
基于AutoTagging技术实践,构建统一的可观测性数据平台


混合云以及容器逐渐成为承载微服务应用的主要基础设施,对于云原生应用的监控保障,也面临诊断难、规模广、弹性大、波动性强等挑战,这些挑战同时也使得云原生应用可观测性成为了运维开发关注的焦点。基于云杉网络在混合云网络场景下的多年实践,给大家分享在构建统一的云原生应用可观测性数据平台中的一些思考和经验。
1-2 人工智能系统概述和深度网络基础
3 深度神经网络网络计算框架基础
4 矩阵运算与计算机体系结构
5 深度学习中的分布式训练-算法
10 神经网络的稀疏化
6 深度学习中的分布式训练-系统
7 异构计算集群调度与资源管理系统
8 深度学习推理系统
9 计算图的编译与优化
11 自动机器学习系统
12 强化学习系统
13 人工智能的安全隐私
14 利用人工智能优化计算机系统
一. 可观测性数据平台的挑战
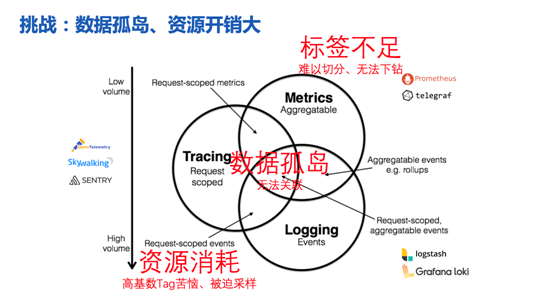
如何理解可观测性数据平台的要素。Peter Bourgon有个很好的总结,从数据类型的角度分为Metrics、Tracing、Logging,这个总结在业内家喻户晓,其实这三个类型的数据也将江湖上的方案划分为了三个派别:指标优先、追踪优先、日志优先。这使得每个开源组件能在自己擅长的领域内做到最好,但也导致了三类数据之间沟壑明显,无法关联。引出了三个关键性问题:数据粒度粗,数据无法关联、资源开销大。三类数据无法关联、无法流通,使用困难。追踪和日志数据体量很大,资源开销难以承受,经常需要削足适履,做采样抹掉高基数字段等。
二. 常见的6种数据孤岛场景
正如文章开头所说,其实可观测性方案是分门派、分信仰的。例如SkyWalking、OpenTelemetry大侠就都来自‘追踪派’,以Tracing为核心维护了一个Context,使得Metrics、Log生成时都能打上同样的Tag以及TraceID、SpanID。
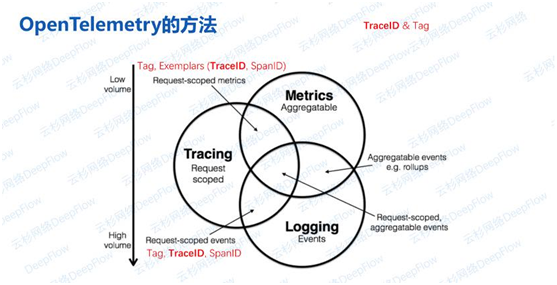
Metrics通过Examplars关联至Trace,而Log和Trace之间也通过TraceID、SpanID进行关联,核心是TraceID,辅助是Context中的Tag。但这样的关联并不完善,这样的关联仅限于Tracing与其他两种数据的交叠部分,一些常见的问题还是无法回答,比如以下几个场景:
场景一:Trace和非Request Scope的Metrics关联
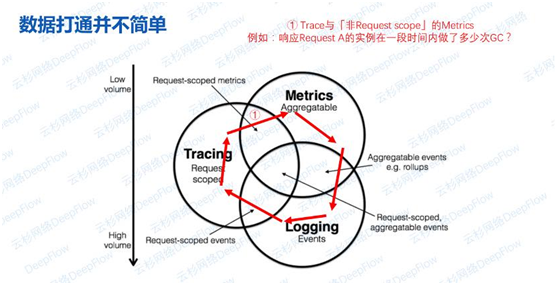
这里分两种指标:请求相关和非请求相关。前者包括某个请求的应用时延、网络性能;后者有某个实例的CPU、内存、GC、内部数据结构,还包括实例所在虚拟机、宿主机的性能指标。这两部分数据不能通过TraceID关联,可能会导致一些问题,例如响应某个请求的实例在某个时间的指标曲线是怎样的?从一个Span能否跳转到指标曲线?
场景二:Metrics与Metrics之间关联
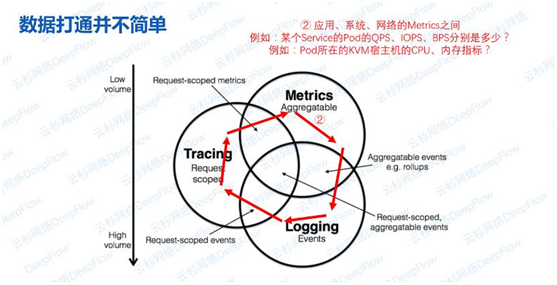
这里的指标可能来自不同的数据源,这些数据源打着不同的Tag,例如某个服务的Pod的请求速率、IO速率、网络流量速率分别是多少?Pod所在的虚拟机或KVM宿主机的CPU、内存是多少?如何做到无缝关联。
场景三:Metrics与非Aggregatable的日志之间关联
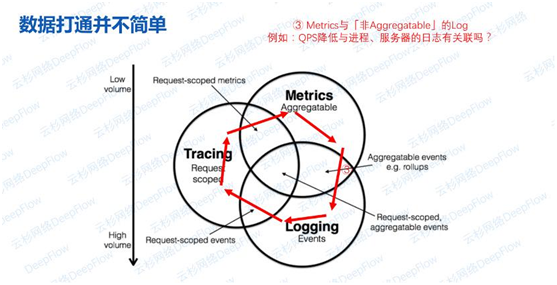
在看到QPS下降时,能否快速关联到进程相关的Pod、虚拟机、KVM日志。这个时候是某一个进程的QPS降低了吗?或者是某个服务它的QPS降低了吗?
场景四:日志与日志之间关联
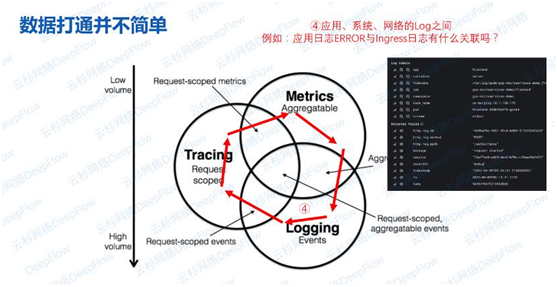
日志一般携带主机名、进程名信息。Loki做的比较好,能自动将K8s中的日志关联上Pod、Namespace、Node等标签,但也依然难回答一些跨进程的问题,例如应用日志中的错误与Ingress日志有关联吗?
场景五:非Request scope的Log与Trace之间关联

系统日志异常与Request时延增大是否有关联?能否快速跳转?通常会有这样的系统日志,一个异常和Request的时延增大,这是不是有问题?某一个Request的时延增大,那它所在的Workload,它所在的VM是不是有异常?
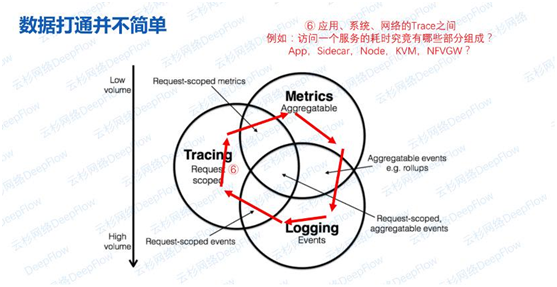
举一个简单的场景:访问一个服务的耗时究竟由哪些部分组成?瓶颈是在应用程序,还是在中间链路上?如果是在链路上,那么哪部分的耗时最大?Sidecar、Node、KVM、NFV网关?
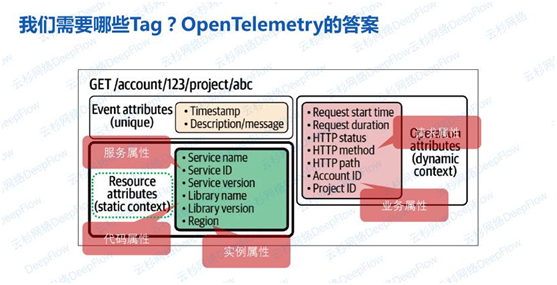
从上述场景中可以发现,其实是缺少了标签,而导致了不同数据源之间的数据无法关联。那我们到底需要哪些标签呢?先看看OpenTelemetry是怎么看待这个问题的。OTel中的标签叫做属性(attribute),并且将标签分为静态的,表示资源的属性;以及动态的,表示请求的属性。资源属性中有描述服务的,例如Service Name等;描述代码的,例如依赖库版本;描述实例的,例如区域等。属性非常多,但在一个混合云的场景下,要解决上文的6种场景还远远不够。
三. 解决数据孤岛:AutoTagging
说了这么多以后,接下来分享DeepFlow的AutoTagging技术,它解决了数据孤岛的问题。在DeepFlow的典型客户中,两个微服务之间通信所涉及到的标签可能多达上百个。比如K8s中的集群、节点、命名空间、服务、Ingress、Deployment、POD。再比如K8s中大量的自定义Label,包括版本version、环境env、组、owner;以及与CI/CD相关的stage、commitId、deployId等(这里列出来的只是自定义标签中的很小一部分)。

这些标签都期待开发者在代码中注入是不现实的,会带来沉重的开发负担。其实这些标签已经存在于某个地方了,奔着一个信息只需要一个源的偷懒原则,开发者当然希望这些分散在各处的标签能自动追加到所有的观测数据中。DeepFlow产品发展了数年,已经能支持市面上常见的公有云、私有云、容器,自动同步其中的资源和服务标签,并自动与观测数据关联起来。
目前支持的数据围绕Trace展开,每个请求的详细日志,以及请求聚合后的RED指标等等,所有覆盖到了网络和应用。利用这些标签可以快速在指标、追踪、流日志之间无缝跳转,也可以在搜索条件中追加这些标签对数据进行进一步的切分和下钻。
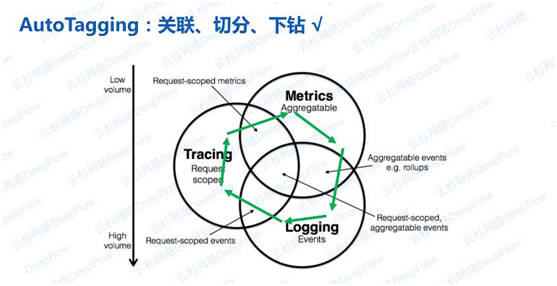
看了这张图,再回顾上文6种数据孤岛场景里提出的一系列数据关联、数据切分、数据下钻的问题就有了答案。通过控制器和云API、K8S apiserve,以及正在推进的服务注册中心的信息同步,将所有资源的标签、容器服务的标签、自定义的标签、乃至于服务注册中心中某一个API都打上标签。再通过eBPF的方式拿到的追踪数据(在HTTP的header里面,或者在任何其他的应用协议头部里面注入的字段),从而无缝的实现数据关联。

虽然做到了AutoTagging,还是会带来另一个问题,大量自动标签的注入带来了资源消耗的飙升。使用MultistageCodec编码技术可以有效降低资源开销这一问题。
四、降低资源开销:MultistageCodec
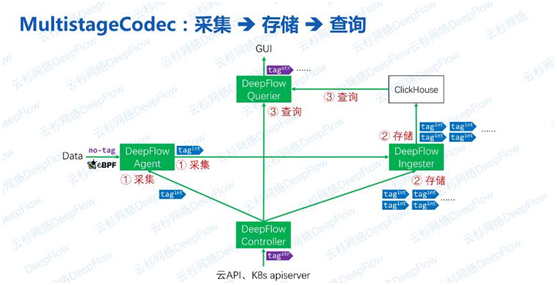
这是一个数据从采集到存储到查询的流程。Agent在采集到数据时通常是从流量或eBPF系统调用中获取的请求数据,原始数据几乎不含有Tag(除了开发者注入到请求Header中的标签以外)。Controller和云API、K8s apiserver进行同步获取所有资源、服务、自定义标签,并将其编码后下发给Agent和Ingester。Agent传输、Ingester存储使用的都是编码后的‘整形标签‘,最终经过Querier的查询计算还原为字符串标签。
因为我们存储使用的ClickHouse,所以告别了高基数的烦恼,“时间线”数量不再是需要考虑的一个问题。在这个流程中,实际上编解码是分多个阶段进行的。
第一阶段:采集编解码
Controller并不会将所有的标签下发给Agent,它只会将标签的“基”下发。这样Agent只需要为数据追加很少的标签即可。在混合云场景下为了标识资源,可以用VPC ID作为基,它能和IP地址联合决定客户端、服务端对应的实例和服务。
第二阶段:存储编解码
同样Controller会将标签编码‘整形’后发给Ingester。Ingester在收到Agent发过来的数据后,会进行一轮Tag的Enrich,基于Agent注入的标签基,扩展为更为丰富的标签集合。但需要注意的是,并不需要存储所有的标签。标签的存储是为了方便检索和聚合,只需要保证每个切分粒度上都有标签存在即可。举个例子:可以将Region、AZ、Host、VM、Node、Namespace、Service、Deployment、POD等固定、系统级别的标签存储即可,其他的自定义的标签一般是依附在这些系统级别标签之上的,存在一一对应的关系。另外,自定义标签动态性高,且无法预知Schema,也不适合全部存储。根据我们的实践,一般每一个请求涉及到的系统级别的标签在40个左右,自定义标签在60个左右。通过只存储系统标签,能将压力进一步降低。
第三阶段:查询编解码
通过字符串查询、聚合,并且也支持没有存储的自定义标签的查询、聚合。这里依赖ClickHouse举个例子,可以创建一个Pod名称和ID对应关系的字典表,这个表可以通过文件、MySQL同步到CK中,也可以直接在CK中创建。在一个CK集群中,让每个节点都从统一的MySQL同步字典是个好办法,这样每个节点上就都会有一个字典副本。如果数据库不适用CK,也可以用Join来实现。
通过这三级编解码能节省大量的资源消耗,性能提升十分可观。一方面采集侧CPU、内存可以降低,传输带宽也降低了,最主要的还是后端存储开销的降低。在ClickHouse基础上的多级编解码能将存储开销最大化的降低,而且由于查询阶段扫描的数据量变小了,可以获得更好的查询性能。这样的处理机制也是即将开源的可观测性数据流引擎中的核心。
五、实战效果:资源消耗不到1%
用一个实例来看这个机制的实际效果,首先对比三种存储方式:
直接存索引:使用MultistageCodec为Tag编码,向CK中存储编码后的Int值。
索引和标签分离:将Tag存为LowCard字段(即CK在存储前将字符串转换为整数,相当于CK做了额外的Tag索引)。
直接存标签:直接将Tag字符串存储到CK中。
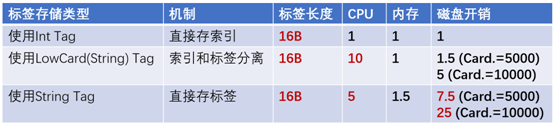
三种方式使用的均为长度为16字节的字符串标签(这个长度其实比一般生产环境中的标签要短得多)。索引和标签分离的方式相比直接存字符串能显著降低磁盘消耗,且能够将CPU消耗降低至1/2。而MultistageCodec相比于其他两种方案都能做到一个数量级的性能提升,效果立竿见影。如果考虑到还有60%的自定义标签是我们在查询期翻译的,那优化的幅度更大。


最后来看看在生产环境的实际表现,用一句话来说,在Server端的资源消耗不到被监控对象的1%。我们在一个生产环境中监控了600个16C的容器节点,上面运行了8000个POD,每秒总的写入速率能到百万行,每行数据都是一个宽表(100到150列),这里面包含了写入的系统级标签和关联的指标数据、请求属性等。这个环境总共用了6个16C的虚拟机来承载,但他们的负载之和不到60,还有很大余量。
六、总结
本文介绍了AutoTagging和MultistageCodec技术。AutoTagging能为来自不同源头的观测数据注入统一的查询标签,打破观测数据之间的隔阂,并提供强大的数据切分、下钻能力。MultistageCodec技术解决了标签爆炸带来的资源开销问题,可将ClickHouse的存储开销降低10倍,生产实践表明后端资源的配比可低于1%。
全课程下载:
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。
免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
电子书<服务器基础知识全解(终极版)>更新完毕。
获取方式:点击“阅读原文”即可查看182页 PPT可编辑版本和PDF阅读版本详情。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。
