
美团 Flink 大作业部署与状态稳定性优化实践
一、相关背景

美团 Flink 的应用场景覆盖了社区定义的三种场景:
应用比较多的是数据管道场景,比如数仓 ODS 层数据的实时接入,或跨数据源的实时数据同步; 比较典型的应用场景是数据分析,比如实时数仓的建设和应用,业务会出一些实时报表和大盘辅助业务做决策,或者计算一些实时特征服务于业务生产; 事件驱动场景,目前主要应用于安全风控、系统监控告警。


二、大作业部署优化

我们当前的大作业算子并发达到了 5000,拓扑复杂度上算子数量达到了 8000,有两层的数据 shuffle 交换,资源上作业需要超过 1000 个 TaskManager,在这样的规模下,我们遇到了一些之前没有遇到过的问题。
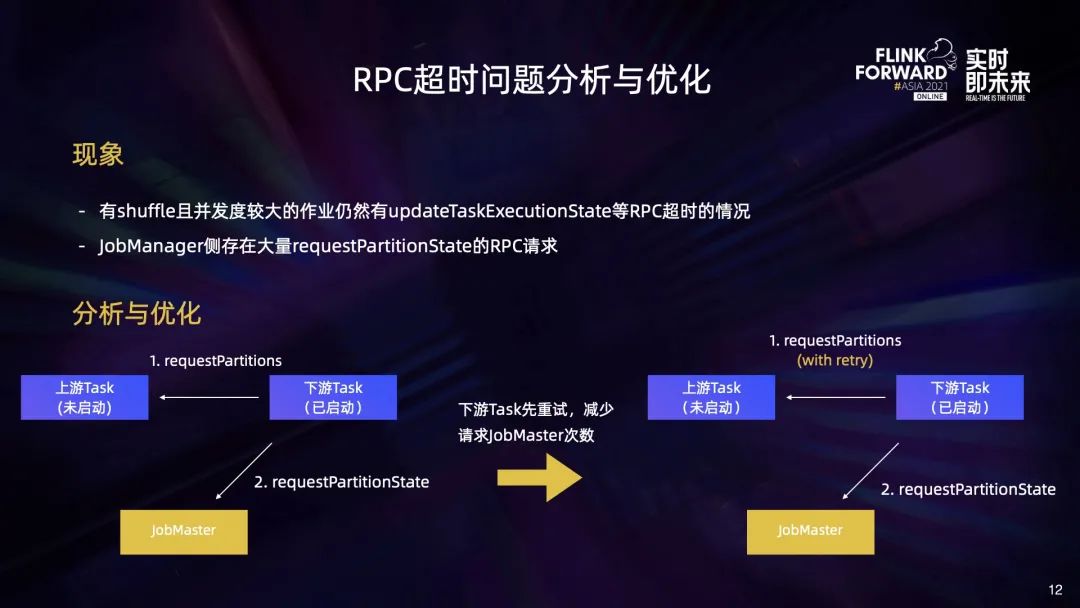
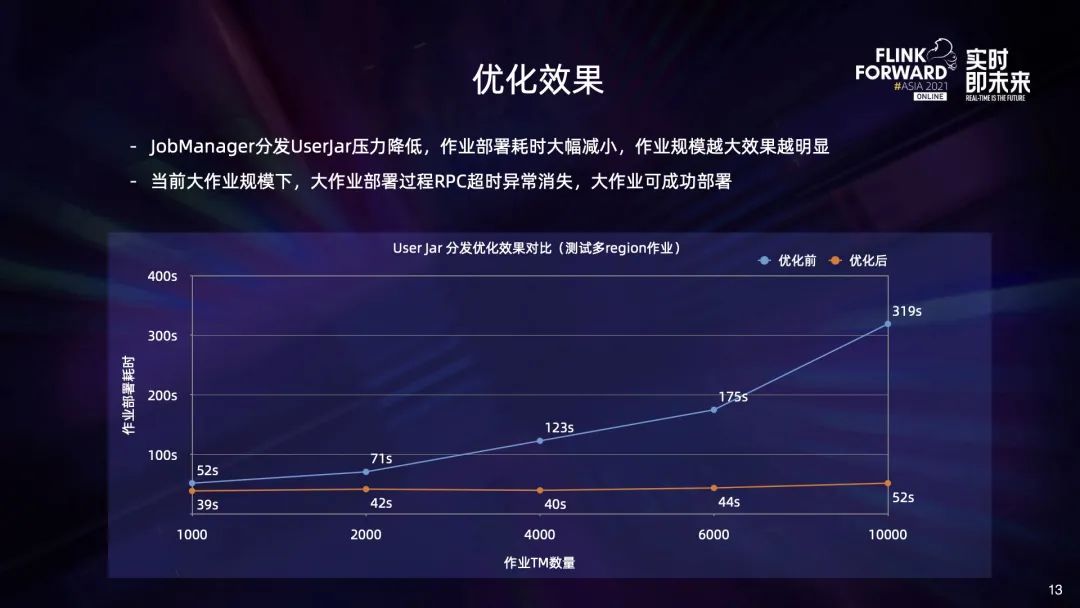
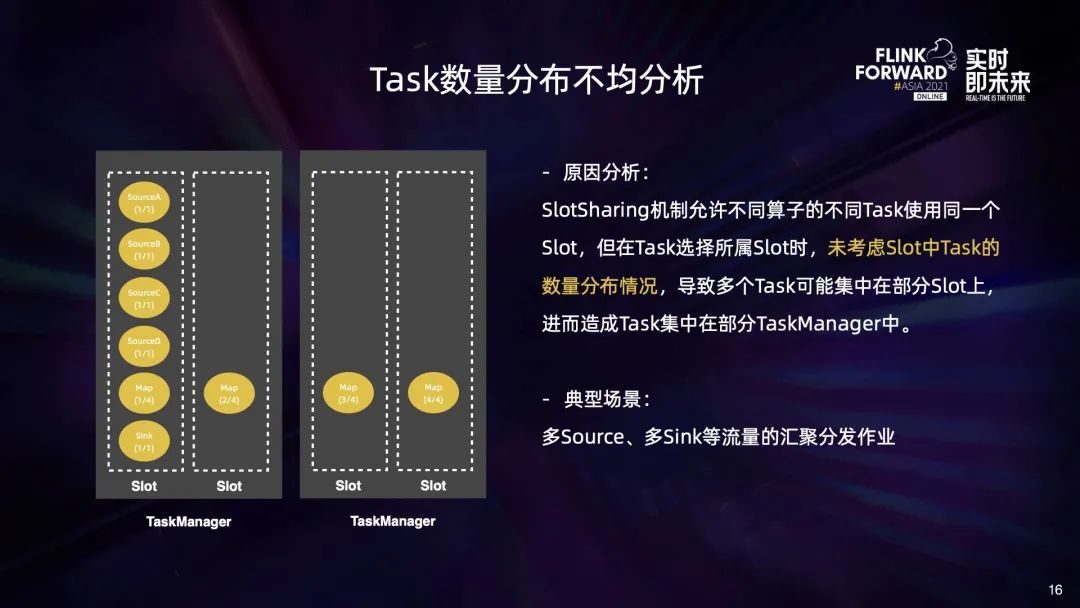
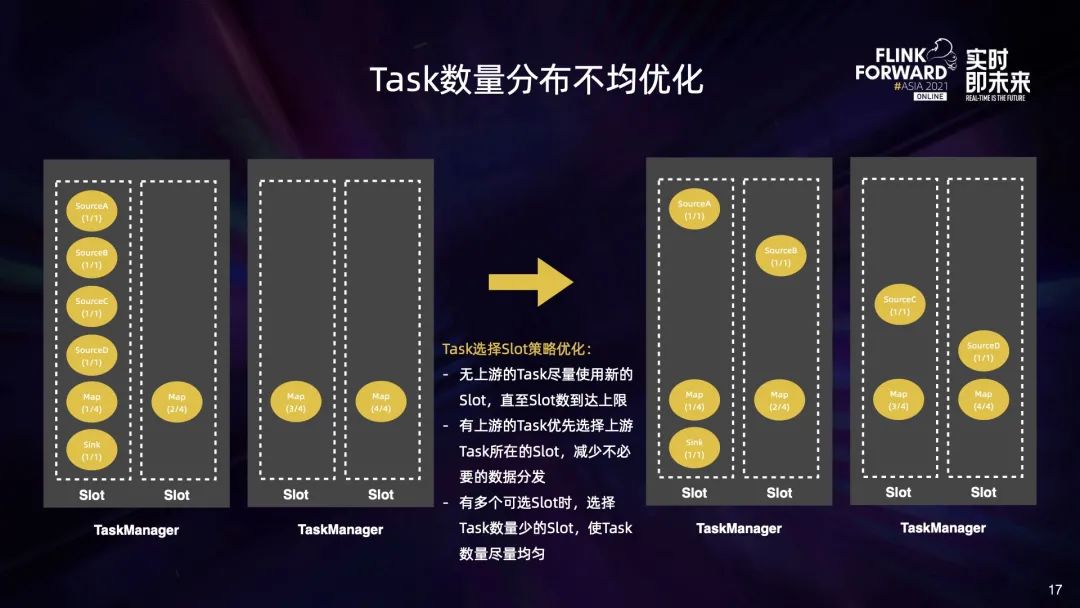
首先,部署大量 Task 的时候会遇到部署时间长或因为 RPC 超时而部署失败的问题; 此外,Task 分布不够合理,部分 TaskManager 中 Network Buffer 的数量不足,会导致作业启动失败; 另外,大作业做 Checkpoint 期间,会给 HDFS 带来瞬时压力,也会影响其他作业使用 HDFS。
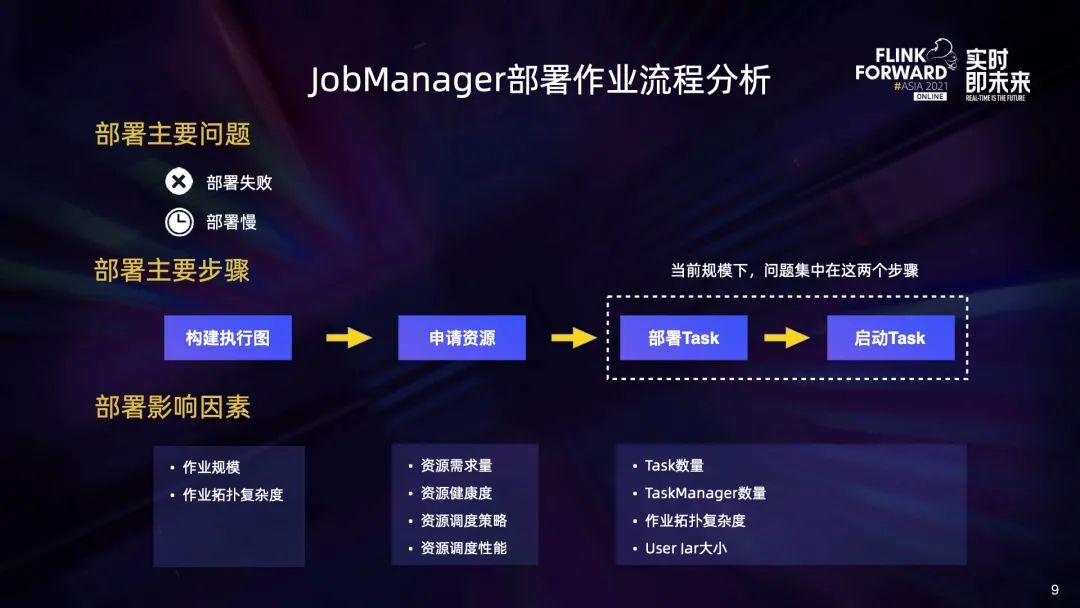
可以看到,从收到 JobGraph 到启动所有 Task,主要环节有构建执行图、申请资源、部署 Task、启动 Task 这几个步骤。
构建执行图环节主要受作业规模和拓扑复杂度的影响。当前构建执行图的时间复杂度比较高,构建大作业执行图的时候,耗时会大幅增加,不过我们当前的规模暂时还没有遇到这个问题,而且社区在 1.13 版本已经对这一问题做了一系列优化,可以参考借鉴。 资源申请环节主要受资源的需求量、资源健康度、调度性能、调度策略的影响,通常可能会遇到资源不足、资源碎片、调度到坏节点等问题,导致作业无法正常启动,但这些问题目前还不是很严重。 部署和启动 Task 环节主要受 Task 数量、TaskManager 数量、拓扑复杂度、user jar 大小的影响。作业规模很大的时候,JobManager 作为一个 master 节点,可能会遇到一些处理瓶颈,就有可能出现 Task 部署慢或部署失败的情况。
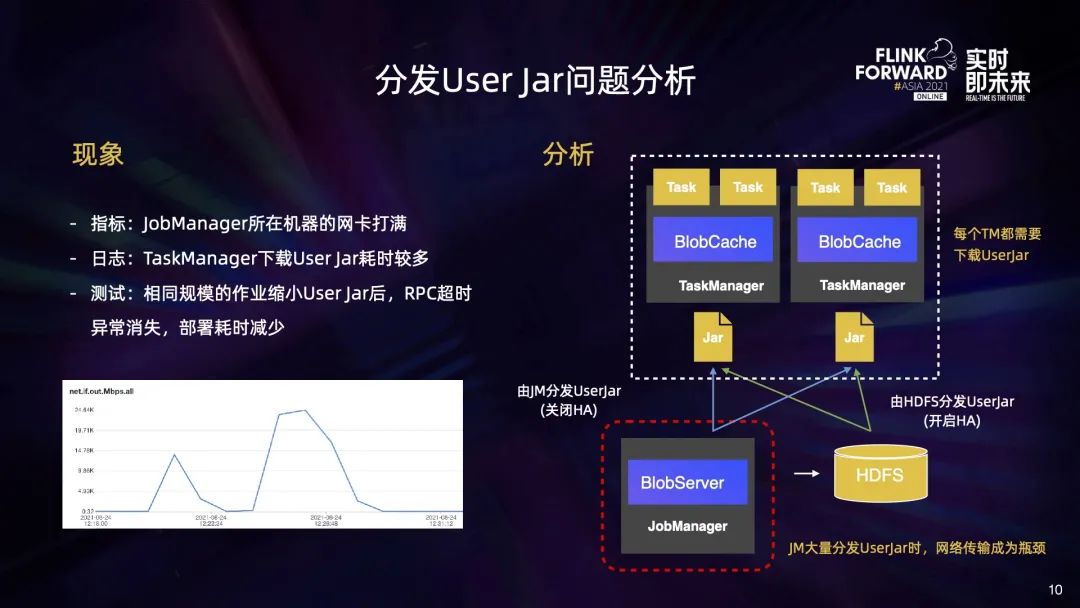

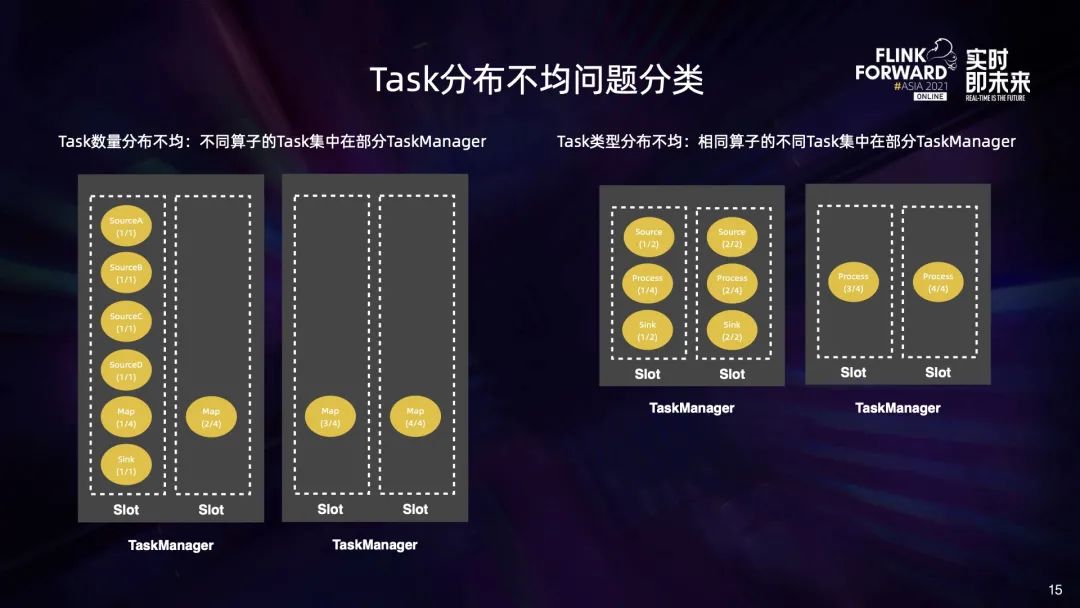
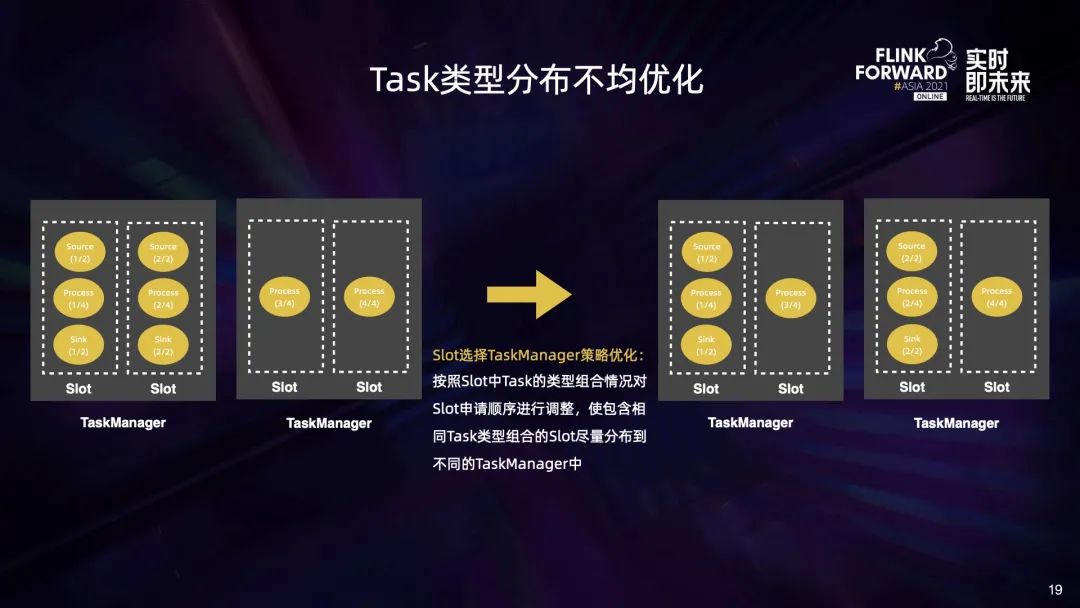
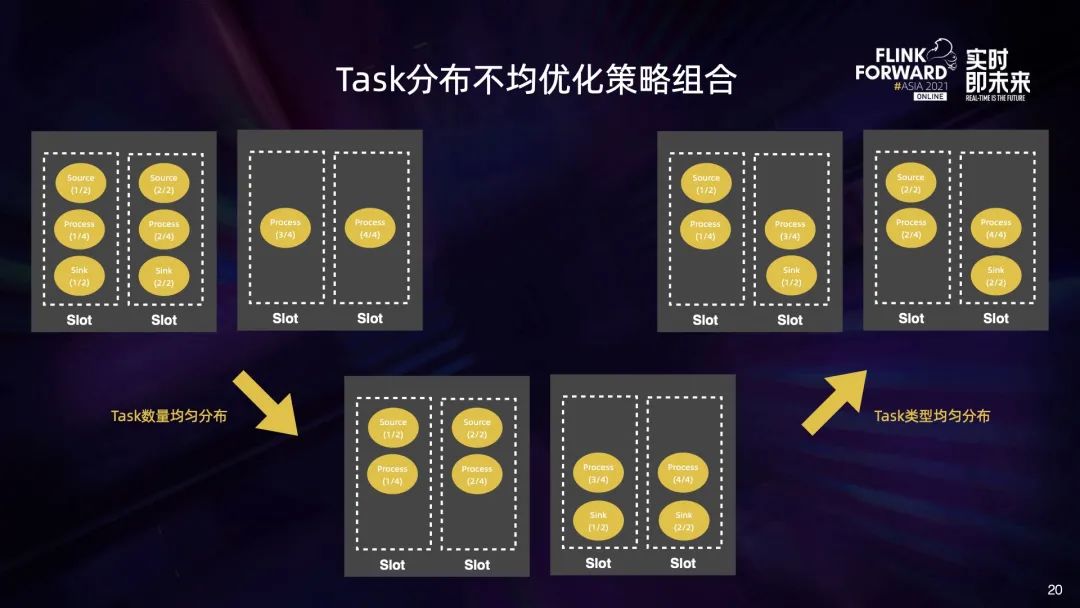
我们总结了两类 Task 分布不均的问题:
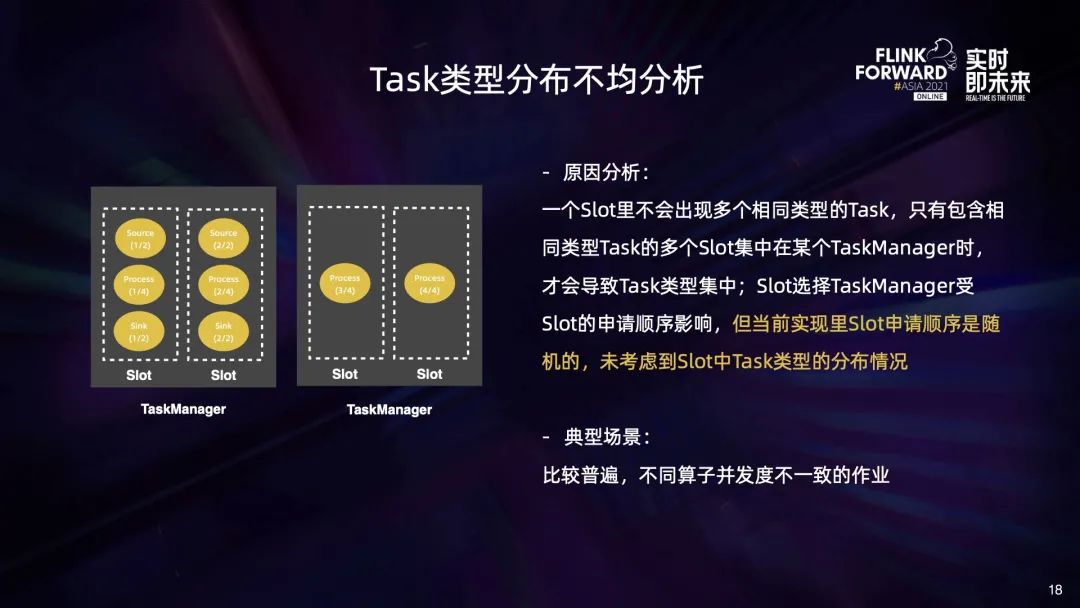
一类是 Task 数量分布不均,也就是不同算子的 Task 集中在同一个 TaskManager 中,例如左图中多种 source 算子集中在第一个 Task 里面; 另一类是 Task 类型分布不均,也就是相同算子的不同 Task 集中在一个 TaskManager 中,例如右图中 source 的两个 Task,sink 的两个 Task 都集中在第一个 TaskManager 中。
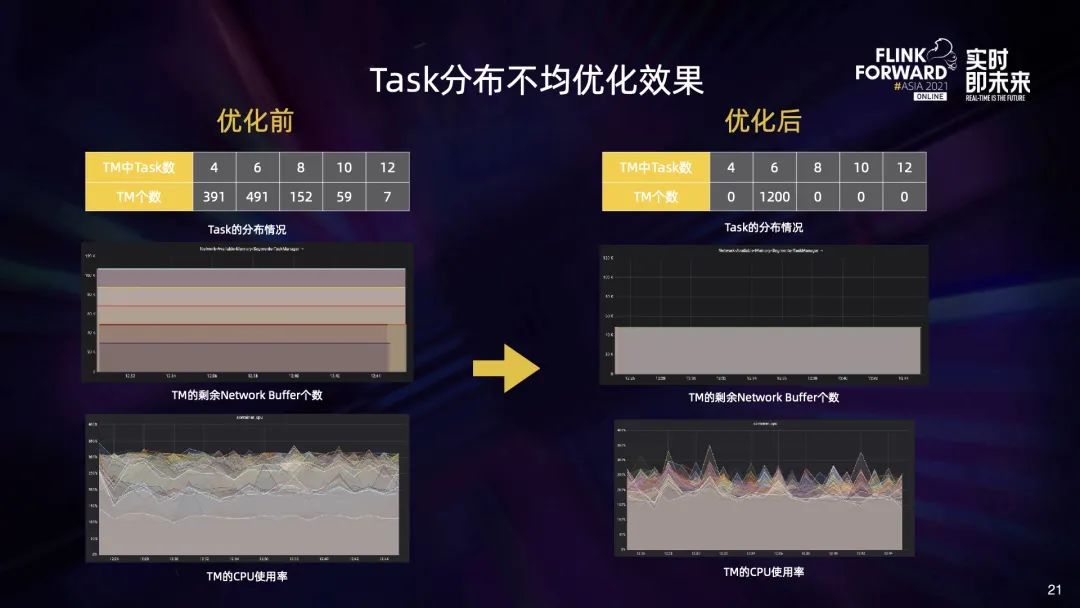
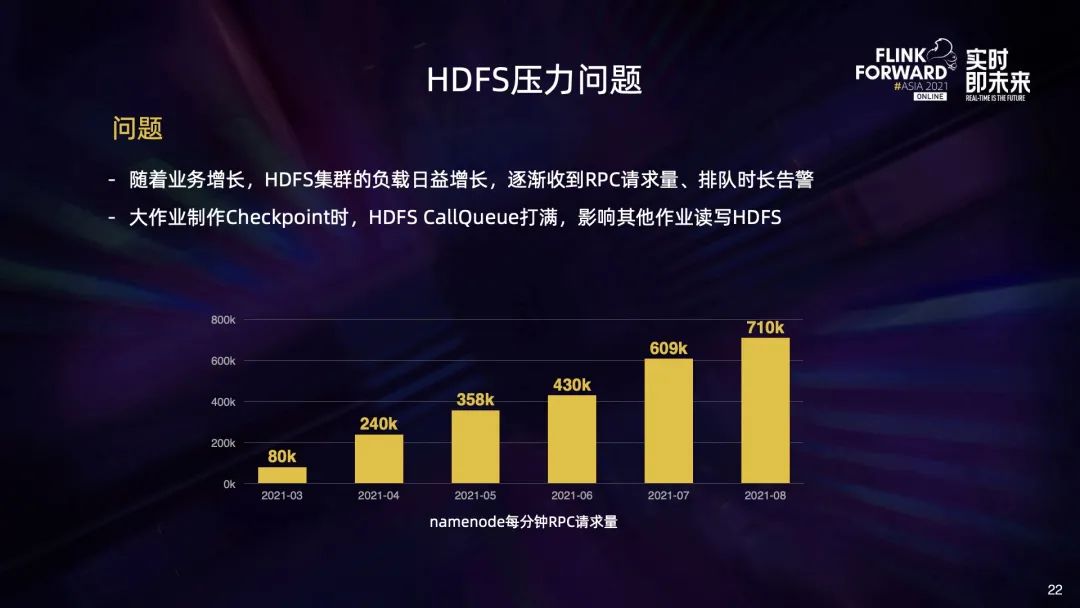
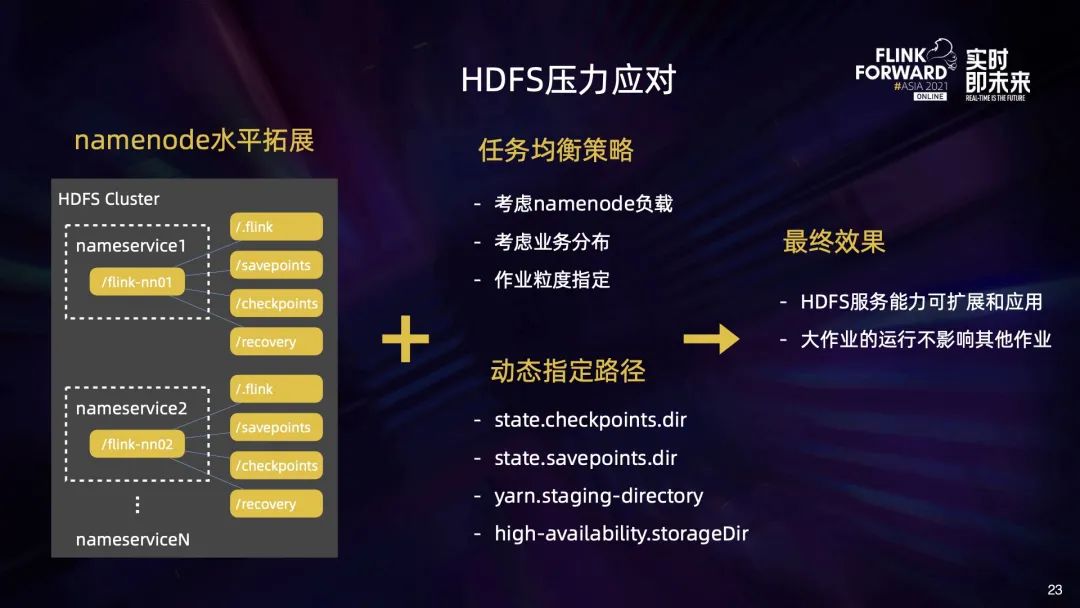
最后我们再来看下 HDFS 的压力问题。导致 HDFS 压力的原因有两个:
一个是随着业务的正常增长,HDFS 的负载也在逐步增大; 另一方面大作业的部署上线也给 HDFS 带来了更大的瞬时压力,大作业在制作 Checkpoint 期间会给 HDFS 带来大量的 RPC 请求,造成 RPC CallQuque 打满,影响其他作业读写 HDFS。

三、Checkpoint 跨机房副本


从上述背景中我们可以提炼出两个目标:
第一是所有作业都需要支持换机房从 Checkpoint 启动,这就需要在作业换机房启动前,将原机房的 Checkpoint 复制到目标机房; 第二是关键作业的 Checkpoint 需要支持跨机房容灾,这就意味着需要随着 Checkpoint 的不断完成,实时地将新产生的 Checkpoint 复制到备份机房,以防止原机房突然故障。
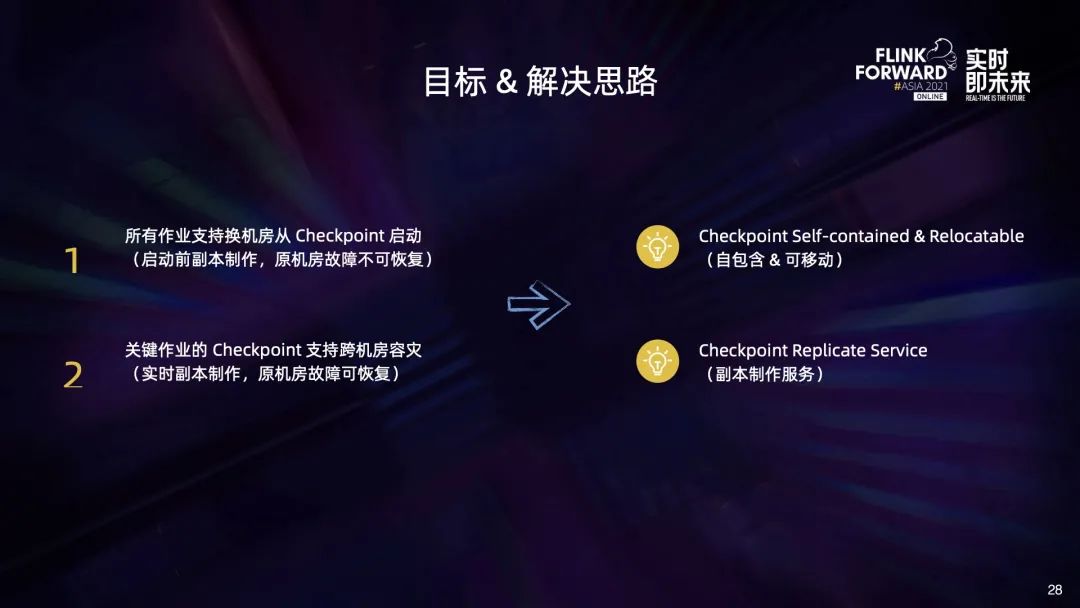
通过分析,我们需要分两步来完成上述目标。
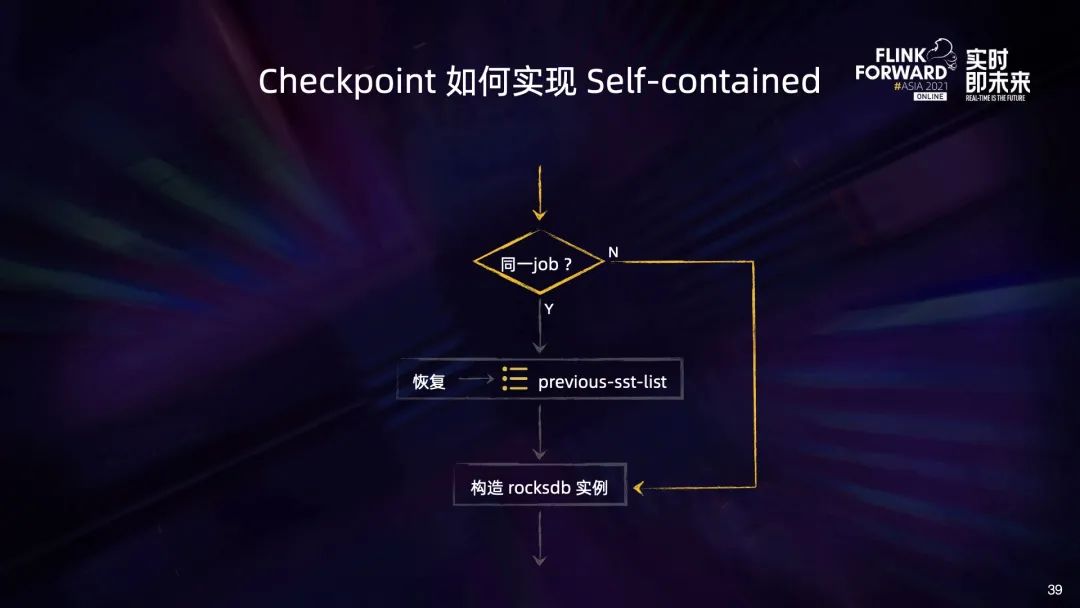
首先需要改造 Flink 引擎,使得 Checkpoint 满足 self-contained & relocatable 的条件,具体的概念和原理会在后面进行详细的介绍,现在可以先简单理解成只有满足这个条件,Checkpoint 的副本才是可用的,否则 Checkpoint 复制到其他地方也无法从副本 Checkpoint 上恢复作业; 其次需要实现 Checkpoint 副本制作的能力,即 Checkpoint Replicate Service。

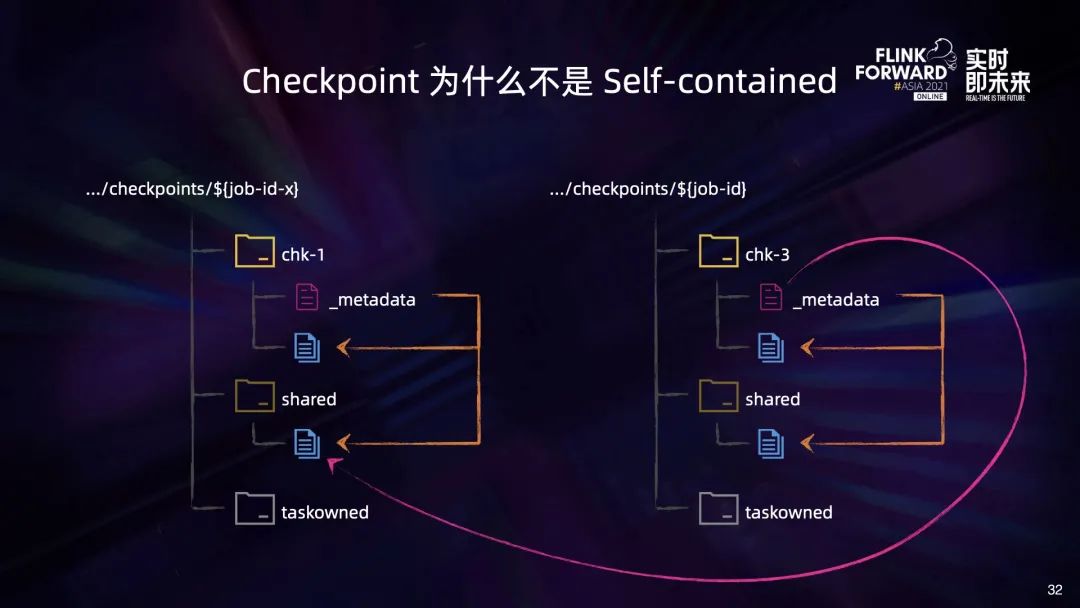
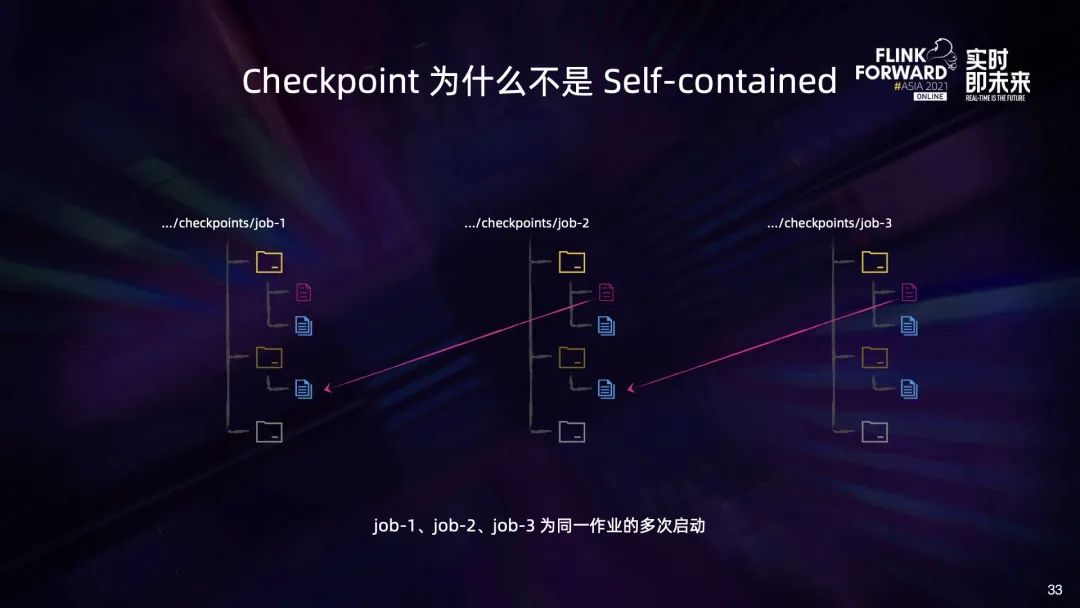

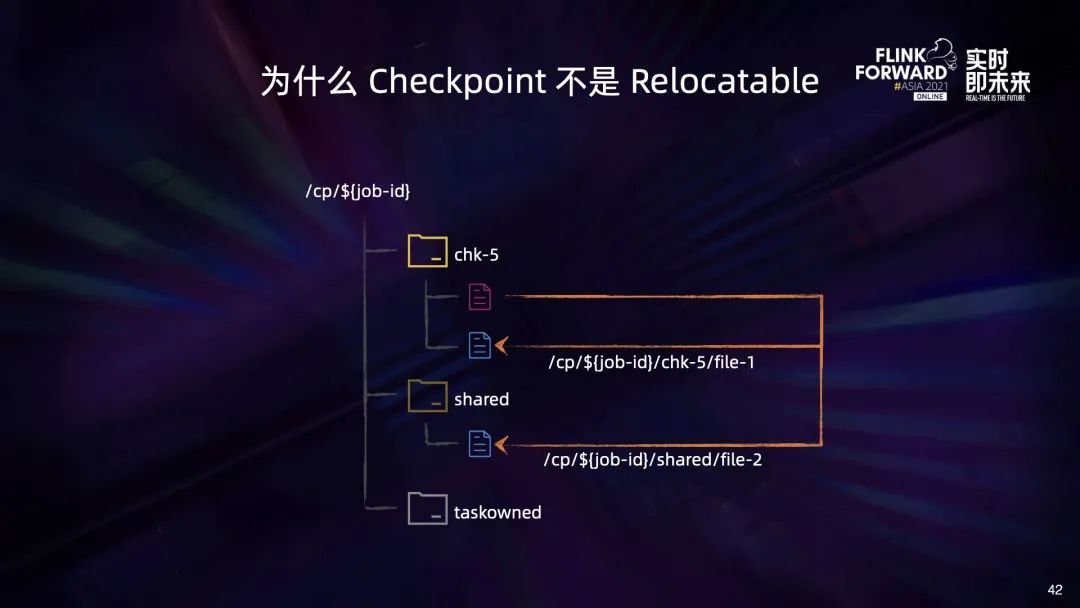
上述情况会带来两个问题:
第一,会导致 Retained Checkpoint 难以被清理。清理作业的 Retained Checkpoint 时要确保其中的文件不会再被其他 Checkpoint 引用,因此作业管理平台就需要维护 Checkpoint 中文件的引用计数,这无疑增加了平台管理的复杂度; 第二,会导致跨存储系统的 Checkpoint 副本不可用。比如我们将 Checkpoint 从 HDFS1 复制到 HDFS2 上之后,由于跨 job 实例引用的文件在 HDFS2 上面并不存在,会导致复制过去的 Checkpoint 不可用。当然我们也可以通过将所有被直接和间接引用的文件都复制到 HDFS2 上来避免这个问题,但这会极大增加副本制作的复杂度。

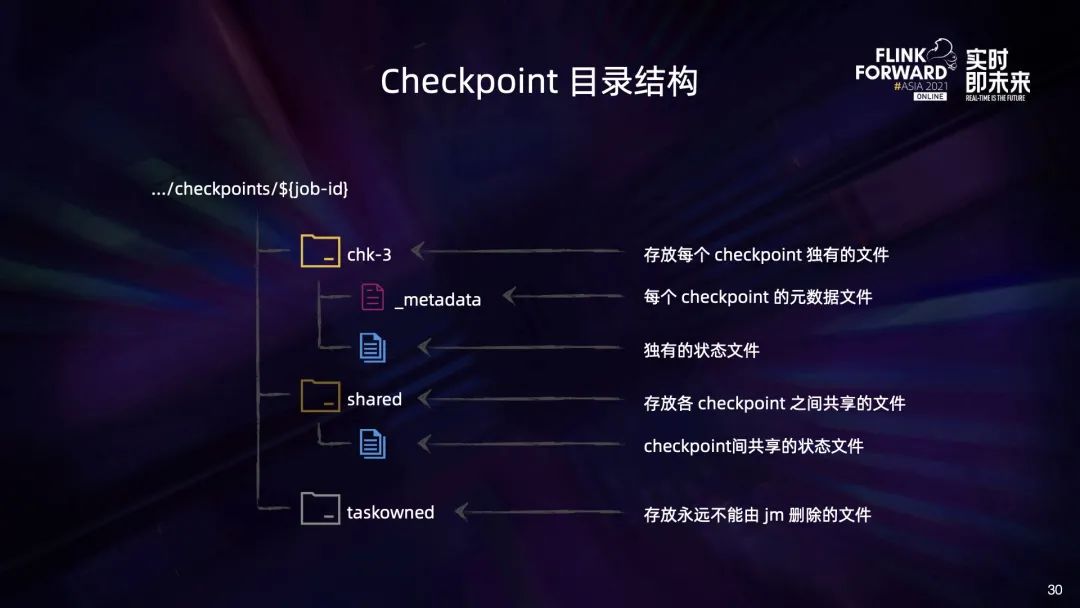
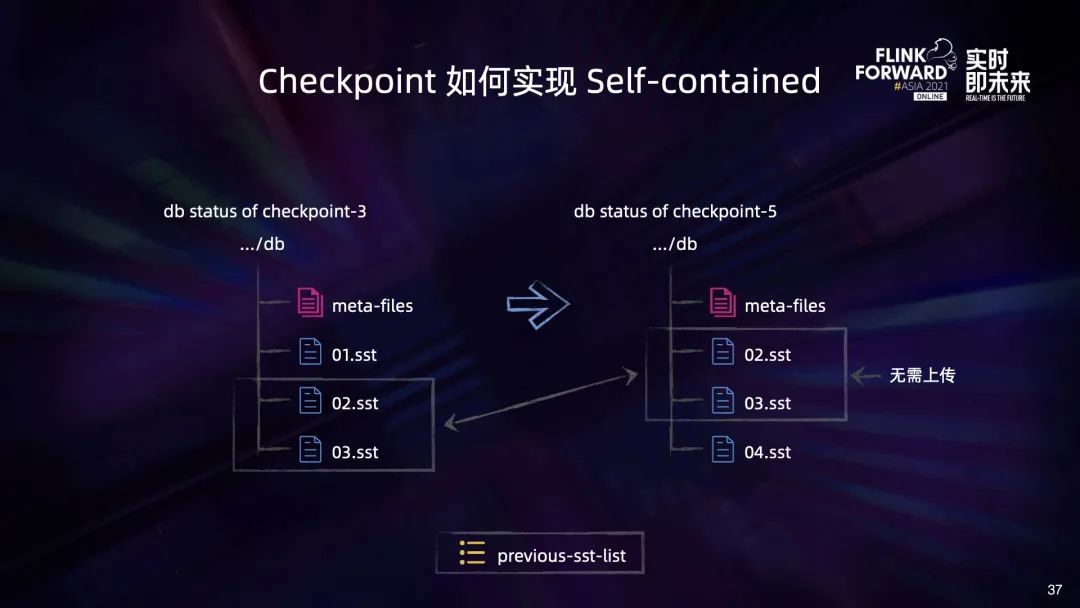
RocksDB 是一个基于 LSM Tree 的 KV 存储引擎,它会将持久化数据写到磁盘文件中。上图是一个 RocksDB 实例的文件目录结构,可以分为两类:
第一类是各种元数据比如 DB 的配置、version changelog 等,这类文件可能会在运行过程中不断被更新; 另一类是 SST 文件,这是 RocksDB 的数据文件,里面包含数据内容、索引等。这类文件一旦产生就不会再修改,只会随着数据的不断写入和 compassion 而不断地产生和删除。

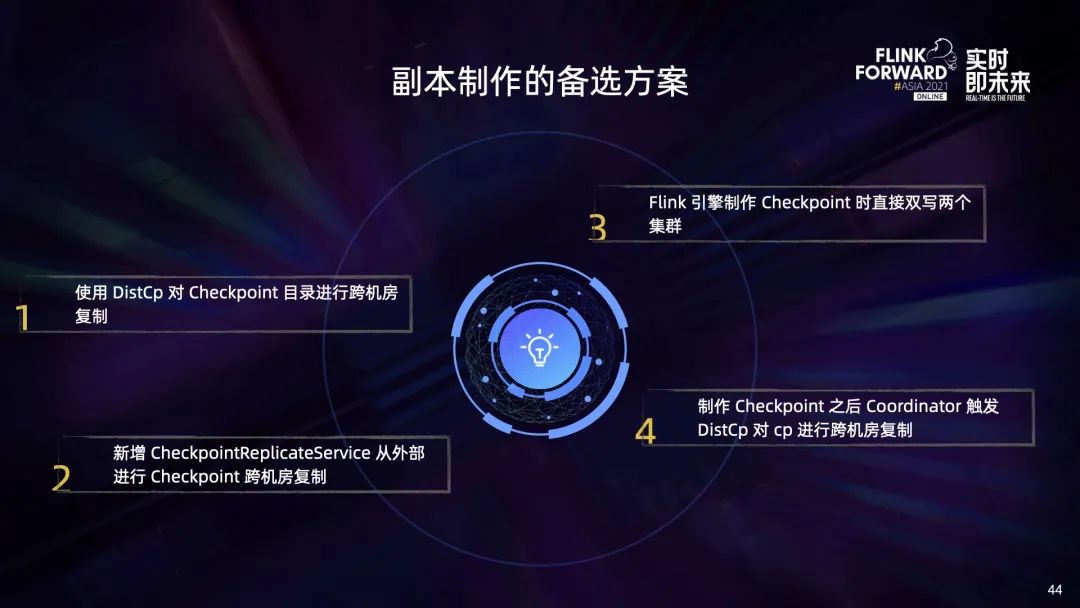
最初在评估如何完成副本跨机房制作能力的时候,有几个备选方案:
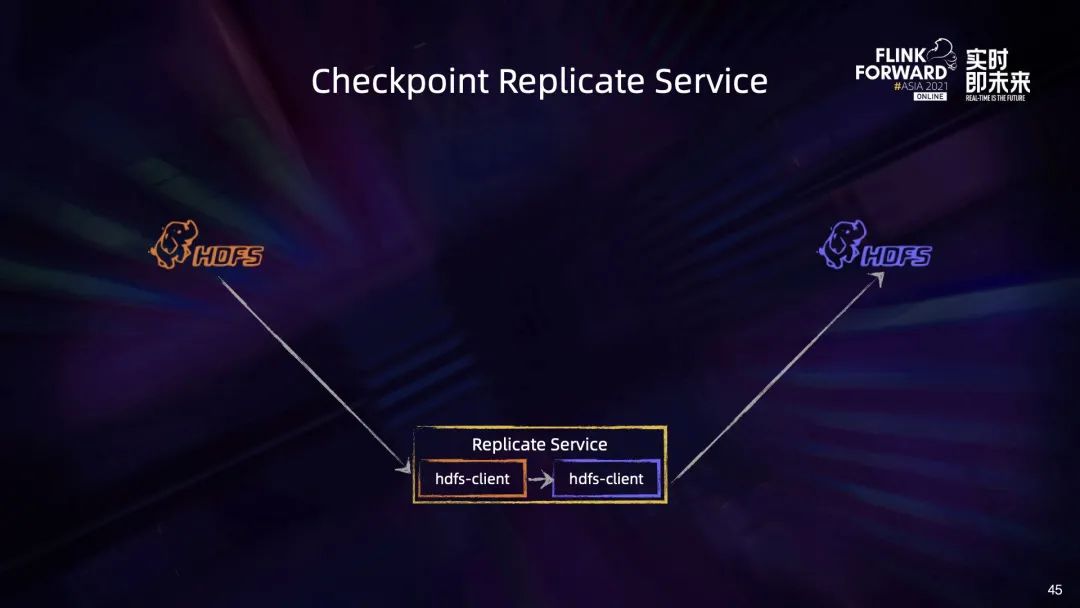
第一就是像支持 Savepoint 副本制作一样,通过 distcp 对整个 Checkpoint 目录进行跨机房复制,这种方式在复制 Savepoint 时工作良好。但由于 distcp 的每个复制任务都会启动一个很重的 mapreduce 作业,而 Checkpoint 又比 Savepoint 频繁得多,而且 distcp 过程中作业还在运行,可能会不断有文件在复制过程中被删除,虽然可以配置为忽略,但也会导致一些其他问题,因此不太合适; 第二就是编写一个 Checkpoint Replicate Service,连接多个 HDFS 集群,专门用于 Checkpoint 的副本制作,这也是我们最后选择的方式; 第三是通过改造 Flink 引擎,在制作 Checkpoint 时直接将数据双写到两个 HDFS 集群上,但是这种方式无疑会给引擎增加不稳定的因素,不能为了应对小概率的机房故障而放弃作业运行的稳定性和效率; 最后就是改造 Flink 的 Checkpoint coordinator,使其在制作 Checkpoint 完成后触发一次 distcp,在 distcp 完成前不触发后续的 Checkpoint 制作。这种方式可以避免方案 1 中提到的 distcp 复制过程中文件变动的问题,但也是由于 distcp 效率原因而被放弃。
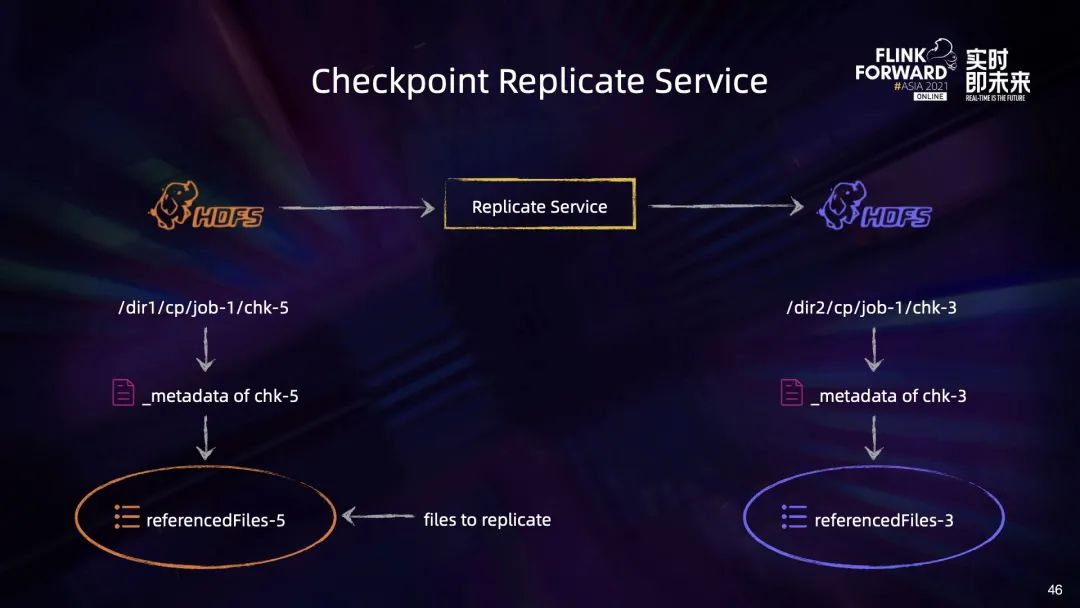
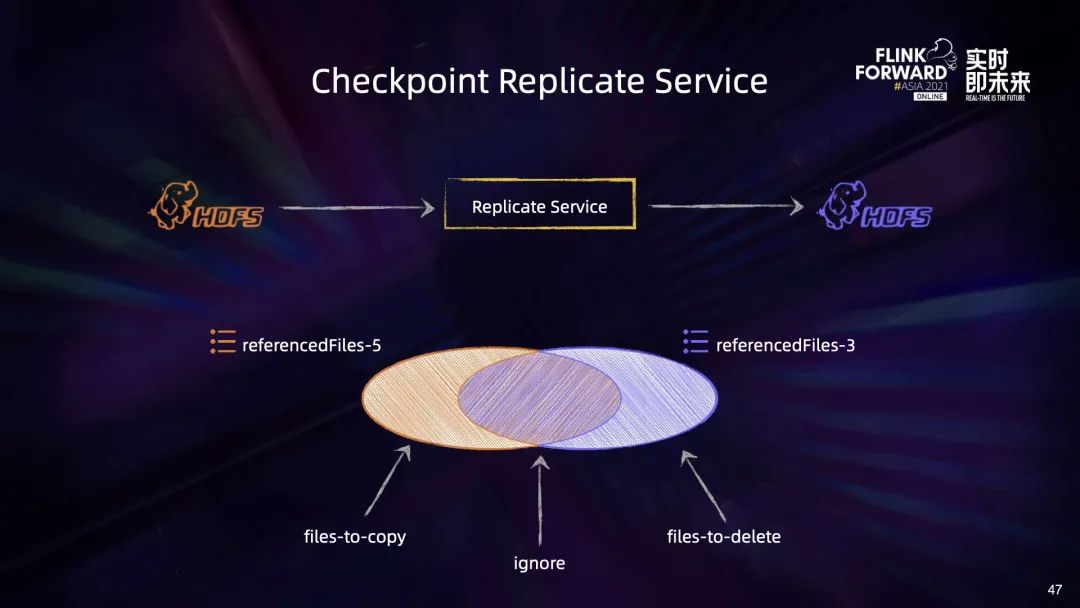
第一部分,只存在于 Checkpoint5 中的文件是新增的文件,需要复制到目标集群中去; 第二部分,只存在于 Checkpoint3 中的文件是在新 Checkpoint 过程中被删除的,由于副本集群只需要保留最新的 Checkpoint3,这部分文件会被直接删除; 最后是相交的部分,这些文件虽然被 Checkpoint5 所需要,但已经被上传过了,因此可以忽略。通过这种方式,我们就能像 Checkpoint 增量制作一样去进行增量的副本制作。

我们在实际工程实践上也获得了不少的经验:
第一点是需要改造 Flink 引擎的 metadata 解析过程。当前的实现会在解析过程中去访问 metadata 文件所在的 HDFS,由于使用的不是我们指定的 HDFS client,可能就会因 metadata 文件所在集群不是副本服务默认连接的集群而导致解析失败。但其实这个访问不是必须的,因此我们在解析服务中将这个访问直接移除; 第二点是考虑缓存 metadata 的解析结果。生产上的大状态作业,一个 metadata 可能有几十 M (甚至几个 G),引用文件会达到几十万个,解析时间可能需要分钟级别,而增量制作副本时会有多次解析同一个 metadata,因此可以考虑把解析结果缓存起来; 第三点是引用文件的复制和删除可以拆分成多个批次发送到多个节点上并行执行。这是因为大状态的作业一个 Checkpoint 复制的文件量可能就达到了 10TB+,很容易达到一台机器的网络瓶颈。
首先是运行中的作业副本制作失败时不需要进行重试,主要是考虑到运行中的作业会不断有更新的 Checkpoint 产生,新 Checkpoint 复制成功的意义要大于旧 Checkpoint 的复制; 此外,files-to-delete 的执行可以异步进行,即使失败了也只是多一些无用的文件残留,不影响副本的可用;只要保证最终有兜底策略进行清理就行。
四、状态稳定性相关其他优化
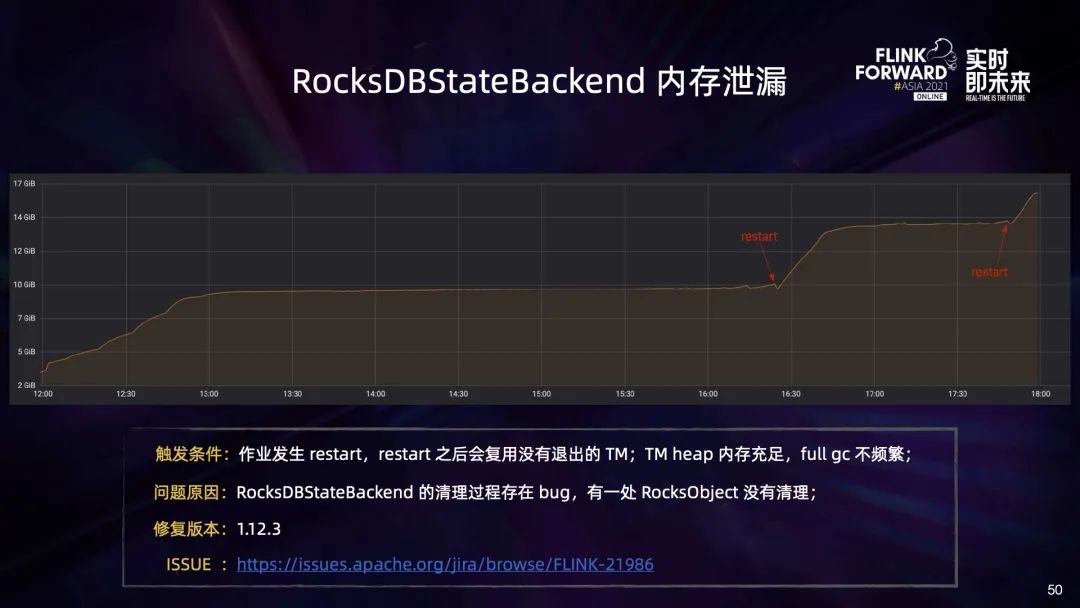
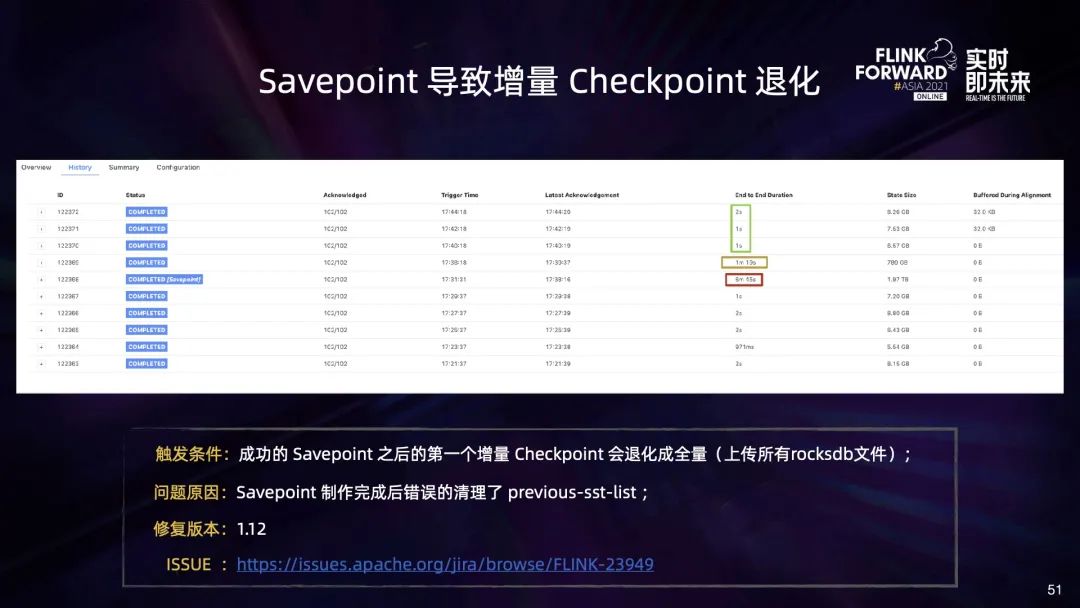
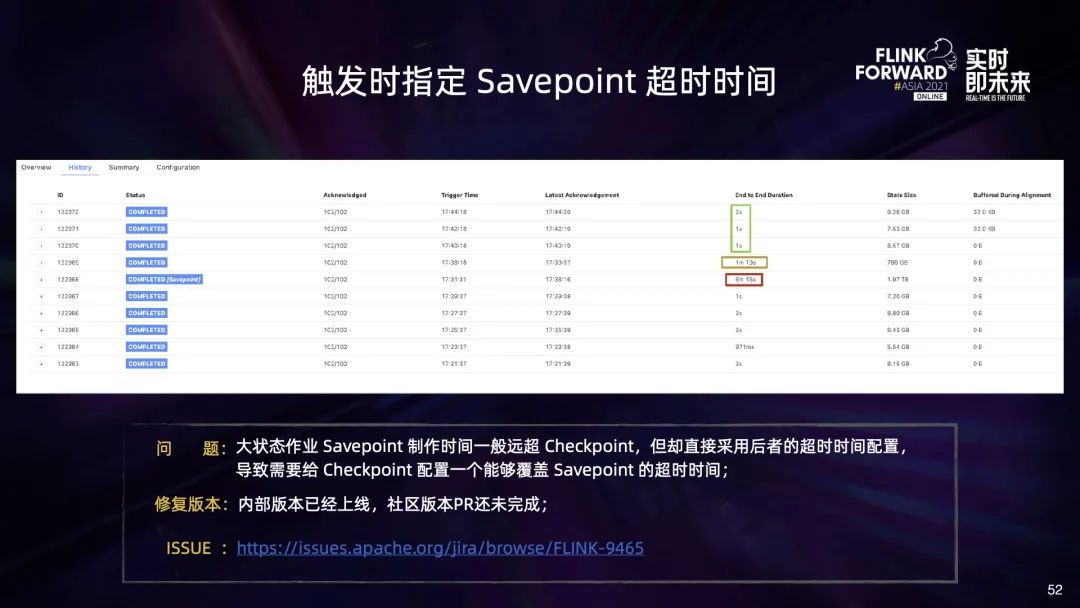
五、未来规划

未来,我们会在以下三个方面继续做改进和稳定性建设:
稳定性方面,我们会继续优化作业的断流时间,提升作业稳定性,探索 k8s 来获取更好的资源隔离和资源扩缩容能力。 运行性能方面,我们会对状态后端做优化来支持大状态作业更好地运行,并对反压做优化让作业在高峰和恢复期运行得更好。 最后在资源效率方面,我们会对作业的资源利用率进行评估和优化,来节省资源和人力成本。
评论