
rollup - 构建原理及简易实现
黄丹丹,微医前端技术部医疗支撑组。一个资深猫奴,爱静亦爱动无痕切换的精分程序媛。
一、Rollup 概述
官网地址:https://rollupjs.org/guide/en/
Rollup 是什么
我们先看看 Rollup 的作者 Rich Harris 是怎么讲的?Rollup 是一个模块化的打包工具。本质上,它会合并 JavaScript 文件。而且你不需要去手动指定它们的顺序,或者去担心文件之间的变量名冲突。它的内部实现会比说的复杂一点,但是它就是这么做的 —— 合并。
对比 Webpack
webpack 对前端来说是再熟悉不过的工具了,它提供了强大的功能来构建前端的资源,包括 html/js/ts/css/less/scss ... 等语言脚本,也包括 images/fonts ... 等二进制文件。正是因为 webpack 拥有如此强大的功能,所以 webpack 在进行资源打包的时候,就会产生很多冗余的代码(如果你有查看过 webpack 的 bundle 文件,便会发现)。
而对于一些项目(特别是类库)只有 js,而没有其他的静态资源文件,使用 webpack 就有点大才小用了,因为 webpack bundle 文件的体积略大,运行略慢,可读性略低。这个时候就可以选择 Rollup
Rollup是一个模块打包器,支持 ES6 模块,支持 Tree-shaking,但不支持 webpack 的 code-splitting、模块热更新等,这意味着它更适合用来做类库项目的打包器而不是应用程序项目的打包器。
简单总结
对于应用适用于 webpack,对于类库更适用于 Rollup,react/vue/anngular 都在用Rollup作为打包工具
二、Rollup 前置知识
在阐述 Rollup 的构建原理之前,我们需要了解一些前置知识
magic-string
magic-string 是 Rollup 作者写的一个关于字符串操作的库,这个库主要是对字符串一些常用方法进行了封装
var MagicString = require('magic-string')
var magicString = new MagicString('export var name = "zhangsan"')
// 以下所有操作都是基于原生字符串
// 类似于截取字符串
console.log(magicString.snip(0, 6).toString()) // export
// 从开始到结束删除
console.log(magicString.remove(0, 7).toString()) // var name = "zhangsan"
// 多个模块,把他们打包在一个文件里,需要把很多文件的源代码合并在一起
let bundleString = new MagicString.Bundle();
bundleString.addSource({
content: 'console.log(hello)',
separator: '\n'
})
bundleString.addSource({
content: 'console.log(world)',
separator: '\n'
})
// // 原理类似
// let str = ''
// str += 'console.log(hello);\n'
// str += 'console.log(world);\n'
console.log(bundleString.toString())
// hello
// world
AST
通过 javascript parse 可以把代码转化为一颗抽象语法树 AST,这颗树定义了代码的结构,通过操纵这个树,我们可以精确的定位到声明语句、赋值语句、运算符语句等等,实现对代码的分析、优化、变更等操作 源代码:main.js
// main.js
import { a } from './a'
console.log(a)
转化为 AST 是长这样子的,如下:
{
"type": "Program", // 这个 AST 类型为 Program,表明是一个程序
"start": 0,
"end": 40,
"body": [ // body 是一个数组,每一条语句都对应 body 下的一个语句
{
"type": "ImportDeclaration", // 导入声明类型
"start": 0,
"end": 23,
"specifiers": [
{
"type": "ImportSpecifier",
"start": 9,
"end": 10,
"imported": {
"type": "Identifier",
"start": 9,
"end": 10,
"name": "a" // 导入模块命名 name 'a'
},
"local": {
"type": "Identifier",
"start": 9,
"end": 10,
"name": "a" // 本地模块命名,同 imported.name
}
}
],
"source": {
"type": "Literal",
"start": 18,
"end": 23,
"value": "./a", // 导入路径 './a'
"raw": "'./a'"
}
},
{
"type": "ExpressionStatement", // 表达式类型
"start": 24,
"end": 38,
"expression": {
"type": "CallExpression", // 调用表达式类型
"start": 24,
"end": 38,
"callee": {
"type": "MemberExpression",
"start": 24,
"end": 35,
"object": {
"type": "Identifier",
"start": 24,
"end": 31,
"name": "console"
},
"property": {
"type": "Identifier",
"start": 32,
"end": 35,
"name": "log"
},
"computed": false,
"optional": false
},
"arguments": [
{
"type": "Identifier",
"start": 36,
"end": 37,
"name": "a"
}
],
"optional": false
}
}
],
"sourceType": "module"
}
AST 工作流
Parse(解析)将代码转化成抽象语法树,树上有很多的 estree 节点 Transform(转换) 对抽象语法树进行转换 Generate(代码生成) 将上一步经过转换过的抽象语法树生成新的代码
acorn
acorn 是一个 JavaScript 语法解析器,它将 JavaScript 字符串解析成语法抽象树 AST 如果想了解 AST 语法树可以点下这个网址https://astexplorer.net/
作用域/作用域链
在 js 中,作用域是用来规定变量访问范围的规则, 作用域链是由当前执行环境和上层执行环境的一系列变量对象组成的,它保证了当前执行环境对符合访问权限的变量和函数的有序访问
三、Rollup
Rollup 是怎样工作的呢?
你给它一个入口文件 —— 通常是 index.js。Rollup 将使用 Acorn 读取解析文件 —— 将返回给我们一种叫抽象语法树(AST)的东西。一旦有了 AST ,你就可以发现许多关于代码的东西,比如它包含哪些 import 声明。
假设 index.js 文件头部有这样一行:
import foo from './foo.js';
这就意味着 Rollup 需要去加载,解析,分析在 index.js 中引入的 ./foo.js。重复解析直到没有更多的模块被加载进来。更重要的是,所有的这些操作都是可插拔的,所以您可以从 node_modules 中导入或者使用 sourcemap-aware 的方式将 ES2015 编译成 ES5 代码。
在 Rollup 中,一个文件就是一个模块,每个模块都会根据文件的代码生成一个 AST 抽象语法树。
分析 AST 节点,就是看这个节点有没有调用函数方法,有没有读到变量,有,就查看是否在当前作用域,如果不在就往上找,直到找到模块顶级作用域为止。如果本模块都没找到,说明这个函数、方法依赖于其他模块,需要从其他模块引入。如果发现其他模块中有方法依赖其他模块,就会递归读取其他模块,如此循环直到没有依赖的模块为止 找到这些变量或着方法是在哪里定义的,把定义语句包含进来即可 其他无关代码一律不要
看如下代码,我们先实际操作一下:
// index.js
import { foo } from "./foo";
foo()
var city = 'hangzhou'
function test() {
console.log('test')
}
console.log(test())
// foo.js
import { bar } from "./bar";
export function foo() {
console.log('foo')
}
// bar.js
export function bar() {
console.log('bar')
}
// rollup.config.js
export default {
input: './src/index.js',
output: {
file: './dist/bundle.js', // 打包后的存放文件
format: 'cjs', //输出格式 amd es6 life umd cjs
name: 'bundleName', //如果输出格式 life,umd 需要指定一个全局变量
}
};
执行 npm run build,会得到如下结果:
'use strict';
function foo() {
console.log('foo');
}
foo();
function test() {
console.log('test');
}
console.log(test());
以上,我们可以看到Rollup 只是会合并你的代码 —— 没有任何浪费。所产生的包也可以更好的缩小。有人称之为 “作用域提升(scope hoisting)”。其次,它把你导入的模块中的未使用代码移除。这被称为“(摇树优化)treeshaking”。总之,Rollup 就是一个模块化的打包工具。
接下来我们进入源码,具体分析下 Rollup 的构建流程
Rollup 构建流程分析
Rollup 源码结构
│ bundle.js // Bundle 打包器,在打包过程中会生成一个 bundle 实例,用于收集其他模块的代码,最后再将收集的代码打包到一起。
│ external-module.js // ExternalModule 外部模块,例如引入了 'path' 模块,就会生成一个 ExternalModule 实例。
│ module.js // Module 模块,module 实例。
│ rollup.js // rollup 函数,一切的开始,调用它进行打包。
│
├─ast // ast 目录,包含了和 AST 相关的类和函数
│ analyse.js // 主要用于分析 AST 节点的作用域和依赖项。
│ Scope.js // 在分析 AST 节点时为每一个节点生成对应的 Scope 实例,主要是记录每个 AST 节点对应的作用域。
│ walk.js // walk 就是递归调用 AST 节点进行分析。
│
├─finalisers
│ cjs.js
│ index.js
│
└─utils // 一些帮助函数
map-helpers.js
object.js
promise.js
replaceIdentifiers.js
Rollup 构建流程
我们以 index.js 入口文件,index 依赖了 foo.js,foo 依赖了 bar.js
// index.js
import { foo } from "./foo";
foo()
var city = 'hangzhou'
function test() {
console.log('test')
}
console.log(test())
// foo.js
import { bar } from "./bar";
export function foo() {
console.log('foo')
}
// bar.js
export function bar() {
console.log('bar')
}
debug 起来!!!
// debug.js
const path = require('path')
const rollup = require('./lib/rollup')
// 入口文件的绝对路径
let entry = path.resolve(__dirname, 'src/main.js')
// 和源码有所不同,这里使用的是同步,增加可读性
rollup(entry, 'bundle.js')
1.new Bundle(), build()
首先生成一个 Bundle 实例,也就是打包器。然后执行 build 打包编译
// rollup.js
let Bundle = require('./bundle')
function rollup(entry, outputFileName) {
// Bundle 代表打包对象,里面包含所有的模块信息
const bundle = new Bundle({ entry })
// 调用 build 方法开始进行编译
bundle.build(outputFileName)
}
module.exports = rollup
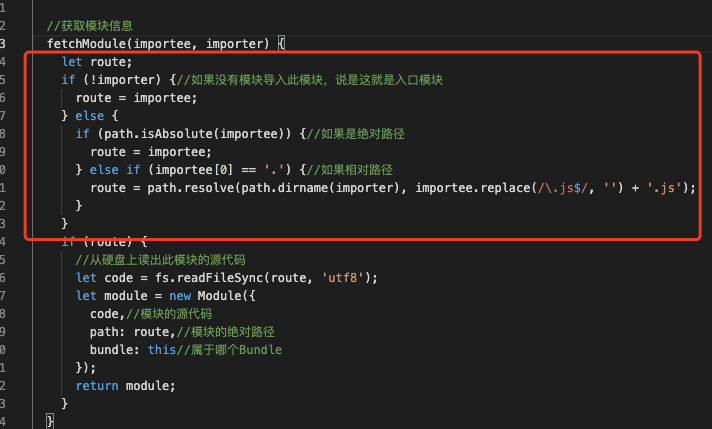
lib/bundle.js根据入口路径出发(在 bundle 中,我们会首先统一处理下入口文件的后缀),去找到他的模块定义,在 fetchModule 中,会生成一个 module 实例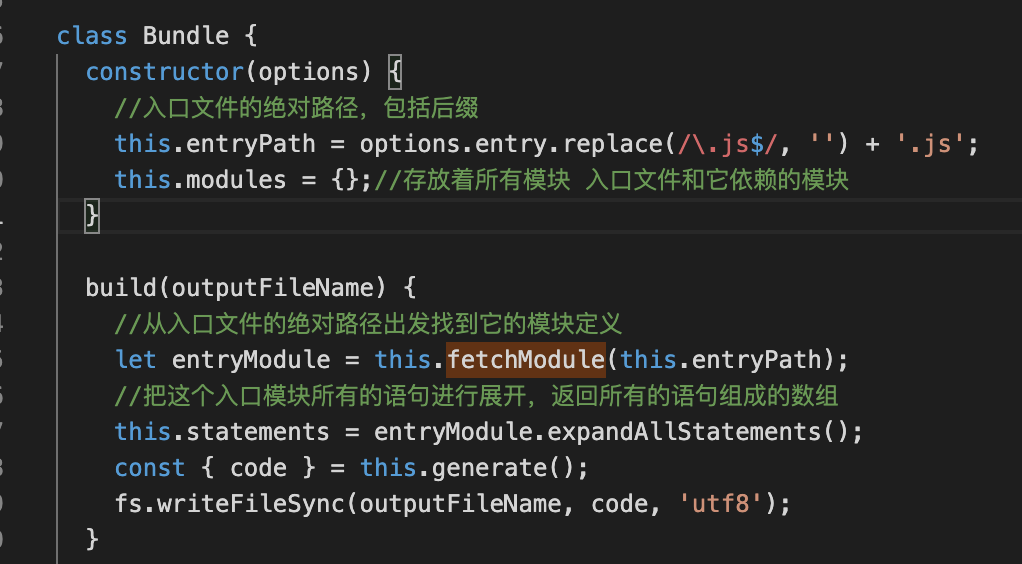 我们关注红框中的代码,会发现返回了一个 module
我们关注红框中的代码,会发现返回了一个 module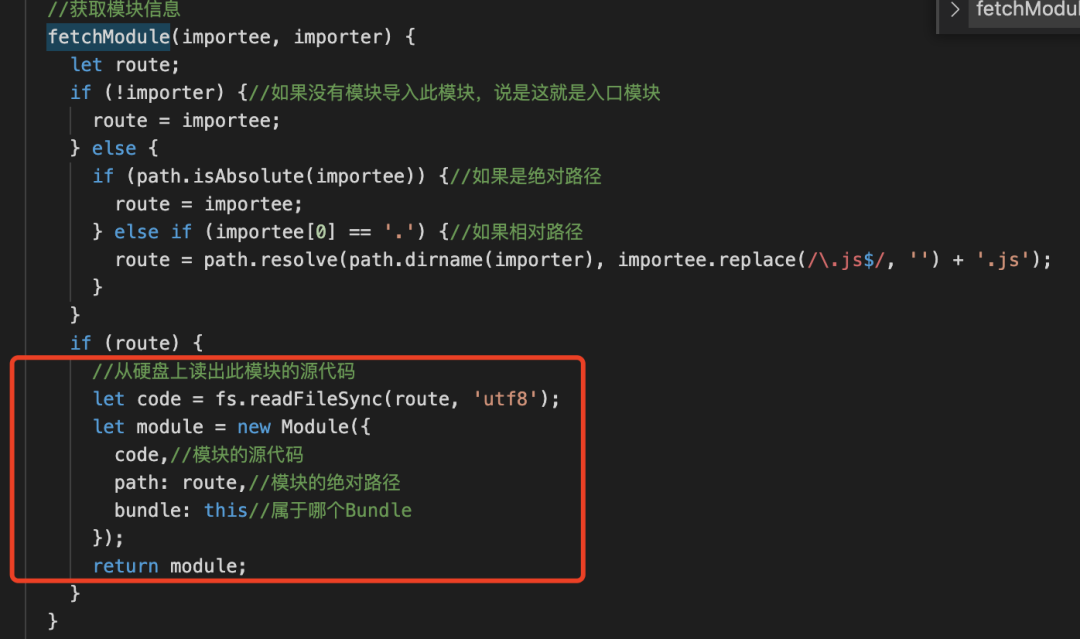
2.new Module()
每个文件都是一个模块,每个模块都会有一个 Module 实例。在 Module 实例中,会调用 acorn 库的 parse() 方法将代码解析成 AST。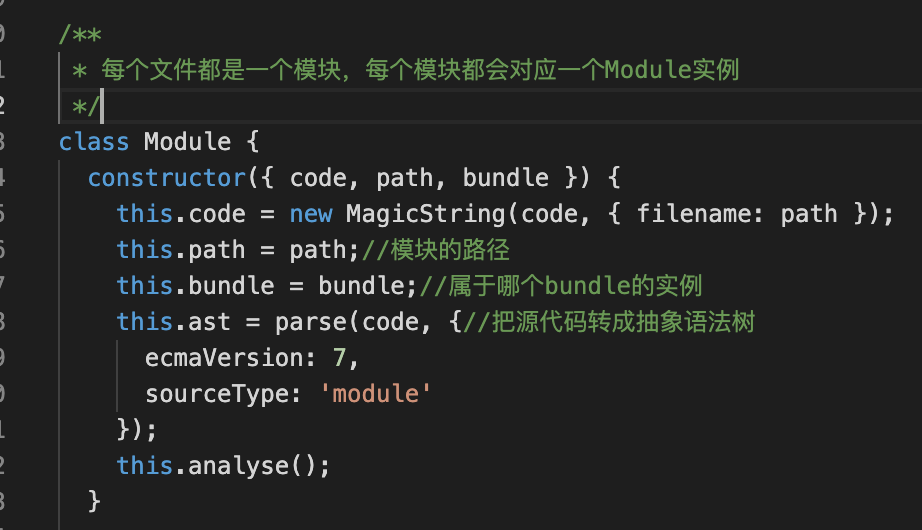 对生成的 AST 进行分析analyse我们先看一下入口文件 index.js 生成的 AST
对生成的 AST 进行分析analyse我们先看一下入口文件 index.js 生成的 AST
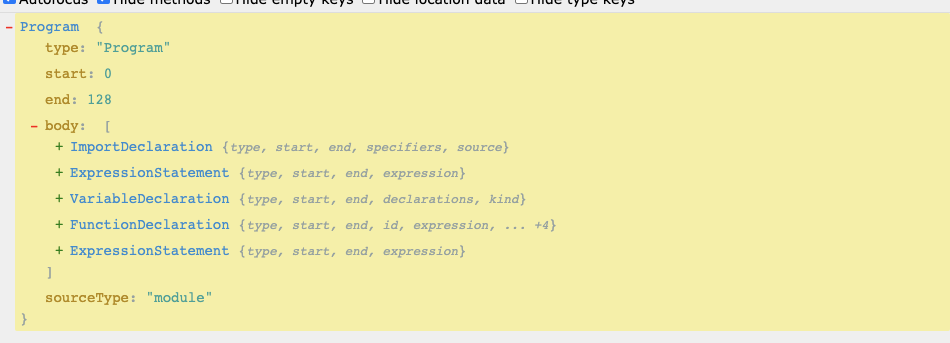 可以看到 ast.body 是一个数组,分别对应 index.js 的五条语句
展开这个 ast 树如下:
可以看到 ast.body 是一个数组,分别对应 index.js 的五条语句
展开这个 ast 树如下:
{
"type": "Program",
"start": 0,
"end": 128,
"body": [
{
"type": "ImportDeclaration", // 导入声明
"start": 0,
"end": 31,
"specifiers": [
{
"type": "ImportSpecifier",
"start": 9,
"end": 12,
"imported": {
"type": "Identifier",
"start": 9,
"end": 12,
"name": "foo"
},
"local": {
"type": "Identifier",
"start": 9,
"end": 12,
"name": "foo"
}
}
],
"source": {
"type": "Literal",
"start": 20,
"end": 30,
"value": "./foo.js",
"raw": "\"./foo.js\""
}
},
{
"type": "ExpressionStatement",
"start": 32,
"end": 37,
"expression": {
"type": "CallExpression",
"start": 32,
"end": 37,
"callee": {
"type": "Identifier",
"start": 32,
"end": 35,
"name": "foo"
},
"arguments": [],
"optional": false
}
},
{
"type": "VariableDeclaration",
"start": 38,
"end": 59,
"declarations": [
{
"type": "VariableDeclarator",
"start": 42,
"end": 59,
"id": {
"type": "Identifier",
"start": 42,
"end": 46,
"name": "city"
},
"init": {
"type": "Literal",
"start": 49,
"end": 59,
"value": "hangzhou",
"raw": "'hangzhou'"
}
}
],
"kind": "var"
},
{
"type": "FunctionDeclaration",
"start": 61,
"end": 104,
"id": {
"type": "Identifier",
"start": 70,
"end": 74,
"name": "test"
},
"expression": false,
"generator": false,
"async": false,
"params": [],
"body": {
"type": "BlockStatement",
"start": 77,
"end": 104,
"body": [
{
"type": "ExpressionStatement",
"start": 83,
"end": 102,
"expression": {
"type": "CallExpression",
"start": 83,
"end": 102,
"callee": {
"type": "MemberExpression",
"start": 83,
"end": 94,
"object": {
"type": "Identifier",
"start": 83,
"end": 90,
"name": "console"
},
"property": {
"type": "Identifier",
"start": 91,
"end": 94,
"name": "log"
},
"computed": false,
"optional": false
},
"arguments": [
{
"type": "Literal",
"start": 95,
"end": 101,
"value": "test",
"raw": "'test'"
}
],
"optional": false
}
}
]
}
},
{
"type": "ExpressionStatement",
"start": 106,
"end": 125,
"expression": {
"type": "CallExpression",
"start": 106,
"end": 125,
"callee": {
"type": "MemberExpression",
"start": 106,
"end": 117,
"object": {
"type": "Identifier",
"start": 106,
"end": 113,
"name": "console"
},
"property": {
"type": "Identifier",
"start": 114,
"end": 117,
"name": "log"
},
"computed": false,
"optional": false
},
"arguments": [
{
"type": "CallExpression",
"start": 118,
"end": 124,
"callee": {
"type": "Identifier",
"start": 118,
"end": 122,
"name": "test"
},
"arguments": [],
"optional": false
}
],
"optional": false
}
}
],
"sourceType": "module"
}
我们通过这个 AST 树,分析 **analyse **具体做了什么???
第一步:分析当前模块导入【import】和导出【exports】模块,将引入的模块和导出的模块存储起来this.imports = {};//存放着当前模块所有的导入
this.exports = {};//存放着当前模块所有的导出
this.imports = {};//存放着当前模块所有的导入
this.exports = {};//存放着当前模块所有的导出
this.ast.body.forEach(node => {
if (node.type === 'ImportDeclaration') {// 说明这是一个 import 语句
let source = node.source.value; // 从哪个模块导入的
let specifiers = node.specifiers; // 导入标识符
specifiers.forEach(specifier => {
const name = specifier.imported.name; //name
const localName = specifier.local.name; //name
//本地的哪个变量,是从哪个模块的的哪个变量导出的
this.imports[localName] = { name, localName, source }
});
//}else if(/^Export/.test(node.type)){ // 导出方法有很多
} else if (node.type === 'ExportNamedDeclaration') { // 说明这是一个 exports 语句
let declaration = node.declaration;//VariableDeclaration
if (declaration.type === 'VariableDeclaration') {
let name = declaration.declarations[0].id.name;
this.exports[name] = {
node, localName: name, expression: declaration
}
}
}
});
analyse(this.ast, this.code, this);//找到了_defines 和 _dependsOn
打断点可以看到,foo 已经被存入 imports =》** import { foo } from "./foo"; **
exports:{} 表示没有导出语句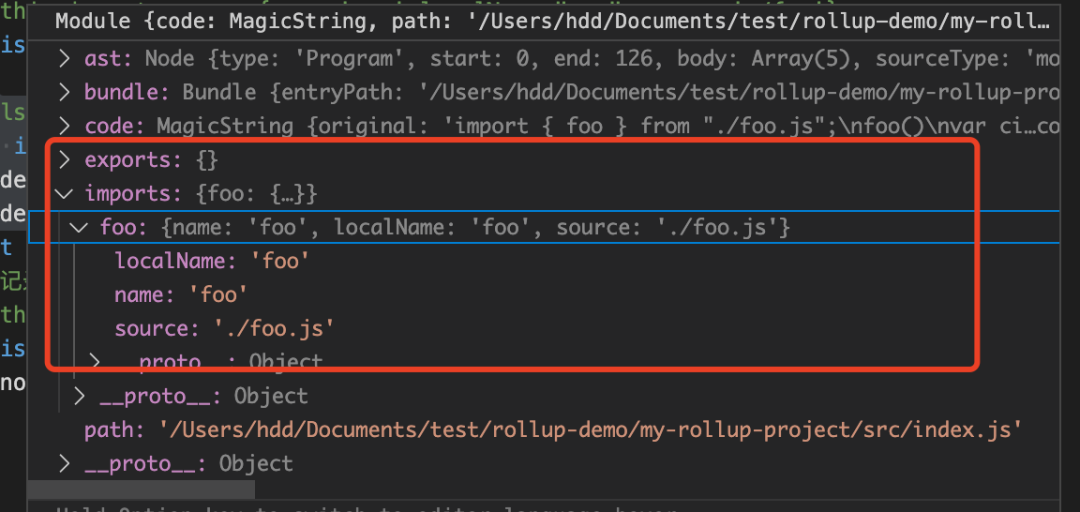
第二步:analyse(this.ast, this.code, this); //找到_defines 和 _dependsOn
找出当前模块使用到了哪些变量
标记哪些变量时当前模块声明的,哪些变量是导入别的模块的变量
我们定义以下字段用来存放:_defines: { value: {} },//存放当前模块定义的所有的全局变量
_dependsOn: { value: {} },//当前模块没有定义但是使用到的变量,也就是依赖的外部变量_included: { value: false, writable: true },//此语句是否已经被包含到打包结果中,防止重复打包_source: { value: magicString.snip(statement.start, statement.end) } //magicString.snip 返回的还是 magicString 实例 clone
分析每个 AST 节点之间的作用域,构建 scope tree,
function analyse(ast, magicString, module) {
let scope = new Scope();//先创建一个模块内的全局作用域
//遍历当前的所有的语法树的所有的顶级节点
ast.body.forEach(statement => {
//给作用域添加变量 var function const let 变量声明
function addToScope(declaration) {
var name = declaration.id.name;//获得这个声明的变量
scope.add(name);
if (!scope.parent) {//如果当前是全局作用域的话
statement._defines[name] = true;
}
}
Object.defineProperties(statement, {
_defines: { value: {} },//存放当前模块定义的所有的全局变量
_dependsOn: { value: {} },//当前模块没有定义但是使用到的变量,也就是依赖的外部变量
_included: { value: false, writable: true },//此语句是否已经 被包含到打包结果中了
//start 指的是此节点在源代码中的起始索引,end 就是结束索引
//magicString.snip 返回的还是 magicString 实例 clone
_source: { value: magicString.snip(statement.start, statement.end) }
});
//这一步在构建我们的作用域链
walk(statement, {
enter(node) {
let newScope;
if (!node) return
switch (node.type) {
case 'FunctionDeclaration':
const params = node.params.map(x => x.name);
if (node.type === 'FunctionDeclaration') {
addToScope(node);
}
//如果遍历到的是一个函数声明,我会创建一个新的作用域对象
newScope = new Scope({
parent: scope,//父作用域就是当前的作用域
params
});
break;
case 'VariableDeclaration': //并不会生成一个新的作用域
node.declarations.forEach(addToScope);
break;
}
if (newScope) {//当前节点声明一个新的作用域
//如果此节点生成一个新的作用域,那么会在这个节点放一个_scope,指向新的作用域
Object.defineProperty(node, '_scope', { value: newScope });
scope = newScope;
}
},
leave(node) {
if (node._scope) {//如果此节点产出了一个新的作用域,那等离开这个节点,scope 回到父作用法域
scope = scope.parent;
}
}
});
});
ast._scope = scope;
//找出外部依赖_dependsOn
ast.body.forEach(statement => {
walk(statement, {
enter(node) {
if (node._scope) {
scope = node._scope;
} //如果这个节点放有一个 scope 属性,说明这个节点产生了一个新的作用域
if (node.type === 'Identifier') {
//从当前的作用域向上递归,找这个变量在哪个作用域中定义
const definingScope = scope.findDefiningScope(node.name);
if (!definingScope) {
statement._dependsOn[node.name] = true;//表示这是一个外部依赖的变量
}
}
},
leave(node) {
if (node._scope) {
scope = scope.parent;
}
}
});
});
}
断点可以看到**_defines 和 _dependsOn **分别存入了当前变量和引入的变量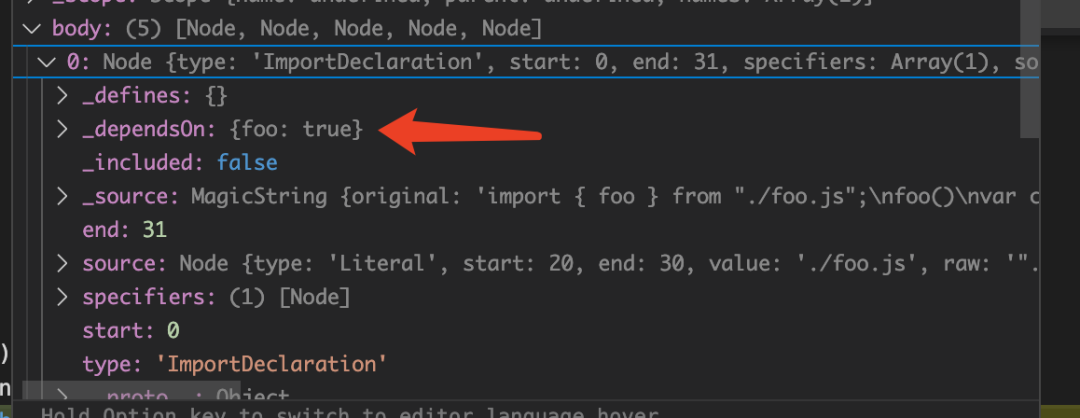
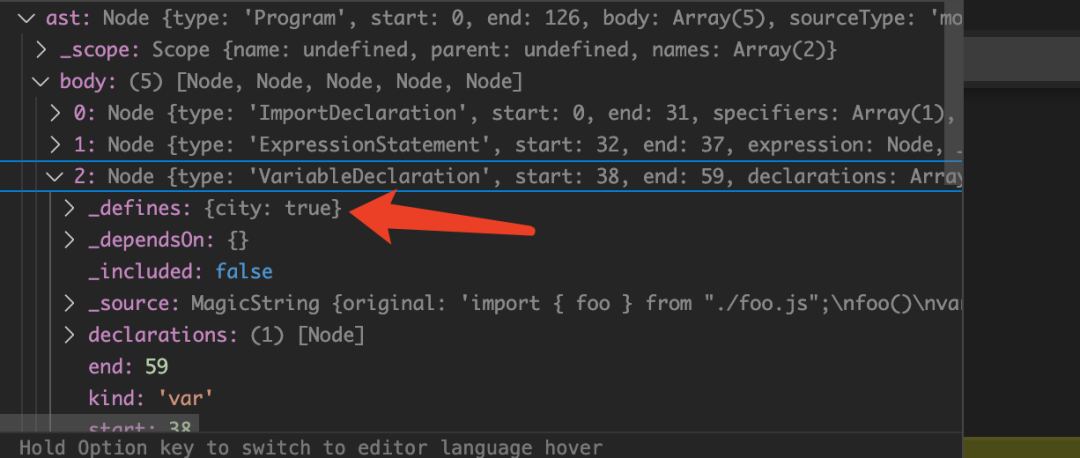 第三步:this.definitions = {};把全局变量的定义语句存放到 definitions 里
第三步:this.definitions = {};把全局变量的定义语句存放到 definitions 里
// module.js
this.definitions = {};//存放着所有的全局变量的定义语句
this.ast.body.forEach(statement => {
Object.keys(statement._defines).forEach(name => {
//key 是全局变量名,值是定义这个全局变量的语句
this.definitions[name] = statement;
});
});
第四步:展开语句,展开当前模块的所有语句,把这些语句中定义的变量的语句都放到结果里
if (statement.type === 'ImportDeclaration') {return} 如果是导入声明语句,既 import { foo } from "./foo";这条语句我们是不需要的,return 掉
//展开这个模块里的语句,把些语句中定义的变量的语句都放到结果里
expandAllStatements() {
let allStatements = [];
this.ast.body.forEach(statement => {
if (statement.type === 'ImportDeclaration') {return}
let statements = this.expandStatement(statement);
allStatements.push(...statements);
});
return allStatements;
}
**expandStatement:**找到当前节点依赖的变量,找到这些变量的声明语句。这些语句可能是在当前模块声明的,也也可能是在导入的模块的声明的 然后放入结果里
expandStatement(statement) {
let result = [];
const dependencies = Object.keys(statement._dependsOn);//外部依赖 [name]
dependencies.forEach(name => {
//找到定义这个变量的声明节点,这个节点可以有在当前模块内,也可能在依赖的模块里
let definition = this.define(name);
result.push(...definition);
});
if (!statement._included) {
statement._included = true;//表示这个节点已经确定被纳入结果里了,以后就不需要重复添加了
result.push(statement);
}
return result;
}
define: 找到定义这个变量的声明节点,这个节点可以有在当前模块内,也可能在依赖的模块里const module = this.bundle.fetchModule(importData.source, this.path);获取导入变量的模块
define(name) {
//查找一下导入变量里有没有 name
if (hasOwnProperty(this.imports, name)) {
const importData = this.imports[name];
// 获取导入变量的模块
const module = this.bundle.fetchModule(importData.source, this.path);
// 这个 module 模块也有导入导出
const exportData = module.exports[importData.name];
// 返回这个导入模块变量的声明语句
return module.define(exportData.localName);
} else {
//definitions 是对象,key 当前模块的变量名,值是定义这个变量的语句
let statement = this.definitions[name];
if (statement && !statement._included) {
return this.expandStatement(statement);
} else {
return [];
}
}
}
this.statements 里就是所有我们分析标记之后返回的数组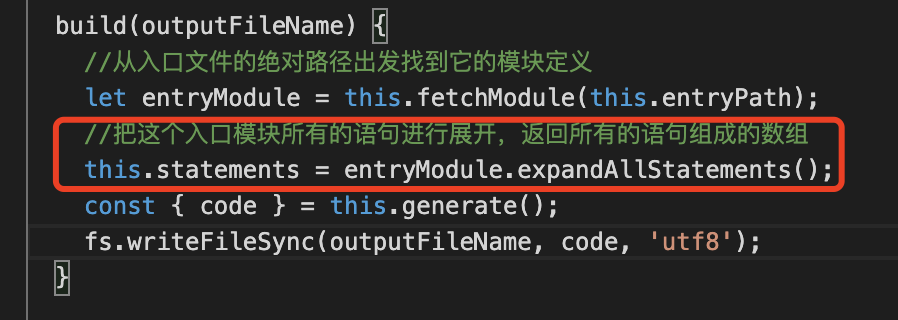
以上分析了很多,但总结来就是做了以下事情:
收集导入和导出变量 建立映射关系,方便后续使用 收集所有语句定义的变量 建立变量和声明语句之间的对应关系,方便后续使用 过滤 import 语句 删除关键词 输出语句时,判断变量是否为 import 如是需要递归再次收集依赖文件的变量 否则直接输出 构建依赖关系,创建作用域链,交由./src/ast/analyse.js 文件处理 在抽象语法树的每一条语句上挂载_source(源代码)、_defines(当前模块定义的变量)、_dependsOn(外部依赖的变量)、_included(是否已经包含在输出语句中) 收集每个语句上定义的变量,创建作用域链
3.generate()
第一步:移除额外代码 例如从 foo.js 中引入的 foo() 函数代码是这样的:export function foo() {}。rollup 会移除掉 export,变 成 function foo() {}。因为它们就要打包在一起了,所以就不需要 export 了。
第二步:把 AST 节点的源码 addSource 到 magicString,这个操作本质上相当于拼字符串,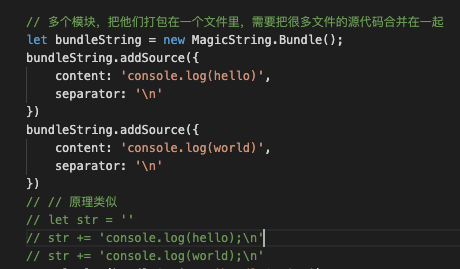 第三步:**return magicString.toString() **。返回合并后源代码
第三步:**return magicString.toString() **。返回合并后源代码
generate() {
let magicString = new MagicString.Bundle();
this.statements.forEach(statement => {
const source = statement._source;
if (statement.type === 'ExportNamedDeclaration') {
source.remove(statement.start, statement.declaration.start);
}
magicString.addSource({
content: source,
separator: '\n'
});
});
return { code: magicString.toString() };
}
最后输出到'dist/bundle.js'中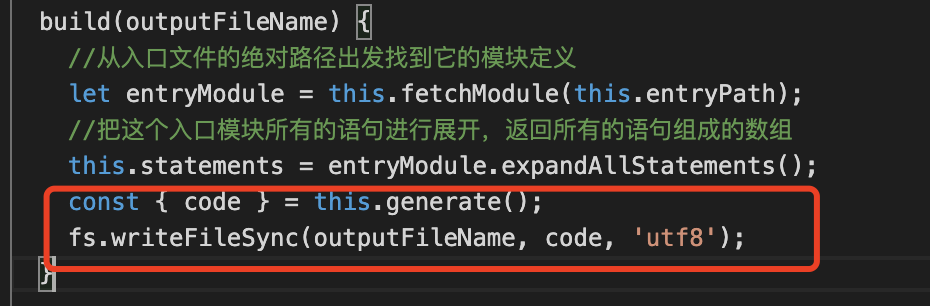
小结
简单来说,Rollup 构建其实就是做了以下几件事:
获取入口文件的内容,包装成 module,生成抽象语法树 对入口文件抽象语法树进行依赖解析 生成最终代码 写入目标文件
四、总结
以上代码实现过程可以帮你简单的实现一个 rollup 打包流程,但也仅仅是对 rollup 源码进行了抽象,方便大家理解 rollup 打包的原理,其中很多细节没有写出来,如果感兴趣的话,可以深入阅读一下源码。
爱心三连击
1.看到这里了就点个在看支持下吧,你的在看是我创作的动力。
2.关注公众号脑洞前端,获取更多前端硬核文章!加个星标,不错过每一条成长的机会。
3.如果你觉得本文的内容对你有帮助,就帮我转发一下吧。