
61秒,摸透Linux的健康状态!
领取嵌入式学习路线,
请加良许微信:coderliangxu-6

操作系统作为所有程序的载体,对应用的性能影响是非常重要的。然而计算机各个组件之间的速度,是非常不均衡的。拿CPU和硬盘的速度来说,比兔子和乌龟的速度差别还要大。
下面将简单的介绍CPU、内存、I/O的一些基本知识,以及一些如何评估它们性能的命令。
1.CPU
首先介绍计算机中最重要的计算组件:中央处理器。一般我们可以通过top命令来观测它的性能。
1.1 top命令
top命令可用于观测CPU的一些运行指标。如图,进入top命令之后,按1键即可看到每核CPU的详细状况。
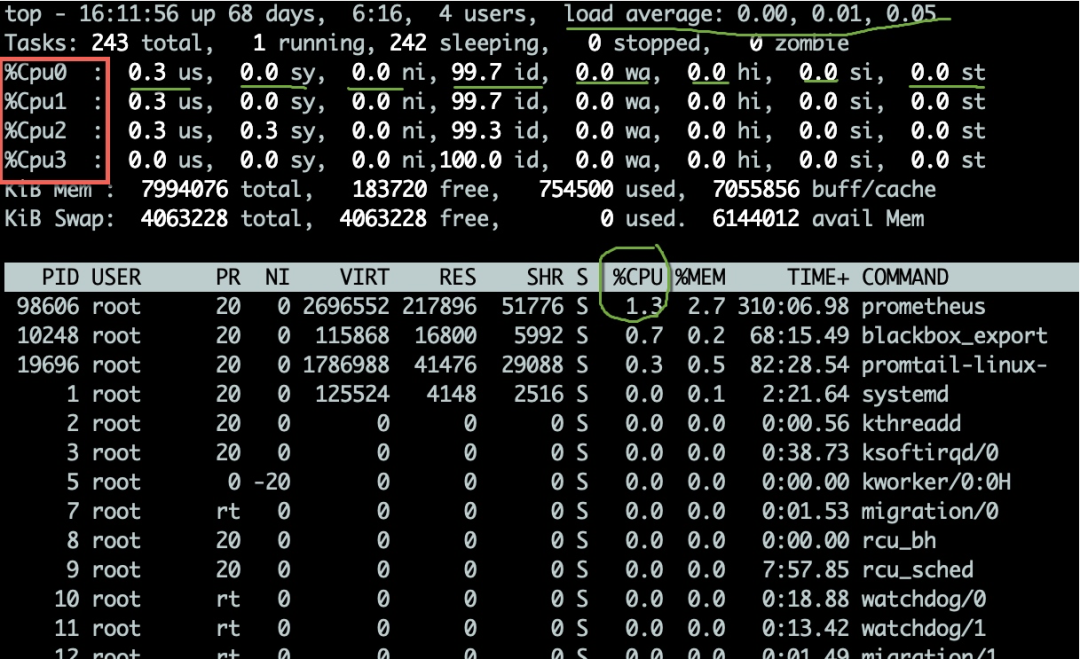
CPU的使用有多个维度的指标,以下分别说明一下:
us 用户态所占用的CPU百分比。 sy 内核态所占用的CPU百分比。如果这个值过高,需要配合vmstat命令,查看是否是上下文切换是否频繁。 ni 高优先级应用所占用的CPU百分比。 wa 等待I/O设备所占用的CPU百分比。如果这个值非常高,输入输出设备可能存在非常明显的瓶颈。 hi 硬件中断所占用的CPU百分比。 si 软中断所占用的CPU百分比。 st 这个一般发生在虚拟机上,指的是虚拟CPU等待实际CPU时间的百分比。如果这个值过大,则你的宿主机压力可能过大。如果你是云主机,则你的服务商可能存在超卖。 id 空闲CPU百分比。
一般的,我们比较关注空闲CPU的百分比,它可以从整体上体现CPU的利用情况。
1.2 什么是负载
我们还要评估CPU任务执行的排队情况,这些值就是负载(load)。top命令,显示的CPU负载,分别是最近1分钟、5分钟、15分钟的数值。
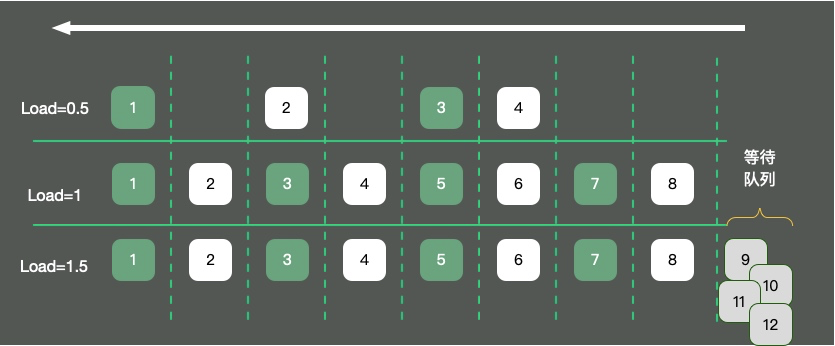
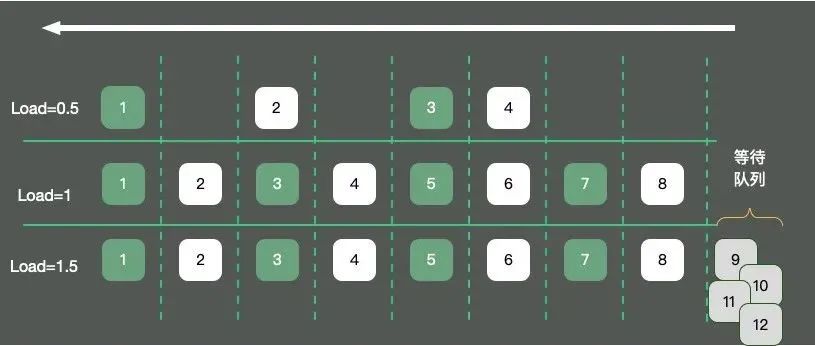
如图,以单核操作系统为例,将CPU资源抽象成一条单向行驶的马路。则会发生三种情况:
马路上的车只有 4辆,车辆畅通无阻,load大约是0.5。马路上的车有8辆,正好能首尾相接安全通过,此时load大约为1。 马路上的车有12辆,除了在马路上的8辆车,还有4辆等在马路外面,需要排队。此时load大约为1.5。
那load为1代表的是啥?针对这个问题,误解还是比较多的。
很多同学认为,load达到1,系统就到了瓶颈,这不完全正确。load的值和cpu核数息息相关。举例如下:
单核的负载达到1,总load的值约1。 双核的每核负载都达到1,总load约2。 四核的每核负载都达到1,总load约为4。
所以,对于一个load到了10,却是16核的机器,你的系统还远没有达到负载极限。通过uptime命令,同样能够看到负载情况。
1.3 vmstat
要看CPU的繁忙程度,还可以通过vmstat命令。下面是vmstat命令的一些输出信息。
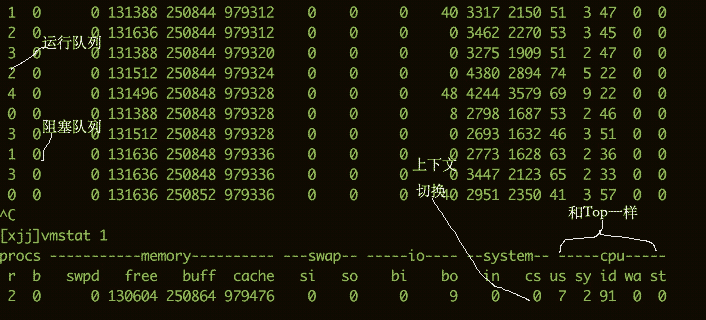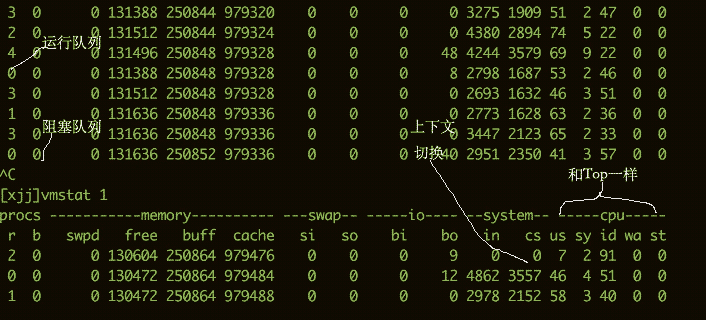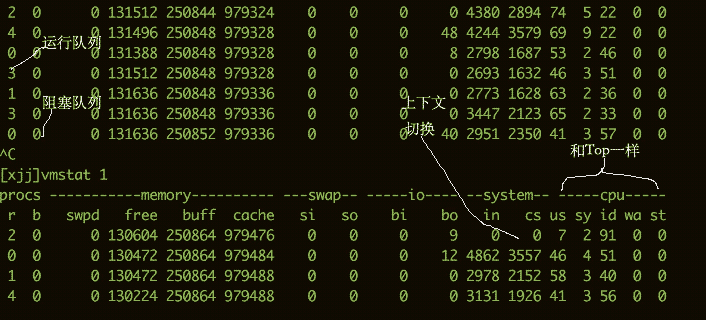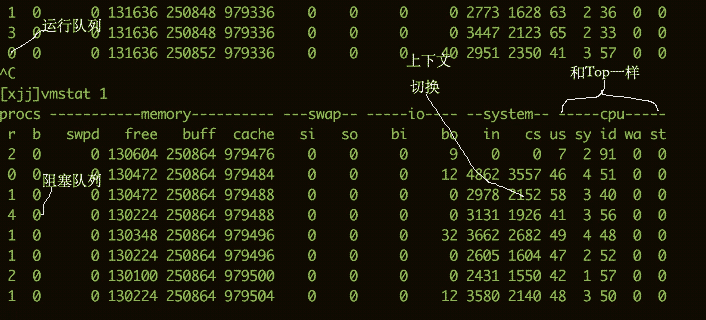
我们比较关注的有下面几列:
b存在于等待队列的内核线程数目,比如等待I/O等。数字过大则cpu太忙。cs代表上下文切换的数量。如果频繁的进行上下文切换,就需要考虑是否是线程数开的过多。si/so显示了交换分区的一些使用情况,交换分区对性能的影响比较大,需要格外关注。
$ vmstat 1
procs ---------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
34 0 0 200889792 73708 591828 0 0 0 5 6 10 96 1 3 0 0
32 0 0 200889920 73708 591860 0 0 0 592 13284 4282 98 1 1 0 0
32 0 0 200890112 73708 591860 0 0 0 0 9501 2154 99 1 0 0 0
32 0 0 200889568 73712 591856 0 0 0 48 11900 2459 99 0 0 0 0
32 0 0 200890208 73712 591860 0 0 0 0 15898 4840 98 1 1 0 0
^C
2.内存
2.1 观测命令
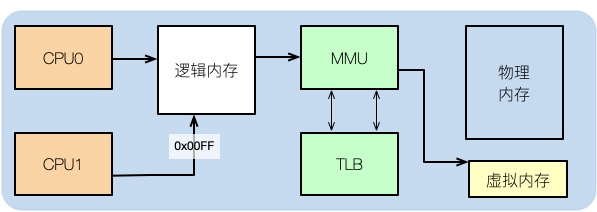
要想了解内存对性能的一些影响,就需要从操作系统层面来看一下内存的分布。
我们在平常写完代码后,比如写了一个C++程序,如果去查看它的汇编,可以看到其中的内存地址,并不是实际的物理内存地址。
那么应用程序所使用的,就是逻辑内存,这个学过计算机组成结构的同学都有了解。
逻辑地址可以映射到物理内存和虚拟内存上。比如你的物理内存是8GB,分配了16GB的SWAP分区,那么应用可用的总内存就是24GB。
从top命令可以看到几列数据,注意方块括起来的三个区域,解释如下:
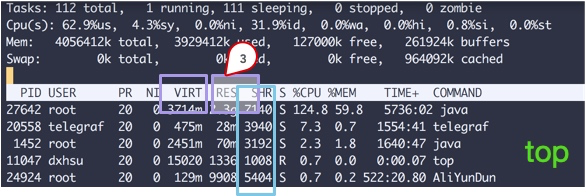
VIRT 这里就是虚拟内存,一般比较大,不用做过多关注。 RES 我们平常关注的就是这一列的数值,它代表了进程实际占用的内存。平常在做监控时,也主要是监控这个数值。 SHR 指的是共享内存,比如可以复用的一些so文件等。
2.2 CPU缓存
由于CPU核内存之间的速度差异是非常大的,解决方式就是加入高速缓存。其实,这些高速缓存,往往会有多层,如下图。
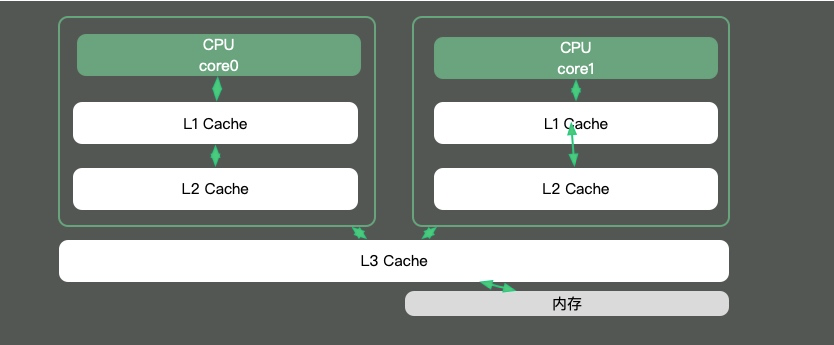
Java有大部分知识点是围绕多线程的,那是因为,如果一个线程的时间片跨越了多个CPU,那么就会存在同步问题。
在Java中,最典型的和CPU缓存相关的知识点,就是并发编程中,针对Cache line的伪共享(false sharing)问题。
伪共享是指:在这些高速缓存中,是以缓存行为单位进行存储的。哪怕你修改了缓存行中一个很小很小的数据,它都会整个的刷新。所以,当多线程修改一些变量的值时,如果这些变量在同一个缓存行里,就会造成频繁刷新,无意中影响彼此的性能。
通过以下命令即可看到当前操作系统的缓存行大小。
cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size
通过以下命令可以看到不同层次的缓存大小。
[root@localhost ~]# cat /sys/devices/system/cpu/cpu0/cache/index1/size
32K
[root@localhost ~]# cat /sys/devices/system/cpu/cpu0/cache/index2/size
256K
[root@localhost ~]# cat /sys/devices/system/cpu/cpu0/cache/index3/size
20480K
在JDK8以上的版本,通过开启参数-XX:-RestrictContended,就可以使用注解@sun.misc.Contended进行补齐,来避免伪共享的问题。在并发优化中,我们再详细讲解。
2.3 HugePage
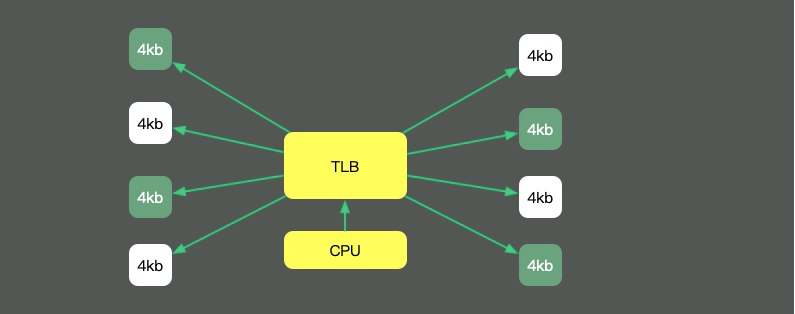
回头看我们最长的那副图,上面有一个叫做TLB的组件,它的速度虽然高,但容量也是有限的。这就意味着,如果物理内存很大,那么映射表的条目将会非常多,会影响CPU的检索效率。
默认内存是以4K的page来管理的。如图,为了减少映射表的条目,可采取的办法只有增加页的尺寸。像这种将Page Size加大的技术,就是Huge Page。
HugePage有一些副作用,比如竞争加剧,Redis还有专门的研究(https://redis.io/topics/latency) ,但在一些大内存的机器上,开启后会一定程度上增加性能。
2.4 预先加载
另外,一些程序的默认行为,也会对性能有所影响。比如JVM的-XX:+AlwaysPreTouch参数。默认情况下,JVM虽然配置了Xmx、Xms等参数,但它的内存在真正用到时,才会分配。
但如果加上这个参数,JVM就会在启动的时候,把所有的内存预先分配。这样,启动时虽然慢了些,但运行时的性能会增加。
3.I/O
3.1 观测命令
I/O设备可能是计算机里速度最差的组件了。它指的不仅仅是硬盘,还包括外围的所有设备。
硬盘有多慢呢?我们不去探究不同设备的实现细节,直接看它的写入速度(数据未经过严格测试,仅作参考)。
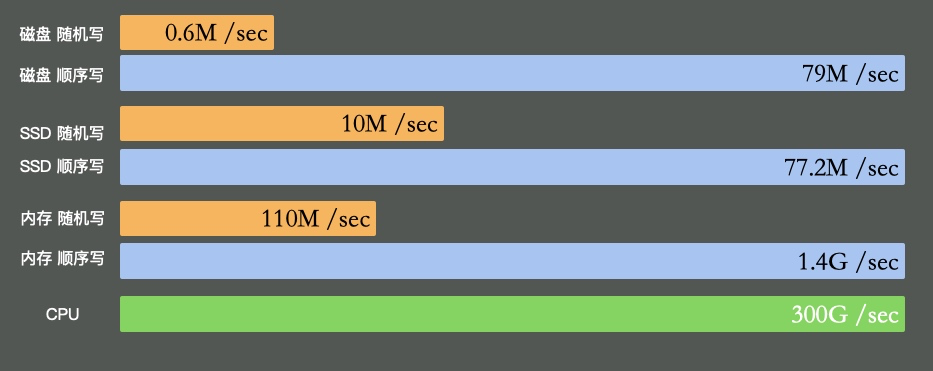
可以看到普通磁盘的随机写和顺序写相差是非常大的。而随机写完全和cpu内存不在一个数量级。
缓冲区依然是解决速度差异的唯一工具,在极端情况比如断电等,就产生了太多的不确定性。这些缓冲区,都容易丢。
最能体现I/O繁忙程度的,就是top命令和vmstat命令中的wa%。如果你的应用,写了大量的日志,I/O wait就可能非常的高。
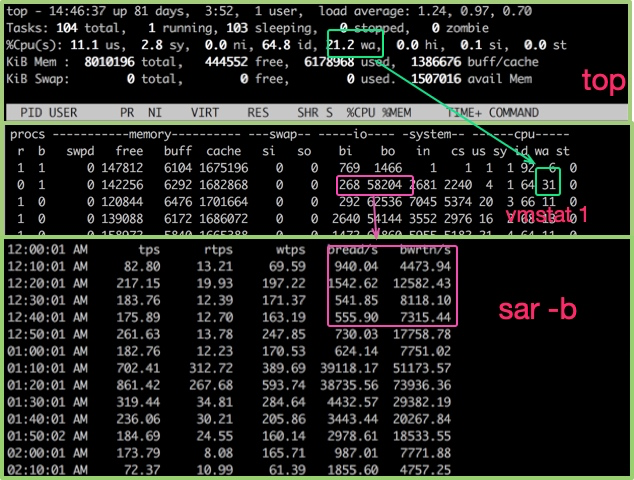
对于硬盘来说,可以使用iostat命令来查看具体的硬件使用情况。只要%util超过了80%,你的系统基本上就跑不动了。
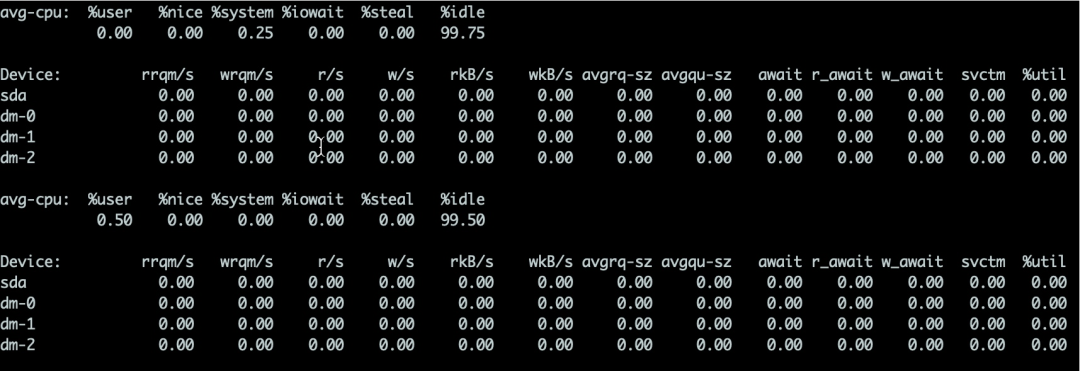
详细介绍如下:
%util 最重要的判断参数。一般地,如果该参数是100%表示设备已经接近满负荷运行了 Device 表示发生在哪块硬盘。如果你有多快,则会显示多行 avgqu-sz 这个值是请求队列的饱和度,也就是平均请求队列的长度。毫无疑问,队列长度越短越好。 await 响应时间应该低于5ms,如果大于10ms就比较大了。这个时间包括了队列时间和服务时间 svctm 表示平均每次设备 I/O操作的服务时间。如果svctm的值与await很接近,表示几乎没有I/O等待,磁盘性能很好,如果await的值远高于svctm的值,则表示I/O队列等待太长,系统上运行的应用程序将变慢。
3.2 零拷贝
kafka比较快的一个原因就是使用了zero copy。所谓的Zero copy,就是在操作数据时, 不需要将数据buffer从一个内存区域拷贝到另一个内存区域。因为少了一次内存的拷贝, CPU的效率就得到提升。
我们来看一下它们之间的区别:
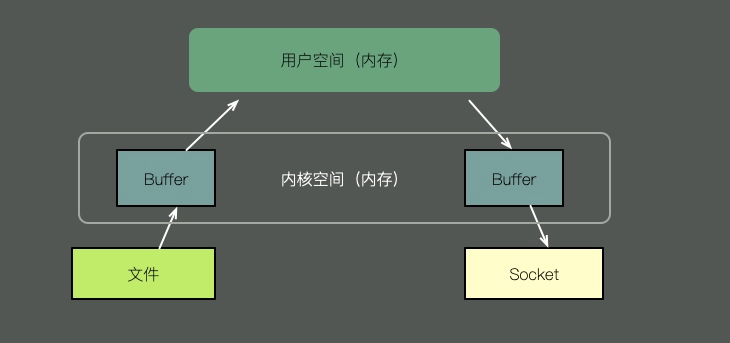
要想将一个文件的内容通过socket发送出去,传统的方式需要经过以下步骤:
将文件内容拷贝到内核空间。 将内核空间的内容拷贝到用户空间内存,比如Java应用。 用户空间将内容写入到内核空间的缓存中。 socket读取内核缓存中的内容,发送出去。
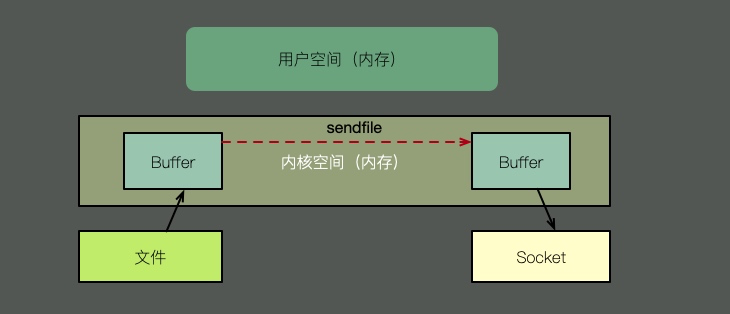
零拷贝又多种模式,我们拿sendfile来说明。如上图,在内核的支持下,零拷贝少了一个步骤,那就是内核缓存向用户空间的拷贝。即节省了内存,也节省了CPU的调度时间,效率很高。
4.网络
除了iotop、iostat这些命令外,sar命令可以方便的看到网络运行状况,下面是一个简单的示例,用于描述入网流量和出网流量。
$ sar -n DEV 1
Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)
12:16:48 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
12:16:49 AM eth0 18763.00 5032.00 20686.42 478.30 0.00 0.00 0.00 0.00
12:16:49 AM lo 14.00 14.00 1.36 1.36 0.00 0.00 0.00 0.00
12:16:49 AM docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
12:16:49 AM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
12:16:50 AM eth0 19763.00 5101.00 21999.10 482.56 0.00 0.00 0.00 0.00
12:16:50 AM lo 20.00 20.00 3.25 3.25 0.00 0.00 0.00 0.00
12:16:50 AM docker0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
^C
当然,我们可以选择性的只看TCP的一些状态。
$ sar -n TCP,ETCP 1
Linux 3.13.0-49-generic (titanclusters-xxxxx) 07/14/2015 _x86_64_ (32 CPU)
12:17:19 AM active/s passive/s iseg/s oseg/s
12:17:20 AM 1.00 0.00 10233.00 18846.00
12:17:19 AM atmptf/s estres/s retrans/s isegerr/s orsts/s
12:17:20 AM 0.00 0.00 0.00 0.00 0.00
12:17:20 AM active/s passive/s iseg/s oseg/s
12:17:21 AM 1.00 0.00 8359.00 6039.00
12:17:20 AM atmptf/s estres/s retrans/s isegerr/s orsts/s
12:17:21 AM 0.00 0.00 0.00 0.00 0.00
^C
5.End
不要寄希望于这些指标,能够立刻帮助我们定位性能问题。这些工具,只能够帮我们大体猜测发生问题的地方,它对性能问题的定位,只是起到辅助作用。想要分析这些bottleneck,需要收集更多的信息。
想要获取更多的性能数据,就不得不借助更加专业的工具,比如基于eBPF的BCC工具,这些牛x的工具我们将在其他文章里展开。读完本文,希望你能够快速的了解Linux的运行状态,对你的系统多一些掌控。
良许花了一个半月的时间研发了一门 Linux 命令课程,欢迎购买学习!
课程特色:
详细总结 150 个高频使用命令,学完可应对工作中 95% 命令需求; 答疑群提供无限次答疑服务,答疑群氛围很好; 总时长超 10 小时,媲美大课时长。

强烈推荐一位腾讯大佬录制的 Shell 实战案例课程(已获授权):
大佬在腾讯工作 6 年,在大厂工作十几年,经验丰富; 大佬根据自己在大厂工作经验总结了 100 个案例,超级实用! 学完这 100 个案例,肯定对自己的 Shell 编程有很大的提升; 答疑群提供无限次答疑服务,答疑群氛围很好。
