
Nature评选改变科学的10个计算机代码,arXiv、AlexNet等上榜
大数据文摘
共 7389字,需浏览 15分钟
·
2021-02-17 09:36

1 语言先驱:Fortran编译器(1957)


3 分子编目:生物资料库(1965)
4 预测领导者:环流模式(1969)
5 数值计算研究机:BLAS(1979)

6 显微镜必备:NIH图像(1987)

7 序列搜索:BLAST(1990)
可能没有比软件名称成为动词更好的文化相关性指示符了。提到搜索,会想到谷歌。提到遗传学,研究者的第一直觉会是BLAST。
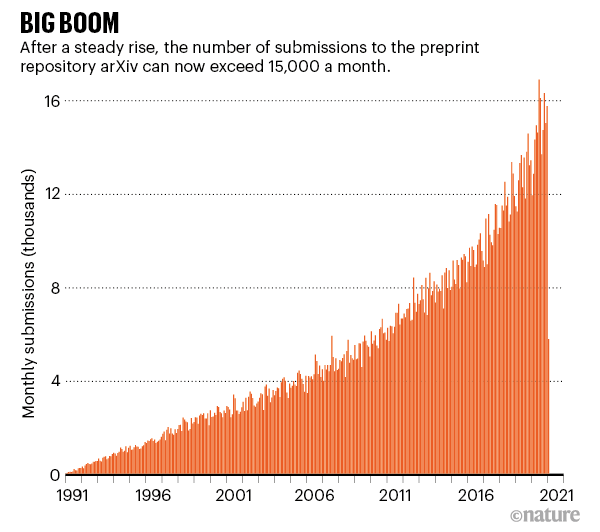
8 预印本平台:arXiv.org(1991)
9 数据浏览器:IPython Notebook (2011)
Fernando Pérez在2001还是一名研究生的时候,开始探索拖延症,当时他决定使用Python的一个核心组件进行研究。
评论