
Google 和 Facebook 为什么不 用Docker?
点击上方 蓝字 关注我们!
Java,Python,C/C++,Linux,PHP,Go,C#,QT,大数据,算法,软件教程,前端,简历,毕业设计等分类,资源在不断更新中... 点击领取!


来源:zhuanlan.zhihu.com/p/368676698
一言蔽之 Packaging Tarball XAR 分层 Overlay Filesystem Docker Image and Layer Docker Image 的好处 Google 和 Facebook 不需要 Docker Google 和 Facebook 没在用 Docker 完美解法的技术挑战
本文涉及的所有技术细节都在开源软件和论文中。
写本文的起因是我想让分布式 PyTorch 程序更快的在 Facebook 的集群上启动。探索过程很有趣。也展示了工业机器学习需要的知识体系。
2007 年我毕业后在 Google 工作过三年。当时觉得分布式操作系统 Borg 真好用。从 2010 年离开 Google 之后就一直盼着它开源,直到 Kubernetes 的出现。
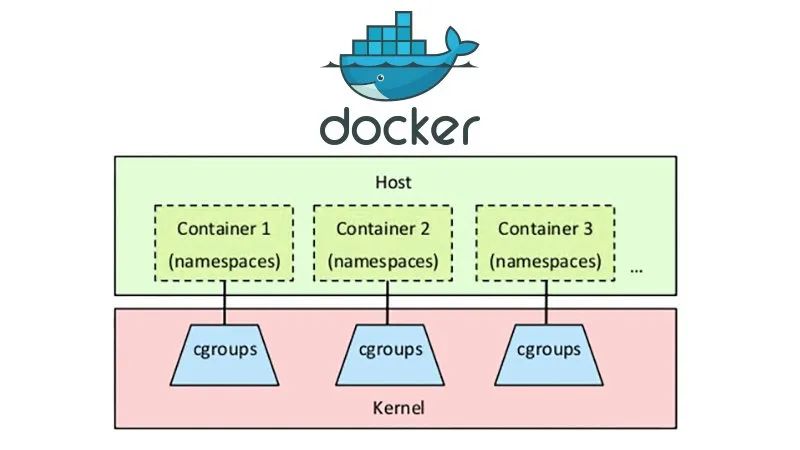
Kubernetes 调度的单元是 containers(准确的翻译是”集装箱“,而不是意思泛泛的”容器“,看看 Docker 公司的 logo 上画的是啥就知道作者的心意了)。而一个 container 执行一个 image 就如一个 process 执行一个 program。
在 Google 工作过的人恐怕在用 Borg 的时候都未曾接触过 container 和 image 这两个概念。为啥 Borg 里没有,而 Kubernetes 却要引入了这样两个概念呢?
这个问题在我脑海中曾经一闪而过,然后就被忽略了。毕竟后来我负责开源项目比较多,比如百度Paddle 以及蚂蚁的 SQLFlow 和 ElasticDL,Docker 用起来很顺手。于是也就没有多想。
今年(2021年)初,我加入 Facebook。恰逢 Facebook 发论文介绍了其分布式集群管理系统 Tupperware。只因为 Tupperware 是一家注册于 1946 年的厨具品牌 https://en.wikipedia.org/wiki/Tupperware_Brands ,所以在论文里只好起了另一个名字 Twine。因为行业里知道 Tupperware 这个名字的朋友很多,本文就不说 Twine 了。总之,这篇论文的发表又引发了我对于之前问题的回顾 —— Facebook 里也没有 Docker!
和 Facebook Tuppware 团队以及 Google Borg 几位新老同事仔细聊了聊之后,方才恍然。因为行业里没有看到相关梳理,特作文以记之。
一言蔽之
简单的说,如果用 monolithic repository 来管理代码,则不需要 Docker image(或者 ZIP、tarball、RPM、deb)之类的“包”。
所谓 monolithic repo 就是一家公司的所有项目的所有代码都集中放在一个(或者极少数) repo 里。甚至第三方源码也放进这个 repo。monolithic repository 得有配套的构建系统(build system)否则编译不动那么老大一坨代码。而既然有统一的 build system,一旦发现某个集群节点需要执行的程序所依赖的某个模块变化了,同步这个模块(例如一个 .so 或者 .jar 文件)到此节点既可。完全不需要先打包再同步。
反之,如果每个项目在一个独立的 git/svn repo 里,比如各个开源项目在不同的 GitHub repo 里,各自用不同的 build system,比如 CMake、GNU make、Bazel、Buck,则需要把每个项目 build 的结果打包。而 Docker image 这样支持分层的包格式让我们只需要传输那些容纳被修改的项目的最上面几层,而尽量复用被节点 cache 了的下面的几层。
Google 和 Facebook 都使用 monolithic repository,也都有自己的 build systems(我这篇老文 寻找 Google Blaze 解释过 Google 的 build system)所以不需要“包”,当然也就不需要 Docker images。
不过 Borg 和 Tupperware 都是有 container 的(使用 Linux kernel 提供的一些 system calls,比如 Google Borg 团队十多年前贡献给 Linux kernel 的 cgroup)来实现 jobs 之间的隔离。只是因为如果不需要大家 build Docker image 了,那么 container 的存在就不容易被关注到了。
如果不想被上述蔽之,而要细究这个问题,那就待我一层一层剥开 Google 和 Facebook 的研发技术体系和计算技术体系。
Packaging
当我们提交一个分布式作业(job)到集群上去执行,我们得把要执行的程序(包括一个可执行文件以及相关的文件,比如 *.so, *.py )传送到调度系统分配给这个 job 的一些机器(节点、nodes)上去。
这些待打包的文件是怎么来的呢?当时是 build 出来的。在 Google 里有 Blaze,在 Facebook 里有 Buck。感兴趣的朋友们可以看看 Google Blaze 的”开源版本“ Bazel,以及 Facebook Buck 的开源版本。不过提醒在先 —— Blaze 和 Facebook Buck 的内部版都是用于 monolithic repo 的,而开源版本都是方便大家使用非 mono repos 的,所以理念和实现上有不同,不过基本使用方法还是可以感受一下的。
假设我们有如下模块依赖(module dependencies),用 Buck 或者 Bazel 语法描述(两者语法几乎一样):
python_binary(name="A", srcs=["A.py"], deps=["B", "C"], ...)
python_library(name="B", srcs=["B.py"], deps=["D"], ...)
python_library(name="C", srcs=["C.py"], deps=["E"], ...)
cxx_library(name="D", srcs=["D.cxx", "D.hpp"], deps="F", ...)
cxx_library(name="E", srcs=["E.cxx", "E.hpp"], deps="F", ...)
那么模块(build 结果)依赖关系如图
A.py --> B.py --> D.so -\
\-> C.py --> E.so --> F.so
如果是开源项目,请自行脑补,把上述模块(modules)替换成 GPT-3, PyTorch, cuDNN, libc++ 等项目(projects) —— 当然,每个 projects 里包含多个 modules 也依赖其他 projects,就像每个 module 有多个子 modules 一样。
Tarball
最简单的打包方式就是把上述文件{A,B,C}.py, {D,E,F}.so打包成一个文件 A.zip,或者 A.tar.gz。
更严谨的说,文件名里应该包括版本号。比如 A-953bc.zip,其中版本号953bc是 git/Mercurial commit ID。引入版本号,可以帮助在节点本地 cache —— 下次运行同一个 tarball 的时候,就不需要下载这个文件了。
请注意在这里我引入了 package caching 的概念,为下文解释 Docker 预备。
XAR
ZIP 或者 tarball 文件拷贝到集群节点上之后,需要解压缩到本地文件系统的某个地方,比如 /var/packages/A-953bc/{A,B,C}.py,{D,E,F}.so。
一个稍显酷炫的方式是不用 Tarball,而是把上述文件放在一个 overlay filesystem 的 loopback device image 里。这样”解压“就变成了”mount“。
请注意在这里我引入了 loopback device image 的概念,为下文解释 Docker 预备。
什么叫 loopback device image 呢?在 Unix 里,一个目录树的文件们被称为一个文件系统(filesystem)。通常一个 filesystem 存储在一个 block device 上。什么是 block device 呢?简单的说,但凡一个存储空间可以被看作一个 byte array 的,就是一个 block device。比如一块硬盘就是一个 block device。在一个新买的硬盘里创建一个空的目录树结构的过程,就叫做格式化(format)。
既然 block device 只是一个 byte array,那么一个文件不也是一个 byte array 吗?是的!在 Unix 的世界里,我们完全可以创建一个固定大小的空文件(用 truncate 命令),然后“格式化”这个文件,在里面创建一个空的文件系统。然后把上述文件{A,B,C}.py,{D,E,F}.so 放进去。
比如 Facebook 开源的 XAR 文件格式。这是和 Buck 一起使用的。如果我们运行 buck build A 就会得到 A.xar. 这个文件包括一个 header,以及一个 squashfs loopback device image,简称 squanshfs image。这里 squashfs 是一个开源文件系统。感兴趣的朋友们可以参考这个教程,创建一个空文件,把它格式化成 squashfs,然后 mount 到本地文件系统的某个目录(mount point)里。待到我们 umount 的时候,曾经加入到 mount point 里的文件,就留在这个“空文件”里了。我们可以把它拷贝分发给其他人,大家都可以 mount 之,看到我们加入其中的文件。
因为 XAR 是在 squashfs image 前面加上了一个 header,所以没法用 mount -t squashf 命令来 mount,得用 mount -t xar 或者 xarexec -m 命令。比如,一个节点上如果有了 /packages/A-953bc.xar,我们可以用如下命令看到它的内容,而不需要耗费 CPU 资源来解压缩:
xarexec -m A-953bc.xar
这个命令会打印出一个临时目录,是 XAR 文件的 mount point。
分层
如果我们现在修改了 A.py,那么不管是 build 成 tarball 还是 XAR,整个包都需要重新更新。当然,只要 build system 支持 cache,我们是不需要重新生成各个 *.so 文件的。但是这个不解决我们需要重新分发 .tar.gz 和 .xar 文件到集群的各个节点的麻烦 —— 之前节点上可能有老版本的 A-953bc87fe.{tar.gz,xar} 了,但是不能复用。
为了复用 ,需要分层。
对于上面情况,我们可以根据模块依赖关系图,构造多个 XAR 文件。
A-953bc.xar --> B-953bc.xar --> D-953bc.xar -\
\-> C-953bc.xar --> E-953bc.xar --> F-953bc.xar
其中每个 XAR 文件里只有对应的 build rule 产生的文件。比如,F-953bc.xar 里只有 F.so。
这样,如果我们只修改了 A.py,则只有 A.xar 需要重新 build 和传送到集群节点上。这个节点可以复用之前已经 cache 了的 {B,C,D,E,F}-953bc.xar 文件。
假设一个节点上已经有 /packages/{A,B,C,D,E,F}-953bc.xar,我们是不是可以按照模块依赖顺序,运行 xarexec -m 命令,依次 mount 这些 XAR 文件到同一个 mount point 目录,既可得到其中所有的内容了呢?
很遗憾。不行。因为后一个 xarexec/mount 命令会报错 —— 因为这个 mount point 已经被前一个 xarexec/mount 命令占据了。
下面解释为什么文件系统 image 优于 tarball。
那退一步,不用 XAR 了,用 ZIP 或者 tar.gz 不行吗?可以,但是慢。我们可以把所有 .tar.gz 都解压缩到同一个目录里。但是如果 A.py 更新了,我们没法识别老的 A.py 并且替换为新的,而是得重新解压所有 .tar.gz 文件,得到一个新的文件夹。而重新解压所有的{B,C,D,E,F}.tar.gz很慢。
Overlay Filesystem
有一个申请的开源工具 fuse-overlayfs。它可以把几个目录”叠加“(overlay)起来。比如下面命令把 /tmp/{A,B,C,D,E,F}-953bc 这几个目录里的内容都”叠加“到 /pacakges/A-953bc 这个目录里。
fuse-overlayfs -o \
lowerdir="/tmp/A-953bc:/tmp/B-953bc:..." \
/packages/A-953bc
而 /tmp/{A,B,C,D,E,F}-953bc 这几个目录来自 xarcexec -m /packages/{A,B,C,D,E,F}-953bc.xar.
请注意在这里我引入了 overlay filesystem 的概念,为下文解释 Docker 预备。
fuse-overlayfs 是怎么做到这一点的呢?当我们访问任何一个文件系统目录,比如 /packages/A 的时候,我们使用的命令行工具(比如 ls )调用 system calls(比如 open/close/read/write) 来访问其中的文件。这些 system calls 和文件系统的 driver 打交道 —— 它们会问 driver:/packages/A 这个目录里有没有一个叫 A.py 的文件呀?
如果我们使用 Linux,一般来说,硬盘上的文件系统是 ext4 或者 btrfs。也就是说,Linux universal filesystem driver 会看看每个分区的文件系统是啥,然后把 system call 转发给对应的 ext4/btrfs driver 去处理。
一般的 filesystem drivers 和其他设备的 drivers 一样运行在 kernel mode 里。这是为什么一般我们运行 mount 和 umount 这类操作 filesystems 的命令的时候,都需要 sudo。而 FUSE 是一个在 userland 开发 filesystem driver 的库。
fuse-overlayfs 这命令利用 FUSE 这个库,开发了一个运行在 userland 的 fuse-overlayfs driver。当 ls 命令询问这个 overlayfs driver /packages/A-953bc 目录里有啥的时候,这个 fuse-overlayfs driver 记得之前用户运行过 fuse-overlayfs 命令把 /tmp/{A,B,C,D,E}-953bc 这几个目录给叠加上去过,所以它返回这几个目录里的文件。
此时,因为 /tmp/{A,B,C,D,E}-953bc 这几个目录其实是 /packages/{A,B,C,D,E,F}-953bc.xar 的 mount points,所以每个 XAR 就相当于一个 layer。
像 fuse-overlayfs driver 这样实现把多个目录“叠加”起来的 filesystem driver 被称为 overlay filesystem driver,有时简称为 overlay filesystems。
Docker Image and Layer
上面说到用 overlay filesystem 实现分层。用过 Docker 的人都会熟悉一个 Docker image 由多层构成。当我们运行 docker pull <image-name>命令的时候,如果本机已经 cache 了这个 image 的一部分 layers,则省略下载这些 layers。这其实就是用 overlay filesystem 实现的。
Docker 团队开发了一个 filesystem(driver)叫做 overlayfs —— 这是一个特定的 filesystem 的名字。顾名思义,Docker overlayfs 也实现了“叠加”(overlay)的能力,这就是我们看到每个 Docker image 可以有多个 layers 的原因。
Docker 的 overlayfs 以及它的后续版本 overlayfs2 都是运行在 kernel mode 里的 —— 这也是 Docker 需要机器的 root 权限的原因之一,而这又是 Docker 被诟病容易导致安全漏洞的原因。
有一个叫 btrfs 的 filesystem,是 Linux 世界里最近几年发展很迅速的,用于管理硬盘效果很好。这个 filesystem 的 driver 也支持 overlay。所以 Docker 也可以被配置为使用这个 filesystem 而不是 overlayfs —— 不过只有 Docker 用户的电脑的 local filesystem 是 btrfs 的时候,Docker 才能用 btrfs 在上面叠加 layers。所以说,如果你用的是 macOS 或者 Windows,那肯定没法让 Docker 使用 btrfs 了。
不过如果你用的是 fuse-overlayfs,那就是用了一副万灵药了。只是通过 FUSE 在 userland 运行的 filesystem 的性能很一般,不过本文讨论的情形对性能也没啥需求。其实 Docker 也可以被配置使用 fuse-overlayfs。Docker 支持的分层 filesystem 列表在这里 Docker storage drivers
Docker Image 的好处
总结上文所述,从编程到可以在集群上跑起来,我们要做几个步骤:
编译:把源码编译成可执行的形式。 打包:把编译结果纳入一个”包“里,以便部署和分发 传输:通常是集群管理系统(Borg、Kubernetes、Tupperware来做)。如果要在某个集群节点上启动 container,则需要把”包“传输到此节点上,除非这个节点曾经运行过这个程序,已经有包的 cache。 解包:如果”包“是 tarball 或者 zip,到了集群节点上之后需要解压缩;如果”包“是一个 filesystem image,则需要 mount。
把源码分成模块,可以让 1. 编译 这步充分利用每次修改只改动一小部分代码的特点,只重新编译被修改的模块,从而节省时间。
为了节省 2.、3. 和 4. 的时间,我们希望”包“是分层的。每一层最好只包含一个或者几个代码模块。这样,可以利用模块之间的依赖关系,尽量复用容纳底层模块的”层“。
在开源的世界里,我们用 Docker image 支持分层的特点,一个基础层可能只包括某个 Linux distribution(比如 CentOS)的 userland programs,如 ls、cat、grep 等。在其上,可以有一个层包括 CUDA。再其上安装 Python 和 PyTorch。再再之上的一层里是 GPT-3 模型的训练程序。这样,如果我们只是修改了 GPT-3 训练程序,则不需要重新打包和传输下面三层。
这里的逻辑核心是:存在”项目“(project)的概念。每个项目可以有自己的 repo,自己的 building system(GNU make、CMake、Buck、Bazel 等),自己的发行版本(release)。所以每个项目的 release 装进 Docker image 的一层 layer —— 与其前置多层合称为一个 image。
Google 和 Facebook 不需要 Docker
经过上述这么多知识准备,我们终于可以点题了。因为 Google 和 Facebook 使用 monolithic repository,使用统一的 build system(Google Blaze 或者 Facebook Buck),所以虽然也可以利用“项目”的概念把每个项目的 build result 装入 Docker image 的一层,但是实际上并不需要。
利用 Blaze 和 Buck 的 build rules 定义的模块,以及模块之间依赖关系,我们可以完全去打包和解包的概念 —— 没有了包,当然就不需要 zip、tarball、以及 Docker image 和 layers 了。
直接把每个模块当做一个 layer 既可 —— 如果 D.so 因为我们修改了 D.cpp 被重新编译,那么只重新传输 D.so 既可,而不需要去传输一个 layer 其中包括 D.so。
于是,在 Google 和 Facebook 里,受益于 monolithic repository 和统一的 build 工具,我们把上述四个步骤省略成了两个:
编译:把源码编译成可执行的形式。 传输:如果某个模块被重新编译,则传输这个模块。
Google 和 Facebook 没在用 Docker
上一节说了 monolithic repo 可以让 Google 和 Facebook 不需要 Docker image。现实是 Google 和 Facebook 没有在使用 Docker。这两个概念有区别。
历史上,Google 和 Facebook 使用超大规模集群先于 Docker 和 Kubernetes 的出现。当时为了打包方便,连 tarball 都没有。对于 C/C++ 程序,直接全静态链接,根本没有 *.so。于是一个 executable binary file 就是“包”了。直到今天,大家用开源的 Bazel 和 Buck 的时候,仍然可以看到默认链接方式就是全静态链接。
Java 语言虽然是一种“全动态链接”的语言,不过其诞生和演进扣准了互联网历史机遇,其开发者发明 jar 文件格式,从而支持了全静态链接。
Python 语言本身没有 jar 包,所以 Blaze 和 Bazel 发明了 PAR 文件格式(英语叫 subpar),相当于为 Python 设计了一个 jar。开源实现在这里。类似的,Buck 发明了 XAR 格式,也就是我上文所说的 squashfs image 前面加了一个 header。其开源实现在这里。
Go 语言默认就是全静态链接的。在 Rob Pike 早先的一些总结里提到,Go 的设计很大程度上就是绕坑而行 —— 绕开 Google C/C++ 实践中遇到过的各种坑。比如支持全静态链接,也包括支持 Google C++ style guide 提倡使用的那一部分 C++ 语法。
简单的说,历史上 Google 和 Facebook 没有在用 Docker image,很重要的一个原因是,其 build system 对各种常见语言的程序都可以全静态链接,所以可执行文件就是“包”。
但这并不是最好的解法 —— 毕竟这样就没有分层了。哪怕我只是修改了 main 函数里的一行代码,重新编译和发布,都需要很长时间 —— 十分钟甚至数十分钟 —— 要知道全静态链接得到的可执行文件往往大小以 GB 计。
所以全静态链接虽然是 Google 和 Facebook 没有在用 Docker 的原因之一,但是并不是一个好选择。 所以也没被其他公司效仿。大家还是更愿意用支持分层 cache 的 Docker image。
完美解法的技术挑战
完美的解法应该支持分层 cache(或者更精确的说是分块 cache)。所以还是应该用上文介绍的 monolithic repo 和统一 build system 的特点。
但是这里有一个技术挑战 —— build system 描述的模块,而模块通常比“项目”细粒度太多了。以 C/C++ 语言为例,如果每个模块生成一个 .so 文件,当做一个“层“或者”块“以便作为 cache 的单元,那么一个应用程序可能需要的 .so 数量就太多了。启动应用的时候,恐怕要花几十分钟来 resolve symbols 并且完成链接。
所以呢,虽然 monolithic repo 有很多好处,它也有一个缺点,不像开源世界里,大家人力的把代码分解成“项目”,每个项目通常是一个 GitHub repo,其中可以有很多模块,但是每个项目里所有模块 build 成一个 *.so 作为一个 cache 的单元。因为一个应用程序依赖的项目数量总不会太多,从而控制了 layer 的总数。
好在这个问题并非无解。既然一个应用程序对各个模块的依赖关系是一个 DAG,那么我们总可以想办法做一个 graph partitioning,把这个 DAG 分解成不那么多的几个子图。仍然以 C/C++ 程序为例,我们可以把每个子图里的每个模块编译成一个 .a,而每个子图里的所有 .a 链接成一个 *.so,作为一个 cache 的单元。
于是,如何设计这个 graph partitioning 算法就成了眼前最重要的问题了。 也不排除跳过这个 graph partitioning 的挑战,直接采用 Docker image 或者类似的技术,比如用 btrfs 而不是 overlayfs。
往期推荐
END
若觉得文章对你有帮助,随手转发分享,也是我们继续更新的动力。
长按二维码,扫扫关注哦
✬「C语言中文网」官方公众号,关注手机阅读教程 ✬

目前收集的资料包括: Java,Python,C/C++,Linux,PHP,go,C#,QT,git/svn,人工智能,大数据,单片机,算法,小程序,易语言,安卓,ios,PPT,软件教程,前端,软件测试,简历,毕业设计,公开课 等分类,资源在不断更新中...