
为什么不建议使用 Java 自带的序列化?

阅读本文大概需要 2.8 分钟。
作者:rickiyang
出处:www.cnblogs.com/rickiyang/p/11074232.html
@Test
public void testSerializable(){
String str = "哈哈,我是一条消息";
Message msg = new Message((byte)0xAD,35,str);
ByteArrayOutputStream out = new ByteArrayOutputStream();
try {
ObjectOutputStream os = new ObjectOutputStream(out);
os.writeObject(msg);
os.flush();
byte[] b = out.toByteArray();
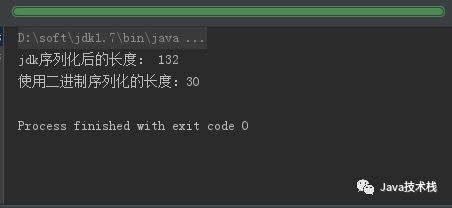
System.out.println("jdk序列化后的长度: "+b.length);
os.close();
out.close();
ByteBuffer buffer = ByteBuffer.allocate(1024);
byte[] bt = msg.getMsgBody().getBytes();
buffer.put(msg.getType());
buffer.putInt(msg.getLength());
buffer.put(bt);
buffer.flip();
byte[] result = new byte[buffer.remaining()];
buffer.get(result);
System.out.println("使用二进制序列化的长度:"+result.length);
} catch (IOException e) {
e.printStackTrace();
}
}
@Test
public void testSerializable(){
String str = "哈哈,我是一条消息";
Message msg = new Message((byte)0xAD,35,str);
ByteArrayOutputStream out = new ByteArrayOutputStream();
try {
long startTime = System.currentTimeMillis();
for(int i = 0;i < 100000;i++){
ObjectOutputStream os = new ObjectOutputStream(out);
os.writeObject(msg);
os.flush();
byte[] b = out.toByteArray();
/*System.out.println("jdk序列化后的长度: "+b.length);*/
os.close();
out.close();
}
long endTime = System.currentTimeMillis();
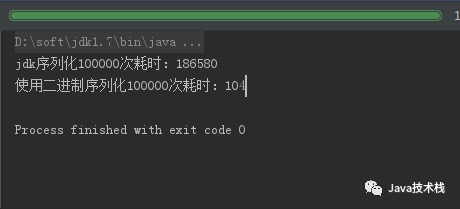
System.out.println("jdk序列化100000次耗时:" +(endTime - startTime));
long startTime1 = System.currentTimeMillis();
for(int i = 0;i < 100000;i++){
ByteBuffer buffer = ByteBuffer.allocate(1024);
byte[] bt = msg.getMsgBody().getBytes();
buffer.put(msg.getType());
buffer.putInt(msg.getLength());
buffer.put(bt);
buffer.flip();
byte[] result = new byte[buffer.remaining()];
buffer.get(result);
/*System.out.println("使用二进制序列化的长度:"+result.length);*/
}
long endTime1 = System.currentTimeMillis();
System.out.println("使用二进制序列化100000次耗时:" +(endTime1 - startTime1));
} catch (IOException e) {
e.printStackTrace();
}
}
推荐阅读:
最近面试BAT,整理一份面试资料《Java面试BATJ通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。
朕已阅 
评论