后端开发仔,必备小技巧!
共 3875字,需浏览 8分钟
·
2021-12-12 12:51

作为一名后端开发仔,和 Linux 系统打交道,经常要用到一些命令是不可避免的了。
Linux 系统的提供了很多小而美的工具,集成了管道符、重定向、强大的命令等等,处理工作起来可以说是非常的优雅,可以将很多复杂的工作自动化。
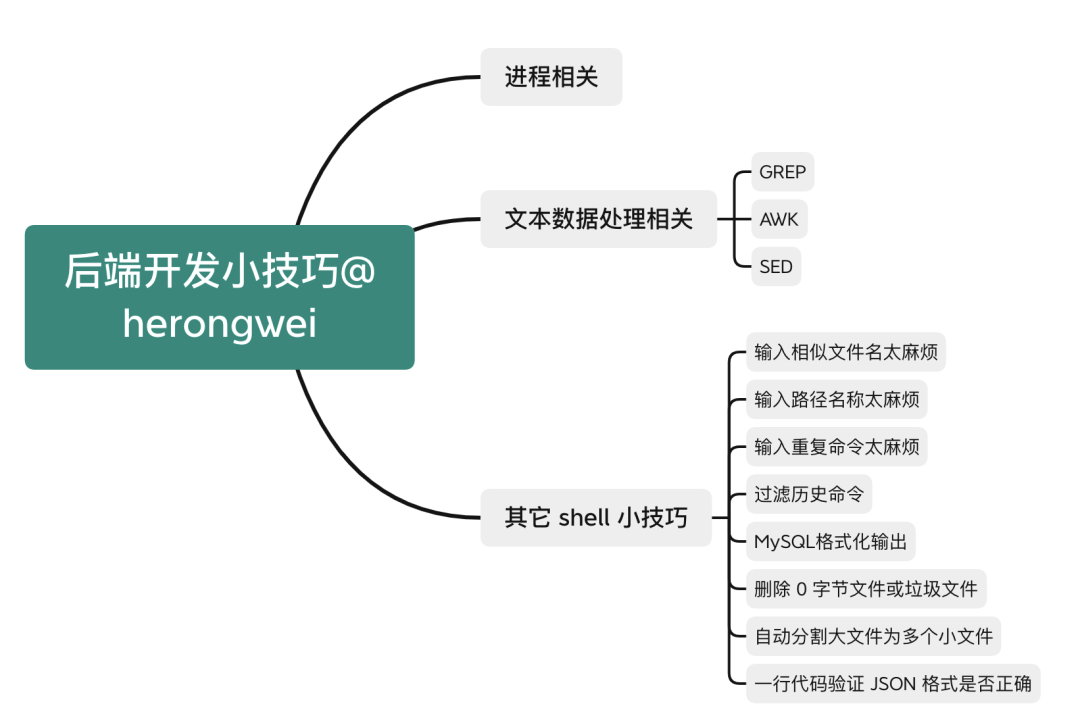
本文就介绍一些基本的 Linux shell 技巧,有了这些,开发效率杠杠滴!
开启守护进程
一般后端服务,都是开启守护进程,其命令类似如下
ps aux | grep start.sh | grep -v "grep --color=auto start.sh" | awk '{print $2}' | xargs kill -9 || echo ok > log
nohup start.sh &> log &
而执行 sh start.sh & 只是开启了后台进程。
后台进程和守护进程的区别?
最大的区别有几点:
守护进程已经完全脱离终端控制台了,而后台程序并未完全脱离终端; 守护进程在关闭终端控制台时不会受影响,而后台程序会随用户退出而停止,需要在以nohup command & 格式运行才能避免影响; 守护进程的会话组和当前目录,文件描述符都是独立的。后台运行只是终端进行了一次 fork,让程序在后台执行。
解释一下,下面的命令是用 awk 提取进程 ID
ps -aux|grep chat.js| grep -v grep | awk '{print $2}'
查看到进程 id 之后,使用 netstat 命令查看其占用的端口
netstat -nap|grep 7779
三大利器 GREP,SED,AWK
Linux 三大利器 grep,sed,awk,熟练掌握其中常见的用法,开发效率杠杠滴。
grep 匹配二进制文件
grep 如果碰到 \000 NUL 字符,就会认为文件是二进制文件,而 grep 匹配默认忽略二进制数据。
使用 grep -a 属性:不忽略二进制的数据。grep 的 -a 或 --text 参数功能:将 binary 文件以 text 文件的方式搜寻数据。
grep -a file_name
或
grep --text file_name
grep 匹配或排除多个关键字
grep -E "word1|word2|word3" file.txt
#满足任意条件(word1、word2和word3之一)将匹配。
grep word1 file.txt | grep word2 |grep word3
#必须同时满足三个条件(word1、word2和word3)才匹配。grep -v 'abc\|efg' log.txt
#排除 log.txt 中的 abc efg 关键字
awk /sed 分割或去重
使用 tab 键分割文件
awk 'BEGIN{IFS='\t'}{print $1}' a.log
按分隔符去重以某列重复的行
cat ios_gupai_only_new.txt | awk -F '|' '!a[$1]++{print}' > ios_gupai_one.txt
sed 文件首尾添加引号
sed -i 's/^/"/;s/$/"/' log.txt
sed 文件尾添加逗号
Sed -i 's/$/,/' txt
其它 shell 小技巧
输入相似文件名太麻烦
用花括号括起来的字符串用逗号连接,可以自动扩展,非常有用,直接看例子:
$ echo {one,two,three}file
onefile twofile threefile
$ echo {one,two,three}{1,2,3}
one1 one2 one3 two1 two2 two3 three1 three2 three3
花括号中的每个字符都可以和之后(或之前)的字符串进行组合拼接,注意花括号和其中的逗号不可以用空格分隔,否则会被认为是普通的字符串对待。
这个技巧有什么实际用处呢?最简单实用的就是给 cp,mv,rm 等命令扩展参数:
$ cp /search/code/file{,.bak}
# 给 file 复制一个叫做 file.bak 的副本
$ rm file{1,3,5}.txt
# 删除 file1.txt file3.txt file5.txt
$ mv *.{c,cpp} src/
# 将所有 .c 和 .cpp 为后缀的文件移入 src 文件夹
输入路径名称太麻烦
用 cd - 返回刚才的目录,直接看例子吧:
$ pwd
/search/code/moyu
$ cd # 回到家目录瞅瞅
$ pwd
/home/herongwei
$ cd - # 再返回刚才那个目录
$ pwd
/search/code/moyu
特殊命令 !$ 会替换成上一次命令最后的路径,直接看例子:
没有加可执行权限
$ /usr/bin/script.sh
zsh: permission denied: /usr/bin/script.sh
$ chmod +x !$
chmod +x /usr/bin/script.sh
特殊命令 !* 会替换成上一次命令输入的所有文件路径,直接看例子:
创建了三个脚本文件
$ touch script1.sh script2.sh script3.sh
给它们全部加上可执行权限
$ chmod +x !*
chmod +x script1.sh script2.sh script3.sh
输入重复命令太麻烦
使用特殊命令!!,可以自动替换成上一次使用的命令:
[@root]# yum install python
E: Could not open lock file - open (13: Permission denied)
[@root]# !!
yum install python
有的命令很长,一时间想不起来具体参数了怎么办?
对于 bash 终端,可以使用 Ctrl+R 快捷键反向搜索历史命令,之所以说是反向搜索,就是搜索最近一次输入的命令。
比如按下 Ctrl+R 之后,输入 cp,bash 就会搜索出最近一次包含 cp 的命令,你回车之后就可以运行该命令了:
(reverse-i-search)`': cp config/app_search_rule.json{,.bak}
但是这个方法有缺点:该功能似乎只有 bash 支持,而 zsh 作为 shell 终端,就用不了;
第二,只能查找出一个(最近的)命令,如果我想找以前的某个命令,就没办法了。
对于这种情况,常用的方法是使用 history 命令配合管道符和 grep 命令来寻找某个历史命令比如:
过滤出所有包含 yum 字段的历史命令
[@root]# history | grep 'yum'
334 2021-08-30 14:36:27 yum install devtoolset-3-gcc.x86_64 devtoolset-3-gcc-c++.x86_64
336 2021-08-30 14:44:31 yum list | grep rdkafka
337 2021-08-30 14:44:57 yum list | grep kafka
435 2021-08-31 15:50:22 yum list | grep sasl2
778 2021-09-16 16:40:55 yum install -y libffi-devel
849 2021-09-16 16:56:49 yum install pip3
一行代码验证 JSON 格式是否正确
执行命令:
cat a.json | python -m json.tool | wc -l
原理
要验证的文件 a.json 如果返回结果一行数字,则表示 a.json 文件格式正确 否则返回 a.json 文件中错误的行号及错误信息
一旦 JSON 文件格式不对,或者文件内容缺失或者其他问题,就会导致 python -m 命令无法格式化,正是利用这一点,我们可以做一个 JSON 的验证。
比如说你在线修改了一个 JSON 数据,但是又不能粘贴出来查看是否修改正确了,直接执行这个命令比较方便,或者也可以用 VIM 命令的 % 命令来匹配中括号和大括号。
删除 0 字节文件或垃圾文件
find . -type f -size 0 -delete
find . -type f -exec rm -rf {} \;
find . -type f -name "a.out" -exec rm -rf {} \;
find . type f -name "a.out" -delete
find . type f -name "*.txt" -print0 | xargs -0 rm -f
自动分割大文件为多个小文件
使用 split 命令,比如:
命令:split -l 10000 -d -a 3 nameall.txt name 将 nameall.txt 文件按照 10000 行分割成前缀 name+数字三位的小文件。
MySQL 终端显示格式化
在 SQL 语句最后加上一个 \G , 比较推荐这个用法,把行转化成列显示。
sl 命令输出小火车