
蚂蚁金服一面:十道经典面试题解析
Hollis
共 11144字,需浏览 23分钟
·
2021-09-02 17:27

1. 用到分布式事务嘛?为什么用这种方案,有其他方案嘛?
什么是分布式事务
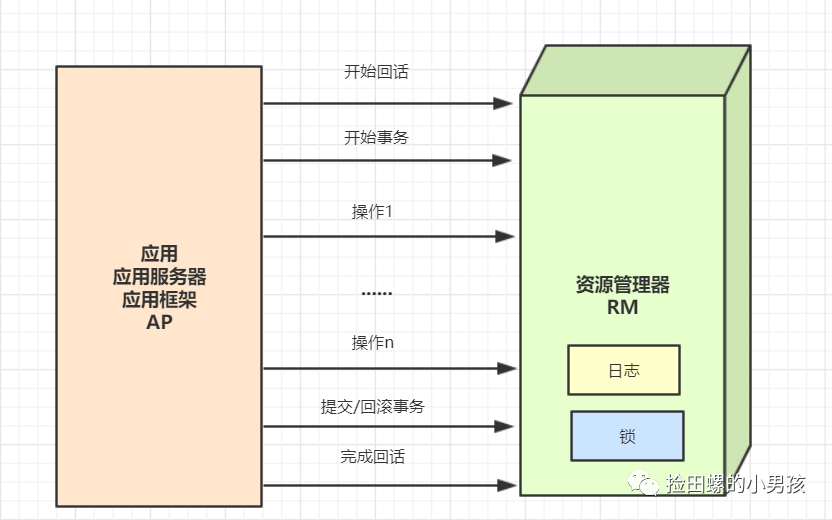
分布式事务基础
CAP理论
一致性(C:Consistency):一致性是指数据在多个副本之间能否保持一致的特性。例如一个数据在某个分区节点更新之后,在其他分区节点读出来的数据也是更新之后的数据。 可用性(A:Availability):可用性是指系统提供的服务必须一直处于可用的状态,对于用户的每一个操作请求总是能够在有限的时间内返回结果。这里的重点是"有限时间内"和"返回结果"。 分区容错性(P:Partition tolerance):分布式系统在遇到任何网络分区故障的时候,仍然需要能够保证对外提供满足一致性和可用性的服务。
BASE 理论
基本可用是指,通过支持局部故障而不是系统全局故障来实现的; Soft State表示状态可以有一段时间不同步; 最终一致,最终数据是一致的就可以了,而不是实时保持强一致。
分布式事务的几种解决方案
2PC(二阶段提交)方案,事务的提交分为两个阶段:准备阶段和提交执行方案。 TCC(即Try、Confirm、Cancel),它采用了补偿机制,核心思想是:针对每个操作,都要注册一个与其对应的确认和补偿(撤销)操作。 本地消息表,它的核心思想就是将分布式事务拆分成本地事务进行处理。 最大努力通知,实现最大努力通知,可以采用MQ的ack机制。 Saga事务,它的核心思想是将长事务拆分为多个本地短事务,由Saga事务协调器协调,如果正常结束那就正常完成,如果某个步骤失败,则根据相反顺序一次调用补偿操作。
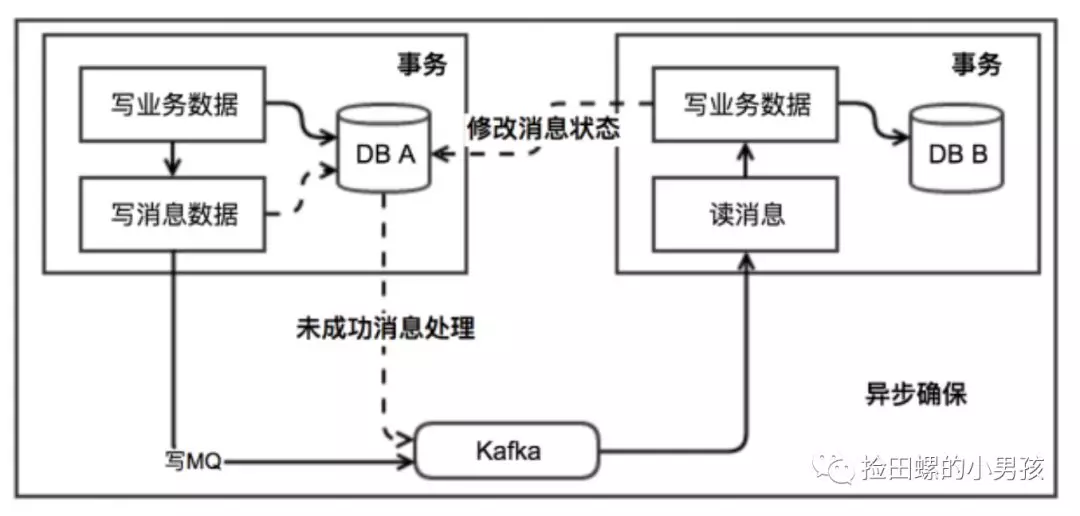
首先需要有一个消息表,记录着消息状态相关信息。 业务数据和消息表在同一个数据库,即要保证它俩在同一个本地事务。 在本地事务中处理完业务数据和写消息表操作后,通过写消息到MQ消息队列。 消息会发到消息消费方,如果发送失败,即进行重试。
处理消息队列中的消息,完成自己的业务逻辑。 此时如果本地事务处理成功,则表明已经处理成功了。 如果本地事务处理失败,那么就会重试执行。 如果是业务上面的失败,给消息生产方发送一个业务补偿消息,通知进行回滚等操作。
2.JDK6、7、8分别提供了哪些新特性

Desktop类(它允许一个Java应用程序启动本地的另一个应用程序去处理URI或文件请求) 使用JAXB2来实现对象与XML之间的映射 轻量级 Http Server API 插入式注解处理API(lombok框架基于这个特性实现) STAX(是JDK6中一种处理XML文档的API)
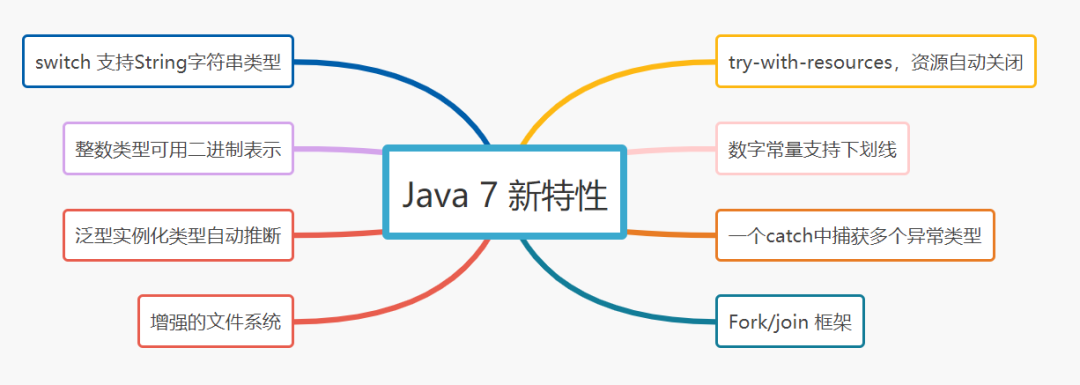
switch 支持String字符串类型 try-with-resources,资源自动关闭 整数类型如(byte,short,int,long)能够用二进制来表示 数字常量支持下划线 泛型实例化类型自动推断,即”<>” 一个catch中捕获多个异常类型,用(|)分隔开 增强的文件系统 Fork/join 框架
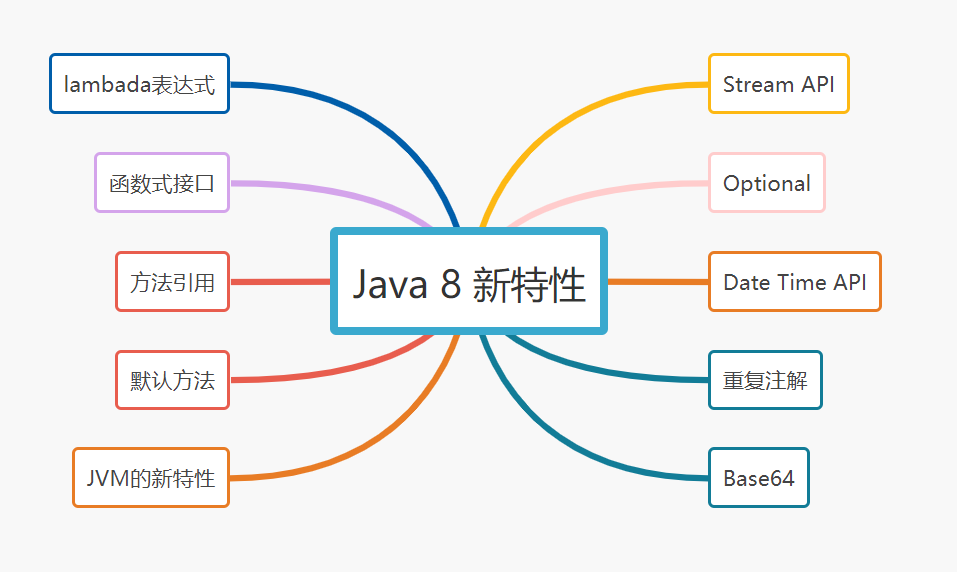
lambada表达式 函数式接口 方法引用 默认方法 Stream API Optional Date Time API(如LocalDate) 重复注解 Base64 JVM的新特性(如元空间Metaspace代替持久代)
3. https原理,工作流程
HTTPS = HTTP + SSL/TLS,即用SSL/TLS对数据进行加密和解密,Http进行传输。 SSL,即Secure Sockets Layer(安全套接层协议),是网络通信提供安全及数据完整性的一种安全协议。 TLS,即Transport Layer Security(安全传输层协议),它是SSL3.0的后续版本。

客户端发起Https请求,连接到服务器的443端口。 服务器必须要有一套数字证书(证书内容有公钥、证书颁发机构、失效日期等)。 服务器将自己的数字证书发送给客户端(公钥在证书里面,私钥由服务器持有)。 客户端收到数字证书之后,会验证证书的合法性。如果证书验证通过,就会生成一个随机的对称密钥,用证书的公钥加密。 客户端将公钥加密后的密钥发送到服务器。 服务器接收到客户端发来的密文密钥之后,用自己之前保留的私钥对其进行非对称解密,解密之后就得到客户端的密钥,然后用客户端密钥对返回数据进行对称加密,酱紫传输的数据都是密文啦。 服务器将加密后的密文返回到客户端。 客户端收到后,用自己的密钥对其进行对称解密,得到服务器返回的数据。
4. 讲讲java jmm volatile的实现原理
Java虚拟机规范试图定义一种Java内存模型,来屏蔽掉各种硬件和操作系统的内存访问差异,以实现让Java程序在各种平台上都能达到一致的内存访问效果。 为了更好的执行性能,java内存模型并没有限制执行引擎使用处理器的特定寄存器或缓存来和主内存打交道,也没有限制编译器进行调整代码顺序优化。所以Java内存模型会存在缓存一致性问题和指令重排序问题的。 Java内存模型规定所有的变量都是存在主内存当中,每个线程都有自己的工作内存。这里的变量包括实例变量和静态变量,但是不包括局部变量,因为局部变量是线程私有的。 线程的工作内存保存了被该线程使用的变量的主内存副本,线程对变量的所有操作都必须在工作内存中进行,而不能直接操作操作主内存。并且每个线程不能访问其他线程的工作内存。 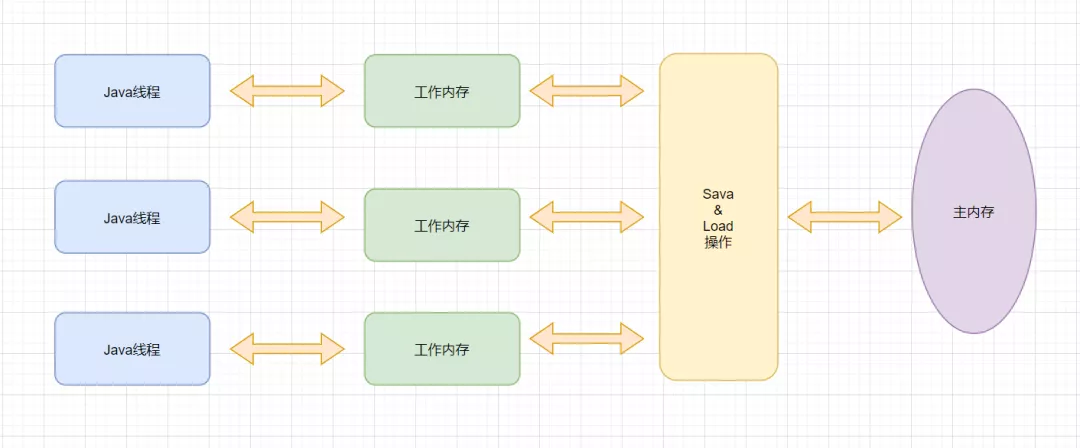
程序次序规则:在一个线程内,按照控制流顺序,书写在前面的操作先行发生于书写在后面的操作。 管程锁定规则:一个unLock操作先行发生于后面对同一个锁额lock操作 volatile变量规则:对一个变量的写操作先行发生于后面对这个变量的读操作 线程启动规则:Thread对象的start()方法先行发生于此线程的每个一个动作 线程终止规则:线程中所有的操作都先行发生于线程的终止检测,我们可以通过Thread.join()方法结束、Thread.isAlive()的返回值手段检测到线程已经终止执行 线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生 对象终结规则:一个对象的初始化完成先行发生于他的finalize()方法的开始 传递性:如果操作A先行发生于操作B,而操作B又先行发生于操作C,则可以得出操作A先行发生于操作C
public class Singleton {
private volatile static Singleton instance;
private Singleton (){}
public static Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
1.重排序时不能把后面的指令重排序到内存屏障之前的位置 2.将本处理器的缓存写入内存 3.如果是写入动作,会导致其他处理器中对应的缓存无效。

在每个volatile写操作的前面插入一个StoreStore屏障。 在每个volatile写操作的后面插入一个StoreLoad屏障。 在每个volatile读操作的后面插入一个LoadLoad屏障。 在每个volatile读操作的后面插入一个LoadStore屏障。

5. 讲一讲7层网络模型,tcp的为什么要三次握手
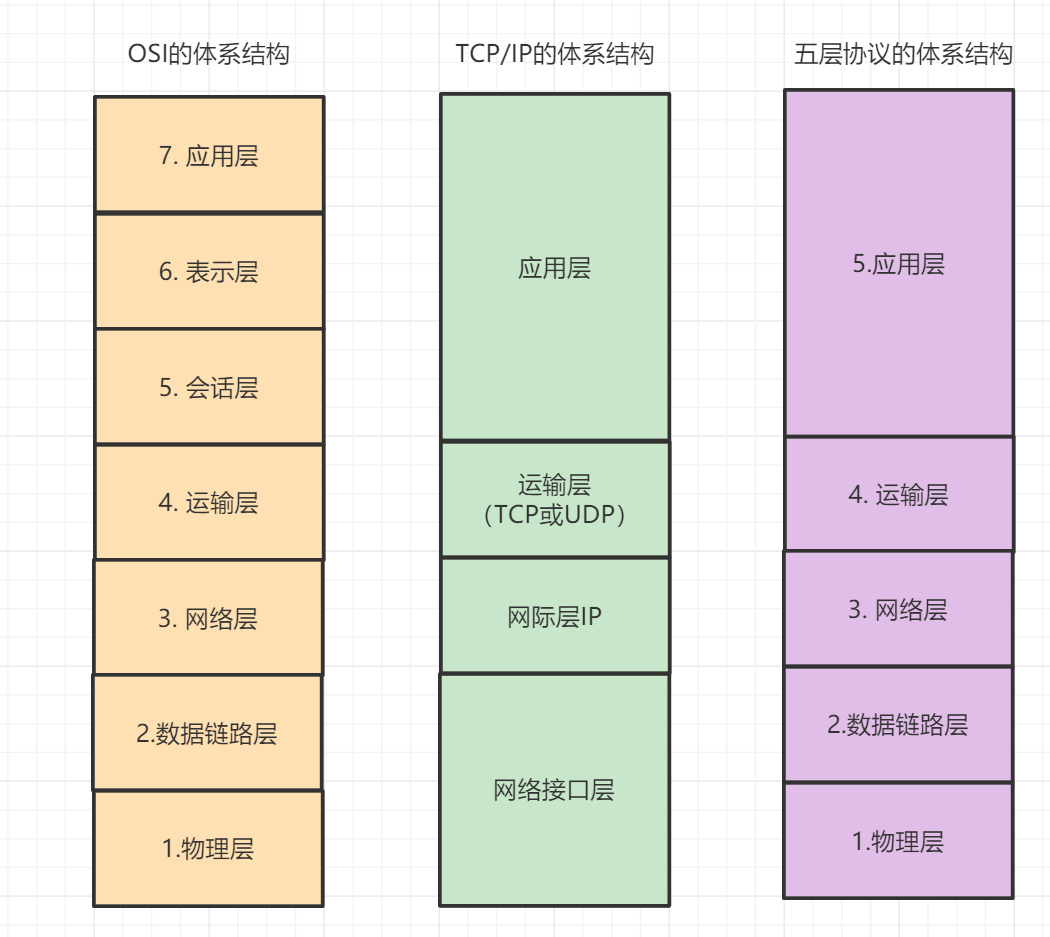
应用层:网络服务与最终用户的一个接口,常见的协议有:HTTP FTP SMTP SNMP DNS. 表示层:数据的表示、安全、压缩。,确保一个系统的应用层所发送的信息可以被另一个系统的应用层读取。 会话层:建立、管理、终止会话,对应主机进程,指本地主机与远程主机正在进行的会话. 传输层:定义传输数据的协议端口号,以及流控和差错校验,协议有TCP UDP. 网络层:进行逻辑地址寻址,实现不同网络之间的路径选择,协议有ICMP IGMP IP等. 数据链路层:在物理层提供比特流服务的基础上,建立相邻结点之间的数据链路。 物理层:建立、维护、断开物理连接。
6.说说线程池的工作原理
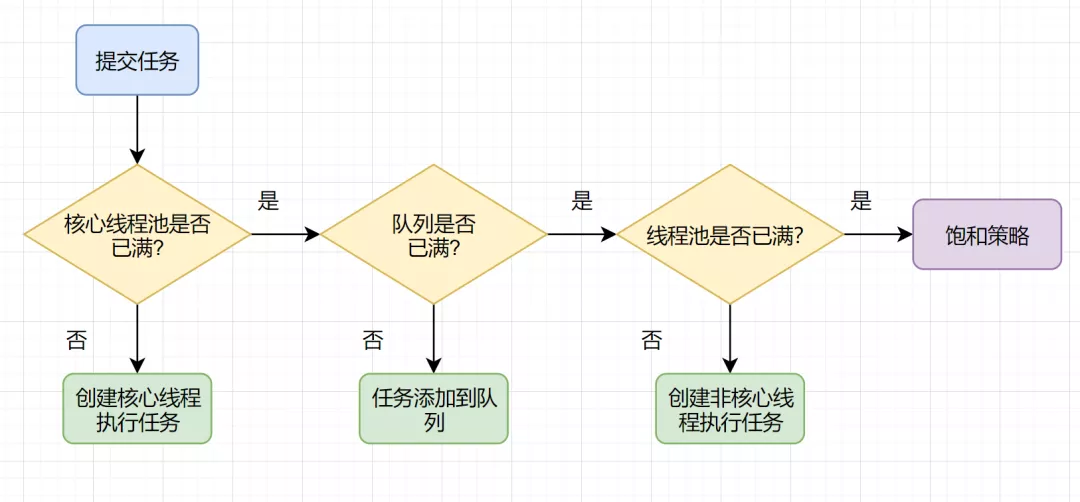
核心线程比作公司正式员工 非核心线程比作外包员工 阻塞队列比作需求池 提交任务比作提需求
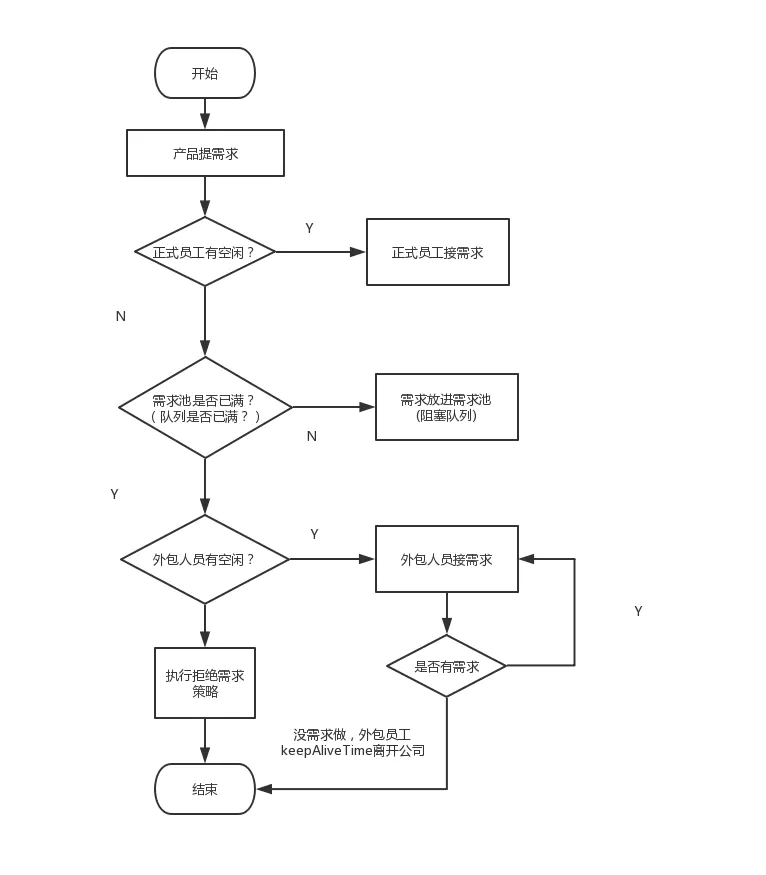
当产品提个需求,正式员工(核心线程)先接需求(执行任务) 如果正式员工都有需求在做,即核心线程数已满),产品就把需求先放需求池(阻塞队列)。 如果需求池(阻塞队列)也满了,但是这时候产品继续提需求,怎么办呢?那就请外包(非核心线程)来做。 如果所有员工(最大线程数也满了)都有需求在做了,那就执行拒绝策略。 如果外包员工把需求做完了,它经过一段(keepAliveTime)空闲时间,就离开公司了。
7.你们数据库的高可用是怎么实现的?
如果数据库节点宕机,需要尽快回复,保证业务不受宕机影响。 从数据库节点的数据,尽可能跟主节点数据实时保持一致,至少保证最终一致性。 数据库节点切换时,数据不能缺失。
7.1 主从或主主半同步复制
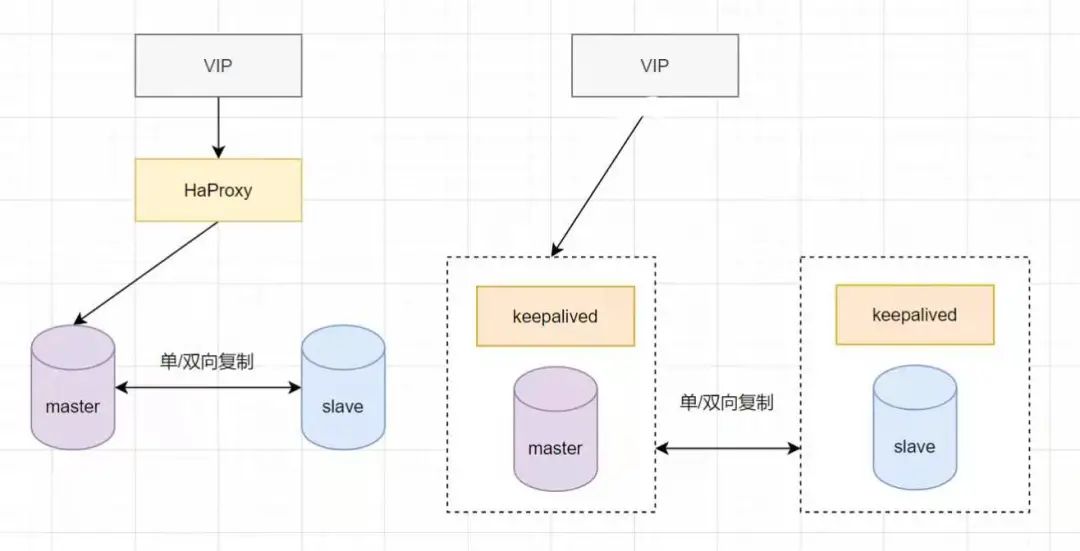
7.2 半同步复制优化
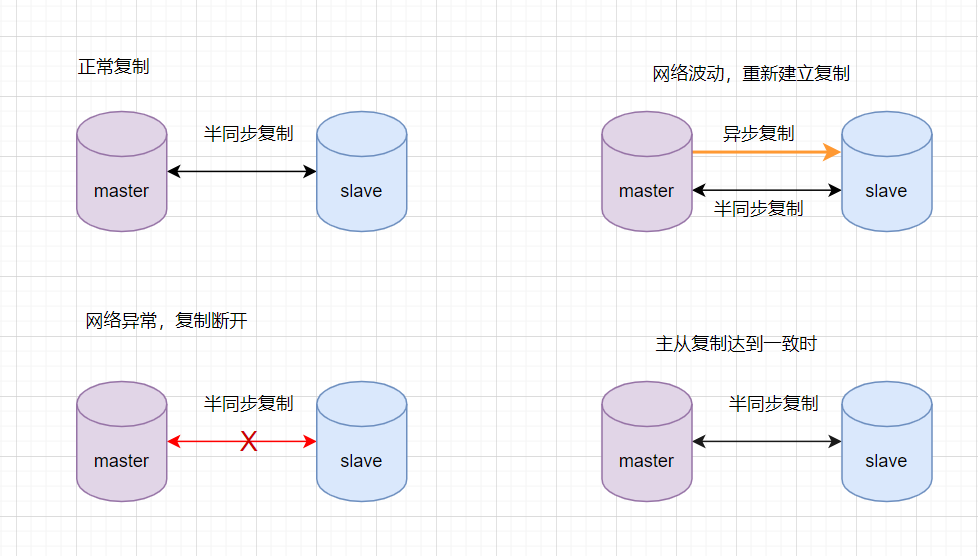
优点:这种方案架构、部署也比较简单,主机宕机也是直接切换即可。比方案1的半同步复制,更能保证数据的一致性。 缺点:需要修改内核源码或者使用mysql通信协议,没有从根本上解决数据一致性问题。
7.3 高可用架构优化
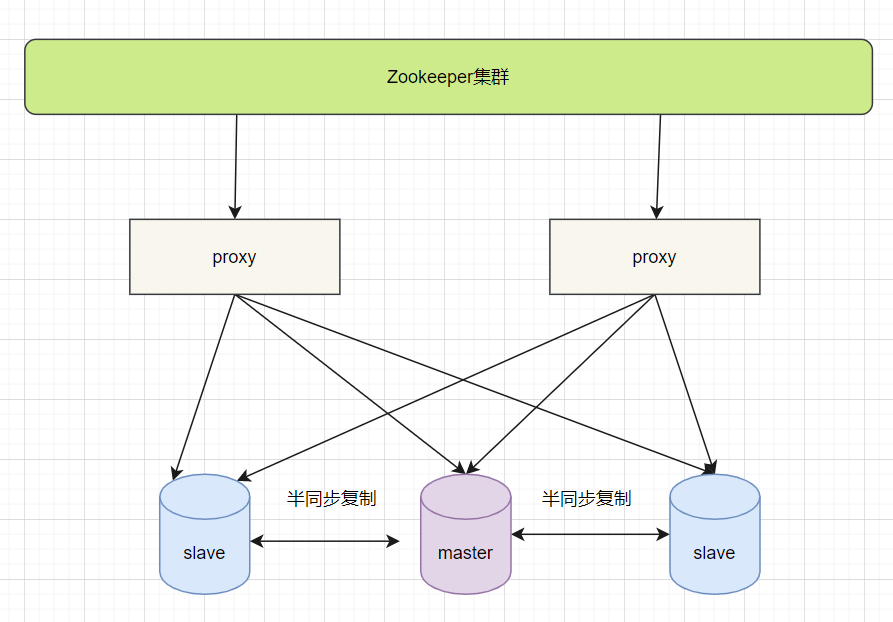
优点:保证了整个系统的高可用性,扩展性也较好,可以扩展为大规模集群。 缺点:数据一致性仍然依赖于原生的mysql半同步复制;引入Zookeeper使系统逻辑更复杂。
7.4 共享存储
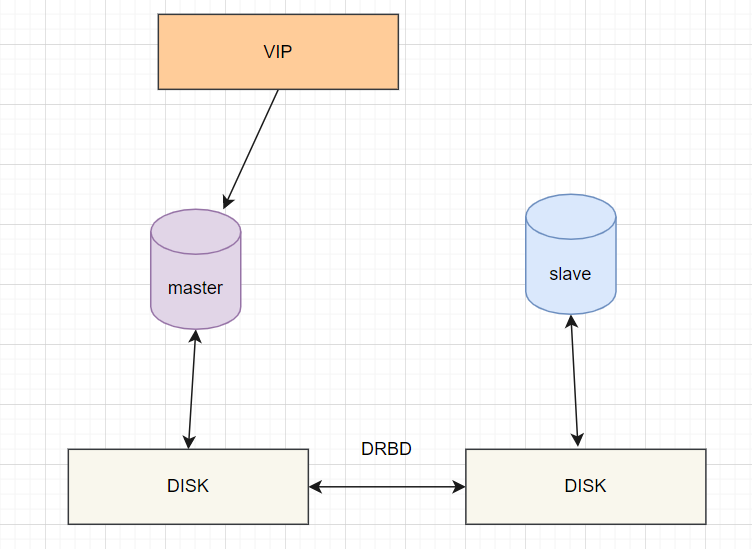
优点:部署简单,价格合适,保证数据的强一致性 缺点:对IO性能影响较大,从库不提供读操作
7.5 分布式协议
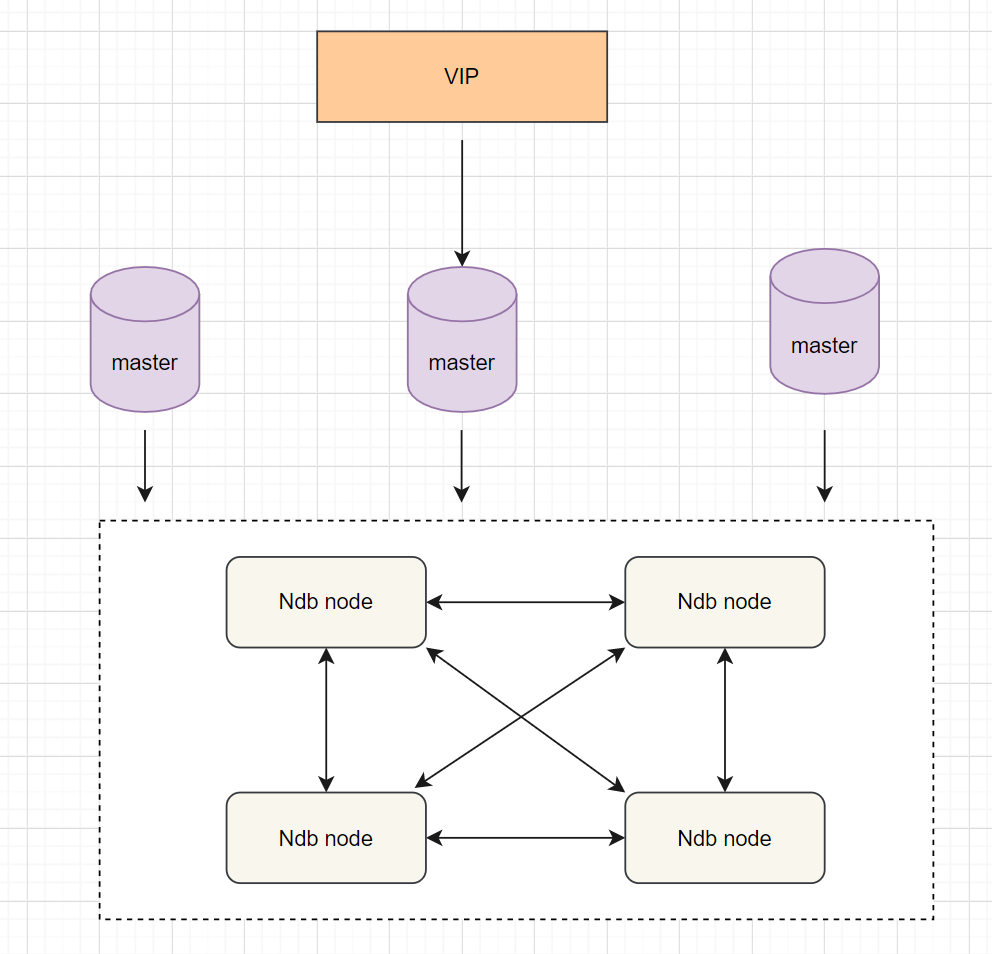
优点:不依赖于第三方软件,可以实现数据的强一致性; 缺点:配置较复杂;需要使用NDB储存引擎;至少三节点;
8. 读写分离的场景下,怎么保证从数据库读到最新的数据?
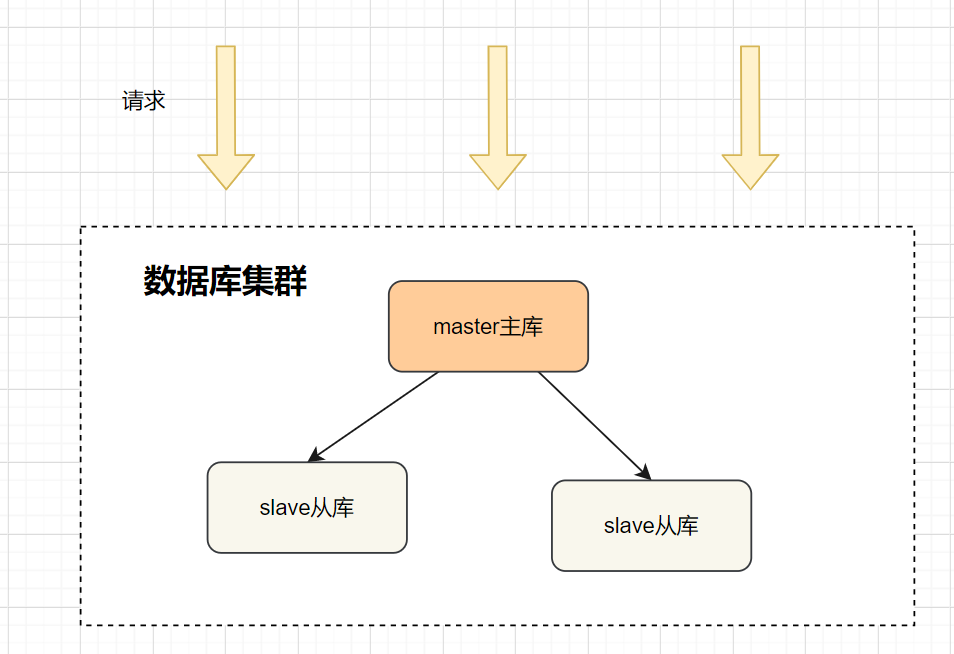
写请求是直接写主库,然后同步数据到从库 读请求一般直接读从库,除飞强制读主库
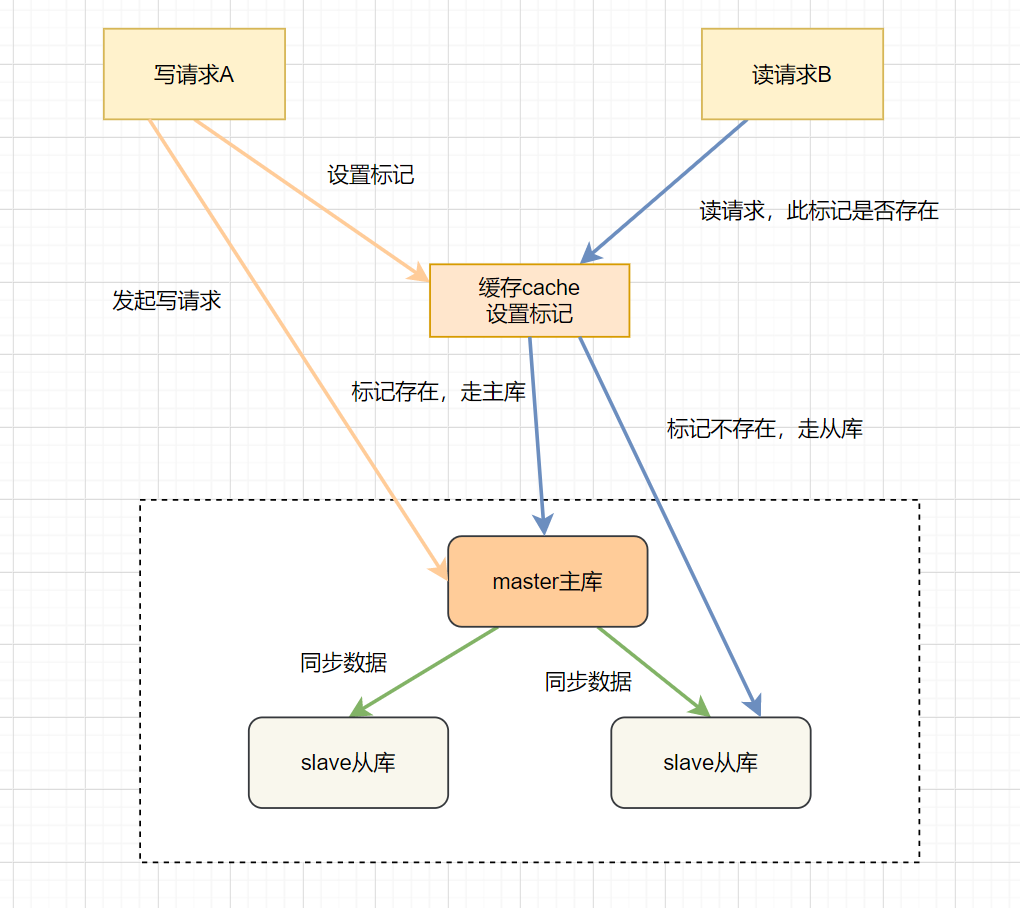
A发起写请求,更新主库数据,并在缓存中设置一个标记,表示数据已更新,标记格式为:userId+业务Id。 设置此标记,设置过期时间(估值为主库和从库同步延迟的时间) B发起读请求,先判断此请求,在缓存中有没有更新标记。 如果存在标记,走主库;如果没有,请求走从库。
9. 如何保证MySQL数据不丢?
binlog日志
statement:每一条会修改数据的sql都会记录到binlog中,不建议使用。 row:基于行的变更情况记录,会记录行更改前后的内容,推荐使用。 mixed:混合statement和row两个模式,不建议使用。

write:指把日志写到文件系统的page cache,并没有把数据持久化到磁盘,因此速度较快。 fsync,实际的写盘操作,即把数据持久化到磁盘。

redo log日志
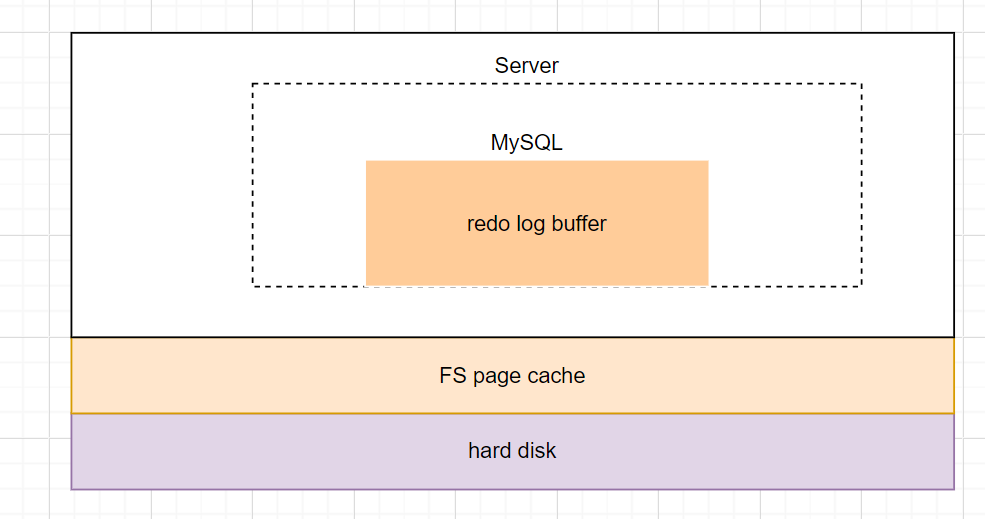
物理上是在MySQL进程内存中,存在redo log buffer中, 物理上在文件系统的page cache里,写到磁盘 (write),但是还没有持久化(fsync)。 存在hard disk,已经持久化到磁盘。
设置为0时,表示每次事务提交时都只是把redo log留在redo log buffer 中 ; 设置为1时,表示每次事务提交时都将 redo log 直接持久化到磁盘; 设置为2时,表示每次事务提交时都只是把redo log 写到page cache。
10. 高并发下如何设计秒杀系统?

页面静态化 按钮至灰控制 服务单一职责 秒杀链接加盐 限流 分布式锁 MQ异步处理 限流&降级&熔断
为了防止某个用户请求过于频繁,我们可以对同一用户限流; 为了防止黄牛模拟几个用户请求,我们可以对某个IP进行限流; 为了防止有人使用代理,每次请求都更换IP请求,我们可以对接口进行限流。 为了防止瞬时过大的流量压垮系统,还可以使用阿里的Sentinel、Hystrix组件进行限流。
if(jedis.set(key_resource_id, uni_request_id, "NX", "EX", 100s) == 1){ //加锁
try {
do something //业务处理
}catch(){
}
finally {
//判断是不是当前线程加的锁,是才释放
if (uni_request_id.equals(jedis.get(key_resource_id))) {
jedis.del(lockKey); //释放锁
}
}
}

if redis.call('get',KEYS[1]) == ARGV[1] then
return redis.call('del',KEYS[1])
else
return 0
end;
限流,就是限制请求,防止过大的请求压垮服务器; 降级,就是秒杀服务有问题了,就降级处理,不要影响别的服务; 熔断,服务有问题就熔断,一般熔断降级是一起出现。
参考资料
五大常见的MySQL高可用方案: https://zhuanlan.zhihu.com/p/25960208
[2]读写分离数据库如何保持数据一致性: https://blog.csdn.net/baidu_36161424/article/details/107712388
[3]《我们一起进大厂》系列-秒杀系统设计: https://juejin.cn/post/6844903999083151374#heading-11
[4]《极客时间:MySQL45讲实战》: http://gk.link/a/10vPr
[5]MySQL是如何保证不丢数据的(一): https://cloud.tencent.com/developer/article/1674625
有道无术,术可成;有术无道,止于术
欢迎大家关注Java之道公众号
好文章,我在看❤️
评论