
Longhorn 微服务化存储初探
共 18467字,需浏览 37分钟
·
2021-07-05 14:29
一、Longhorn 安装
1.1、准备工作
Longhorn 官方推荐的最小配置如下,如果数据并不算太重要可适当缩减和调整,具体请自行斟酌:
3 Nodes 4 vCPUs per Node 4 GiB per Node SSD/NVMe or similar performance block device on the node for storage(We don’t recommend using spinning disks with Longhorn, due to low IOPS.)
本次安装测试环境如下:
Ubuntu 20.04(8c16g) Disk 200g Kubernetes 1.20.4(kubeadm) Longhorn 1.1.0
1.2、安装 Longhorn(Helm)
安装 Longhorn 推荐使用 Helm,因为在卸载时 kubectl 无法直接使用 delete 卸载,需要进行其他清理工作;helm 安装命令如下:
# add Longhorn repo
helm repo add longhorn https://charts.longhorn.io
# update
helm repo update
# create namespace
kubectl create namespace longhorn-system
# install
helm install longhorn longhorn/longhorn --namespace longhorn-system --values longhorn-values.yamlCopy
其中 longhorn-values.yaml 请从 Charts 仓库 下载,本文仅修改了以下两项:
defaultSettings:
# 默认存储目录(默认为 /var/lib/longhorn)
defaultDataPath: "/data/longhorn"
# 默认副本数量
defaultReplicaCount: 2Copy
安装完成后 Pod 运行情况如下所示:
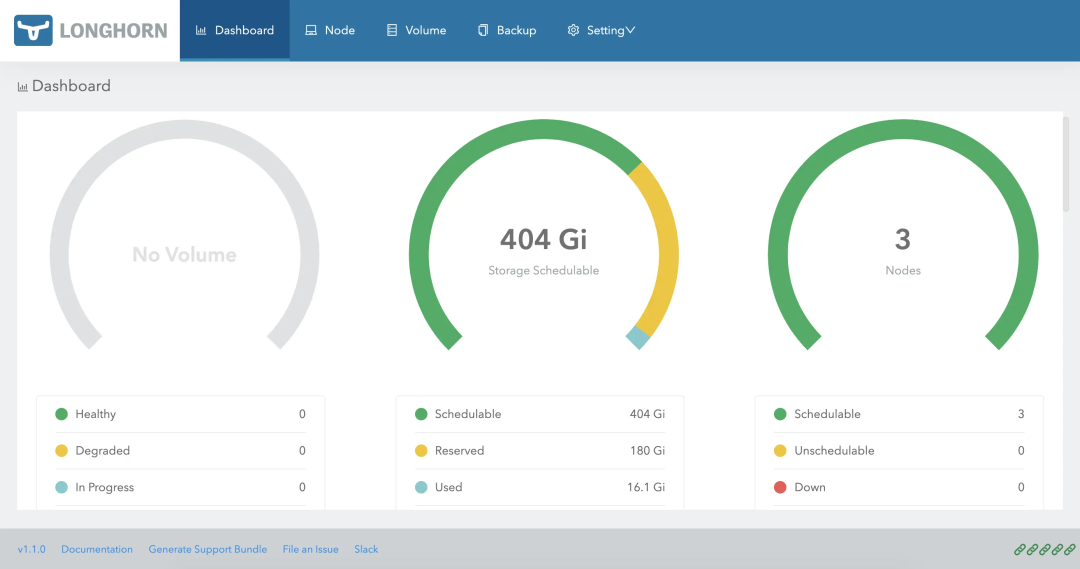
此后可通过集群 Ingress 或者 NodePort 等方式暴露 service longhorn-frontend 的 80 端口来访问 Longhorn UI;注意,Ingress 等负载均衡其如果采用 HTTPS 访问请确保向 Longhorn UI 传递了 X-Forwarded-Proto: https 头,否则可能导致 Websocket 不安全链接以及跨域等问题,后果就是 UI 出现一些神奇的小问题(我排查了好久…)。
1.3、卸载 Longhorn
如果在安装过程中有任何操作错误,或想重新安装验证相关设置,可通过以下命令卸载 Longhorn:
# 卸载
helm uninstall longhorn -n longhorn-systemCopy
二、Longhorn 架构
2.1、Design
Longhorn 总体设计分为两层: 数据平面和控制平面;Longhorn Engine 是一个存储控制器,对应数据平面;Longhorn Manager 对应控制平面。
2.1.1、Longhorn Manager
Longhorn Manager 使用 Operator 模式,作为 Daemonset 运行在每个节点上;Longhorn Manager 负责接收 Longhorn UI 以及 Kubernetes Volume 插件的 API 调用,然后创建和管理 Volume;
Longhorn Manager 在与 kubernetes API 通信并创建 Longhorn Volume CRD(heml 安装直接创建了相关 CRD,查看代码后发现 Manager 里面似乎也会判断并创建一下),此后 Longhorn Manager watch 相关 CRD 资源和 Kubernetes 原生资源(PV/PVC…),一但集群内创建了 Longhorn Volume 则 Longhorn Manager 负责创建物理 Volume。
当 Longhorn Manager 创建 Volume 时,Longhorn Manager 首先会在 Volume 所在节点创建 Longhorn Engine 实例(对比实际行为后发现所谓的 “实例” 其实只是运行了一个 Linux 进程,并非创建 Pod),然后根据副本数量在所需放置副本的节点上创建对应的副本。
2.1.2、Longhorn Engine
Longhorn Engine 始终与其使用 Volume 的 Pod 在同一节点上,它跨存储在多个节点上的多个副本同步复制卷;同时数据的多路径保证 Longhorn Volume 的 HA,单个副本或者 Engine 出现问题不会影响到所有副本或 Pod 对 Volume 的访问。
下图中展示了 Longhorn 的 HA 架构,每个 Kubernetes Volume 将会对应一个 Longhorn Engine,每个 Engine 管理 Volume 的多个副本,Engine 与 副本实质都会是一个单独的 Linux 进程运行:
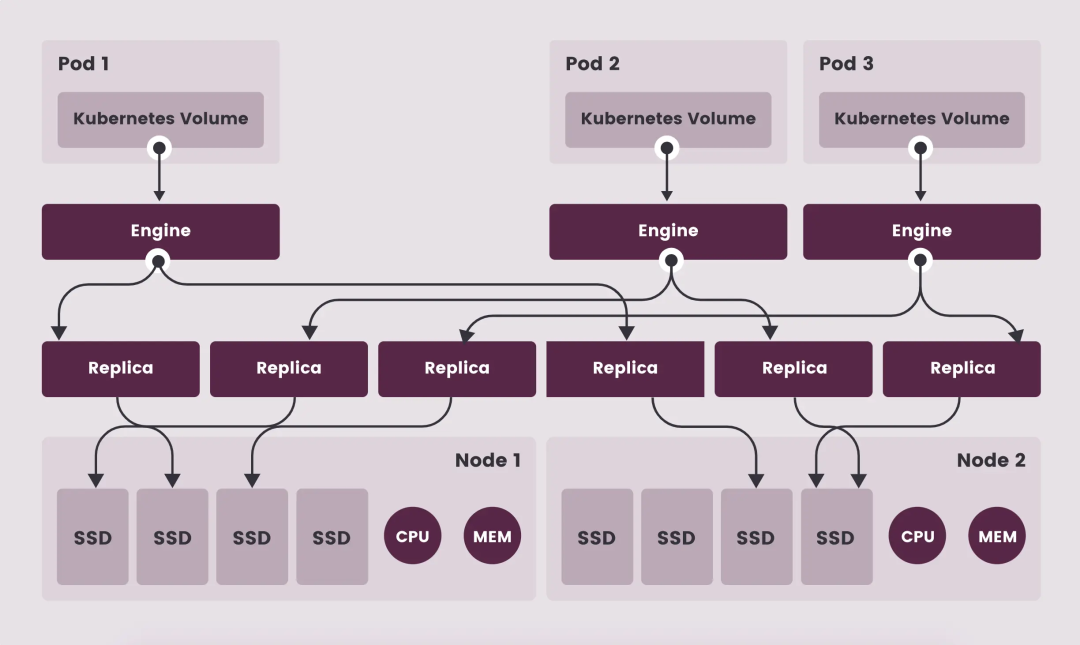
注意: 图中的 Engine 并非是单独的一个 Pod,而是每一个 Volume 会对应一个 golang exec 出来的 Linux 进程。
2.2、CSI Plugin
CSI 部分不做过多介绍,具体参考 如何编写 CSI 插件;以下为简要说明:
Kubernetes CSI 被抽象为具体的 CSI 容器并通过 gRPC 调用目标 plugin Longhorn CSI Plugin 负责接收标准 CSI 容器发起的 gRPC 调用 Longhorn CSI Plugin 将 Kubernetes CSI gRPC 调用转换为自己的 Longhorn API 调用,并将其转发到 Longhorn Manager 控制平面 Longhorn 某些功能使用了 iSCSI,所以可能需要在节点上安装 open-iscsi 或 iscsiadm
2.3、Longhorn UI
Longhorn UI 向外暴露一个 Dashboard,并用过 Longhorn API 与 Longhorn Manager 控制平面交互;Longhorn UI 在架构上类似于 Longhorn CSI Plugin 的替代者,只不过一个是通过 Web UI 转化为 Longhorn API,另一个是将 CSI gRPC 转换为 Longhorn API。
2.4、Replicas And Snapshots
在 Longhorn 微服务架构中,副本也作为单独的进程运行,其实质存储文件采用 Linux 的稀释文件方式;每个副本均包含 Longhorn Volume 的快照链,快照就像一个 Image 层,其中最旧的快照用作基础层,而较新的快照位于顶层。如果数据会覆盖旧快照中的数据,则仅将其包含在新快照中;整个快照链展示了数据的当前状态。
在进行快照时,Longhorn 会创建差异磁盘(differencing disk)文件,每个差异磁盘文件被看作是一个快照,当 Longhorn 读取文件时从上层开始依次查找,其示例图如下:
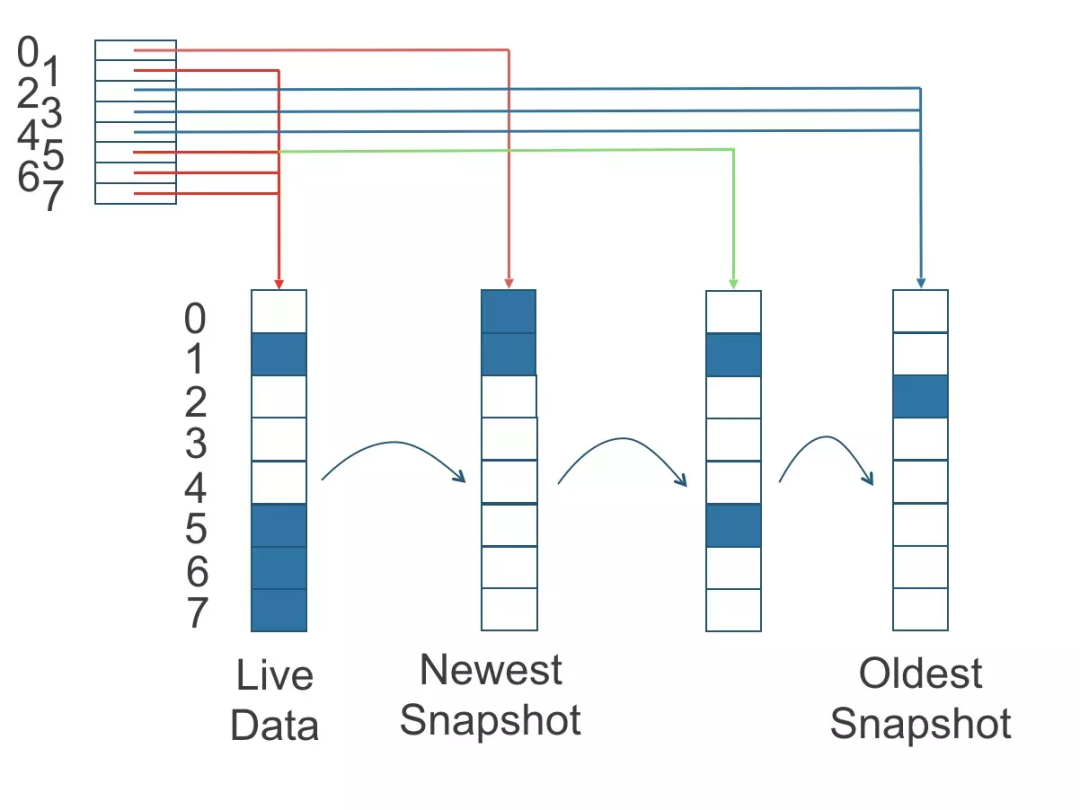
为了提高读取性能,Longhorn 维护了一个读取索引,该索引记录了每个 4K 存储块中哪个差异磁盘包含有效数据;读取索引会占用一定的内存,每个 4K 块占用一个字节,字节大小的读取索引意味着每个卷最多可以拍摄 254 个快照,在大约 1TB 的卷中读取索引大约会消耗256MB 的内存。
2.5、Backups and Secondary Storage
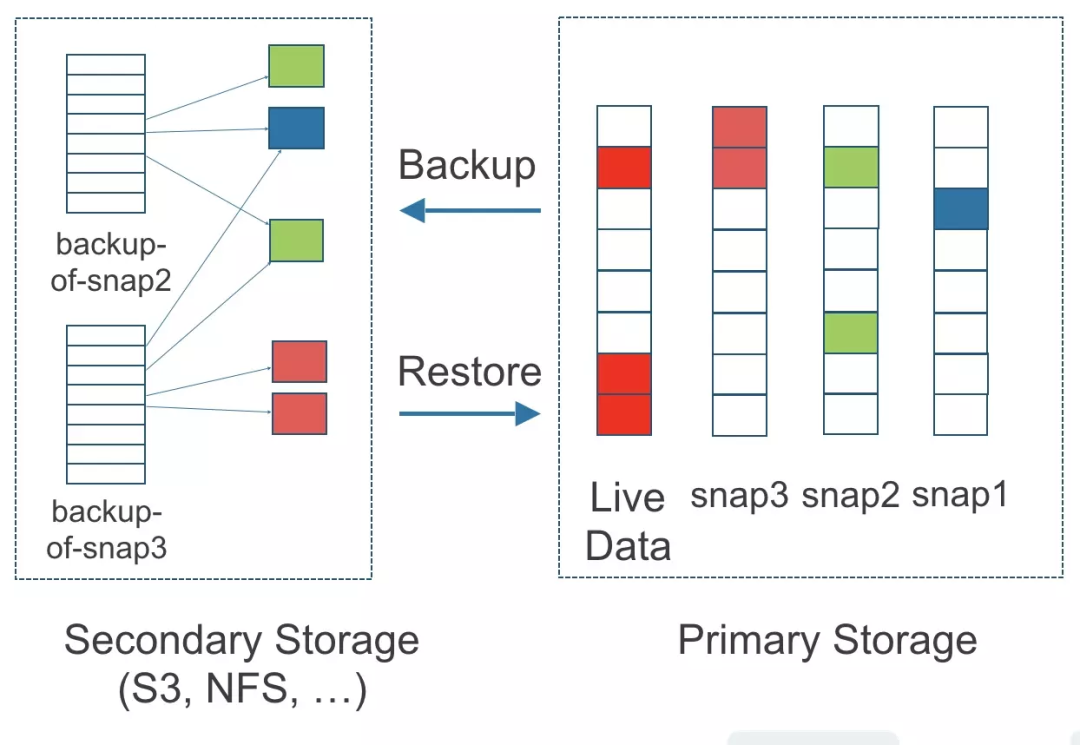
由于数据大小、网络延迟等限制,跨区域同步复制无法做到很高的时效性,所以 Longhorn 提供了称之为 Secondary Storage 的备份方案;Secondary Storage 依赖外部的 NFS、S3 等存储设施,一旦在 Longhorn 中配置了 Backup Storage,Longhorn 将会通过卷的指定版本快照完成备份;**备份过程中 Longhorn 将会抹平快照信息,这意味着快照历史变更将会丢失,相同的原始卷备份是增量的,通过不断的应用差异磁盘文件完成;为了避免海量小文件带来的性能瓶颈,Longhorn 采用 2MB 分块进行备份,任何边界内 4k 块变动都会触发 2MB 块的备份行为;Longhorn 的备份功能为跨集群、跨区域提供完善的灾难恢复机制。**Longhorn 备份机制如下图所示:
2.6、Longhorn Pods
上面的大部分其实来源于对官方文档 Architecture and Concepts 的翻译;在翻译以及阅读文档过程中,通过对比文档与实际行为,还有阅读源码发现了一些细微差异,这里着重介绍一下这些 Pod 都是怎么回事:
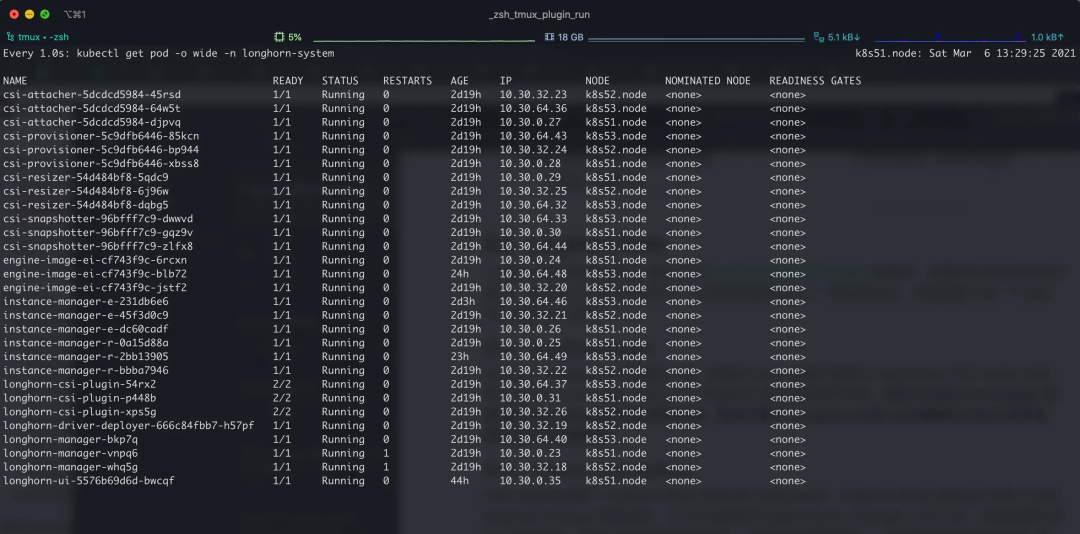
2.6.1、longhorn-manager
longhorn-manager 与文档描述一致,其通过 Helm 安装时直接以 Daemonset 方式 Create 出来,然后 longhorn-manager 开启 HTTP API(9500) 等待其他组件请求;同时 longhorn-manager 还会使用 Operator 模式监听各种资源,包括不限于 Longhorn CRD 以及集群的 PV(C) 等资源,然后作出对应的响应。
2.6.2、longhorn-driver-deployer
Helm 安装时创建了 longhorn-driver-deployer Deployment,longhorn-driver-deployer 实际上也是 longhorn-manager 镜像启动,只不过启动后会沟通 longhorn-manager HTTP API,然后创建所有 CSI 相关容器,包括 csi-provisioner、csi-snapshotter、longhorn-csi-plugin 等。
2.6.3、instance-manager-e
上面所说的每个 Engine 对应一个 Linux 进程其实就是通过这个 Pod 完成的,instance-manager-e 由 longhorn-manager 创建,创建完成后 instance-manager-e 监听 gRPC 8500 端口,其只要职责就是接收 gRPC 请求,并启动 Engine 进程;从上面我们 Engine 介绍可以得知 Engine 与 Volume 绑定,所以理论上集群内 Volume 被创建时有某个 “东西” 创建了 CRD engines.longhorn.io,然后又有人 watch 了 engines.longhorn.io 并通知 instance-manager-e 启动 Engine 进程;这里不负责任的推测是 longhorn-manager 干的,但是没看代码不敢说死…
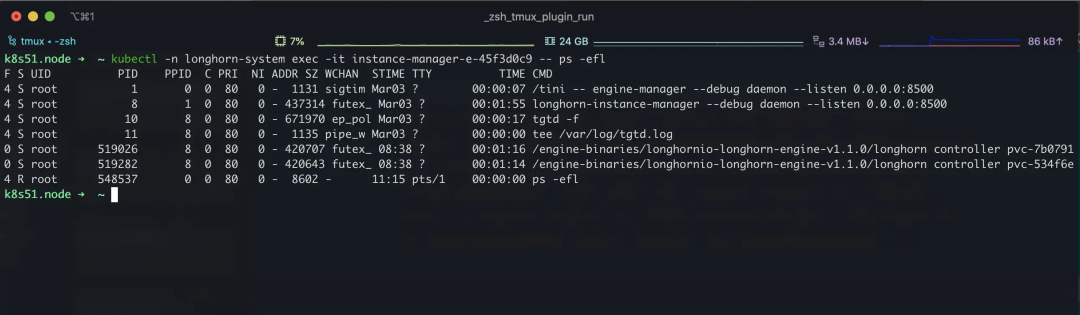
同理 instance-manager-r 是负责启动副本的 Linux 进程的,工作原理与 instance-manager-e 相同,通过简单的查看代码(IDE 没打开…哈哈哈)推测,instance-manager-e/-r 应该是 longhorn-manager Operator 下的产物,其维护了一个自己的 “Daemonset”,但是 kubectl 是看不到的。
2.6.4、longhorn-ui
longhorn-ui 很简单,就是个 UI 界面,然后 HTTP API 沟通 longhorn-manager,这里不再做过多说明。
三、Longhorn 使用
3.1、常规使用
默认情况下 Helm 安装完成后会自动创建 StorageClass,如果集群中只有 Longhorn 作为存储,那么 Longhorn 的 StorageClass 将作为默认 StorageClass。关于 StorageClass、PV、PVC 如果使用这里不做过多描述,请参考官方 Example 文档;
**需要注意的是 Longhorn 作为块存储仅支持 ReadWriteOnce 模式,如果想支持 ReadWriteMany 模式,则需要在节点安装 nfs-common,Longhorn 将会自动创建 share-manager 容器然后通过 NFSV4 共享这个 Volume 从而实现 ReadWriteMany;**具体请参考 Support for ReadWriteMany (RWX) workloads。
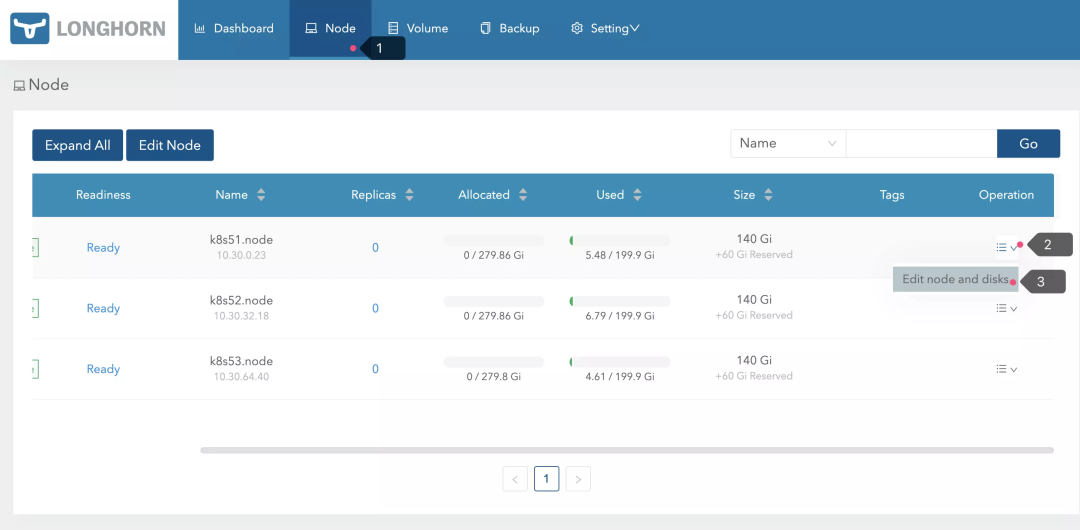
3.2、添加删除磁盘
如果出现磁盘损坏重建或者添加删除磁盘,请直接访问 UI 界面,通过下拉菜单操作即可;在操作前请将节点调整到维护模式并驱逐副本,具体请参考 Evicting Replicas on Disabled Disks or Nodes。
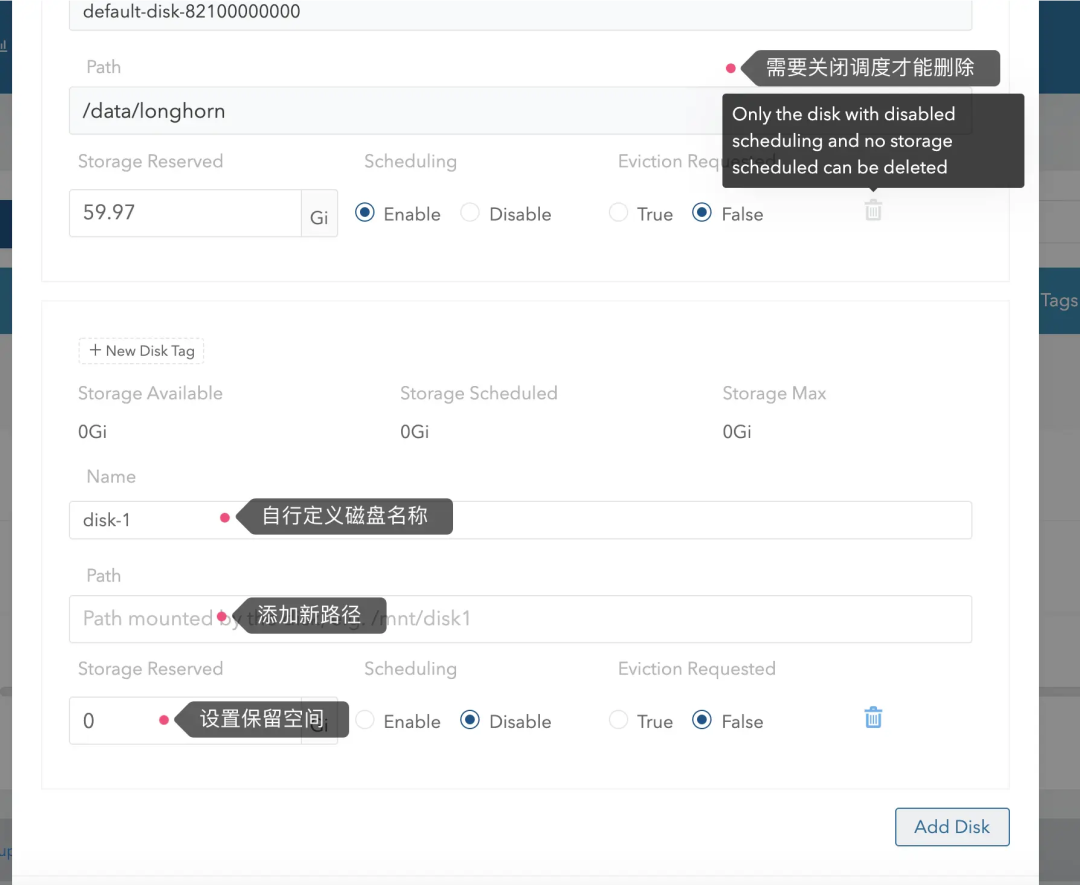
需要注意的是添加新磁盘时,磁盘挂载的软连接路径不能工作,请使用原始挂载路径或通过 mount --bind 命令设置新路径。
3.3、创建快照及回滚
当创建好 Volume 以后可以用过 Longhorn UI 在线对 Volume 创建快照,**但是回滚快照过程需要 Workload(Pod) 离线,同时 Volume 必须以维护模式 reattach 到某一个 Host 节点上,然后在 Longhorn UI 进行调整;**以下为快照创建回滚测试:
test.pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: longhorn-simple-pvc
spec:
accessModes:
- ReadWriteOnce
storageClassName: longhorn
resources:
requests:
storage: 1GiCopy
test.po.yaml
apiVersion: v1
kind: Pod
metadata:
name: longhorn-simple-pod
namespace: default
spec:
restartPolicy: Always
containers:
- name: volume-test
image: nginx:stable-alpine
imagePullPolicy: IfNotPresent
livenessProbe:
exec:
command:
- ls
- /data/lost+found
initialDelaySeconds: 5
periodSeconds: 5
volumeMounts:
- name: volv
mountPath: /data
ports:
- containerPort: 80
volumes:
- name: volv
persistentVolumeClaim:
claimName: longhorn-simple-pvcCopy
3.3.1、创建快照
首先创建相关资源:
kubectl create -f test.pvc.yaml
kubectl create -f test.po.yamlCopy
创建完成后在 Longhorn UI 中可以看到刚刚创建出的 Volume:
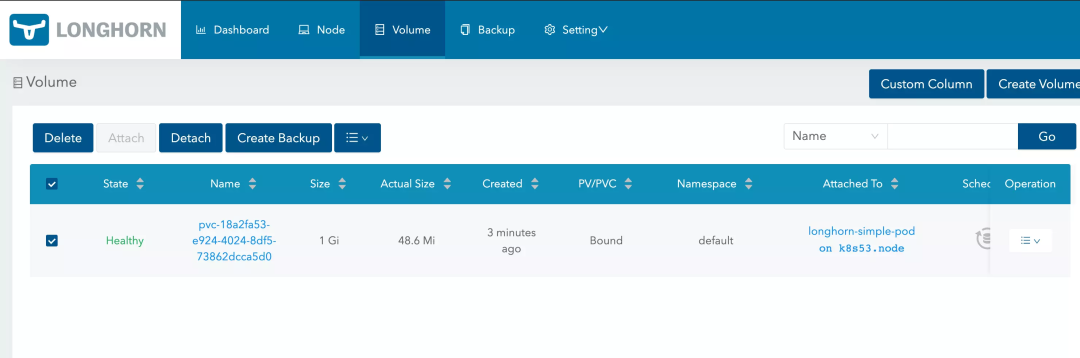
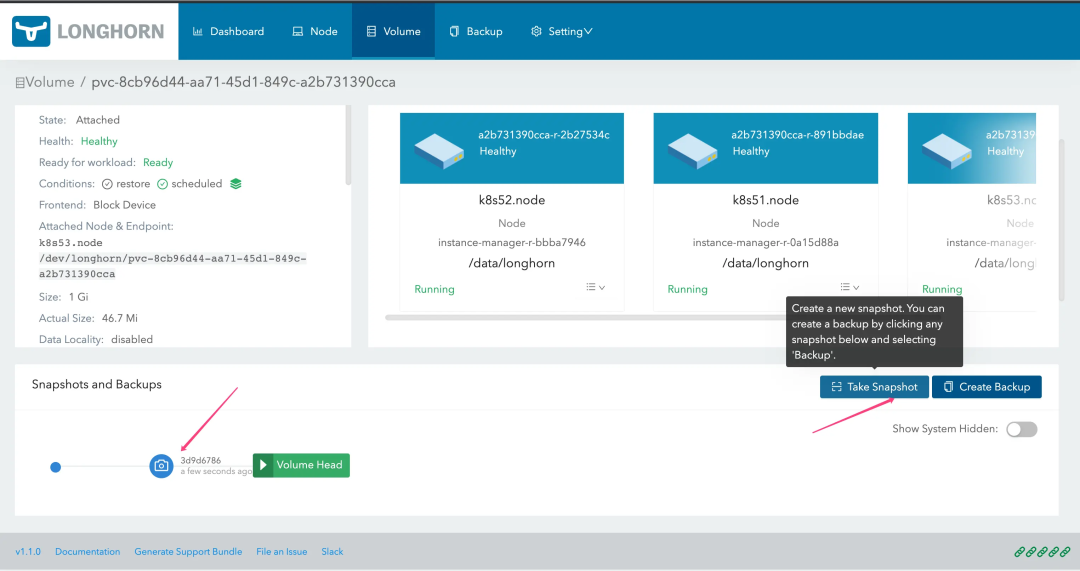
点击 Name 链接进入到 Volume 详情,然后点击 Take Snapshot 按钮即可拍摄快照;有些情况下 UI 响应缓慢可能导致 Take Snapshot 按钮变灰,刷新两次即可恢复。
快照在回滚后仍然可以进行交叉创建
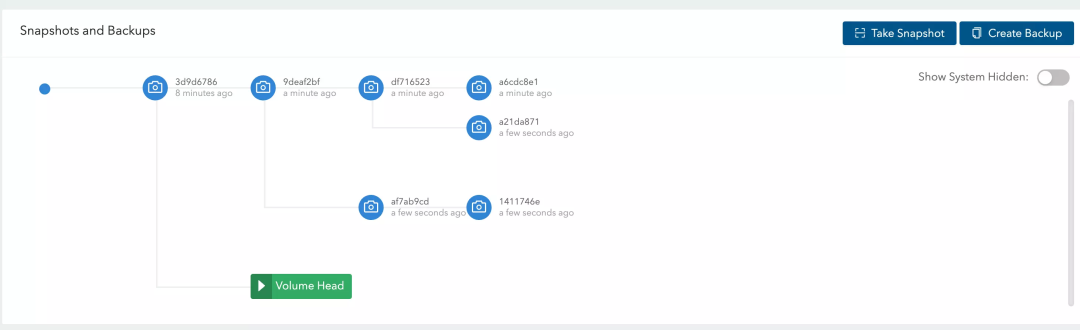
3.3.2、回滚快照
回滚快照时必须停止 Pod:
# 停止
kubectl delete -f test.po.yamlCopy
然后重新将 Volume Attach 到宿主机:
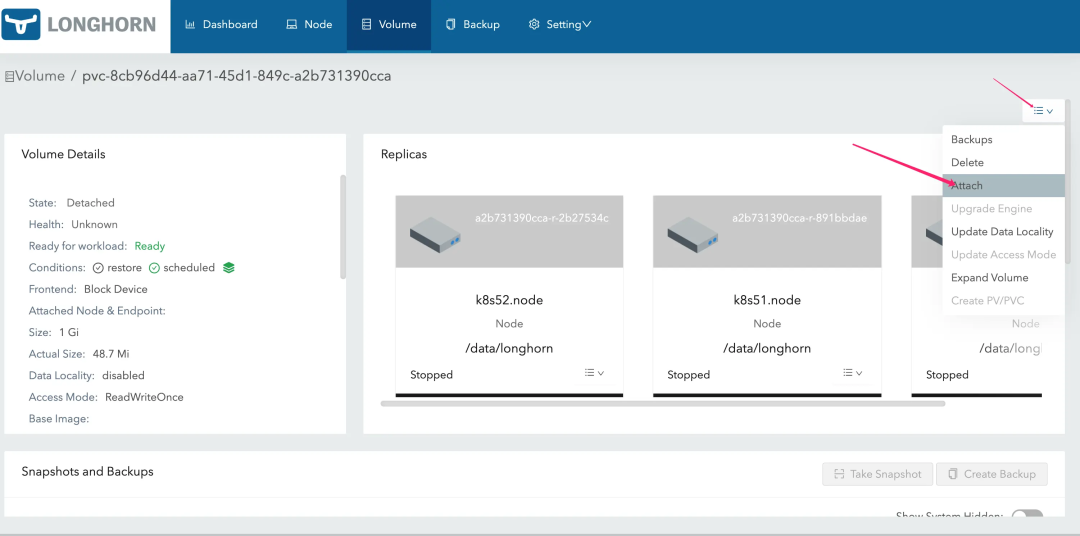
注意要开启维护模式
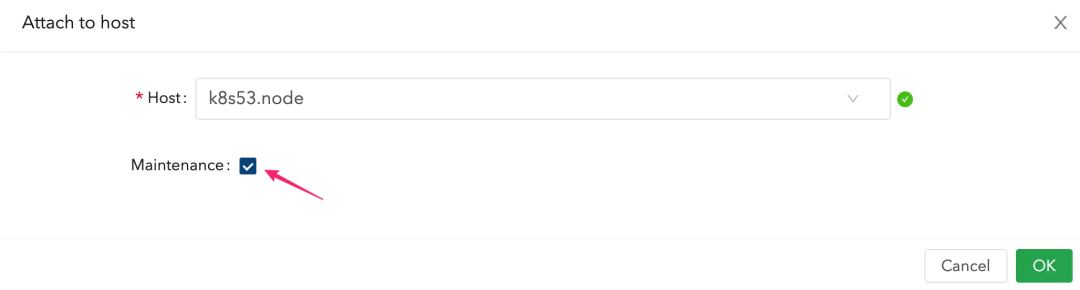
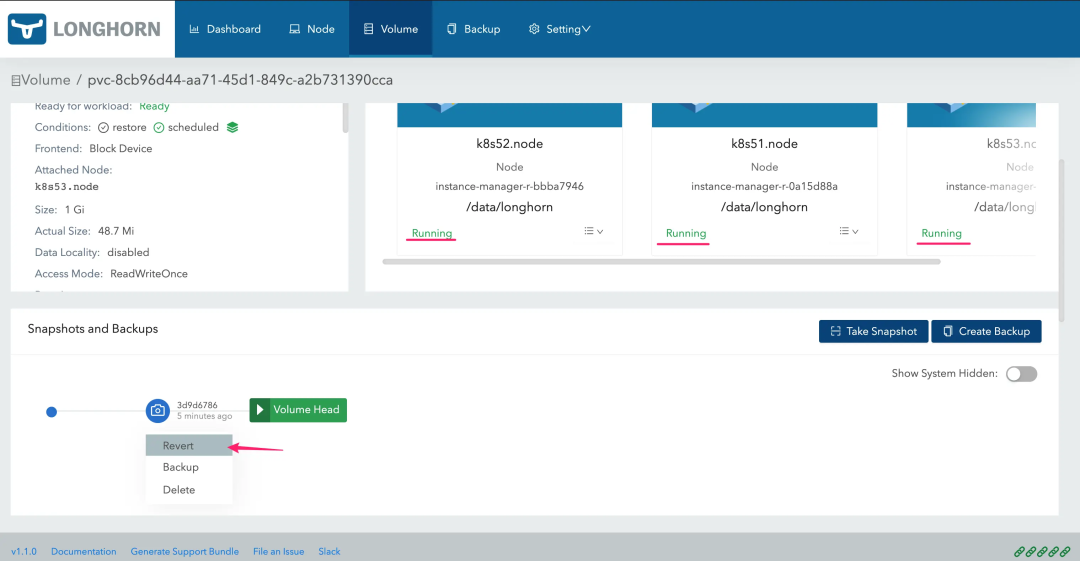
稍等片刻等待所有副本 “Running” 然后 Revert 即可
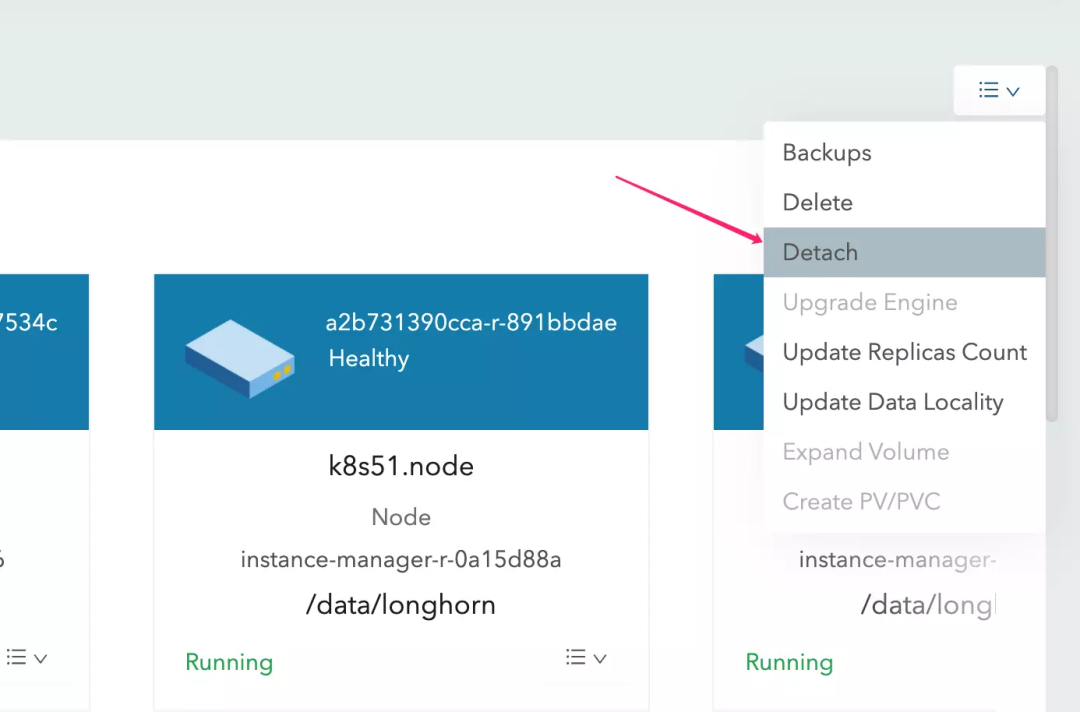
回滚完成后,需要 Detach Volume,以便供重新创建的 Pod 使用
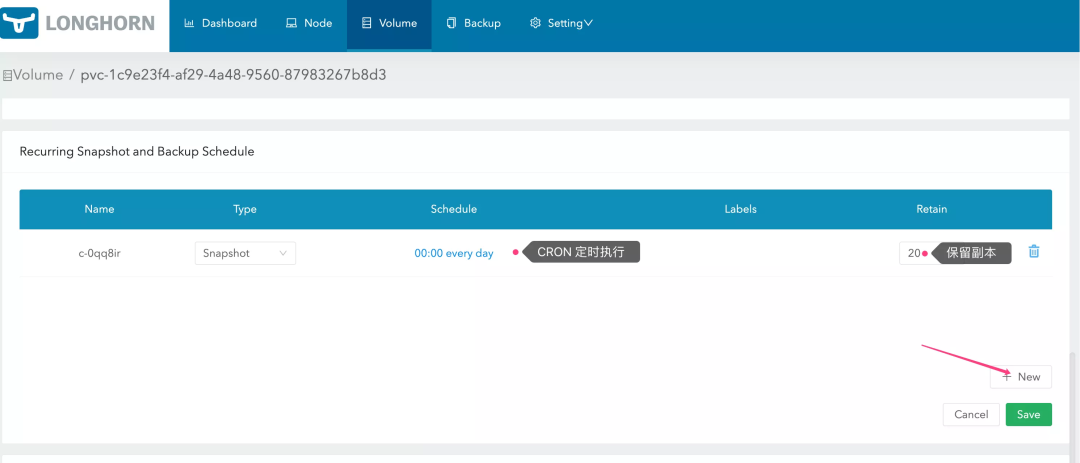
3.3.3、定时快照
除了手动创建快照之外,Longhorn 还支持定时对 Volume 进行快照处理;要使用定时任务,请进入 Volume 详情页面,在 Recurring Snapshot and Backup Schedule 选项卡下新增定时任务即可:
如果不想为内核 Volume 都手动设置自动快照,可以用过调整 StorageClass 来实现为每个自动创建的 PV 进行自动快照,具体请阅读 Set up Recurring Jobs using a StorageClass 文档。
3.4、Volume 扩容
Longhorn 支持对 Volume 进行扩容,扩容方式和回滚快照类似,都需要 Deacth Volume 并开启维护模式。
首先停止 Workload
➜ ~ kubectl exec -it longhorn-simple-pod -- df -h
Filesystem Size Used Available Use% Mounted on
overlay 199.9G 4.7G 195.2G 2% /
tmpfs 64.0M 0 64.0M 0% /dev
tmpfs 7.8G 0 7.8G 0% /sys/fs/cgroup
/dev/longhorn/pvc-1c9e23f4-af29-4a48-9560-87983267b8d3
975.9M 2.5M 957.4M 0% /data
/dev/sda4 60.0G 7.7G 52.2G 13% /etc/hosts
/dev/sda4 60.0G 7.7G 52.2G 13% /dev/termination-log
/dev/sdc1 199.9G 4.7G 195.2G 2% /etc/hostname
/dev/sdc1 199.9G 4.7G 195.2G 2% /etc/resolv.conf
shm 64.0M 0 64.0M 0% /dev/shm
tmpfs 7.8G 12.0K 7.8G 0% /run/secrets/kubernetes.io/serviceaccount
tmpfs 7.8G 0 7.8G 0% /proc/acpi
tmpfs 64.0M 0 64.0M 0% /proc/kcore
tmpfs 64.0M 0 64.0M 0% /proc/keys
tmpfs 64.0M 0 64.0M 0% /proc/timer_list
tmpfs 64.0M 0 64.0M 0% /proc/sched_debug
tmpfs 7.8G 0 7.8G 0% /proc/scsi
tmpfs 7.8G 0 7.8G 0% /sys/firmware
➜ ~ kubectl delete -f test.po.yaml
pod "longhorn-simple-pod" deletedCopy
然后直接使用 kubectl 编辑 PVC,调整 spec.resources.requests.storage
保存后可以从 Longhorn UI 中看到 Volume 在自动 resize

重新创建 Workload 可以看到 Volume 已经扩容成功
➜ ~ kubectl create -f test.po.yaml
pod/longhorn-simple-pod created
➜ ~ kubectl exec -it longhorn-simple-pod -- df -h
Filesystem Size Used Available Use% Mounted on
overlay 199.9G 6.9G 193.0G 3% /
tmpfs 64.0M 0 64.0M 0% /dev
tmpfs 7.8G 0 7.8G 0% /sys/fs/cgroup
/dev/longhorn/pvc-1c9e23f4-af29-4a48-9560-87983267b8d3
4.9G 4.0M 4.9G 0% /data
/dev/sda4 60.0G 7.6G 52.4G 13% /etc/hosts
/dev/sda4 60.0G 7.6G 52.4G 13% /dev/termination-log
/dev/sdc1 199.9G 6.9G 193.0G 3% /etc/hostname
/dev/sdc1 199.9G 6.9G 193.0G 3% /etc/resolv.conf
shm 64.0M 0 64.0M 0% /dev/shm
tmpfs 7.8G 12.0K 7.8G 0% /run/secrets/kubernetes.io/serviceaccount
tmpfs 7.8G 0 7.8G 0% /proc/acpi
tmpfs 64.0M 0 64.0M 0% /proc/kcore
tmpfs 64.0M 0 64.0M 0% /proc/keys
tmpfs 64.0M 0 64.0M 0% /proc/timer_list
tmpfs 64.0M 0 64.0M 0% /proc/sched_debug
tmpfs 7.8G 0 7.8G 0% /proc/scsi
tmpfs 7.8G 0 7.8G 0% /sys/firmwareCopy
Volume 扩展过程中 Longhorn 会自动处理文件系统相关调整,但是并不是百分百会处理,一般 Longhorn 仅在以下情况做自动处理:
扩展后大小大约当前大小(进行扩容) Longhorn Volume 中存在一个 Linux 文件系统 Longhorn Volume 中的 Linux 文件系统为 ext4 或 xfs Longhorn Volume 使用 block device作为 frontend
非这几种情况外,如还原到更小容量的 Snapshot,可能需要手动调整文件系统,具体请参考 Filesystem expansion 章节文档。
四、总结
总体来说目前 Longhorn 是一个比较清量级的存储解决方案,微服务化使其更加可靠,同时官方文档完善社区响应也比较迅速;最主要的是 Longhorn 采用的技术方案不会过于复杂,通过文档以及阅读源码至少可以比较快速的了解其背后实现,而反观一些其他大型存储要么文档不全,要么实现技术复杂,普通用户很难窥视其核心;综合来说在小型存储选择上比较推荐 Longhorn,至于稳定性么,很不负责的说我也不知道,毕竟我也是新手,备份还没折腾呢…
原文链接:https://mritd.com/2021/03/06/longhorn-storage-test/