
YOLOv5 对决 Faster RCNN,谁赢谁输?
共 3340字,需浏览 7分钟
·
2020-10-18 00:02
重磅干货,第一时间送达
撇开所有争议不谈,YOLOv5 看起来是一个“很有前途”的模型。因此,我将它与 Faster RCNN 进行了比较,Faster RCNN 是最好的 two stage 检测器之一。为了进行比较,我选取了三段背景不同的视频,并将这两个模型并排运行。我的评估包括对结果质量和推理速度的观察结果。那么,让我们言归正传。
YOLOv5 的实现是在 PyTorch 中完成的,与之前基于 DarkNet 框架的开发形成了鲜明的对比。这使得该模型的理解、训练和部署变得更加容易(目前暂时没有使用 YOLO-v5 的论文发表)。以我的理解来看,在架构上,它和 YOLO-v4 很相似。一个不同之处可能是使用了 Cross Stage Partial Network(CSP)来降低计算成本。目前尚不清楚 YOLOv5 的运行速度是否比 YOLO-v4 更快,但我更喜欢 PyTorch 的实现,而且让惊讶的是,使用这个模型进行训练是如此的容易。就我个人经验而言,通过它进行推理的体验也是如此。
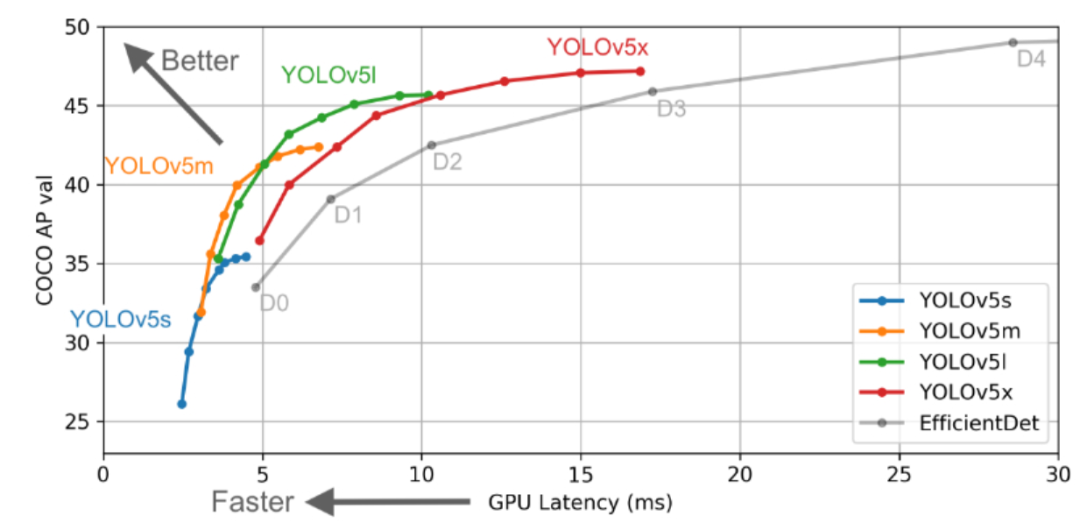
这次发布的 YOLOv5 包括五种不同尺寸的模型:YOLOv5s(最小)、YOLOv5m、YOLOv5l、YOLOv5x(最大)。这些模型的推理速度和平均精度均值(mean average precision,mAP)如下图所示:
第一步就是克隆 YOLO-v5 的 repo,并安装所有的依赖要求。我使用的是 PyTorch 1.5,代码可以正常工作,没有任何问题。
你可以按照以下方法下载不同预训练 COCO 模型的所有权重:
bash weights/download_weights.sh
要对视频进行推理,就必须将传递给视频的路径以及要使用的模型的权重。如果没有设置权重参数,那么在默认情况下,代码在 YOLO 小模型上运行。我使用的示例参数如下所示。
python detect.py --source video/MOT20-01-raw-cut1.mp4 --output video_out/ --weights weights/yolov5s.pt --conf-thres 0.4
输出视频将保存在输出文件夹中。
对于 Faster RCNN 模型,我使用了 TensorFlow Object Detection 中的预训练模型。TensorFlow Object Detection 共享 COCO 预训练的 Faster RCNN,用于各种主干。对于这个博客,我使用了 Faster RCNN ResNet 50 主干。这个 repo 分享了一个很不错的教程,介绍如何使用他们的预训练模型进行推理。
考虑到对自动驾驶行业的重要性,我选择的第一个场景是街道驾驶场景。这两个模型的结果分别如下:

YOLOv5 模型评估驾驶视频

Faster RCNN 评估驾驶视频
YOLO 模型似乎更善于检测较小的目标,在这种情况下是红绿灯,并且还能够在当汽车距离较远(即在透视上看起来较小)将其进行标记。
YOLOv5s 的运行速度(端到端包括读取视频、运行模型和将结果保存到文件)为 52.8 FPS。
而 Faser RCNN ResNet 50 的运行速度(端到端包括读取视频、运行模型和将结果保存到文件)为 21.7 FPS。
以上结果是在 NVIDIA 1080 Ti 上进行评估的。
到目前为止,YOLOv5 看上去比 Faster RCNN 更好一些。

YOLOv5 与 Faster RCNN 的比较(1)
下一段视频是 YouTube 的篮球比赛视频。两个模型的结果如下所示:
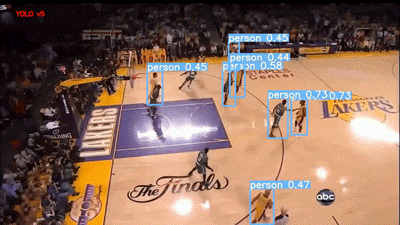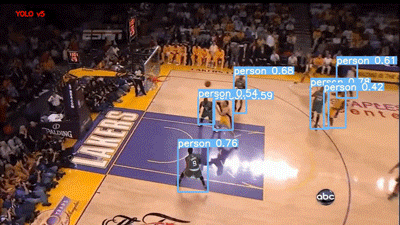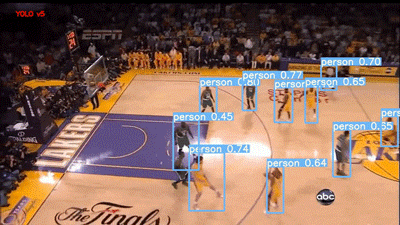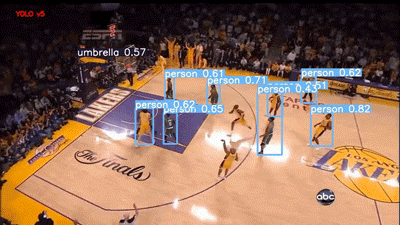
YOLOv5 评估篮球比赛视频

Faster RCNN ResNet 50 评估篮球比赛视频
Faster RCNN 模型在 60% 的阈值下运行,可以说它是用“Person”标签对人群进行标记,但我个人更喜欢 YOLO,因为它的结果干净整洁。不过,这两种模型在视频右下角的 abc(美国广播公司)徽标上都存在假正类误报。
我也很失望,虽然运动球也是 COCO 的类别之一,但这两个模型都没有检测到篮球。它们现在的统计情况如下:
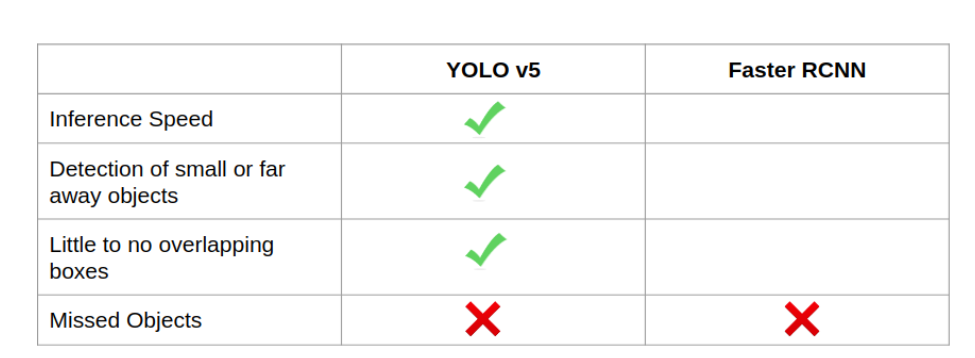
YOLOv5 与 Faster RCNN 的比较 (2)
在最后一段视频中,我从 MOT 数据集中选择了一个室内拥挤的场景。这是一段很有挑战性的视频,因为光线不足,距离遥远,人群密集。这两个模型的结果如下所示:

YOLOv5 模型在来自 MOT 数据集中的室内拥挤场景进行测试

Faster RCNN 模型在来自 MOT 数据集中的室内拥挤场景进行测试
这一次的测试很有趣。我想说的是,当人们走进走廊的时候,这两种模型都很难检测到远处的人。这可能是由于光线较弱和目标较小所致。当人群靠近摄像机方向时,这两种模型都能对重叠的人进行标记。
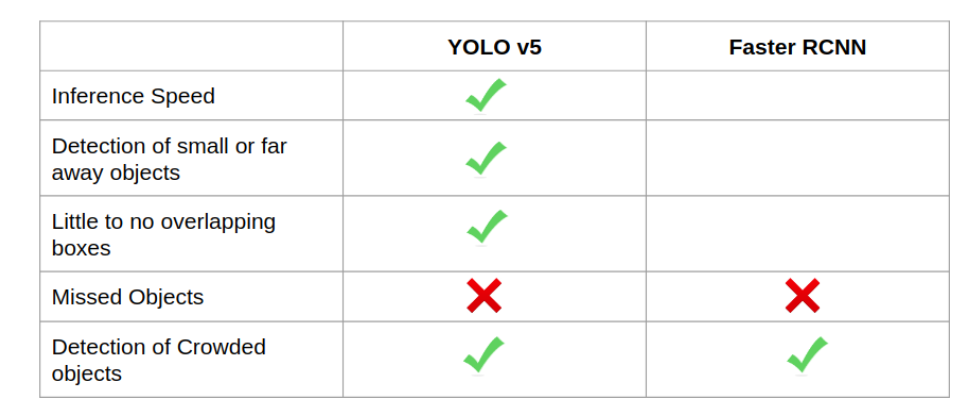
YOLOv5 与 Faster RCNN 的比较(3)
最后对比两种模型可以看出,YOLOv5 在运行速度上有明显优势。小型 YOLOv5 模型运行速度加快了约 2.5 倍,同时在检测较小的目标时具有更好的性能。结果也更干净,几乎没有重叠的边框。Ultralytics 在他们的 YOLOv5 上做得非常出色,并开源了一个易于训练和运行推理的模型。
该博文还显示了计算机视觉目标检测的一个新兴趋势,即朝既快又准确的模型发展。
原文链接:
https://towardsdatascience.com/yolov5-compared-to-faster-rcnn-who-wins-a771cd6c9fb4
转自:AI前线
下载1:OpenCV黑魔法
在「AI算法与图像处理」公众号后台回复:OpenCV黑魔法,即可下载小编精心编写整理的计算机视觉趣味实战教程
下载2 CVPR2020
在「AI算法与图像处理」公众号后台回复:CVPR2020,即可下载1467篇CVPR 2020论文 个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称

觉得有趣就点亮在看吧
