
知识蒸馏:如何用一个神经网络训练另一个神经网络
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
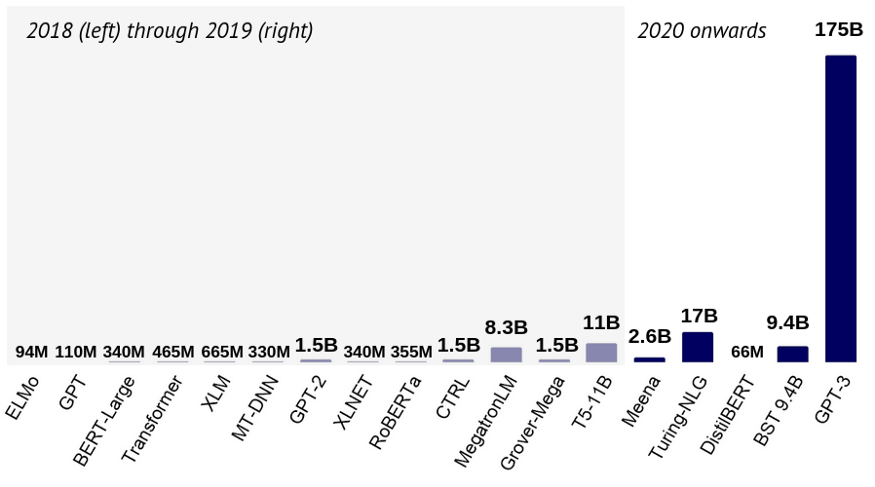
权值裁剪 量化 知识蒸馏
什么是知识蒸馏?
训练一个能够性能很好泛化也很好的大模型。这被称为教师模型。 利用你所拥有的所有数据,计算出教师模型的预测。带有这些预测的全部数据集被称为知识,预测本身通常被称为soft targets。这是知识蒸馏步骤。 利用先前获得的知识来训练较小的网络,称为学生模型。
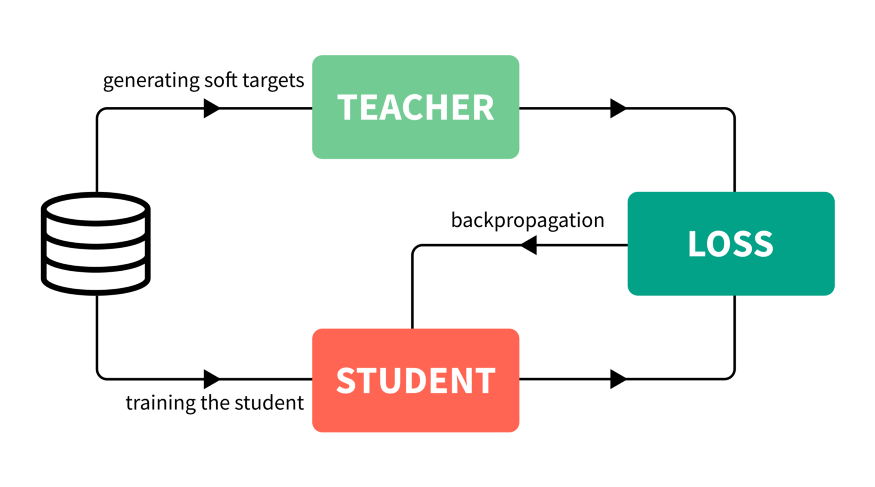
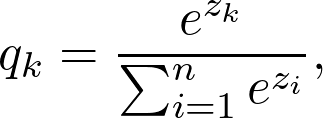
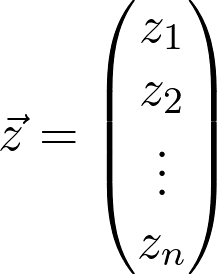
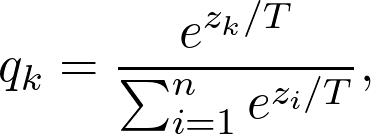
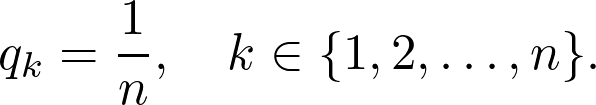
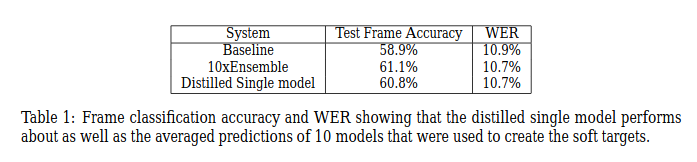
为什么不重头训练一个小网络?

首先,教师模型的知识可以教学生模型如何通过训练数据集之外的可用预测进行泛化。回想一下,我们使用教师模型对所有可用数据的预测来训练学生模型,而不是原始的训练数据集。 其次,soft targets提供了比类标签更有用的信息:它表明两个类是否彼此相似。例如,如果任务是分类狗的品种,像“柴犬和秋田犬非常相似”这样的信息对于模型泛化是非常有价值的。

与迁移学习的区别
“……我们倾向于用学习的参数值在训练过的模型中识别知识,这使得我们很难看到如何改变模型的形式而保持相同的知识。知识的一个更抽象的观点是,它是一个从输入向量到输出向量的学习好的映射,它将知识从任何特定的实例化中解放出来。—— Distilling the Knowledge in a Neural Network
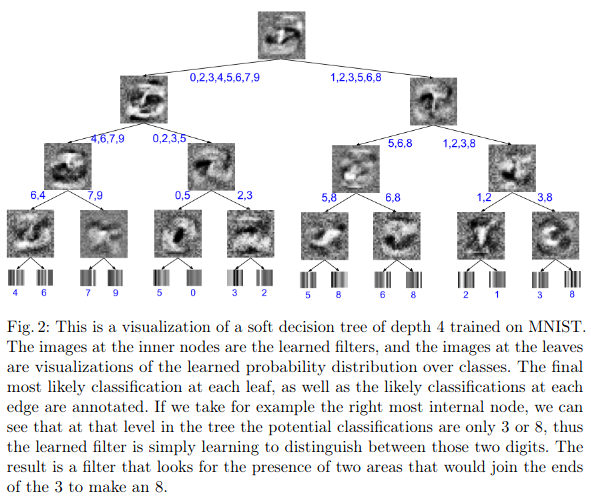
使用决策树
Distilling BERT
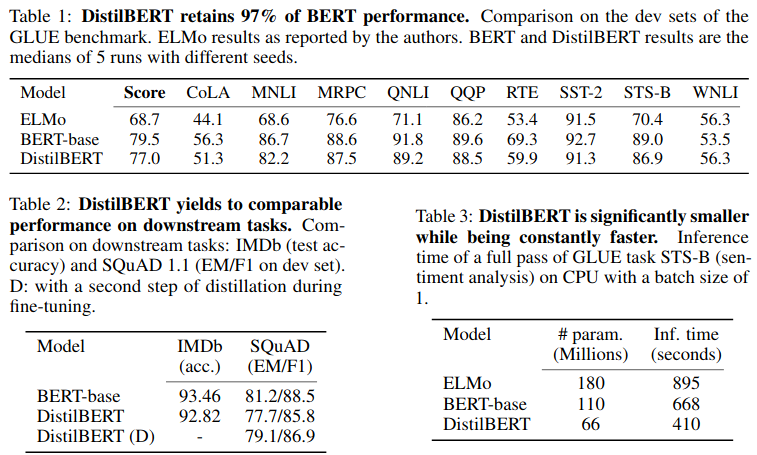
总结
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
评论