
如何从大量商品数据里面找到降价商品?
↑ 关注 + 星标 ,每天学Python新技能
后台回复【大礼包】送你Python自学大礼包
相信很多做爬虫的同学都会爬电商网站,每天爬一次,然后监控商品是否降价。如果你只监控一个商品,那么是否降价这非常容易判断,但如果你要找到这个网站里面所有降价的商品,那就非常麻烦了。
如下图所示,是美国电商沃尔玛的全站商品数据:

每个商品每天都会爬一次,一共有 61w+ 条数据。里面有 N 个商品降价了,现在需要把这些降价的商品找出来。
商品有十几万个,如果你分别找到每个商品的 ID,然后用 ID 再找到这个商品每一天的数据,最后看它是否降价,这个工作量非常大,速度也会非常慢。
Pandas 内部使用了 SIMB 技术来对并行计算进行优化,我们需要尽量在不使用 for 循环的情况下,完成这个任务。
为了简单起见,我们假设降价就是指今天比昨天的价格低,不考虑先涨价再降价的情况。
要解决这个问题,我们需要使用 DataFrame 的 pct_change()方法。它就像是reduce一样,给出一系列数据,它会计算数据改变量的百分比——第二条相对于第一条数据的改变,第三条数据相对于第二条数据的改变,第四条数据相对于第三条数据的改变。
首先我们使用date字段对数据进行排序,确保价格是按时间排列的。然后对商品的id进行分组,这样就能拿到每一个商品每天的价格了。然后对price字段使用pct_change():
df2['pct'] = df2.sort_values(['date', 'id']).groupby(['id']).price.pct_change()
运行效果如下图所示:
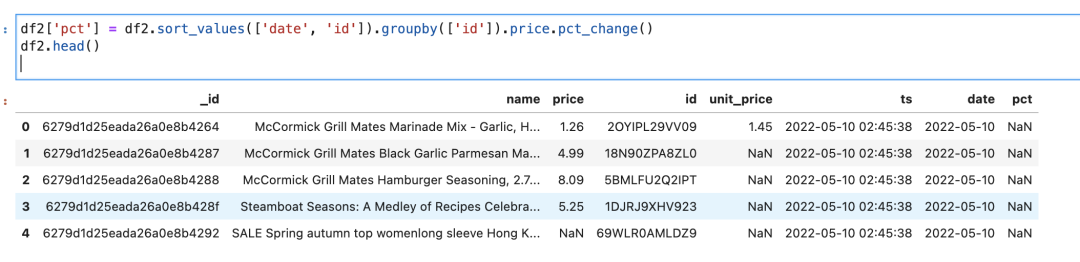
图中最右侧pct字段是 NaN,是因为这是这些商品的第一条数据,所以始终是 NaN.
我们筛选出今天(2022-05-16),pct 小于 0 的商品:
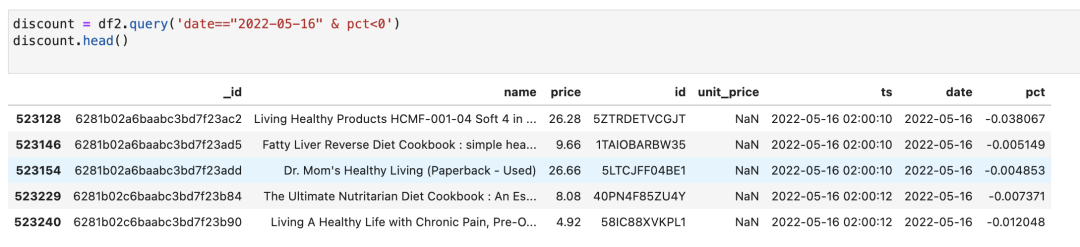
这些就是降价的商品了。我们可以随便筛选一个商品来检查一下:
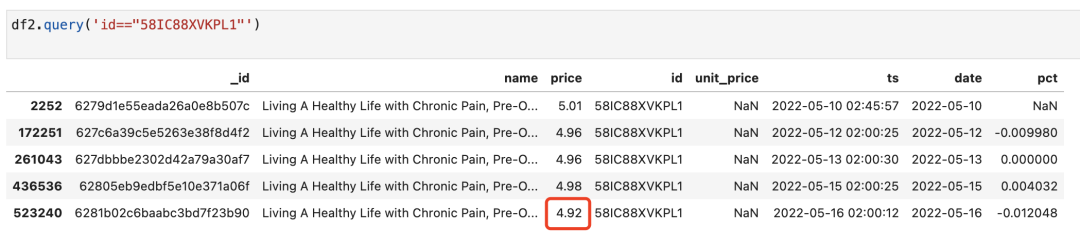
使用pct_change()速度非常快,60w 数据几乎秒出。比 for 循环快多了。


评论