
Elasticsearch 8.X 导出 CSV 多种方案,一网打尽!
1、问题来源
看到 Elasticsearch 数据导出需求,我的第一反应是,好好的为啥要导出?
写入的时候直接写给定格式的文件如 CSV 不就可以了。
其实真实的业务场景,远非我想的这么简单。
Elasticsearch 作为存储库和检索源,相关的输入数据来源早已包罗万象、几乎“无所不能”。
如下图所示:
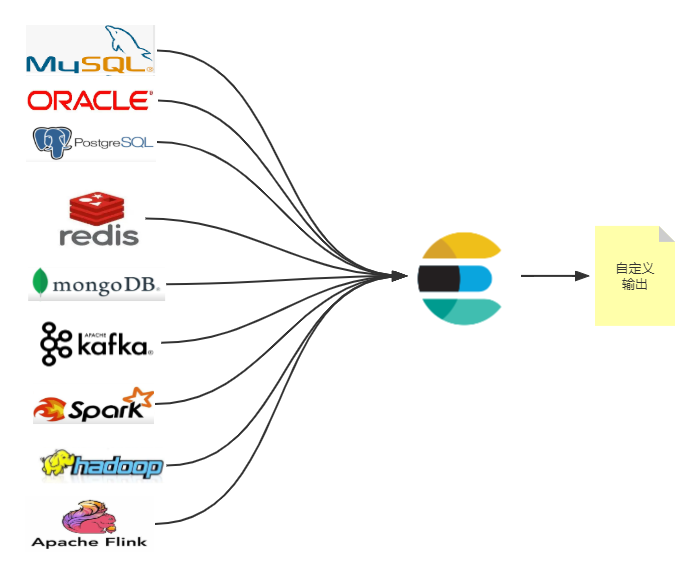
关系型数据库(MySQL、Oracle、PostgreSQL)、非关系型数据库(MongoDB)、大数据引擎(Kafka、Spark、Hadoop、Hbase、Flink)、内存数据库(Redis)都可以导入 Elasticsearch。
原始数据经过采集到写入 Elasticsearch 之前往往经过预处理、ETL(抽取、转换、加载),核心检索相关的数据落地存储到 Elasticsearch。
某些特定的业务场景(比如:银行业务)需要导出 Elasticsearch 数据,实际是需要导出已经预处理过、已经清洗过的 Elasticsearch 数据。
那么,问题来了?如何导出呢?
2、Elasticsearch 导出数据的方式
以 CSV 格式(导出数据格式)数据为例。
Elasticsearch 导出数据的方式有很多种,包含但不限于:
logstash_output_csv 类似 es2csv python 开源工具包导出 kibana 可视化导出 python、java或shell脚本等自己实现
我们逐个以 Elasticsearch 8.X 版本演示一下。
3、logstash_output_csv 导出
input {
elasticsearch {
hosts => "172.121.10.114:9200"
index => "tianyancha_index"
query => '
{
"query": {
"match_all": {}
}
}
'
ssl => "true"
user => "elastic"
password => "changeme"
ca_file => "/www/...省略.../certs/http_ca.crt"
}
}
output {
csv {
# elastic field name
fields => ["regist_id", "establishment_time", "enttype", "company_name", "company_type"]
# This is path where we store output.
path => "/www/...省略.../sync/tyc_export.csv"
}
}
结果如下:
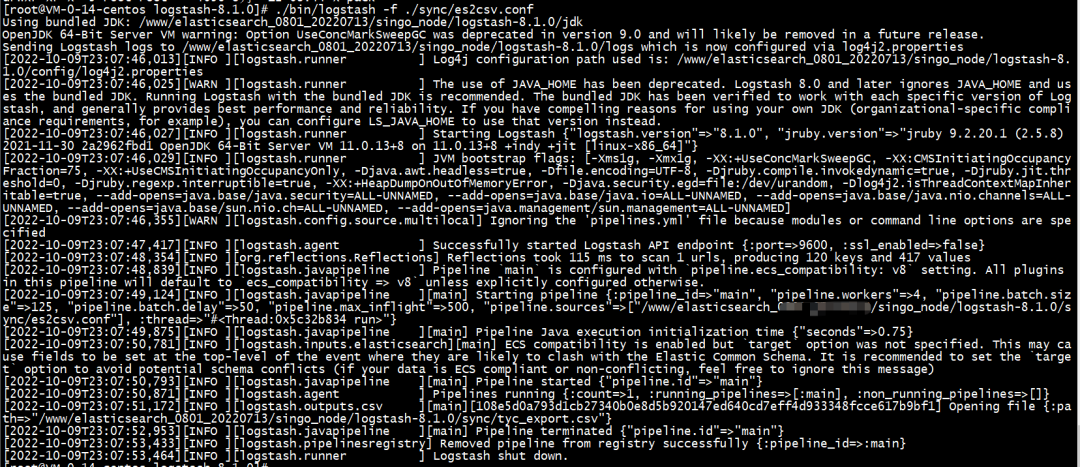
生成 CSV 文件如下:
常见报错信息:
[main] Pipeline error {:pipeline_id=>"main", :exception=>#<Manticore::ClientProtocolException: 172.21.0.14:9200 failed to respond>,
解决方案:开启 ssl,默认为false。8.X 必须得手动开启。
4、elasticsearch_tocsv 开源工具包导出
工具名称:elasticsearch_tocsv 工具地址:https://pypi.org/project/elasticsearch-tocsv/ 工具安装方式:
pip3 install elasticsearch-tocsv
工具依赖:python 3.8(含)以上版本。 工具实战:
elasticsearch_tocsv -p 9200 -ho 172.121.10.114 -u elastic -pw changeme -s True -cp '../config/certs/http_ca.crt' -i tianyancha_index -f "@regist_id,establishment_time,scope_business,address,registration_number"
参数含义:
-ho:Elasticsearch IP 地址 -p: Http 端口号 -u:用户名 -pw:密码 -cp:CRT证书地址 -s:SSL 认证,默认为false,8.X 需要开启 -i:索引 -f:导出的字段
工具导出实现截图:

类似工具很多,拿一个举例,方便大家实操。
5、借助kibana 导出
1 分钟视频就可以搞定。
视频如下,一看就会。
6、自己写代码导出
6.1 Python 程序导出
简单的 Python 程序实现如下。
def client_init():
ssl_context = create_ssl_context()
ssl_context.check_hostname = False
ssl_context.verify_mode = ssl.CERT_NONE
es = Elasticsearch(
hosts=[
"https://172.121.10.114:9200"
],
ssl_context=ssl_context,
http_auth=('elastic', 'changeme'),
use_ssl=True,
verify_certs=True,
)
return es
def tianyancha_search():
client =client_init()
s = Search(using=client, index="tianyancha_index") \
.query("match_all")
response = s.execute()
sample = response['hits']['hits']
with open( 'tianyancha_rst.csv', 'w', newline='' ) as csvfile:
spamwriter = csv.writer( csvfile, delimiter=',',
quotechar='|', quoting=csv.QUOTE_MINIMAL )
spamwriter.writerow( ['regist_id_new', 'company_name', 'business_starttime', 'scope_business'] )
for hit in sample:
# fill columns 1, 2, 3 with your data
col1 = hit._source.regist_id_new
col2 = hit._source.company_name
col3 = hit._source.business_starttime
col4 = hit._source.scope_business
spamwriter.writerow( [col1, col2, col3, col4] )
不复杂三段论:
1)连接 8.X Elasticsearch 集群; 2)遍历索引获取数据 3)解析数据写入 CSV 文件。
这里只是简单的 from + size 遍历,数据量大可以改成 scroll 实现。
导出 CSV 结果如下:
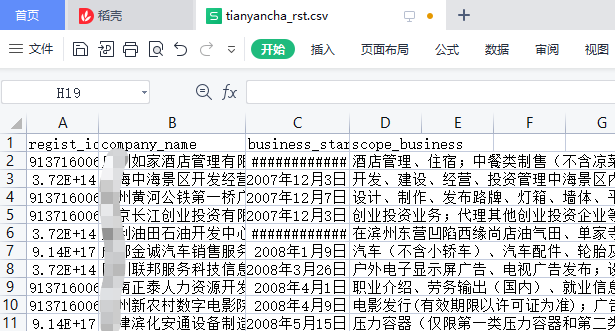
6.2 Shell 脚本导出
curl -s -XGET -H "Content-Type:application/json" --cacert ../config/certs/http_ca.crt -u elastic:changeme 'https://172.121.10.114:9200/tianyancha_index/_search' -d '
{"from": 0,
"size": 2,
"query": {
"match_all": {}
}
}' | jq -r '["regist_id", "establishment_time", "scope_business", "address", "registration_number"],(.hits.hits[] |
[._source.regist_id // "", ._source.establishment_time // "", ._source.scope_business // "", ._source.address // "", ._source.registration_number // ""]) | @csv' > tyc_es2csv.csv
解释一下:
jq 是 shell 脚本下的 json 解析工具。
["regist_id", ****, "registration_number"]代表以数组形式自定义输出多项。
jq 使用细节可以查看帮助手册:https://stedolan.github.io/jq/tutorial/
shell 脚本导出 CSV 如下:

7、小结
能导出 Elasticsearch 方案有 N 多种,本文仅是抛砖引玉。
导出方案如何选型?
根据业务需求,如果不想写代码可以借助第三方工具实现。
如果想使用 ELK 组件,推荐使用 logstash。
如果仅自己有针对的实现,可以 Python 脚本、Shell 脚本都可以。
更多方案,欢迎留言交流。
