
Label Smoothing分析
共 2362字,需浏览 5分钟
·
2020-12-08 13:52
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
导读
Label Smoothing在图像识别中能稳定涨点,但在人脸的loss里加上Label Smoothing却是掉点的,本文作者详细分析了该方法的问题,Label Smoothing起到的作用实际上是抑制了feature norm,此时只能控制角度,起到反向优化的作用,因此在人脸loss上加Label Smoothing效果会变差。
有挺多人问过我一个问题:Label Smoothing在图像识别中能稳定涨点,在人脸的loss里加上Label Smoothing是否有用呢?
我挺早之前就注意到了这件事,当时也做了实验,发现直接应用在人脸相关的loss上,是掉点的。其实DL发展到现在,可以说如果你想到了一个非常简单的排列组合式idea,而经过survey没见过别人这么做,那大概率这个方法是不work的...
但这事到这当然不算完,我们得分析一下它为啥不work。
要引出Label Smoothing,首先我们要知道,Softmax Cross Entropy不仅可以做分类任务(目标为one-hot label),还可以做回归任务(目标为soft label)。设网络输出的softmax prob为p,soft label为q,那Softmax Cross Entropy定义为:

而Label Smoothing虽然仍是做分类任务,但其目标q从one-hot label变为soft label了,原来是1的位置变为  ,其他的原来是0的位置变为
,其他的原来是0的位置变为  ,
,  通常取0.1。
通常取0.1。
假设一个6分类任务,之前的  就变成了
就变成了  ,直观上看,这个目标还是很奇怪的,如果一个样本网络非常确认其类别,给了个0.99的置信度,难道经过Label Smoothing,还要反向优化不成?
,直观上看,这个目标还是很奇怪的,如果一个样本网络非常确认其类别,给了个0.99的置信度,难道经过Label Smoothing,还要反向优化不成?
这个问题其实在概率层面上是没法解释的,从概率上看,确实会有发生反向优化的情况,但为什么这样可以涨点呢?
看看Hinton组对Label Smoothing的分析文章[1],里面有一张图比较有意思:
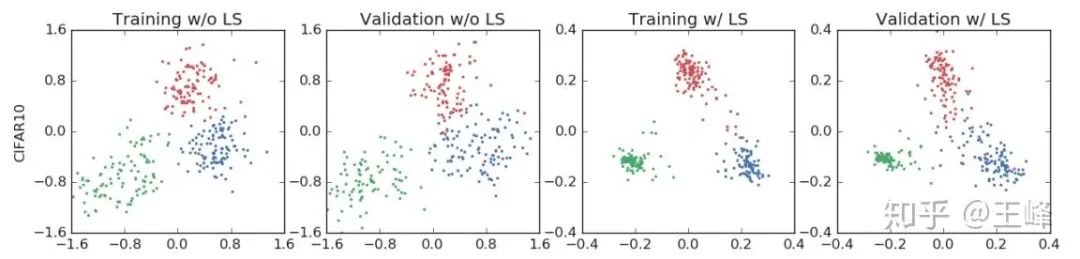
熟悉人脸识别loss的人会发现,这个Label Smoothing得到的特征分布,怎么跟人脸loss的效果这么像?竟然都可以起到让每个类别的样本聚拢的效果。
而少数细心的朋友可能会发现这里的玄机:不做Label Smoothing(标注为w/o LS)的feature norm,普遍比做了LS(标注为w/ LS)的要大很多!w/o LS时最大可以达到1.6,而w/ LS时只有0.4。
回顾之前的文章,减小feature norm实际上等效于降低s,较低的s会使softmax prob的最大值降低,如下图所示(来自于zhuanlan.zhihu.com/p/52 ):
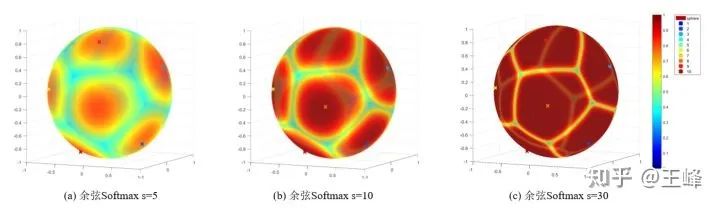
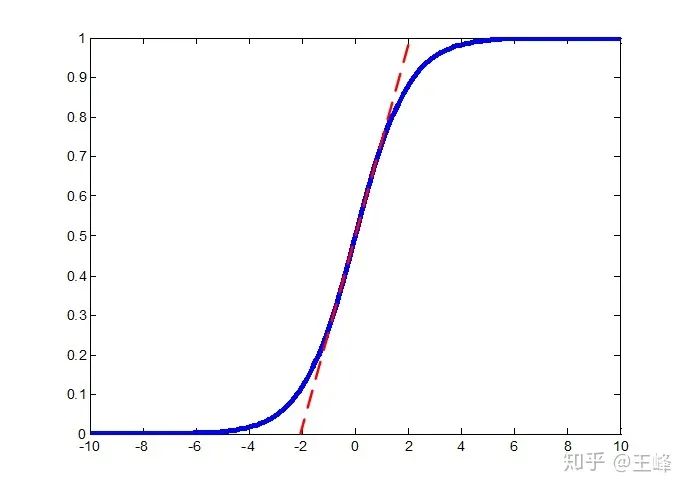
 后,我们只会用到sigmoid曲线上中间的一段,平缓的区域基本上不存在了,样本的移动几乎永不终止,因此特征会比不加LS更加聚拢。
后,我们只会用到sigmoid曲线上中间的一段,平缓的区域基本上不存在了,样本的移动几乎永不终止,因此特征会比不加LS更加聚拢。 ,loss曲面上不再存在平缓区域,处处都有较大的梯度指向各个类中心,所以特征会更加聚拢。而之所以人脸上不work,是因为我们通常会使用固定的s,此时Label Smoothing无法控制feature norm,只能控制角度,就会起到反向优化的作用,因此在人脸loss上加Label Smoothing效果会变差。
,loss曲面上不再存在平缓区域,处处都有较大的梯度指向各个类中心,所以特征会更加聚拢。而之所以人脸上不work,是因为我们通常会使用固定的s,此时Label Smoothing无法控制feature norm,只能控制角度,就会起到反向优化的作用,因此在人脸loss上加Label Smoothing效果会变差。参考
When Does Label Smoothing Help? https://arxiv.org/pdf/1906.02629.pdf
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:leetcode 开源书
在「AI算法与图像处理」公众号后台回复:leetcode,即可下载。每题都 runtime beats 100% 的开源好书,你值得拥有!
下载3 CVPR2020 在「AI算法与图像处理」公众号后台回复:CVPR2020,即可下载1467篇CVPR 2020论文 个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称

觉得不错就点亮在看吧
