Redis 数据结构之字符串的那些骚操作
共 10613字,需浏览 22分钟
·
2020-11-21 18:39

Redis 字符串底层用的是 sds 结构,该结构同 c 语言的字符串相比,其优点是可以节省内存分配的次数,还可以...
这样写是不是读起来很无聊?这些都是别人咀嚼过后,经过一轮两轮三轮的再次咀嚼,吐出来的精华,这就是为什么好多文章你觉得干货满满,但就是记不住说了什么。我希望把这个咀嚼的过程,也讲给你,希望以后再提到 Redis 字符串时,它是活的。
前置知识:本篇文章的阅读需要你了解 Redis 的编码类型,知道有这么回事就行,如果比较困惑可以先读一下 《面试官问我 redis 数据类型,我回答了 8 种》 这篇文章
源码选择:Redis-3.0.0
文末总结:本文行为逻辑是边探索边出结论,但文末会有很精简的总结,所以不用怕看的时候记不住,放心看,像读小说一样就行,不用边读边记。
我研究 Redis 源码时的小插曲
我下载了 Redis-3.0.0 的源码,找到了 set 命令对应的真正执行存储操作的源码方法 setCommand。其实 Redis 所有的指令,其核心源码的位置都是叫 xxxCommand,所以还是挺好找的。
t_string.c
/* SET key value [NX] [XX] [EX ] [PX ] */
void setCommand(redisClient *c) {
int j;
robj *expire = NULL;
int unit = UNIT_SECONDS;
int flags = REDIS_SET_NO_FLAGS;
for (j = 3; j < c->argc; j++) {
// 这里省略无数行
...
}
c->argv[2] = tryObjectEncoding(c->argv[2]);
setGenericCommand(c,flags,c->argv[1],c->argv[2]...);
}
不知道为什么,看到字符串这么长的源码(主要是下面那两个方法展开很多),我就想难道这不会严重影响性能么?我于是做了如下两个压力测试。
未修改源代码时的压力测试
[root@VM-0-12-centos src]# ./redis-benchmark -n 10000 -q
...
SET: 112359.55 requests per second
GET: 105263.16 requests per second
INCR: 111111.11 requests per second
LPUSH: 109890.11 requests per second
...
观察到 set 指令可以达到 112359 QPS,可以,这个和官方宣传的 Redis 性能也差不多。
我又将 setCommand 的源码修改了下,在第一行加入了一句直接返回的代码,也就是说在执行 set 指令时直接就返回,我想看看这个 set 性能会不会提高。
void setCommand(redisClient *c) {
// 这里我直接返回一个响应 ok
addReply(c, shared.ok);
return;
// 下面是省略的 Redis 自己的代码
...
}
将 setCommand 改为立即返回后的压力测试
[root@VM-0-12-centos src]# ./redis-benchmark -n 10000 -q
...
SET: 119047.62 requests per second
GET: 105263.16 requests per second
INCR: 113636.37 requests per second
LPUSH: 90090.09 requests per second
...
和我预期的不太一样,性能几乎没有提高,又连续测了几次,有时候还有下降的趋势。
说明这个 setCommand 里面写了这么多判断呀、跳转什么的,对 QPS 几乎没有影响。想想也合理,现在 CPU 都太牛逼了,几乎性能瓶颈都是在 IO 层面,以及内存分配与释放这些地方,这个 setCommand 里面写了这么多代码,执行速度同直接返回相比,都几乎没有什么差别。
跟我在源码里走一遍 set 的全流程
首先,客户端执行指令
127.0.0.1:6379> set name tom
然后就进入我的 debug 断点了
别深入,先看骨架
源码没那么吓人,多走几遍你就会发现看源码比看文档容易了,因为最直接,且阅读量也最少,没有那么多脑筋急转弯一样的比喻。
真的全流程,应该把前面的 建立 socket 链接 --> 建立 client --> 注册 socket 读取事件处理器 --> 从 socket 读数据到缓冲区 --> 获取命令 也加上,也就是面试中的常考题 单线程的 Redis 为啥那么快 这个问题的答案。不过本文专注于 Redis 字符串在数据结构层面的处理,请求流程后面会专门去讲,这里只把前面步骤的 debug 堆栈信息给大家看下
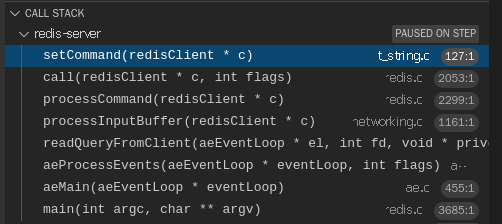
总之当客户端发送来一个 set name tom 指令后,Redis 服务端历经千山万水,找到了 setCommand 方法进来。
// 注意入参是个 redisClient 结构
void setCommand(redisClient *c) {
int flags = REDIS_SET_NO_FLAGS;
// 前面部分完全不用看
...
// 下面两行是主干,先确定编码类型,再执行通用的 set 操作函数
c->argv[2] = tryObjectEncoding(c->argv[2]);
setGenericCommand(c,flags,c->argv[1],c->argv[2]...);
}
好长的代码被我缩短到只有两行了,因为前面部分真的不用看,前面是根据 set 的额外参数来设置 flags 的值,但是像如 set key value EX seconds 这样的指令,一般都直接被更常用的 setex key seconds value 代替了,而他们都有专门对应的更简洁的方法。
void setnxCommand(redisClient *c) {
c->argv[2] = tryObjectEncoding(c->argv[2]);
setGenericCommand(...);
}
void setexCommand(redisClient *c) {
c->argv[3] = tryObjectEncoding(c->argv[3]);
setGenericCommand(...);
}
void psetexCommand(redisClient *c) {
c->argv[3] = tryObjectEncoding(c->argv[3]);
setGenericCommand(...);
}
| 属性 | argv[0] | argv[1] | argv[2] |
|---|---|---|---|
| type | string | string | string |
| encoding | embstr | embstr | embstr |
| ptr | "set" | "name | "tom" |
我们可以断定,这些 argv 参数就是 将我们输入的指令一个个的包装成了 robj 结构体 传了进来,后面怎么用的,那就再说咯。
骨架了解的差不多了,总结起来就是,Redis 来一个 set 指令,千辛万苦走到 setCommand 方法里,tryObjectEncoding 一下,再 setGenericCommand 一下,就完事了。至于那两个方法干嘛的,我也不知道,看名字再结合上一讲中的编码类型的知识,大概猜测先是处理下编码相关的问题,然后再执行一个 set、setnx、setex 都通用的方法。
那继续深入这两个方法,即可,一步步来
进入 tryObjectEncoding 方法
c->argv[2] = tryObjectEncoding(c->argv[2]);
我们可以看到调用方把 argv[2],也就是我们指令中 value 字符串 "tom" 包装成的 robj 结构,传进了 tryObjectEncoding,之后将返回值又赋回去了。一个合理的猜测就是可能 argv[2] 什么都没变就返回去了,也可能改了点什么东西返回去更新了自己。那要是什么都不变,就又可以少研究一个方法啦。
抱着这个侥幸心理,进入方法内部看看。
/* Try to encode a string object in order to save space */
robj *tryObjectEncoding(robj *o) {
long value;
sds s = o->ptr;
size_t len;
...
len = sdslen(s);
// 如果这个值能转换成整型,且长度小于21,就把编码类型替换为整型
if (len <= 21 && string2l(s,len,&value)) {
// 这个 if 的优化,有点像 Java 的 Integer 常量池,感受下
if (value >= 0 && value < REDIS_SHARED_INTEGERS) {
...
return shared.integers[value];
} else {
...
o->encoding = REDIS_ENCODING_INT;
o->ptr = (void*) value;
return o;
}
}
// 到这里说明值肯定不是个整型的数,那就尝试字符串的优化
if (len <= REDIS_ENCODING_EMBSTR_SIZE_LIMIT) {
robj *emb;
// 本次的指令,到这一行就返回了
if (o->encoding == REDIS_ENCODING_EMBSTR) return o;
emb = createEmbeddedStringObject(s,sdslen(s));
...
return emb;
}
...
return o;
}
别看这么长,这个方法就一个作用,就是选择一个合适的编码类型而已。功能不用说,如果你感兴趣的话,从中可以提取出一个小的骚操作:
在选择整型返回的时候,不是直接转换为一个 long 类型,而是先看看这个数值大不大,如果不大的话,从常量池里面选一个返回这个引用,这和 Java Integer 常量池的思想差不多,由于业务上可能大部分用到的整型都没那么大,这么做至少可以节省好多空间。
进入 setGenericCommand 方法
看完上个方法很开心,因为就只是做了编码转换而已,这用 Redis 编码类型的知识很容易就理解了。看来重头戏在这个方法里呀。
方法不长,这回我就没省略全粘过来看看
void setGenericCommand(redisClient *c, int flags, robj *key, robj *val, robj *expire, int unit, robj *ok_reply, robj *abort_reply) {
long long milliseconds = 0; /* initialized to avoid any harmness warning */
if (expire) {
if (getLongLongFromObjectOrReply(c, expire, &milliseconds, NULL) != REDIS_OK)
return;
if (milliseconds <= 0) {
addReplyErrorFormat(c,"invalid expire time in %s",c->cmd->name);
return;
}
if (unit == UNIT_SECONDS) milliseconds *= 1000;
}
if ((flags & REDIS_SET_NX && lookupKeyWrite(c->db,key) != NULL) ||
(flags & REDIS_SET_XX && lookupKeyWrite(c->db,key) == NULL))
{
addReply(c, abort_reply ? abort_reply : shared.nullbulk);
return;
}
setKey(c->db,key,val);
server.dirty++;
if (expire) setExpire(c->db,key,mstime()+milliseconds);
notifyKeyspaceEvent(REDIS_NOTIFY_STRING,"set",key,c->db->id);
if (expire) notifyKeyspaceEvent(REDIS_NOTIFY_GENERIC,
"expire",key,c->db->id);
addReply(c, ok_reply ? ok_reply : shared.ok);
}
我们只是 set key value, 没设置过期时间,也没有 nx 和 xx 这种额外判断,也先不管 notify 事件处理,整个代码就瞬间只剩一点了。
void setGenericCommand(redisClient *c, robj *key, robj *val...) {
...
setKey(c->db,key,val);
...
addReply(c, ok_reply ? ok_reply : shared.ok);
}
addReply 看起来是响应给客户端的,和字符串本身的内存操作关系应该不大,所以看来重头戏就是这个 setKey 方法啦,我们点进去。由于接下来都是小方法连续调用,我直接列出主线。
void setKey(redisDb *db, robj *key, robj *val) {
if (lookupKeyWrite(db,key) == NULL) {
dbAdd(db,key,val);
} else {
dbOverwrite(db,key,val);
}
...
}
void dbAdd(redisDb *db, robj *key, robj *val) {
sds copy = sdsdup(key->ptr);
int retval = dictAdd(db->dict, copy, val);
...
}
int dictAdd(dict *d, void *key, void *val) {
dictEntry *entry = dictAddRaw(d,key);
if (!entry) return DICT_ERR;
dictSetVal(d, entry, val);
return DICT_OK;
}
这一连串方法见名知意,最终我们可以看到,在一个字典结构 dictEntry 里,添加了一条记录。这也说明了 Redis 底层确实是用 字典(hash 表)来存储 key 和 value 的。
跟了一遍 set 的执行流程,我们对 redis 的过程有个大致的概念了,其实和我们预料的也差不多嘛,那下面我们就重点看一下 Redis 字符串用的数据结构 sds
字符串的底层数据结构 sds
关于字符编码之前说过了,Redis 中的字符串对应了三种编码类型,如果是数字,则转换成 INT 编码,如果是短的字符串,转换为 EMBSTR 编码,长字符串转换为 RAW 编码。
不论是 EMBSTR 还是 RAW,他们只是内存分配方面的优化,具体的数据结构都是 sds,即简单动态字符串。
sds 结构长什么样
很多书中说,字符串底层的数据结构是 SDS,中文翻译过来叫 简单动态字符串,代码中也确实有这种赋值的地方证明这一点
sds s = o->ptr;
但下面这段定义让我曾经非常迷惑
sds.h
typedef char *sds;
struct sdshdr {
unsigned int len;
unsigned int free;
char buf[];
};
将一个字符串变量的地址赋给了一个 char* 的 sds 变量,但结构 sdshdr 才是表示 sds 结构的结构体,而 sds 只是一个 char* 类型的字符串而已,这两个东西怎么就对应上了呢
其实再往下读两行,就豁然开朗了。
static size_t sdslen(const sds s) {
struct sdshdr *sh = (void*)(s-(sizeof(struct sdshdr)));
return sh->len;
}
原来 sds 确实就是指向了一段字符串地址,就相当于 sdshdr 结构里的 buf,而其 len 和 free 变量就在一定的内存偏移处。
结构与优点
盯着这个结构看 10s,你脑子里想到的是什么?如果你什么都想不到,那建议之后和我的公众号一起,多多阅读源码。如果瞬间明白了这个结构的意义,那请联系我,收我为徒吧!
struct sdshdr {
unsigned int len;
unsigned int free;
char buf[];
};
回过头来说这个 sds 结构,char buf[] 我们知道是表示具体值的,这个肯定必不可少。那剩下两个字段 len 和 free 有什么作用呢?
敲重点!敲重点!敲重点!!
len:表示字符串长度。由于 c 语言的字符串无法表示长度,所以变量 len 可以以常数的时间复杂度获取字符串长度,来优化 Redis 中需要计算字符串长度的场景。而且,由于是以 len 来表示长度,而不是通过字符串结尾标识来判断,所以可以用来存储原封不动的二进制数据而不用担心被截断,这个叫二进制安全。
free:表示 buf 数组中未使用的字节数。同样由于 c 语言的字符串每次变更(变长、变短)都需要重新分配内存地址,分配内存是个耗时的操作,尤其是 Redis 面对经常更新 value 的场景。那有办法优化么?
能想到的一种办法是:在字符串变长时,每次多分配一些空间,以便下次变长时可能由于 buf 足够大而不用重新分配,这个叫空间预分配。在字符串变短时,并不立即重新分配内存而回收缩短后多出来的字符串,而是用 free 来记录这些空闲出来的字节,这又减少了内存分配的次数,这叫惰性空间释放。
不知不觉,多出了四个名词可以和面试官扯啦,哈哈。现在记不住没关系,看文末的总结笔记就好。
上源码简单证明一下
老规矩,看源代码证明一下,不能光说结论,我们拿空间预分配来举例。
由于将字符串变长时才能触发 Redis 的这个技能,所以感觉应该看下 append 指令对应的方法 appendCommand。
跟着跟着发现有个这样的方法
/* Enlarge the free space at the end of the sds string so that the caller
* is sure that after calling this function can overwrite up to addlen
* bytes after the end of the string, plus one more byte for nul term.
* Note: this does not change the *length* of the sds string as returned
* by sdslen(), but only the free buffer space we have. */
sds sdsMakeRoomFor(sds s, size_t addlen) {
struct sdshdr *sh, *newsh;
size_t len, newlen;
// 空闲空间够,就直接返回
size_t free = sdsavail(s);
if (free >= addlen) return s;
// 再多分配一倍(+1)的空间作为空闲空间
len = sdslen(s);
sh = (void*) (s-(sizeof(struct sdshdr)));
newlen = (len+addlen);
newlen *= 2;
newsh = zrealloc(sh, sizeof(struct sdshdr)+newlen+1);
..
return newsh->buf;
}
本段代码就是说,如果增长了字符串,假如增长之后字符串的长度是 15,那么就同样也分配 15 的空闲空间作为 free,总 buf 的大小为 15+15+1=31(额外 1 字节用于保存空字符)
最上面的源码中的英文注释,就说明了一切,留意哦~
其他几个特性的源代码,我希望读者可以自己下载来跟一下,因为最开头用了大量的篇幅来跟踪了 set 指令的整个流程,相信验证其他几个特性去找源码,也相对没有那么恐怖了。
下载不到源码,或者编译源码有问题,或者不知道从何处入手源码的童鞋,可以公众号后台与我交流哦~
总结
敲重点敲重点,课代表来啦~
一次 set 的请求流程堆栈
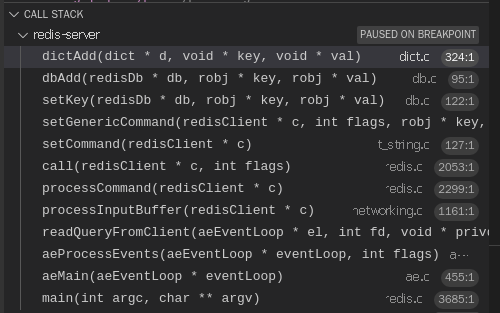
建立 socket 链接 --> 建立 client --> 注册 socket 读取事件处理器 --> 从 socket 读数据到缓冲区 --> 获取命令 --> 执行命令(字符串编码、写入字典)--> 响应
数值型字符串一个小骚操作
在选择整型返回的时候,不是直接转换为一个 long 类型,而是先看看这个数值大不大,如果不大的话,从常量池里面选一个返回这个引用,这和 Java Integer 常量池的思想差不多,由于业务上可能大部分用到的整型都没那么大,这么做至少可以节省好多空间。
字符串底层数据结构 SDS
字符串底层数据结构是 SDS,简单动态字符串
struct sdshdr {
unsigned int len;
unsigned int free;
char buf[];
};
优点如下:
常数时间复杂度计算长度:可以通过 len 直接获取到字符串的长度,而不需要遍历 二进制安全:由于是以 len 来表示长度,而不是通过字符串结尾标识来判断,所以可以用来存储原封不动的二进制数据而不用担心被截断 空间预分配:在字符串变长时,每次多分配一些空间,以便下次变长时可能由于 buf 足够大而不用重新分配 惰性空间释放:在字符串变短时,并不立即重新分配内存而回收缩短后多出来的字符串,而是用 free 来记录这些空闲出来的字节,这又减少了内存分配的次数。
字符串操作指令
这个我就直接 copy 网上的了
SET key value:设置指定 key 的值 GET key:获取指定 key 的值。 GETRANGE key start end:返回 key 中字符串值的子字符 GETSET key value:将给定 key 的值设为 value ,并返回 key 的旧值(old value)。 GETBIT key offset:对 key 所储存的字符串值,获取指定偏移量上的位(bit)。 MGET key1 [key2..]:获取所有(一个或多个)给定 key 的值。 SETBIT key offset value:对 key 所储存的字符串值,设置或清除指定偏移量上的位(bit)。 SETEX key seconds value:将值 value 关联到 key ,并将 key 的过期时间设为 seconds (以秒为单位)。 SETNX key value:只有在 key 不存在时设置 key 的值。 SETRANGE key offset value:用 value 参数覆写给定 key 所储存的字符串值,从偏移量 offset 开始。 STRLEN key:返回 key 所储存的字符串值的长度。 MSET key value [key value ...]:同时设置一个或多个 key-value 对。 MSETNX key value [key value ...]:同时设置一个或多个 key-value 对,当且仅当所有给定 key 都不存在。 PSETEX key milliseconds value:这个命令和 SETEX 命令相似,但它以毫秒为单位设置 key 的生存时间,而不是像 SETEX 命令那样,以秒为单位。 INCR key:将 key 中储存的数字值增一。 INCRBY key increment:将 key 所储存的值加上给定的增量值(increment) 。 INCRBYFLOAT key increment:将 key 所储存的值加上给定的浮点增量值(increment) 。 DECR key:将 key 中储存的数字值减一。 DECRBY key decrement:key 所储存的值减去给定的减量值(decrement) 。 APPEND key value:如果 key 已经存在并且是一个字符串, APPEND 命令将指定的 value 追加到该 key 原来值(value)的末尾。