
有了这个,网页反爬限制请求频率易如反掌!
↑ 关注 + 星标 ,每天学Python新技能
后台回复【大礼包】送你Python自学大礼包
在以前的文章里面,我给大家介绍了使用 Python 自带的 LRU 缓存实现带有过期时间的缓存:实现有过期时间的 LRU 缓存。也讲过倒排索引:使用倒排索引极速提高字符串搜索效率。但这些代码对初学者来说比较难,写起来可能会出错。
实际上,这些功能其实都可以使用 Redis 来实现,而且每个功能只需要 1 分钟就能做出来。全文搜索功能在搜索英文的时候,甚至可以智能识别拼写错误的问题。
要实现这些功能,只需要做两件事:
安装 Redis Python 安装第三方库: walrus
安装完成以后,我们来看看它有多简单:
带过期时间的缓存装饰器
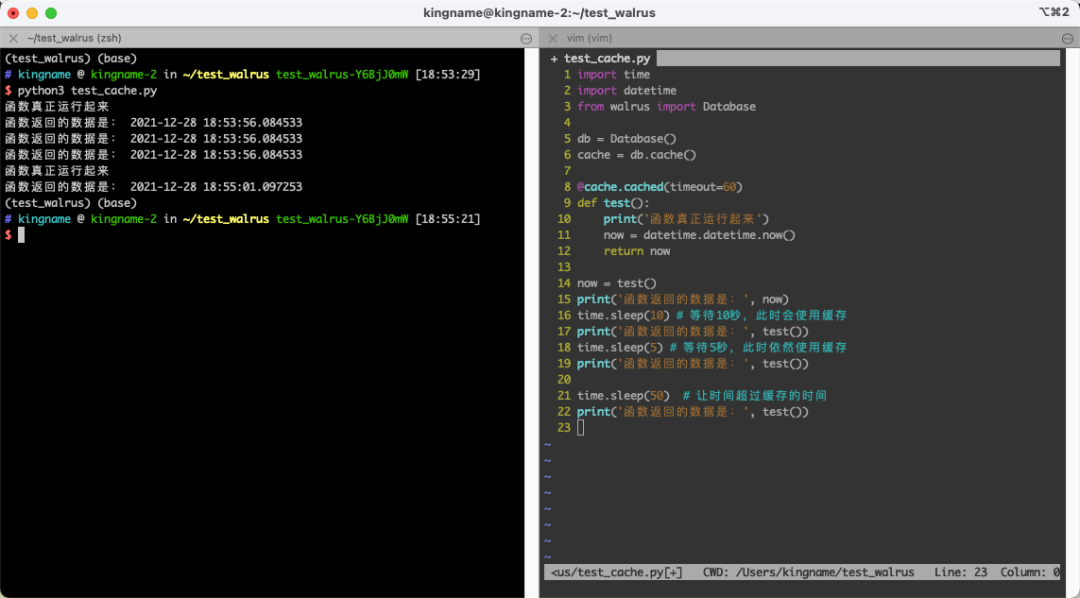
我们想实现一个装饰器,它装饰一个函数。让我在 1 分钟内多次访问函数的时候,使用缓存的数据;超过 1 分钟以后才重新执行函数的内部代码:
import time
import datetime
from walrus import Database
db = Database()
cache = db.cache()
@cache.cached(timeout=60)
def test():
print('函数真正运行起来')
now = datetime.datetime.now()
return now
now = test()
print('函数返回的数据是:', now)
time.sleep(10) # 等待10秒,此时会使用缓存
print('函数返回的数据是:', test())
time.sleep(5) # 等待5秒,此时依然使用缓存
print('函数返回的数据是:', test())
time.sleep(50) # 让时间超过缓存的时间
print('函数返回的数据是:', test())
运行效果如下图所示:
全文搜索
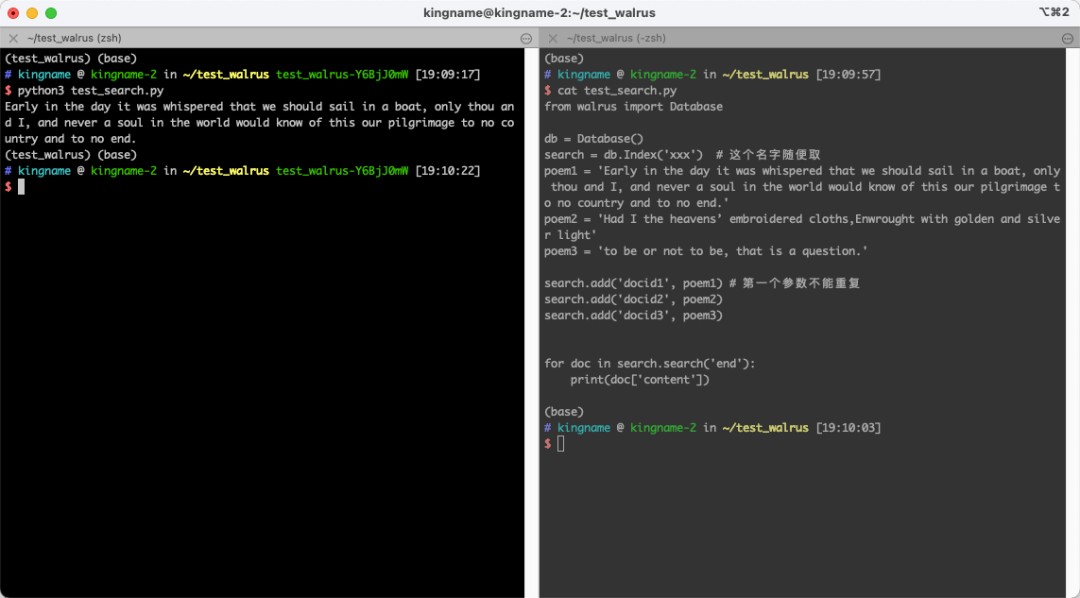
我们再来看看全文搜索功能,实现起来也很简单:
from walrus import Database
db = Database()
search = db.Index('xxx') # 这个名字随便取
poem1 = 'Early in the day it was whispered that we should sail in a boat, only thou and I, and never a soul in the world would know of this our pilgrimage to no country and to no end.'
poem2 = 'Had I the heavens’ embroidered cloths,Enwrought with golden and silver light'
poem3 = 'to be or not to be, that is a question.'
search.add('docid1', poem1) # 第一个参数不能重复
search.add('docid2', poem2)
search.add('docid3', poem3)
for doc in search.search('end'):
print(doc['content'])
运行效果如下图所示:
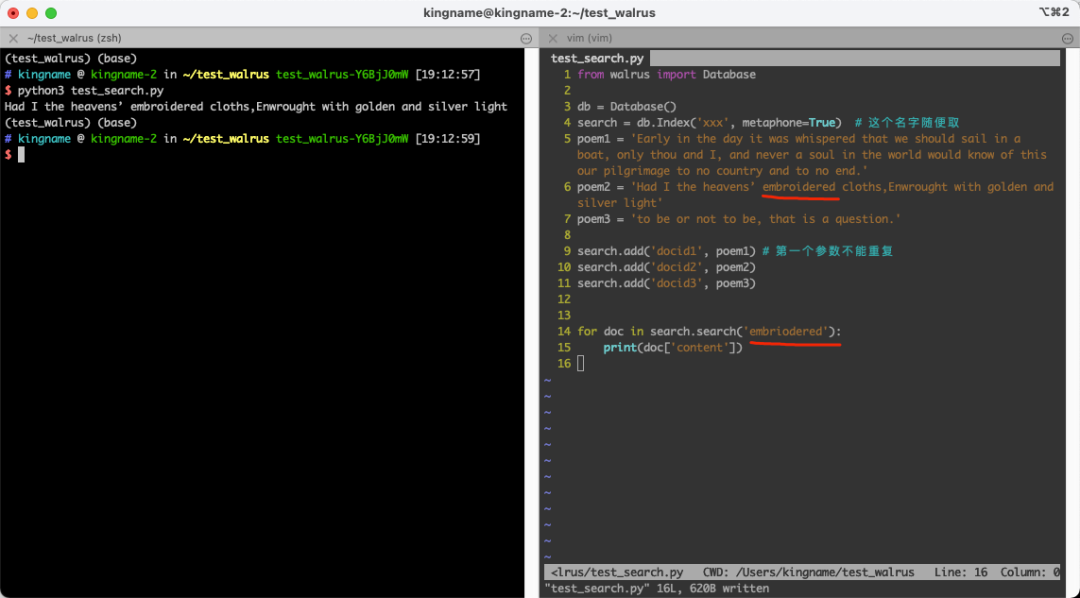
如果你想让他兼容拼写错误,那么可以把search = db.Index('xxx')改成search = db.Index('xxx’, metaphone=True),运行效果如下图所示:
不过遗憾的是,这个全文搜索功能只支持英文。
频率限制
我们有时候要限制调用某个函数的频率,或者网站的某个接口要限制 IP 的访问频率。这个时候,使用walrus也可以轻松实现:
import time
from walrus import Database
db = Database()
rate = db.rate_limit('xxx', limit=5, per=60) # 每分钟只能调用5次
for _ in range(35):
if rate.limit('xxx'):
print('访问频率太高!')
else:
print('还没有触发访问频率限制')
time.sleep(2)
运行效果如下图所示:
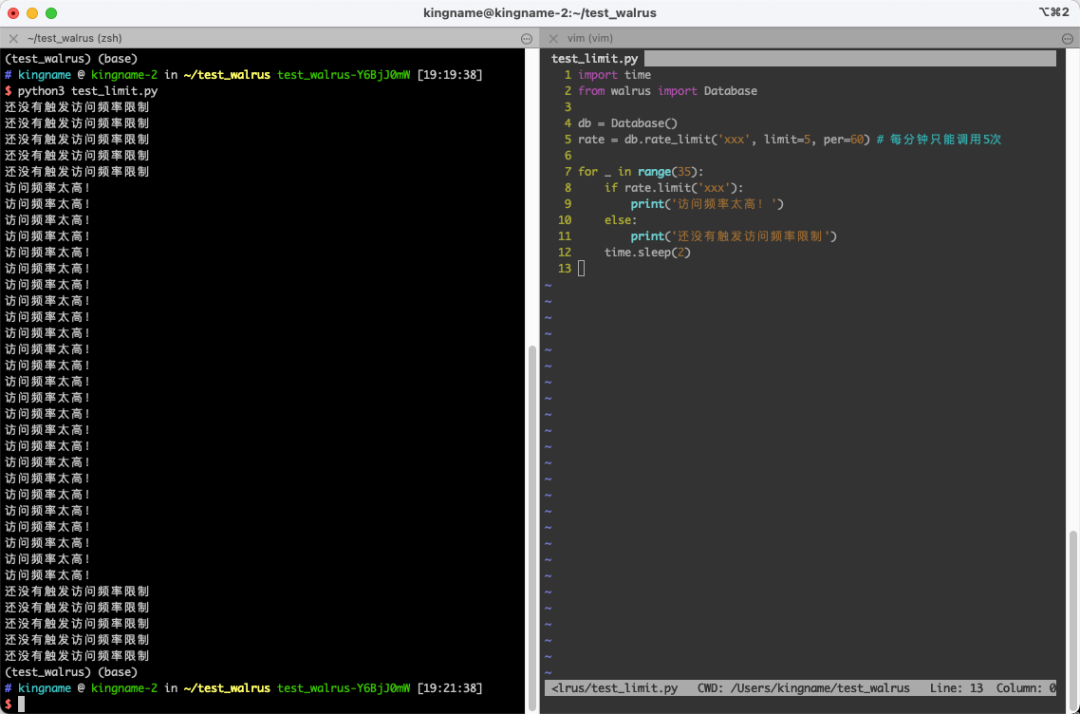
其中参数limit表示能出现多少次,per表示在多长时间内。
rate.limit只要传入相同的参数,那么就会开始检查这个参数在设定的时间内出现的频率。
你可能觉得这个例子并不能说明什么问题,那么我们跟 FastAPI 结合一下,用来限制 IP 访问接口的频率。编写如下代码:
from walrus import Database, RateLimitException
from fastapi import FastAPI, Request
from fastapi.responses import JSONResponse
db = Database()
rate = db.rate_limit('xxx', limit=5, per=60) # 每分钟只能调用5次
app = FastAPI()
@app.exception_handler(RateLimitException)
def parse_rate_litmit_exception(request: Request, exc: RateLimitException):
msg = {'success': False, 'msg': f'请喝杯茶,休息一下,你的ip: {request.client.host}访问太快了!'}
return JSONResponse(status_code=429, content=msg)
@app.get('/')
def index():
return {'success': True}
@app.get('/important_api')
@rate.rate_limited(lambda request: request.client.host)
def query_important_data(request: Request):
data = '重要数据'
return {'success': True, 'data': data}
上面代码定义了一个全局的异常拦截器:
@app.exception_handler(RateLimitException)
def parse_rate_litmit_exception(request: Request, exc: RateLimitException):
msg = {'success': False, 'msg': f'请喝杯茶,休息一下,你的ip: {request.client.host}访问太快了!'}
return JSONResponse(status_code=429, content=msg)
在整个代码的任何地方抛出了RateLimitException异常,就会进入这里的逻辑中。
使用装饰器@rate.rate_limited装饰一个路由函数,并且这个装饰器要更靠近函数。路由函数接收什么参数,它就接收什么参数。在上面的例子中,我们只接收了request参数,用于获取访问者的 IP。发现这个 IP 的访问频率超过了限制,就抛出一个RateLimitException。于是前面定义好的全局拦截器就会拦截RateLimitException异常,拦截到以后返回我们定义好的报错信息。
在频率范围内访问页面,返回正常的 JSON 数据:
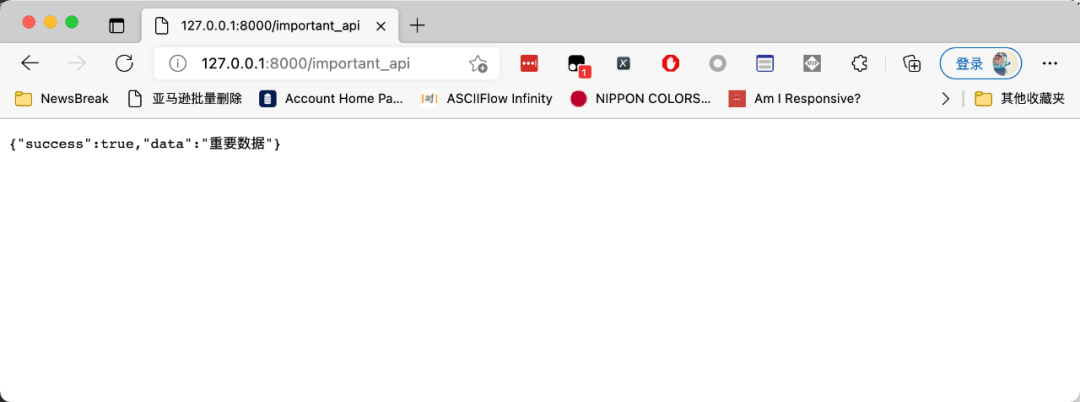
频率超过设定的值以后,访问页面就会报错,如下图所示:

总结
walrus对redis-py进行了很好的二次封装,用起来非常顺手。除了上面我提到的三个功能外,它还可以实现几行代码生成布隆过滤器,实现自动补全功能,实现简易图数据库等等。大家可以访问它的官方文档了解详细使用说明[1]。
参考文献
推荐阅读
您看此文用 
分

秒,转发只需1秒哦~