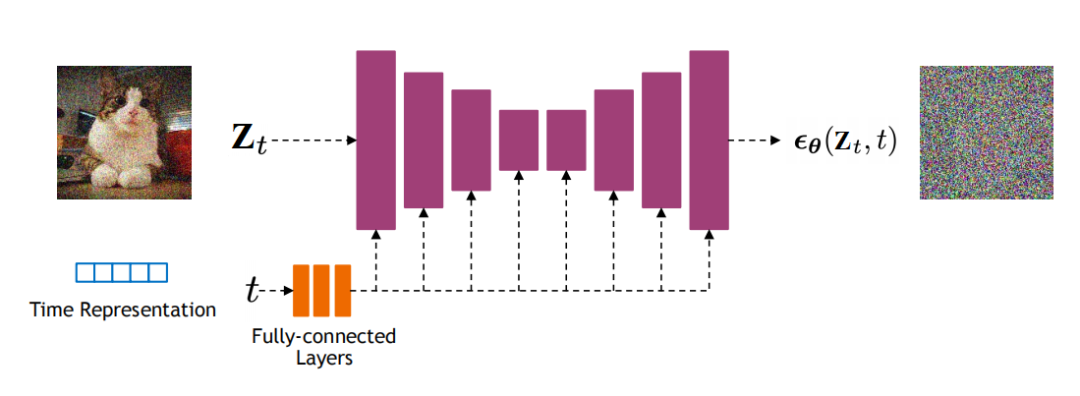
本篇到此告一段落,先对扩散模型有个大致概念,有关扩散模型的更多内容将在后面陆续展开。