
(附方法或代码)干货 | 一文总结旋转目标检测全面综述
点击左上方蓝字关注我们

作者 | qianlinjun @知乎
链接 | https://zhuanlan.zhihu.com/p/98703562
1.RRPN(两阶段文字检测 华科白翔组)

2.EAST (单阶段文字检测器 旷世科技)
提出单阶段的检测框架figure3。提出一种新的旋转目标定义方式(特征点到旋转框的四边距离以及角度信息),如下图c,图d,e分别预测四个距离和角度信息
应该算是比较早的anchor-free方法检测旋转目标的尝试,将旋转的ground-truth box向内按比例缩小一个范围如下图左上角(a)中的绿色框,特征点落在这个绿色框内作为正样本。2019年的一篇 anchor-free 水平框目标检测器FoveaBox 和这个思路有点相似(arxiv.org/abs/1904.0379)

提出一个Locality-Aware NMS,加速nms过程
3. R2CNN (两阶段文字检测 三星中国)
提出一种新的旋转目标定义方式(检测 顺时针顺序的四个角点中的 前两个角点x1 y1 x2 y2和矩形高)

整体使用faster rcnn框架,考虑到某些文字框的宽高差距很大,在ROI pooling时 除了使用7x7的pooled size 还增加了3x11和11x3 两种pooled size。3x11可以更好地捕捉水平特征,这对于检测宽大于高的框比较有好处,而11x3可以更好地捕捉竖直特征,这对于检测高大于宽的框比较有好处。

4.RR-CNN(两阶段舰船检测 中科院自动化所)
提出RRoI pooling layer,提取旋转目标特征
回归旋转目标模型
传统NMS针对同类目标做,这篇文章针对多类别提出多任务NMS


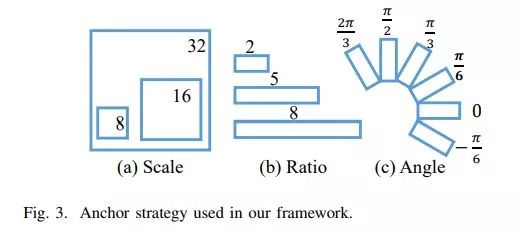
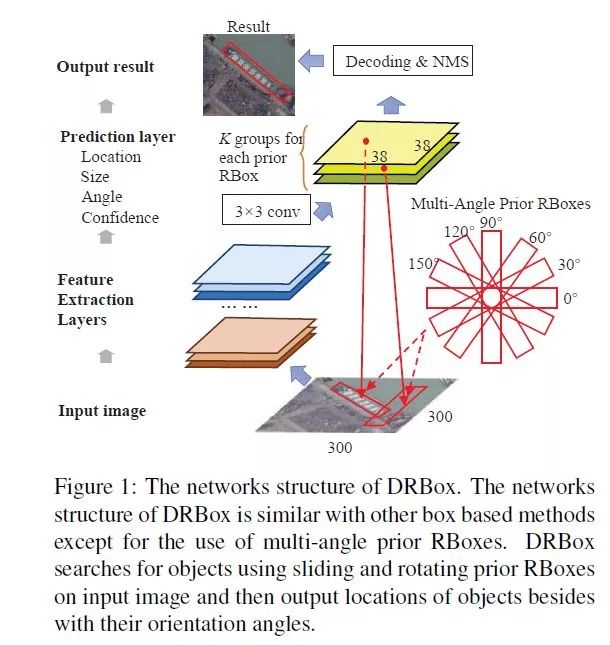
5. DRBOX(两阶段目标检测 中科院电子所)
网络pipeline如下,论文时间比较早,没具体说使用了什么网络结构,参考其他论文说法,DRBOX类似RPN结构
比较早的说明了用水平框检测旋转目标存在的问题

6. TextBoxes++(单阶段 华科白翔组)
在SSD基础上检测水平框和旋转框


使用不规则卷积核:
textboxes++中采用3x5的卷积核,以便更好的适应长宽比更大的文字
使用OHEM策略
训练过程采用OHEM策略,不同于传统的OHEM,训练分为两个stage,stage1的正负样本比为1:3,stage2的政府样本比为1:6
多尺度训练
由于Textboxes++采用了全卷积结构,因此可以适应不同尺度的输入。为了适应不同尺度目标,采用了多尺度训练。
级联NMS
由于计算倾斜文字的IOU较为耗时,因此作者采用级联NMS加速IOU计算,先计算所有所有框的最小外接矩形的IOU,做一次阈值为0.5的NMS,消除一部分框,然后再计算倾斜框的IOU的基础上做一次阈值为0.2的NMS。
7. Learning roi transformer for oriented object detection in aerial images(cvpr2019 武大夏桂松 两阶段)
基于水平anchor,在RPN阶段通过全连接学习得到旋转ROI(区别于RRPN设置很多旋转anchor,因为这篇文章是从水平anchor学习得到旋转ROI,减小了计算量),基于旋转ROI提取特征,然后进行定位和分类
Rotated Position Sensitive RoI Align
基于旋转框提取roi特征
8. R2PN(两阶段)
感觉和RRPN比较像,基于旋转anchor,通过RPN得到旋转ROI,基于旋转ROI提取特征,然后进行定位和分类。和Learning roi transformer这篇文章区别 是前者是旋转anchor,后者是水平anchor,计算量更小。
9. R2CNN++(SCRDet) (两阶段 中科院电子所)

SF-Net:把两个不同层的feature map进行定制化融合 有效检测小目标
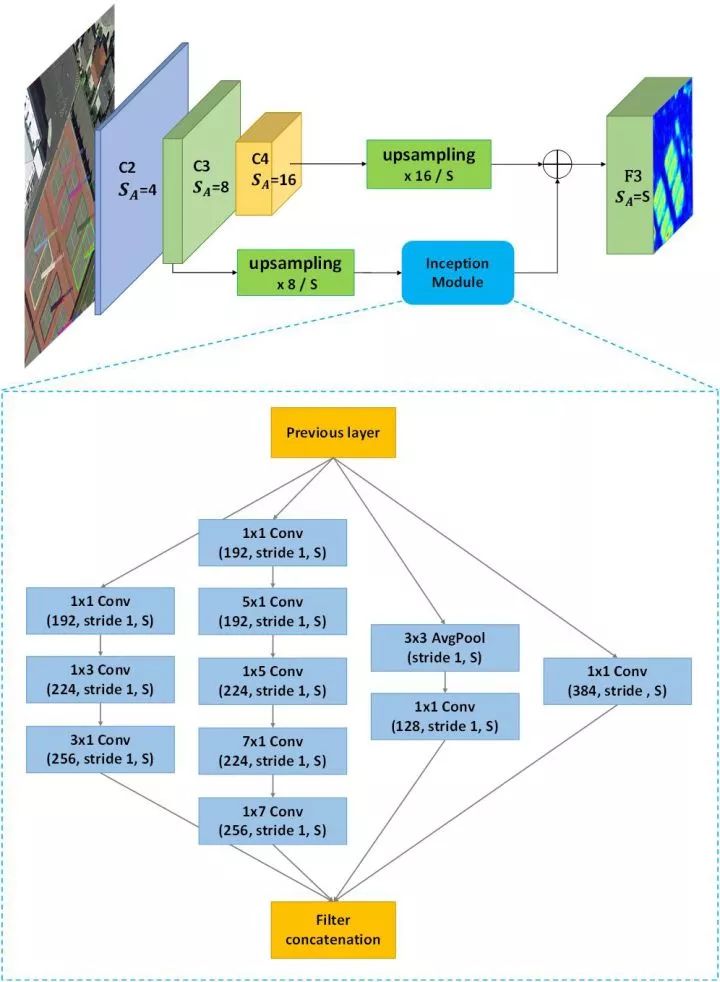
MDA-Net: 使用通道注意力和像素级别的注意力机制检测密集目标和小目标
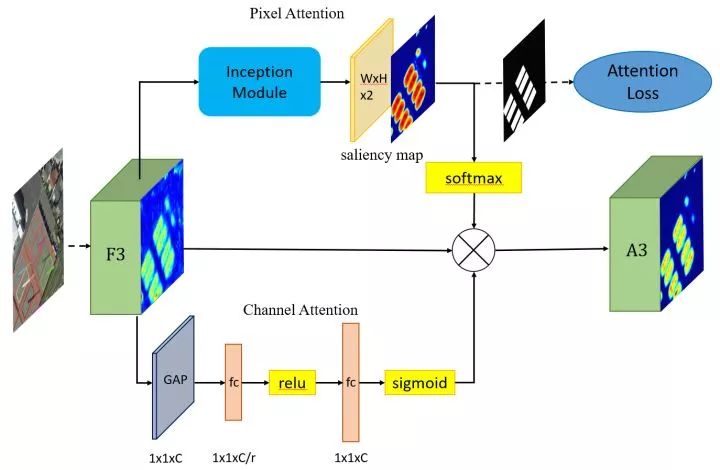
提出改进版的smooth L1loss 解决旋转目标在垂直时角度(从0°会突变到-90°) 存在变化不连续问题

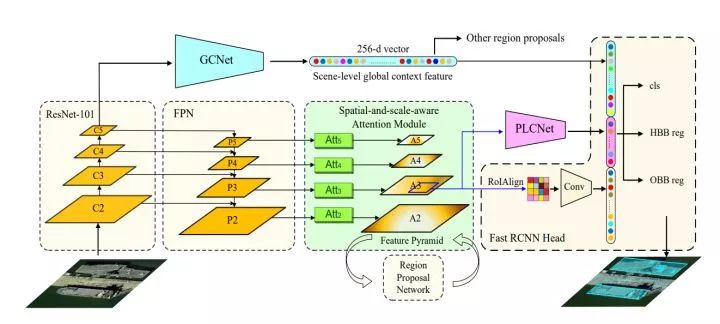
10. CAD-Net (两阶段)
提出GCNet(Global Context Network),在进行目标检测时融入全局上下文信息
提出PLCNet(pyramid local context network)引入空间注意力学习目标协同关系,


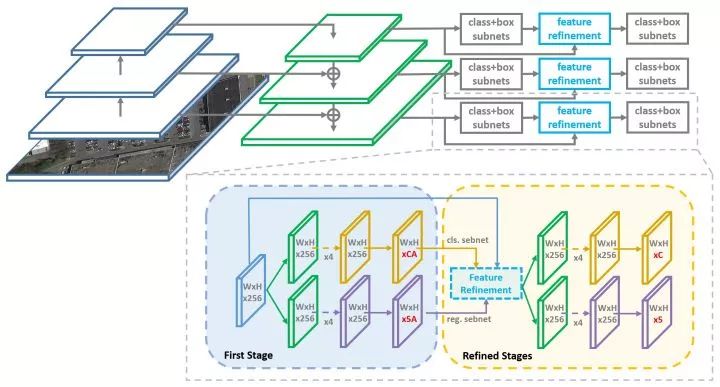
11. R3Det (单阶段旋转目标检测 上交&南理&旷世)
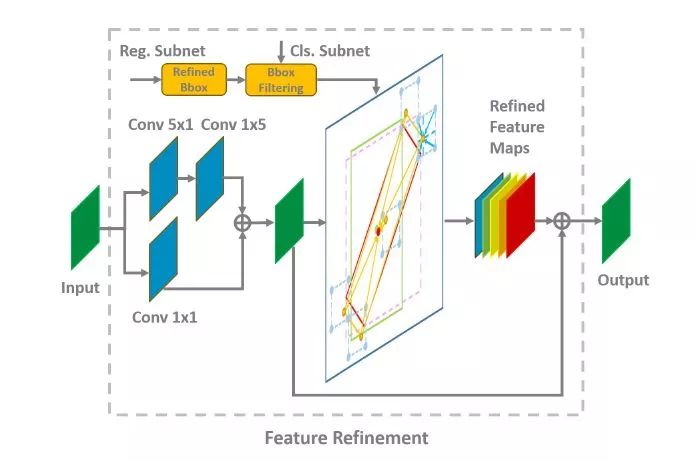
旋转目标检测(水平目标检测也)可能存在某个anchor所在的特征点的感受野和目标位置、形状不匹配 (如下图左上角,绿色框是anchor,它所在的特征点只能看到这艘船的一部分,那么直接用这个点的特征去回归anchor 以拟合ground truth(红色框)不一定准确),所以这篇论文分两个stage:first stage 从anchor预测旋转框(橙色框),如下图红色数字1->2,这时候橙色框范围和真实目标就很接近了,然后根据橙色框提取特征(我理解为类似ROI pooling特征提取),通过这个特征回归到ground truth,如下图中红色数字2->3.

网络结构沿用RetinaNet的结构,并引入了feature refinement 模块,并且可以叠加多次
END
整理不易,点赞三连↓