
spark shuffle的几种特殊情况
共 3041字,需浏览 7分钟
·
2021-06-15 21:22
1.shuffle概览
一个spark的RDD有一组固定的分区组成,每个分区有一系列的记录组成。对于由窄依赖变换(例如map和filter)返回的RDD,会延续父RDD的分区信息,以pipeline的形式计算。每个对象仅依赖于父RDD中的单个对象。诸如coalesce之类的操作可能导致任务处理多个输入分区,但转换仍然被认为是窄依赖的,因为一个父RDD的分区只会被一个子RDD分区继承。
sc.textFile("someFile.txt").map(mapFunc).flatMap(flatMapFunc).filter(filterFunc).count()
上面的代码片段只有一个action操作,count,从输入textfile到action经过了三个转换操作。这段代码只会在一个stage中运行,因为,三个转换操作没有shuffle,也即是三个转换操作的每个分区都是只依赖于它的父RDD的单个分区。
但是,下面的单词统计就跟上面有很大区别:
val tokenized = sc.textFile(args(0)).flatMap(_.split(' '))val wordCounts = tokenized.map((_, 1)).reduceByKey(_ + _)val filtered = wordCounts.filter(_._2 >= 1000)val charCounts = filtered.flatMap(_._1.toCharArray).map((_, 1)).reduceByKey(_ + _)charCounts.collect()
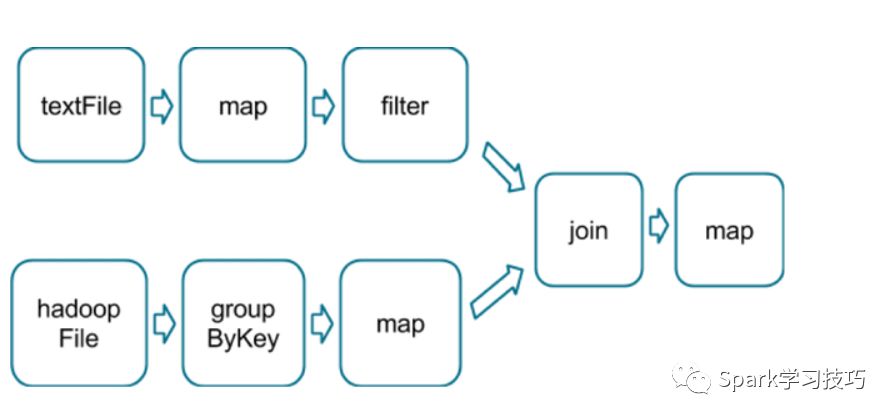
粉框圈住的就是整个DAG的stage划分。
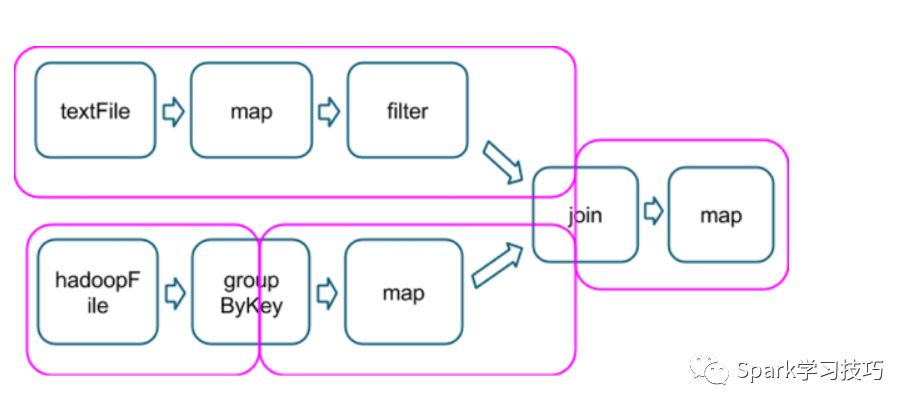
2.优化shuffle
3. no shuffle
rdd1 = someRdd.reduceByKey(...)rdd2 = someOtherRdd.reduceByKey(...)rdd3 = rdd1.join(rdd2)
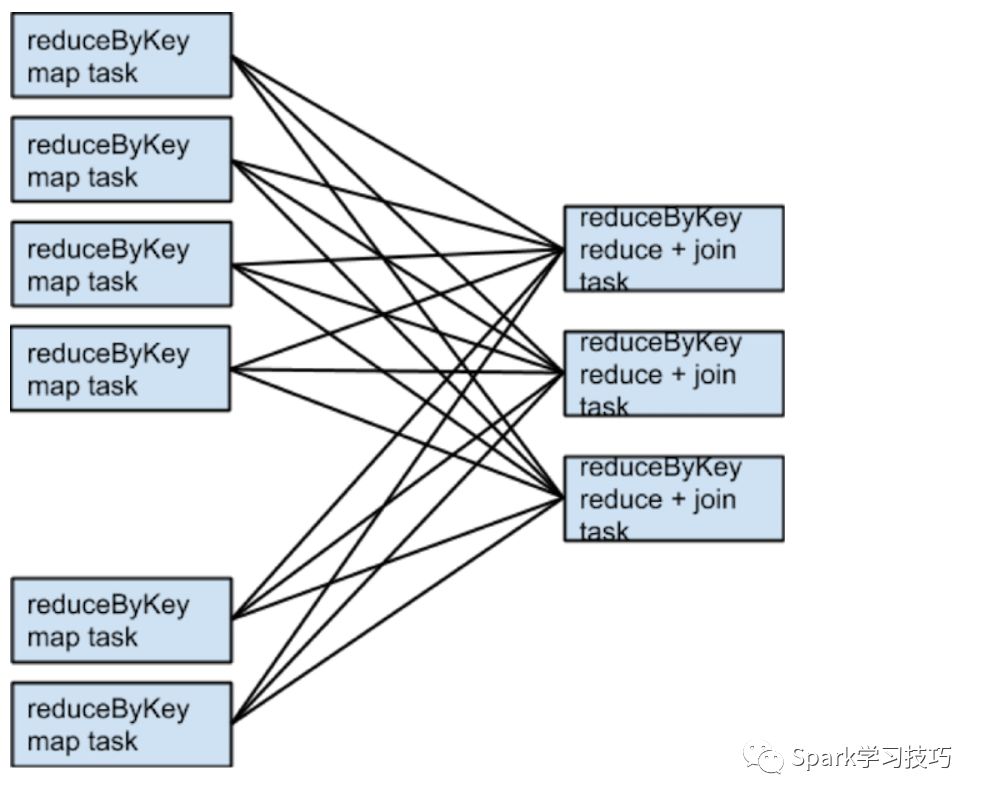
如果rdd1和rdd2使用不同的分区器或者相同的分区器不同的分区数,仅仅一个数据集在join的过程中需要重新shuffle
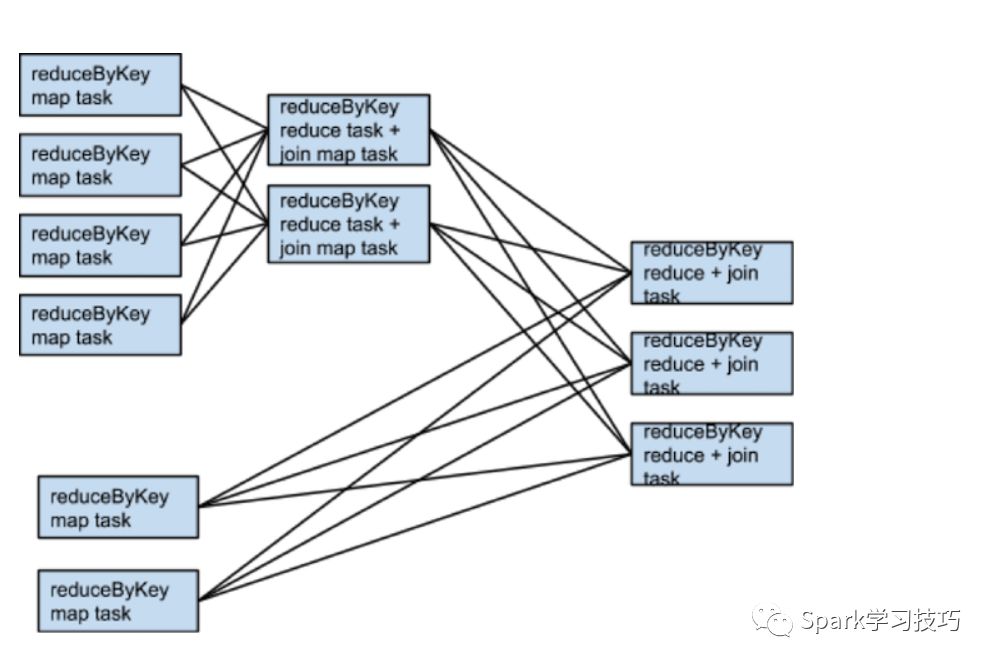
在join的过程中为了避免shuffle,可以使用广播变量。当executor内存可以存储数据集,在driver端可以将其加载到一个hash表中,然后广播到executor。然后,map转换可以引用哈希表来执行查找。
4.增加shuffle
有时候需要打破最小化shuffle次数的规则。
当增加并行度的时候,额外的shuffle是有利的。例如,数据中有一些文件是不可分割的,那么该大文件对应的分区就会有大量的记录,而不是说将数据分散到尽可能多的分区内部来使用所有已经申请cpu。在这种情况下,使用reparition重新产生更多的分区数,以满足后面转换算子所需的并行度,这会提升很大性能。
使用reduce和aggregate操作将数据聚合到driver端,也是修改区数的很好的例子。
在对大量分区执行聚合的时候,在driver的单线程中聚合会成为瓶颈。要减driver的负载,可以首先使用reducebykey或者aggregatebykey执行一轮分布式聚合,同时将结果数据集分区数减少。实际思路是首先在每个分区内部进行初步聚合,同时减少分区数,然后再将聚合的结果发到driver端实现最终聚合。典型的操作是treeReduce 和 treeAggregate。
当聚合已经按照key进行分组时,此方法特别适用。例如,假如一个程序计算语料库中每个单词出现的次数,并将结果使用map返回到driver。一种方法是可以使用聚合操作完成在每个分区计算局部map,然后在driver中合并map。可以用aggregateByKey以完全分布的方式进行统计,然后简单的用collectAsMap将结果返回到driver。
推荐阅读: