
GPU在深度学习中究竟起了什么作用
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达


围绕深度学习的“噪声”经常误导外行人以为这是一种新发明的技术,使他们为之一振的是当他们知道深度学习早在1940-1950年代就奠定了基础。还有很长的历史,其中最流行的深层神经网络结构和理论已经在整个20世纪后半期提出深的学问。如果是这种情况,那么你们可能会问,为什么在当前时代发生了深度学习革命,为什么不回溯几十年。
简单来说,在那些时期内,不存在有效训练大型神经网络所需的正确硬件和计算能力。因此所有的理论大部分都在纸上,没有实际的支持。尽管专门的研究人员继续在神经网络上开展工作,直到2000年代下半叶,当硬件革命开始兴起时,但它大部分都是不切实际的理论。
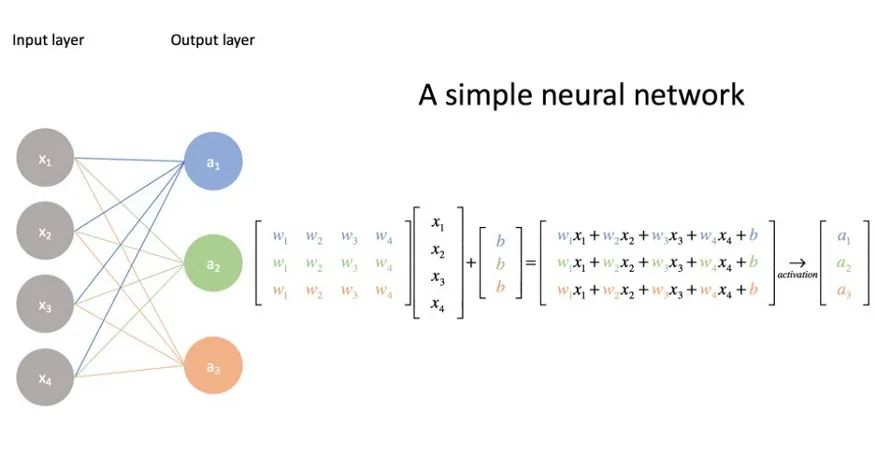 图1 并行执行神经网络的矩阵计算
图1 并行执行神经网络的矩阵计算
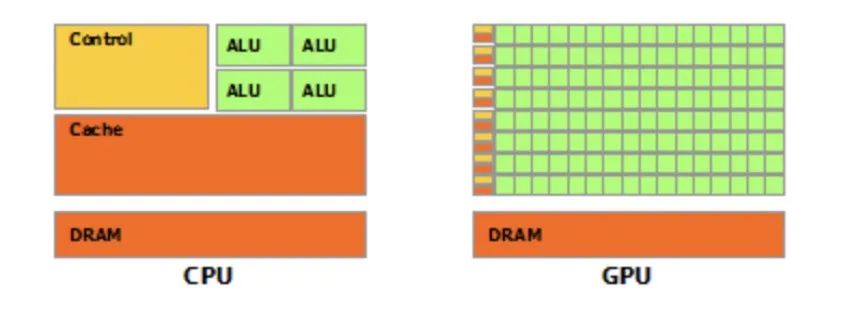
图2 GPU与CPU架构
让我们比较一下CPU和GPU的体系结构,以了解为什么GPU在神经网络上执行操作要比CPU更好。
第一个主要的明显区别是CPU仅具有几个内核来执行算术运算,而GPU可以具有成千上万个这样的内核。从一个角度来看,一个标准的性能良好的CPU有8个内核,而功能强大的CPU Intel Core i9-10980XE有18个内核。另一方面,出色的GeForce GTX TITAN Z NVIDIA GPU具有5760个CUDA内核。如此多的内核使GPU可以非常高效地进行并行计算以产生高吞吐量。GPU还具有比CPU高的内存带宽,从而使GPU可以一次在存储单元之间移动大量数据。
由于其高内存带宽和并行化,GPU可以立即加载神经网络矩阵的很大一部分,并进行并行计算以产生输出。另一方面,与GPU相比,CPU将以几乎可以忽略的并行化顺序加载数字。这就是为什么对于具有大型矩阵运算的大型深度神经网络而言,GPU可以胜过CPU的原因。
应该注意的是,拥有如此多的内核并不能使GPU在所有操作上都优于CPU。由于其低延迟,CPU可以更快地处理无法分解为并行化的任何操作。因此,CPU将比GPU更快地计算顺序浮点运算。
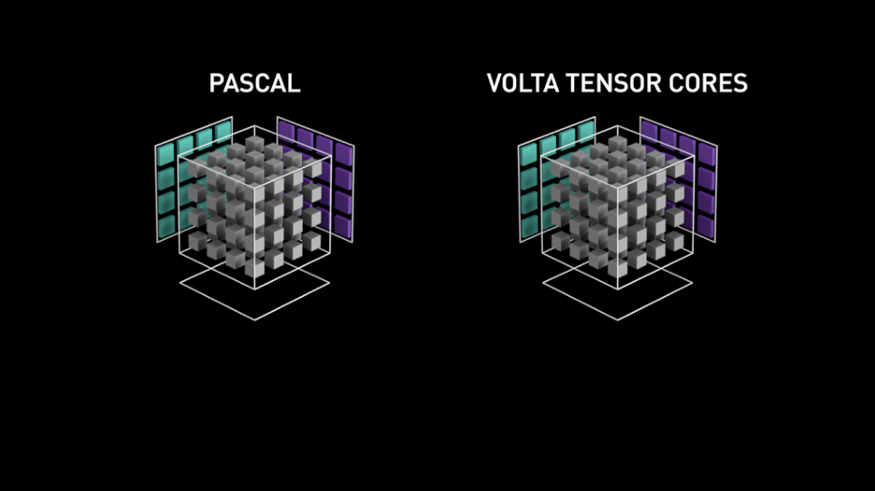
图3 Voltas Tensor核心性能
随着GPU在深度学习中的广泛采用,NVIDIA在2017年推出了GPU Tesla Tesla V100,它具有新型的Voltas架构,该架构具有称为Tensor Core的专用内核,以支持神经网络的特定张量操作。NVIDIA声称,Volta Tensor Core的吞吐率比使用常规CUDA的前代产品高出12倍。

图4 矩阵的计算操作支持张量核心
其背后的基本方法是Tensor Core专门用于将两个4x4 FP16矩阵相乘并在其中添加4x4 FP16或FP32矩阵(FP代表浮点数)。这样的矩阵运算在神经网络中非常普遍,因此具有一个专用的Tensor Core进行优化的优势,以使其比传统的CUDA内核执行得更快。
到目前为止,我们的讨论集中在GPU的硬件方面。现在让我们了解程序员如何利用NVIDIA GPU进行深度学习。在前面的部分中,我们讨论了CUDA,其中讨论了CUDA是供程序员在GPU上执行通用计算的API。CUDA具有对C / C ++和Fortran等编程语言的本机支持,以及对其他编程语言(如Python,R,Matlab,Java等)的第三方包装支持。
CUDA的发布是为了牢记图形设计社区,尽管深度学习社区开始使用CUDA,但对于他们而言,专注于CUDA的低级复杂性而不是专注于神经网络是一项艰巨的任务。因此,NVIDIA在2014年发布了CUDNN,这是一个基于CUDA的专用于深度学习的库,为神经网络的原始操作提供了功能,例如反向传播,卷积,池化等。
只有认真使用GPU,GPU才能加速深度学习管道,否则也会造成瓶颈。当用户尝试通过GPU推送所有代码而不考虑是否可以在GPU上并行执行所有这些操作时,通常会发生这种情况。
根据经验,只有可以并行执行的计算密集型代码才应推送到GPU,其余所有序列代码都应发送到CPU。例如,用于数据清理,预处理的代码应在CPU上执行,而用于神经网络训练的代码应在GPU上运行,只有这样,您才能看到性能的提升。

图5 GPU加速
在本文中,我们了解了GPU如何在重新激发ML社区对神经网络的兴趣并将深度学习带入主流方面发挥如此重要的作用。以下是针对深度神经网络进行编程时要考虑的一些要点:
GPU用于大规模并行计算,因此应用于大量数据处理。
仅当将可分解为并行计算的操作发送到GPU,而其他操作应在CPU上执行时,GPU才是有益的。
在使用大数据进行模型训练时,GPU更为有利,你们可以在其中对数据进行分块处理并利用并行计算。推论可能并非如此。如果推断是在非常快的一批数据上发生的,但是如果推断在每个数据点上是一个接一个地发生(实时推断),则在GPU上加载模型可能不会导致性能提高。
尽管GPU支持研究人员和大公司通过深度学习创造奇迹,但它们的成本很高,超出了大多数爱好者的能力范围。但是,Google Colab和Kaggle上有免费的GPU免费层选项,但资源有限,初学者可以尝试动手。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~