
如何优雅的设计一套高性能短网址服务
共 3229字,需浏览 7分钟
·
2020-12-04 17:51

文 | 豆豆
来源:Python 技术「ID: pythonall」

得益于移动互联网的蓬勃发展,自媒体日益火爆的同时其门槛也越来越低,可以说是全民自媒体。其中内容创作平台尤为火爆,比如微信公众号、微博、知乎、头条等。随之而来的就是各种「奇葩」需求,比如将长链接转换为短链接。
相信大家也都见过下面这种短信,极客时间的营销短信,就是短链接,点击之后会跳转到下面这个长链接,那么为啥要那么麻烦转换成短链接呢,直接用原始链接不就好了么。
https://shop18793264.m.youzan.com/v2/feature/pqzBz4KeGT?dc_ps=2663040806184605700.200001
其实之所以需要短链接其一是因为成本更低。我们都知道短信是有字数限制的,所以用长链接的话运营商有可能将短信拆分为两条或者多条来发送,成本增加一倍。
其二是因为效果更好。好比微博也是有字数限制的,如果如我们想在微博发一个引流文,引导用户点击我们的注册链接,但因为微博有 140 字的限制,我们的注册链接又比较长,如果我们可以将长链接转换为短链接的话,那岂不是就可以编辑更多的文字来吸引用户了么。
另外,有时候是不方便直接放链接的,比如微信公众号是不允许放外链的,那么我们就可以将链接转换为二维码引导用户扫描二维码即可,短链接比长链接转换出来的二维码更清晰易识别。
那么如果让你来设计一套短链接服务,你会怎么设计呢,同时这也是一道用来考察候选人基本功的常用面试题。
最糟糕的设计
首先我们梳理下需求,即我们想要让网址变短之后依然不影响使用。
那么我们是否可以设计一个算法,将长链接和短链接一一对应呢。该算法接收一个长链接的参数,输出其对应的短链接,当服务器收到短链接的请求后,再通过逆运算将短链接变成长链接,这样一来不不就很容易实现长链接变短链接的需求了么。
只是这里有个问题我们可能忽略了,事实上世界上的长链接个数是趋于正无穷的,有限长度的字符串只能表示有限个短链接,假设短链接的长度为 20 位,那么最多只能表示 62 的 20 次方个短链接,无法做到和正无穷个长链接一一对应。
次糟糕的设计
回到原点,我们只不过是想将长网址变短而已,变短不就是数据压缩吗,签名算法可以不,比如 MD5、SHA 等散列算法。这些算法可以将任何长度的字符串压缩到固定长度。
但是它们也是有问题的,首先 MD5 有可能碰撞我们不说,单就 MD5 签名之后的字符串长度是定长这一点我们是无法接受的,有可能能能我们的长网址都没有 32 位那么长,这样一来不仅没有变短,反而变长了,这设计不合理。
另外 MD5 这类函数通常用于加密,其性能不是很高,我们并不关心安全性,只关心转换效率和哈希之后的冲突概率而已。
常规的设计
既然要把长链接映射成短链接,哈希算法就是做这个事情的嘛,只不过上面的设计选的哈希算法不好而已。效率高的哈希算法很多,推荐 Murmur 哈希,Murmur 哈希是一种非加密散列函数,适用于一般的基于散列的查找。非加密意味着效率更高,该哈希算法会一个 32 位或者 64 位的值,32 位最多表示 42亿+ 个记录,对于常规业务来讲足够用了。
假设我么对一个网址哈希之后的值是 4003787369,那么生成的短链接就是 https://domain/4003787369,其中前面的域名就是我们的短链接服务器域名。如果你觉得域名还是长,那么可以将十进制的 4003787369 转换为 62 进制,转换之后的结果为:4mXtZD,即 https://domain/4mXtZD,从 10 位直接缩短为 6 位。
既然是哈希函数,肯定会产生哈希冲突,那如何解决哈希冲突呢?
这里假设我们将长链接和短链接的对应关系是存储在数据库的,该表有四列,分别是:id、long_url、short_url、create_time, 我们可以在 short_url 列建立一个唯一索引,当我们得到一个长链接和短链接的对应关系后,直接插入数据库,如果插入失败说明有冲突,这是需要给长链接添加混淆字符串再次求哈希,之后在插入,如果还冲突就重复刚才的过程,直到插入成功。
事实上 Murmur 哈希算法的冲突是很低的,基本可以忽略。
最佳设计
除了对长链接进行哈希运算之后,我们还可以通过发号策略,给每一个长链接发一个号码,你可以把发号策略理解为 ID 生成器。
这样子,第一个来的长网址对应的短链接是 https://domain/1,第二个长链接对应的短链接是 https://domain/2,依次递增。拿到号码之后,我们可以将该号码作为主键存储该长网址记录,同时因为 MySQL 根据主键去获取记录的速度是超级快的,所以这种方式我们不需要担心查询的性能问题。
这里我们唯一需要关心的就是发号策略了,业务量不大的话,我们可以直接用 MySQL 的自增序列来实现;如果是大型应用,就需要考虑高并发了。我们可以多部署一些节点,比如部署 1000 个节点,每个发号器发完一个号之后不在自增 1 ,而是自增 1000。比如对于 1 号发号器,其发送的号码依次是:1、1001、2001、3001...,如对于 2 号发号器,其发送的号码依次是:2、1002、2002、3002...
如此一来,即保证了我们的发号器永远不会发出重复的号码,也保证了号码是递增的,主键递增对于数据库来说太重要了。
那如果遇到相同的长链接如何处理呢,直接查表吗?
直接查表怕是会浪费太多时间,我们可以做一个 LRU 缓存,当有请求过来时,我们只需要判断该网址是否在 LRU 缓存中即可,若存在,则直接返回,否则直接生成对应关系后将该记录加入缓存。
只不过这样一来的话,对于那些不热门的网址,可能会生成多个对应关系,事实上我们也没必要非得做到一一对应,一个长链接对应多个短链接对业务来说没什么影响,而且不热门网址出现频率本来就很低,不会浪费多少空间。
短链接原理
打开极客时间发我给的短链接,调出开发者工具来看看网络请求。
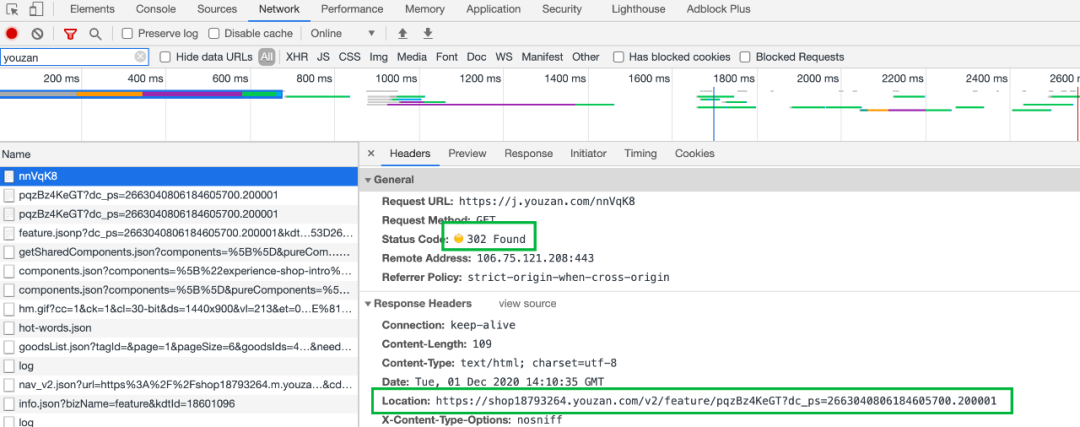
由上图我们可以得知,浏览器请求短链接的时候服务器返回了 302 状态码,然后浏览器重新发起了一次请求到长链接,主要原理就是用到了重定向,我们知道 302 状态码和 301 状态码都是表示重定向,那么为啥返回 302 而不是 301 呢。
301 是永久重定向,浏览器第一次拿到长链接后,后面再去请求短链接都不会在请求短链接服务器了,而是直接从本地缓存获取,正常来说短链接一经生成是不会在变化的了,那么使用 301 状态码不管在正常逻辑方面还是 http 语义方面都是合情合理的呀,同时对短链接服务器的压力也会小很多。但是如果使用 301 状态码我们是无法统计到该链接的点击次数的,如果我们想分析活动的效果的话,点击次数可是一个很重要的指标哦,返回 302 增加点服务器压力是值得的。
总结
关于以上如何生成短链接,我们介绍了四种方案,其中第一种压根不可行,第二种设计不是很合理,第三种对于业务量不大的系统来说足够了,第四种则是最佳实践。
今天我们详细阐述了如何设计一个高性能短链接服务,该问题看似简单,实则涉及很多知识点,像短链接跳转原理,301 还是 302,以及如何更快更好的生成短链接,希望小伙伴们能有所收获,下次在遇到这道题时可以吊打面试官。
PS:公号内回复「Python」即可进入Python 新手学习交流群,一起 100 天计划!
老规矩,兄弟们还记得么,右下角的 “在看” 点一下,如果感觉文章内容不错的话,记得分享朋友圈让更多的人知道!


【神秘礼包获取方式】