
Paimon 实践 | 幸福里基于 Flink & Paimon 的流式数仓实践
Tips: 点击 「阅读原文」 免费领取 5000CU*小时 Flink 云资源
01
业务背景
幸福里业务是字节旗下关于房产的业务线,围绕这个业务有很多针对 BP 支持的方向,其中最重要的方向之一就是工单系统。工单系统面向的用户是幸福里业务线一线的经纪人和门店经理等。如下图所示,我们可以看下通过工单系统,数据是如何产生和流转的。
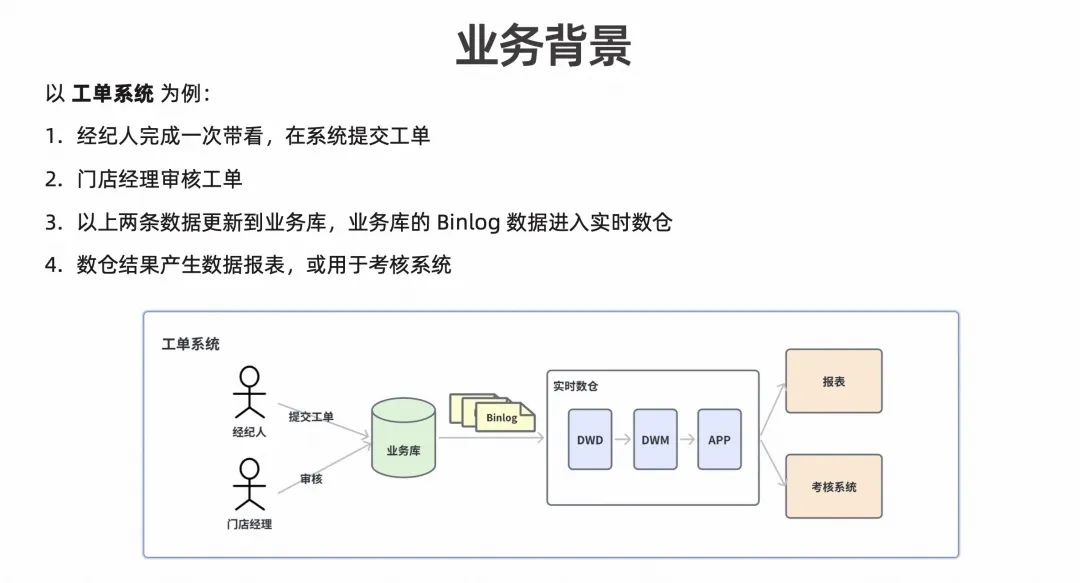
首先由经纪人将已完成的代看任务提交工单,后续相应的门店经理会对该工单进行审核,在这个过程中就产生了两条数据,并将其更新到业务库的 Binlog 数据,作为实时数仓的数据源进行计算后生成数据报表或直接用于一些考核系统。其中数据报表用于展示评估一线经纪人的工作是否达标等;考核系统则用于门店经理为一线经纪人设定考核任务量的工作系统,通过任务量标准自动反馈奖励等。因此在以上应用的实时数仓建模上,我们发现房产类业务有两个典型的特点:
-
准确性要求 100%,不能有数据丢失和重复的情况发生。
- 需要全量计算,增量数据在 MQ 留存时间有限,需要拿到全量数据 View 进行计算。
实时数仓建模特点
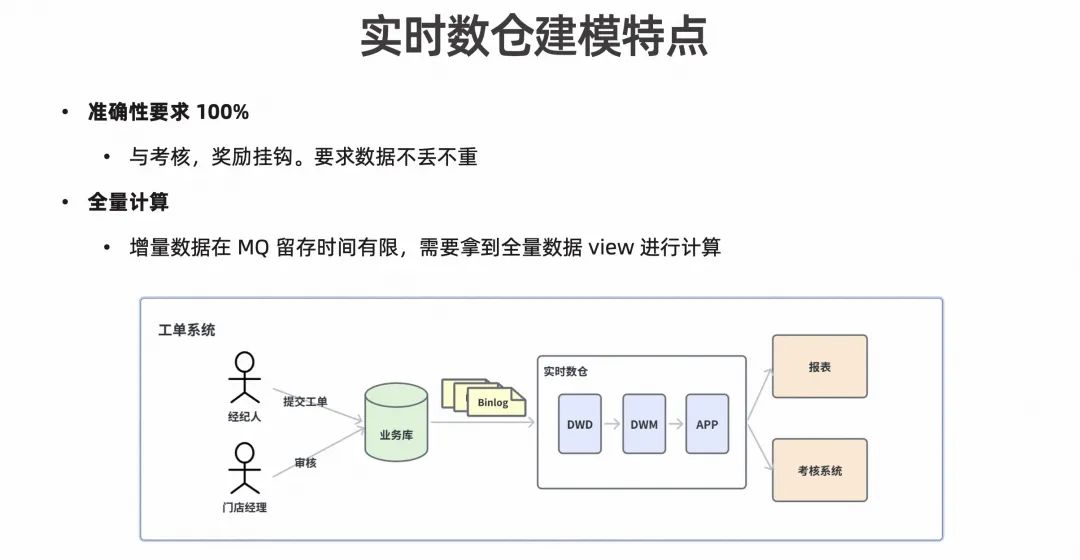
在实际业务的实时数仓 Pipeline 中,进入实时数仓前有多个数据源,每个数据源的特点也都不同,所以实时增量部分会存在 MQ 中,全量数据则是存在 Hive 中。
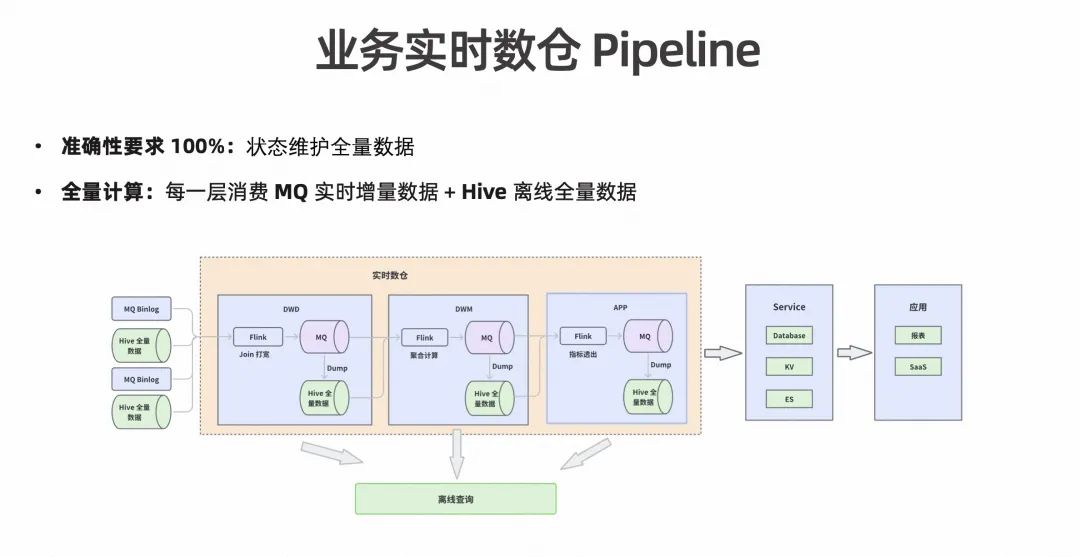
上图实时数仓中的每一层都是由一个 Flink Streaming SQL 串联起来的,DW 层的主要功能是把多个数据源进行 Join 打宽,通过计算出来的宽表实现直接输出进 MQ 中。由于 MQ 的留存时间有限会形成一个小时级或天级的周期性任务,在一个周期结束后 MQ 中的数据最终会落到 Hive 里。DWM 这一层主要的作用是聚合计算,聚合计算的结果也会直接输出到 MQ 中。每一层的计算模式都和上一层相同,实时数仓的计算结果会通过 Service 层服务于在线的数据应用,比如上面提到的数据报表和考核系统。每层输出的 Hive 离线数据可以用于 BP 同学做数据排查/验证等离线查询工作。
回顾实时数仓的两个特点,一是准确性要求 100%,也就是说要求整个数仓的实时任务状态算子都要维护全量数据;二是需要全量计算,是指由于异构存储,实时数据存在 MQ,历史数据存在 Hive,那么就使得每层消费的 MQ 都需要实时消费增量数据和 Hive 全量数据。从开发工程师的视角这套实时数仓模型存在如下痛点:

在开发过程中需要时刻关注业务逻辑之外的逻辑,比如在 SQL 中对数据的重复处理;在数据去重过程中,使用单一字段处理不够精准,需要引入 Nanotime 做非确定性计算来解决问题等。之所以存在以上问题,主要是因为在整个链路中,实时数据和离线数据是分开存储的,这种存储异构使得两部分的数据天然很难对齐。
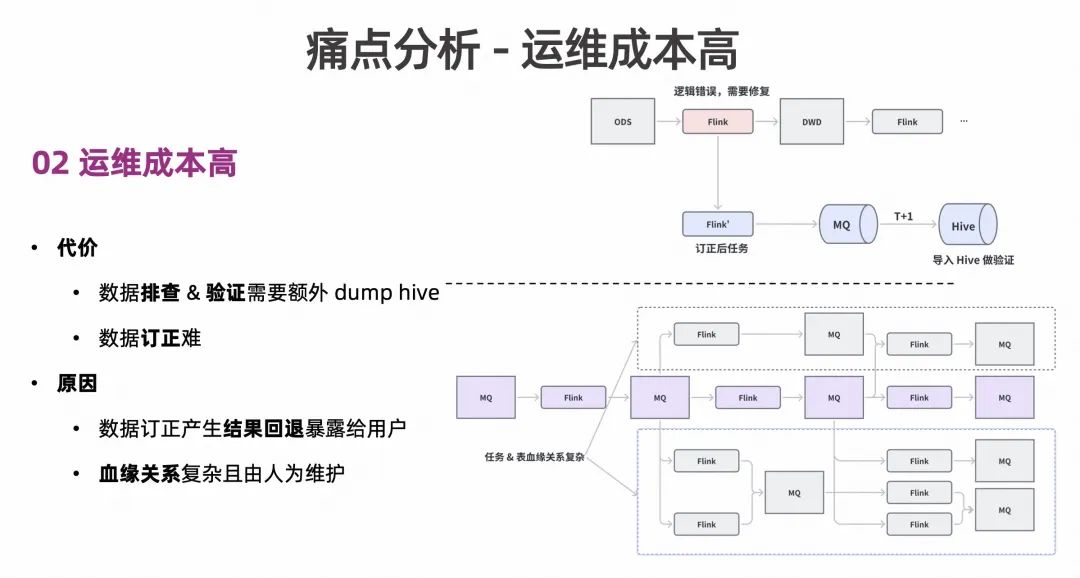
这里的数据运维包含三个部分:数据排查、数据验证和数据订正。存在的问题是,在数据排查和数据验证的过程中,如果发现某条链路上的某个 SQL 作业需要订正。订正完成的 SQL 的结果输出到 MQ 中,需要再将 MQ 中的数据落盘到存储中的操作会产生 T+1 的代价。另外在订正过程中的中间结果回退会直接暴露给用户。
第二个问题是如上图紫色部分是一个简化的链路,而在实际生产过程中的复杂度很高,体现在主链路上的是一些表和任务会被其他很多任务或表依赖,使得订正过程会影响到很多不可预知的表或任务。造成以上问题的原因,主要有两点,一个是数据订正产生结果回退暴露给用户,另外则是血缘关系复杂且需要人为维护。
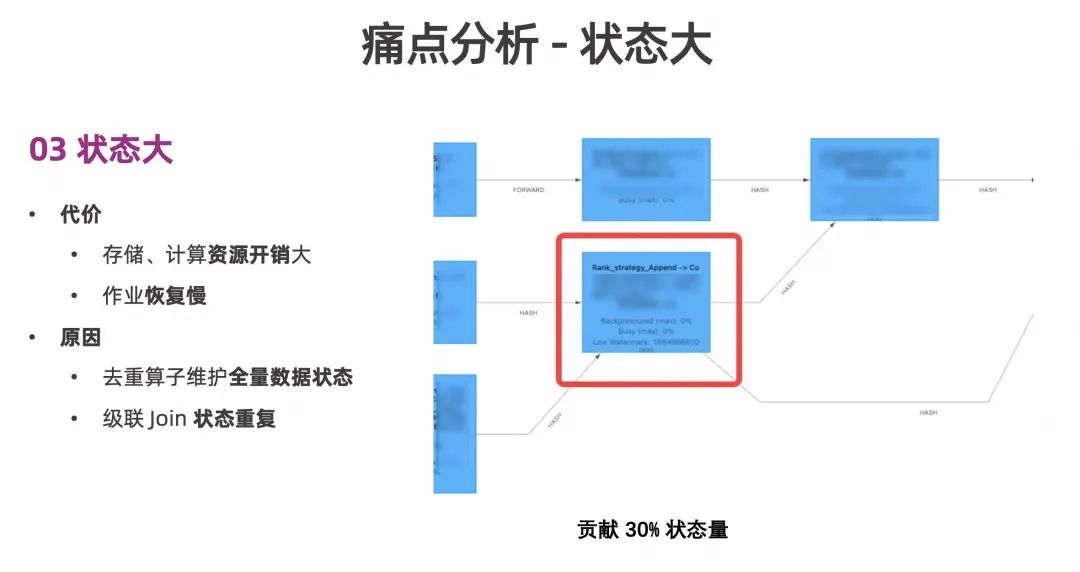
在当前的这条链路上,Flink 实时任务的状态维护是非常大的,这就造成存储和计算资源的消耗非常大,从这么大的状态中恢复作业的过程也会很慢。产生状态大问题的两大原因主要是去重算子维护全量数据状态和级联 Join 状态重复。
为什么选择 Paimon
基于以上存在的痛点,我们考虑希望通过 Flink 生态搭建 Steaming Lakehouse 的组合来解决原始链路上的问题,如上图所示,原始链路存在的问题有:
-
存储异构,Base+Delta 数据难对齐;
-
去重引入非确定性计算和大状态;
- 血缘关系复杂 & 数据订正结果回退暴露给用户。
对应解决原始链路的问题,我们选择了 Paimon:
-
流批一体的存储可以以统一 Table 对外输出,实时和离线数据可以存储到一张 Paimon 表中,直接解决了对齐的问题;
-
不需要去重,Changelog Producer 代替状态算子,同时支持在存储上产生完整的 Log,并将其持久化代替原有链路上的状态算子;
- 血缘管理 & 数据一致性管理,支持无感知数据订正。
02
流式数仓实践
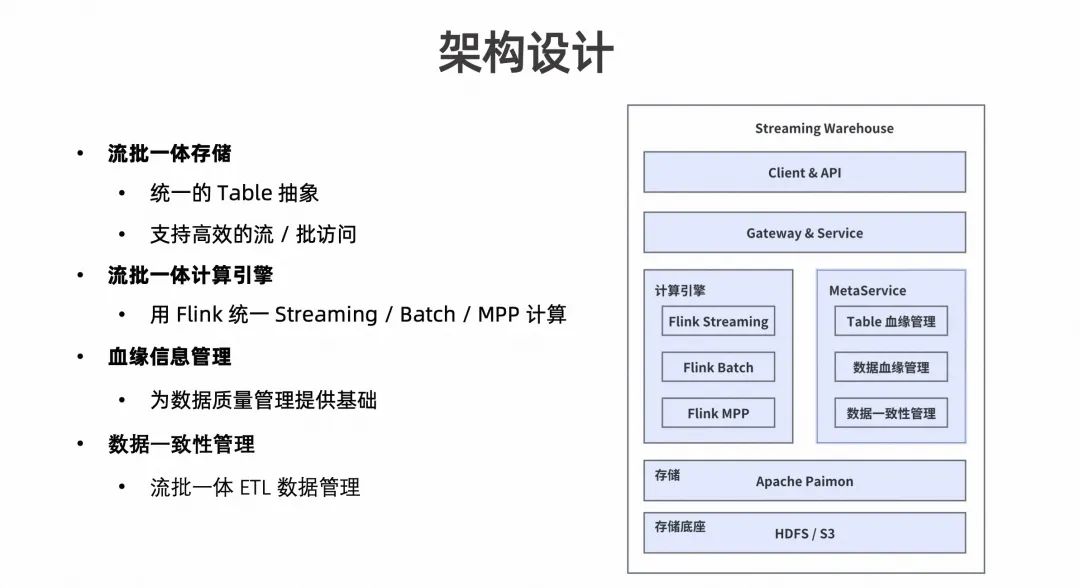
首先介绍流式数仓实践过程中的架构设计,如下图所示:
-
存储层选用了 HDFS 或 S3 的对象存储作为存储底座,选用 Paimon 作为统一的 Table 抽象;
-
计算层选用 Flink 同一的技术栈,统一了流批计算;
-
数据管理层实现了 Table 的血缘管理和数据的血缘管理,基于这样的血缘管理可以做到数据一致性,血缘管理可以用于数据溯源的需求,为数据质量提供保障。
- 数据一致性管理,流批一体 ETL 数据管理。在多表一致性联调的时候,可以自动对齐数据,不需要开发人员手动对齐。
如上图可见上层通过 Gateway 或 Service 层对外提供服务,最终用户通过 SQL Client 或是 Rest API 访问整个系统。
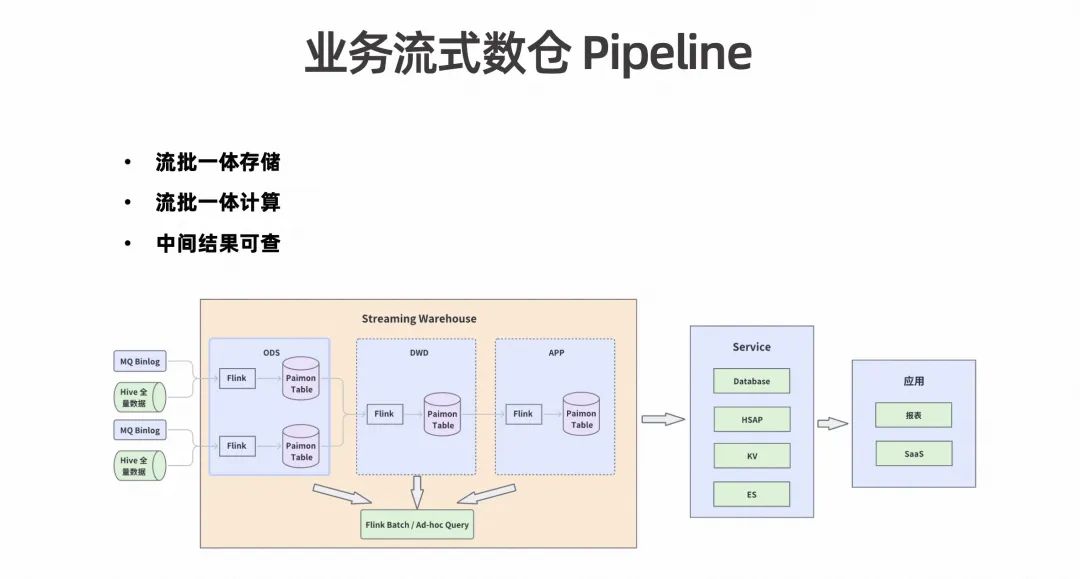
上图是流式数仓 Pipeline。数据源和前面提到的一样,离线数据存在 Hive 中,实时数据存在 MQ 中。不同的是在进入 Streaming Lakehouse 的时候,设置了一个 ODS 层,这层会通过 Flink Streaming SQL 把每一个数据源沉淀到 Paimon Table 里。第二层是 DWD 层,通过对多个数据源进行 Join 打宽的操作,将输出的结果沉淀到 Paimon Table 里。再通过最后一层 APP 层做指标聚合以及透出的工作。
由于中间数据都沉淀在 Paimon Table 中,所以开发人员在做数据排查和验证的时候可以直接操作。通过上图实时数仓的 Pipeline 可以看到存储上是流批一体的,在计算上也是用 Flink 的技术栈统一了流批计算,这样可以减少开发和运维的成本。而且中间数据沉淀也是可直接查询的,不需要在运维的时候做更多繁琐的操作。

在完成上述 Streaming Lakehouse 实践落地后总结了如下收益:
-
简化开发流程
-
流批一体存储可以解决实时和离线存储异构的问题;
-
减少业务入侵,移除去重算子,解决非确定性计算。
-
-
提升运维体验
-
中间数据可查;数据可追溯;
-
血缘关系 & 多表一致性,增强了多表关联调试能力,并且可以做到数据订正无感知。
-
-
减少状态量
- Changelog 持久化,可以减少30%的状态量。
在实践过程中,除了获得了不少收益,也同样遇到了新的问题,主要包括两个:
- 数据新鲜度差:端到端的延迟变化为分钟级,数据新鲜度降低;
-
小文件问题:一些小文件可能会影响读写性能。
03
流式数仓的调优
端到端延迟调优
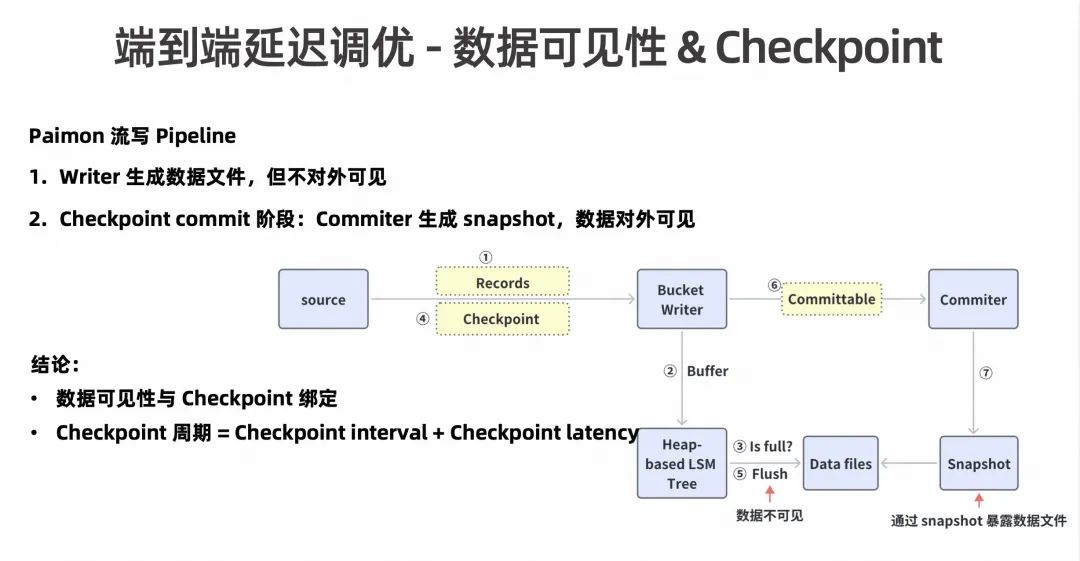
首先要分析下整个链路数据的可见性与什么相关。如上图所示,Source 在收到数据之后,会把这些 Records 源源不断的发给 Bucket,然后 Bucket Writer 在收到数据后,先把这些数据缓存到一个基于内存的 Buffer,存满之后会触发一个 Flash 将这个 Buffer 里的数据全部都 Flash 到磁盘上。这个时候就生成了对外不可见的数据文件,只有当上游触发了一个 Checkpoint 的时候,整个链路中 Commit 算子生成一个 Snapshot 指向刚生成的数据文件才能对外可见。
分析整个流程,可以得出两个结论:
-
数据可见性与 Checkpoint 绑定。更严格的说是一个周期的数据可见性与 Checkpoint 周期严格绑定。
- Checkpoint 周期 = Checkpoint interval + Checkpoint latency。Checkpoint interval 是 Checkpoint 触发的频率;Checkpoint latency 是整个完成一个 Checkpoint 所需的耗时。
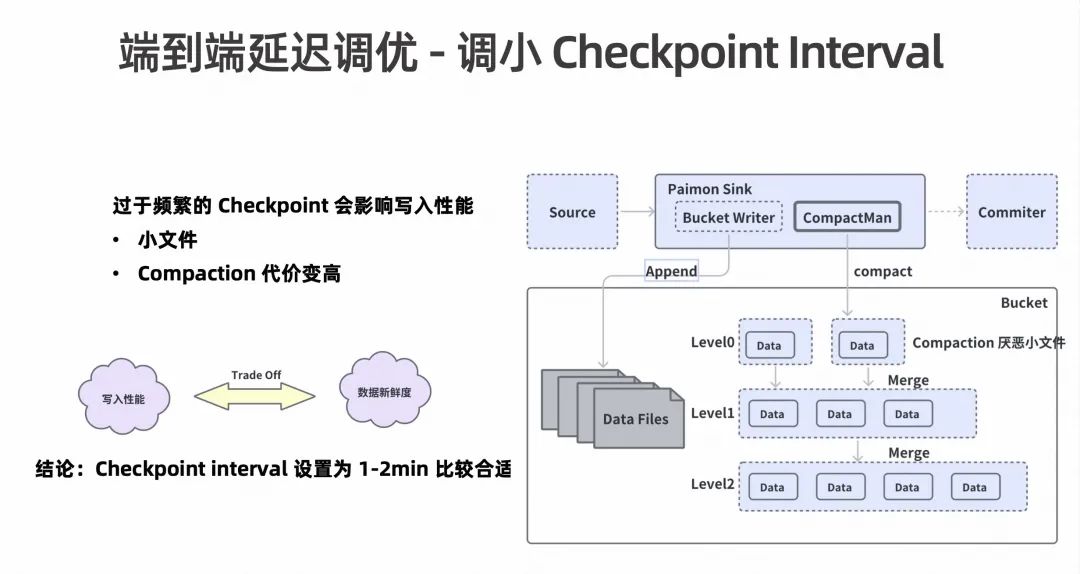
因此在我们在做端到端调优的时候,是否只需要针对 Checkpoint 周期做相关调整就可以呢?最简单的是不是将 Checkpoint interval 进行调小操作呢?
在得出结论前我们先来看下写入流程。在 Paimon Sink 算子中,Bucket Writer 会源源不断的把数据开放到磁盘的数据文件里,另外 Paimon Sink 还包含另外一个组件 Compact Manager。这个组件主要是针对磁盘上的数据文件不断的做 Compaction。如上图右侧展示,Compaction 在逻辑上是个 Bucket,在存储上是一个目录,目录下会存放很多数据文件,这些文件是由 LSM 树组织的,分为多个 Level。实际上 Compact Manager 在做 Compaction 的时候就是针对这些不同层的数据做的过程。
所以我们推断,整个 Compaction 过程是一个 I/O 比较多的操作过程,假设一味的调小 Checkpoint Interval,会导致频繁的 Checkpoint,比如原来 100 条数据本来是能分一个文件里的,但是现在 Checkpoint 频率过高后,这 100 条数据可能会被分到多个文件里,那么每个文件里面的数据都会很小。其次,小文件过多,会让 Compaction 的整体代价变得更高,也会影响写入的性能。其实这就是一个追求数据新鲜度的过程,主要需要在数据的写入性能和数据新鲜度上做权衡。在经过多方实践验证后,推荐将 Checkpoint Interval 设置为 1-2 分钟为优。
Checkpoint Latency 优化可以分为几个方向进行:
-
Log-Based 增量 Checkpoint
利用 Flink 高版本的一些特性,如 Log-based 增量 Checkpoint 的方式去优化上传阶段的耗时。
减少状态量
比如减少上传输数据量,那么上传耗时就会减少。
-
Checkpoint 持续上传
持续上传本地状态文件。
-
搭建独立 HDFS 集群

小文件优化
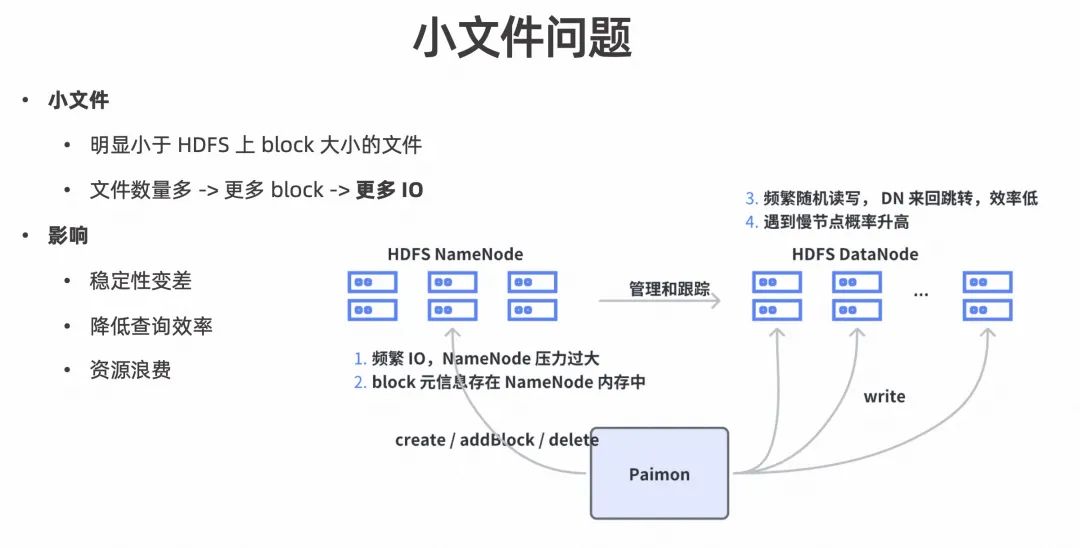
字节内部的实践是基于 HDFS 为存储底座的,我们将小文件定义为明显小于 HDFS 上一个 Block 大小的文件。小文件引出最直接的问题就是文件数量太多导致需要更多的 Block,比如 Create Block,Delete Block等,直接的影响就是 I/O 操作频繁,会导致 HDFS 上的 NamaNode 压力过大对稳定性产生影响;另外,无论文件本身有多大,它的 Block 的元信息是固定的,而这些元信息都是存在 NameNode 内存里的,过多的 Block 元信息会造成内存 OOM 问题;当数据太分散/文件数量太多时,数据就有可能被分配到更多的 HDFS 的 DataNode 里,就会造成 DataNode 的来回跳转,增加频繁的随机读写,使效率和性能变低;并且分配的 DataNode 变多遇到慢节点的概率也会变大。
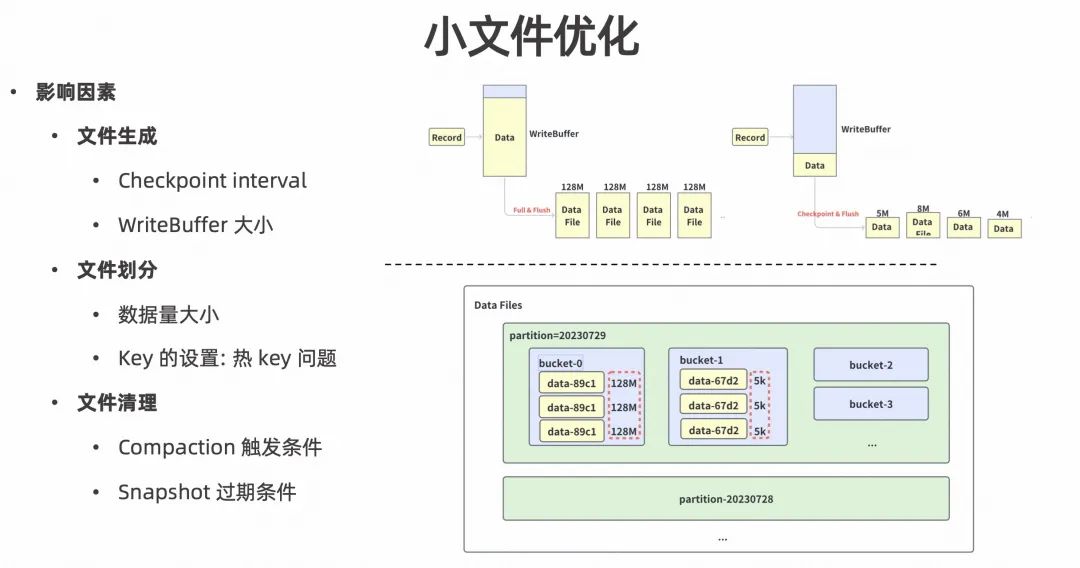
在小文件相关的问题中,决定是否产生小文件的时机和因素有以下几点:
-
文件生成。数据文件在磁盘上生成是有两个触发时机的,一个是 Checkpoint 的时候,它会强制把当前的 WriteBuffer 里的数据刷到磁盘上;第二个是 WriteBuffer,当它满了也会把内存里面的数据刷到磁盘上。如果把 Checkpoint Interval 调的过小,或是把 WriteBuffer 容量设置的比较小,那么数据就会更频繁的被刷到磁盘上,而产生过量的小文件。
-
文件划分。通过设置一些 Partition key 或 Bucket key,就决定了数据的走向,它会落在哪些文件里。比如,生产中实际数量非常小,同时又设置了过多的 Bucket,那么可以预见,一个 Bucket 可以分到的数据量一定会比较小。这个过程中也会遇到小文件问题。另外,如果设置 Partition key 或 Bucket key 不合理,可能会产生一些文件倾斜的情况,即热 Key 问题。
- 文件清理。Paimon 具有文件清理机制,在 Compaction 过程中会删除一些无用的文件。另外,数据由 Snapshot 管理,如果 Snapshot 过期,就会从磁盘上删除对应的数据文件。如果 Compaction 触发条件和 Snapshot 过期条件没有管理好,也会造成冗余的文件留在磁盘上。
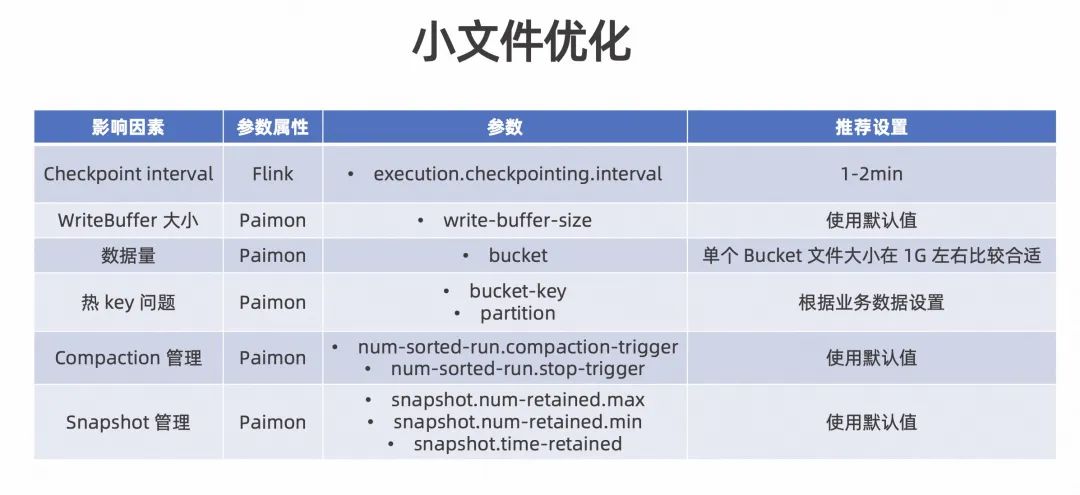
基于以上的介绍,分享一下我们在实践过程中积累的一些小文件调优参数,见下表所示。
-
Checkpoint interval::推荐在 1-2 min 比较合适;
-
WriteBuffer 大小:推荐使用默认值,除非遇到相关问题需要调整;
-
业务数据量:可以根据业务数据量调节 Bucket 数,调整依据为单个 Bucket 大小在 1G 左右比较合适;
-
Key 的设置:可以根据实际的业务 Key 特点设置合适的 Bucket-key、Partition,以防产生热 Key 倾斜的问题;
- Compaction 管理和 Snapshot 管理相关参数:推荐使用默认值,除非遇到相关问题需要调整。
经历了整个架构改造之后,我们将原有实时数仓链路做了对比,如下图可见,在很多指标上都获得了一定的收益。
-
端到端延迟:在原始实时数仓开启 Mini-batch 的情况下,端到端延迟没有明显退化,可以支持 1-2 min 的近实时可见;
-
数据排查时效性:可以从小时级提升到分钟级;
-
状态量节省了约 30%;
- 开发周期缩短约 50%。

04
未来规划
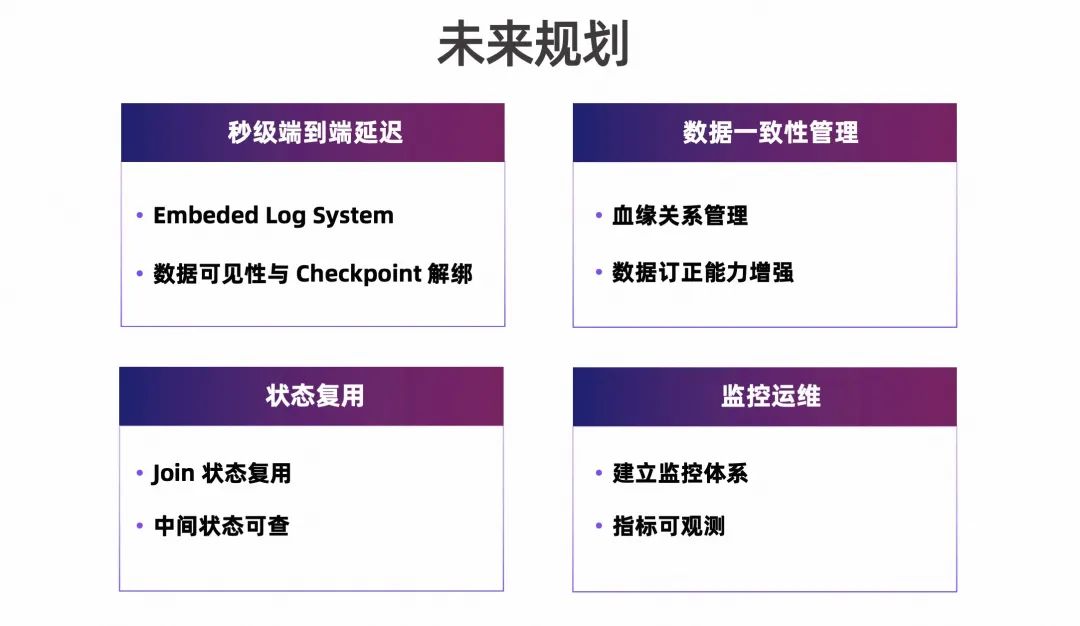
当前主要规划了以下四个方向:
- 首先,秒级端到端延迟的尝试。可能会分几期来做,计划引入 Embeded Log System 来解决这个问题。长期来看,会把数据可见性与 Checkpoint 解绑;
- 其次,数据一致性管理。血缘关系管理和数据一致性管理这两个方面,在实际数据运维中是很有价值的;
- 第三,状态复用。状态复用主要是解决 Join 状态复用的问题。另外,我们希望可以做到中间状态可查;
- 第四,监控运维。未来当规模上去,希望可以建立监控体系,并做到指标可观测。
Q&A
Q:请问在数据源异构的情况下,是否考虑过其他入湖的技术选型?为何最终选择了 Paimon?
A:在最初技术选型的时候,主要考虑几个点,一个是跟 Flink 生态的结合,一个是 Streaming Warehouse 这种模型,当时与这两点结合最好的是 Paimon,另外在我们 Steaming upsert 的主流场景下情况更优。 另外,对于中间存储层,是 Plugin 的模式,不是说一定要和 Paimon 做很深的绑定。Q:请问在做数据回溯、快照和回滚的时候,有做过哪些考虑?能够给一些可供参考的建议? A:在这个方面我们主要是基于 Paimon 做了血缘管理的功能。血缘关系管理简单来讲分为两个部分:第一部分是表的血缘关系管理;第二部分是数据的血缘关系管理。 表的血缘关系管理,比如在提交作业的时候,通过任务可以提取出它上下游表的信息,然后插入到引入的 System Database 里。数据血缘关系管理,可以根据 Checkpoint 去划分数据版本,一个 Checkpoint 完成之后就意味着一个版本数据的产生。然后再把具体消费了哪个版本的数据,记录到 System Database 里。 基于这两种血缘关系管理,既可以保持旧链路在线服务的状态,也能保障新链路回溯数据或订正数据成为可能。在生产环境中,由系统层面把表自动切换,就可以完成一次数据回溯。
Q:请问用流本身去处理数据,如果数据量过大,是否会造成获取数据源开口的环节拥堵,以至于数据进不来? A:这是一个写入性能优化的问题,在 Paimon 官网上有专门针对这块的详细指导,大家可以去了解下。
活动视频回顾 & PPT 获取
PC 端
建议前往 Apache Flink 学习网:
https://flink-learning.org.cn/activity/detail/69d2ec07bc2f664d000a954f49ed33aa移动端
视频回顾/PPT 下载 :关注 Apache Flink 公众号/ Apache Paimon 公众号,回复 0729
想要了解如何 使用 Flink 在 GitHub 中发现最热门的项目 吗?本实验使用阿里云实时计算 Flink 版内置的 GitHub 公开事件数据集,通过 Flink SQL 实时探索分析 Github 公开数据集中隐藏的彩蛋!
- 了解 Flink 和流式计算的优势
-
对 Flink SQL 基础能力和 Flink 实时处理特性有初步体验
实验详情: 如何使用 Flink SQL 探索 GitHub 数据集|Flink-Learning 实战营
Flink Forward Asia 2023 正式启动
▼ 「 活动推荐 」首购 99 元包月试用 ▼
▼ 关注「 Apache Flink 」,获取更多技术干货 ▼
 点击「阅 读原文 」,免费领取 5000CU*小时 Flink 云资源
点击「阅 读原文 」,免费领取 5000CU*小时 Flink 云资源