
2022年5月下旬字节跳动风控算法面试题6道|含解析
公众号福利
👉回复【100题】领取《名企AI面试100题》PDF
👉回复【干货资料】领取NLP、CV、ML等AI方向干货资料
👉回复【往期招聘】查看往期重要招聘


问题1:机器学习模型评价指标
泛化能力是模型对未知数据的预测能力。
常见有两种问题:分类和回归。
分类问题:
准确率:分类正确的样本占总样本的比例
准确率的缺陷:当正负样本不平衡比例时,当不同类别的样本比例非常不均衡时,占比大的类别往往成为影响准确率的最主要因素。
精确率:分类正确的正样本个数占分类器预测为正样本的样本个数的比例;
召回率:分类正确的正样本个数占实际的正样本个数的比例。
F1 score:是精确率和召回率的调和平均数,综合反应模型分类的性能。
Precision值和Recall值是既矛盾又统一的两个指标,为了提高Precision值,分类器需要尽量在“更有把握”时才把样本预测为正样本,但此时往往会因为过于保 守而漏掉很多“没有把握”的正样本,导致Recall值降低。
ROC曲线的横坐标为假阳性率(False Positive Rate,FPR);纵坐标为真阳性 率(True Positive Rate,TPR)。FPR和TPR的计算方法分别为
精确度(precision)/查准率:TP/(TP+FP)=TP/P 预测为真中,实际为正样本的概率
召回率(recall)/查全率:TP/(TP+FN) 正样本中,被识别为真的概率
假阳率(False positive rate):FPR = FP/(FP+TN) 负样本中,被识别为真的概率
真阳率(True positive rate):TPR = TP/(TP+FN) 正样本中,能被识别为真的概率
准确率(accuracy):ACC =(TP+TN)/(P+N) 所有样本中,能被正确识别的概率
上式中,P是真实的正样本的数量,N是真实的负样本的数量,TP是P个正样本中被分类器预测为正样本的个数,FP是N个负样本中被分类器预测为正样本的个数。
AUC:AUC是ROC曲线下面的面积,AUC可以解读为从所有正例中随机选取一个样本A,再从所有负例中随机选取一个样本B,分类器将A判为正例的概率比将B判为正例的概率大的可能性。AUC反映的是分类器对样本的排序能力。AUC越大,自然排序能力越好,即分类器将越多的正例排在负例之前。
AUC:随机取一个正样本和一个负样本,正样本的预测值大于负样本预测值的概率。
AUC计算的关键是找到所有正样本预测值大于负样本预测值的正负样本对。首先,需要将样本按照预测值进行从小到大排序(最小score对应的sample的rank为1,第二小score对应sample的rank为2,以此类推);其次,把所有的正类样本的rank相加,再减去两个正样本组合的情况。
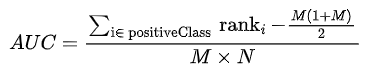
回归问题
1、平均绝对误差(MAE)
2、均方误差(MSE)
3、均方根误差(RMSE)
4、归一化均方根误差(NRMSE)

问题2:异常检测模型有哪些
统计检验方法:3-sigma
基于深度(树)的方法:孤立森林算法(Isolation Forest)
基于距离的方法:kNN、KMeans
基于密度的方法:DBSCAN、Local Outlier Factor
深度学习方法:Autoencoder
3、常用的异常检测算法pca 和 knn 的原理
PCA 异常检测的原理:PCA在做特征值分解后得到的特征向量反应了原始数据方差变化程度的不同方向,特征值为数据在对应方向上的方差大小。
最大特征值对应的特征向量为数据方差最大的方向,最小特征值对应的特征向量为数据方差最小的方向。原始数据在不同方向上的方差变化反应了其内在特点。
如果单个数据样本跟整体数据样本表现的特点不一致,如在某些方向上跟其它数据样本偏离较大,可能就表示该数据样本是一个异常点。
knn的核心思想是异常点一定是跟大部分的样本点都隔得很远。基于这个思想,依次计算每个样本点与它最近的K个样本的平均距离,再利用计算的距离与阈值进行比较,如果大于阈值,则认为是异常点。
问题4:第一次只出现一次的字符(剑指offer 50)
对字符串进行两次遍历。在第一次遍历时,使用哈希映射统计出字符串中每个字符出现的次数。在第二次遍历时,只要遍历到了一个只出现一次的字符,那么就返回该字符,否则在遍历结束后返回空格。
class Solution:def firstUniqChar(self, s: str) -> str:frequency = collections.Counter(s)for i, ch in enumerate(s):if frequency[ch] == 1:return chreturn \' \'
问题5:二叉树的最小深度(Leetcode 111)
##递归法class Solution:def minDepth(self, root: TreeNode) -> int:if not root:return 0if not root.left and not root.right:return 1min_depth = 10**9if root.left:min_depth = min(self.minDepth(root.left), min_depth) # 获得左子树的最小高度if root.right:min_depth = min(self.minDepth(root.right), min_depth) # 获得右子树的最小高度return min_depth + 1
问题6:基于统计学的异常检测模型以及优缺点
基于统计学的异常检测模型基于的基本假设是,正常的数据是遵循特定分布形式的,并且占了很大比例,而异常点的位置和正常点相比存在比较大的偏移。比如高斯分布,在平均值加减3倍标准差以外的部分仅占了0.2%左右的比例,一般我们把这部分数据就标记为异常数据。
优点就是速度一般比较快。使用这种方法存在的问题是,均值和方差本身都对异常值很敏感,因此如果数据本身不具备正态性,就不适合使用这种检测方法。

— 推荐阅读 — 最新大厂面试题
学员最新面经分享
七月内推岗位
AI开源项目论文
NLP ( 自然语言处理 )
CV(计算机视觉)
推荐