
文字识别:一文读懂 Transformer OCR
共 4595字,需浏览 10分钟
·
2022-02-09 17:36
深度学习时代的文字识别:行识别,主流有两种算法,一种是CRNN 算法,一种是attention 算法。
CRNN:CNN+RNN+CTC
白裳:一文读懂CRNN+CTC文字识别attention :CNN+Seq2Seq+Attention
白裳:完全解析RNN, Seq2Seq, Attention注意力机制两种算法都比较成熟,互联网上也有很多讲解的文章。
Attention Is All You Need (Transformer)这篇文章,设计了一种新型self-attention结构,取代了 RNN(LSTM\GRU) 的结构,在众多nlp相关任务上取得了效果上的突破,而后来的BERT、GPT等模型亦是来源于这篇文章。有关Transformer 的讲解也有很多。
大师兄:详解Transformer (Attention Is All You Need)OCR行识别本身也是seq2seq的序列识别问题,这里讲下如何利用transformer结构进行OCR识别,本文介绍的Transformer OCR 基于以下代码
https://github.com/saberSabersaber/transformer_OCR目前仅支持宽、高固定的定长识别(高度固定,宽度需要padding到最大长度),以下假设输入图像高度固定为32, 最大宽度为100。
Transformer OCR 模型结构,核心分为两个部分:backbone + transfromer
- Backbone:
backbone一般是由卷积层+pooling层堆叠而成, 这里以crnn 中 VGG_FeatureExtractor 为例,一共是经过4次pooling层,其中 2 个2*2 pooling ,2个 2 * 1 的pooling,经过backbone之后输出为512*2*25(其中512是channel数),为了将高度pooling 到1 ,最后又额外利用卷积操作将图像变为512*1*24。(并不必要,因为后面会接一个AdaptiveAvgPool2d 层,以保证不同backbone提取到的特征高度均为1)。
2. Transformer:
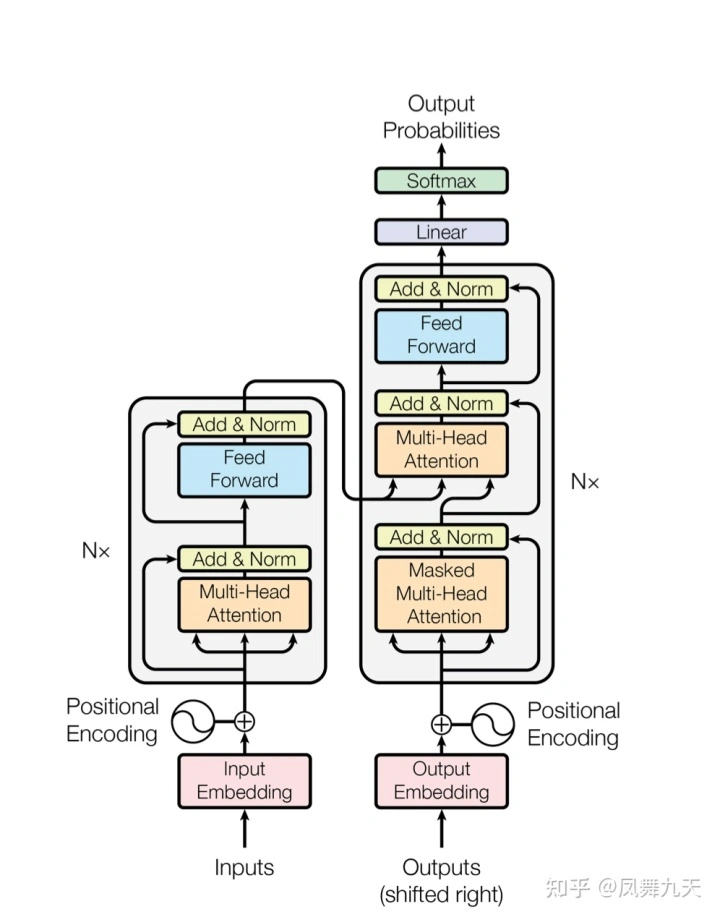
transformer 主要有两个结构,encoder 和 decoder.
2.1 Encoder:
encoder 结构由多个MultiHeadAttentionLayer 和 PositionwiseFeedforwardLayer 堆叠而成的block组成。其输入为经过backbone之后提取的特征,这里记为 ,为了保证transformer 输入的时序性,transformer 额外计算了位置编码(pos_embedding),这里记为 ,那么 encoder内部输入给MultiHeadAttentionLayer 的输入可以表示为: 。encoder 第一个block(MultiHeadAttentionLayer + PositionwiseFeedforwardLayer)输入是有图像特征和位置编码得到的 ,后面block 的输入为上一个block 的输出。
Self-attention
Self-attention 是 transformer 的核心结构,在这里数据首先会经过一个叫做self-attention的模块得到一个加权之后的特征向量 ,这个 便是论文公式1中的 :
在encoder 中, 全部来自于输入 :
其中 是模型参数。Self-attention 可以看到是将输入经过三个不同的线性映射得到三个中间变量 ,然后利用矩阵乘法来模拟RNN 的时序计算。RNN,包括LSTM、GRU的一个问题是随着时间步的变长,时序依赖性会减弱,即 和 ,在 比较小的时候互相之间依赖较强,当 越来越大时,两个时刻之间的联系也会越来越弱。但是在矩阵乘法中,每一列也可以认为是一个时间步,而任意两列在矩阵乘法中距离是一样的,都会得到计算,故而对于序列识别来说,transformer打破了时序长时依赖的障碍。但是,由于矩阵乘法是无序的,而OCR识别输入的图像是有序的,所以需要通过位置编码来弥补。
MultiHeadAttentionLayer
Multi-Head Attention,其实是多个self-attention的集成,这里采用多个self-attention能够丰富特征,代买设置的参数为 。Multi-Head Attention的输出分成3步:
- 将输入 分别输入到8个self-attention中,得到8个加权后的特征矩阵 ,将这8个输出矩阵直接拼成一个大的特征矩阵,最后再利用一层全连接后得到输出 。
PositionwiseFeedforward
这个全连接有两层,第一层的激活函数是ReLU,第二层是一个线性激活函数,可以表示为:
图像特征 经过encoder之后得到的特征记为 。
2.2 Decoder
Decoder 结构和encoder 稍有不同,是由 MASK MultiHeadAttentionLayer 、encoder-decoder MultiHeadAttentionLayer 和 PositionwiseFeedforwardLayer 三部分组成的多个block 堆叠而成。
Decoder 的输入由两部分组成,其中之一是encoder 输出 ,另外一个输入是target, 由label 得到,而MASK MultiHeadAttentionLayer 结构输入就是target。
MASK MultiHeadAttentionLayer
这里首先要讲一下target 的生成方式,以下图为例,其真实label为London,在计算loss 时,会在字符串最后补一个终止符[end], 由于是batch 训练,多个样本的label长度不同,这里也采用pading 的方式对齐到max_len,即label为London[end][pad][pad]....,而target 为[begin]London[end][pad]...., 即在label 前插入一个起始符,[begin] 和 [end] 用途稍后会说。


MASK MultiHeadAttentionLayer 与 MASK MultiHeadAttentionLayer 区别在于mask,而利用mask 的原因是在序列运算的时候,后面的字符可以看到前面的字符,但是前面的字符看不到后面的字符,比如,当预测o的时候,L是已经预测出来的,可以用于输入,但是o、n都不能用于输入,所以要生成三角矩阵来进行mask。操作起来也比较简单,就是在公示(1)中 得到的矩阵对应位置上填充-inf即可。其余地方和 MultiHeadAttentionLayer 一致。将target 经过MASK MultiHeadAttentionLayer 之后得到的特征记为 。
encoder-decoder MultiHeadAttentionLayer
encoder-decoder MultiHeadAttentionLayer 运算过程和MultiHeadAttentionLayer 也是一样的,只不过这里的 来自于 , 而 来自于 , 其余部分与MultiHeadAttentionLayer 完全相同。其意思为每个时刻输入一个query,通过query,key,和 value的矩阵乘法得到当前时刻的输出。target在最开始的时候插入[begin]就是为了输入的query 领先于需要预测的label,即query为[begin],预测得到L,query为L, 预测得到o。最后的PositionwiseFeedforwardLayer 与encoder中相同。
Tips:
最后针对一些常见的问题,给出一些解释:
1)label 为何要在最后添加[end] 符号?
这是因为在测试的时候我们不知道最终结果的长度,比如London这个单词,当预测到字符n的时候,程序并不会终止,会继续预测,添加终止符号的情况下,模型会学到预测到[end],这时候可以终止预测,或者通过简单的后处理提取[end]之前有效字符。
2)target 为何在最开始添加[begin] 符号?
这个和attention OCR 中类似,只不过在运算中由于都是矩阵运算体现的不明显(在代码中测试的时候采用的是循环的方式,这种方式更容易理解)
从decoder 输入可以看到,decoder 同时输入了图像和label(target 是在lable 最开始插入了[begin]符号),但是实际情况我们是没有label的,只有图像,仍然以London 为例,当预测第一个字符的L的时候,如果不补[begin]会发生什么?模型能看到整张图像的特征以及label第一个字符L 提取的特征,当预测o的时候,模型能看到整张图像的特征以及label 前两个符号Lo的特征,这样显然是有问题的。接下来在label 最开始的位置插入一个[begin] 符号,那么当预测第一个字符的L的时候, 模型能看到整张图像的特征以及[begin]的特征,当预测o的时候,模型能看到整张图像的特征以及label 前两个符号[begin][L] 的特征,在训练的时候 L 来自label,当预测的时候,L 是前一次预测的结果。
3)encoder-decoder MultiHeadAttentionLayer 需不需要用mask?
在encoder-decoder MultiHeadAttentionLayer 中计算是不需要计算mask的,这是因为这个模块的输入是MASK MultiHeadAttentionLayer的输出,这里的输出已经保证了 时刻的特征看不到 时刻的特征。
4)transformer VS RNN(LSTM、GRU)有哪些优势?为什么要用位置编码?
这里把两个问题放在一起,之前也简单提过,不过这里只是个人理解,不保证个人理解一定正确。
RNN 是利用隐含层h记录之前时刻的状态,LSTM、GRU 通过记录更多的额外状态以期保留时间跨度更长的信息,但都不可避免的是, 和 ,在 比较小的时候互相之间依赖较强,当 越来越大时,两个时刻之间的联系也会越来越弱。Transformer 里面是 的矩阵乘法,而矩阵乘法任意两列(两个时刻)都会计算。以Beijing is the captial of china 为例,在RNN 这种结构中,Beijing 和 china 距离较远,所以在预测china 的时候RNN中几乎没有任何关于Beijing特征的信息,但是在transformer 中,Beijing is the captial of china 这句话和 is the captial of Beijing china 是一样的,所以在长时间依赖上,transformer 能够优于RNN,也正是因为这个原因,需要利用位置编码将位置信息加给模型。