
阿里二面:group by 怎么优化?
01 前言
哈喽,我是狗哥,好久不见呀!是的,我又又换了工作。最近一直在面试这几天刚好整理下在面试中被问到有意思的问题,也借此机会跟大家分享下。
这家企业的面试官有点意思,一面是个同龄小哥,一起聊了两个小时(聊到我嘴都干了)。二面是个从阿里出来的架构师,视频面试,我做完自我介绍之后,他一开场就问我:
对 MySQL 熟悉吗?
我一愣,随之意识到这是个坑。他肯定想问我某方面的原理了,恰好我研究过索引。就回答:
对索引比较熟悉。
他:
group by 是怎么实现分组的?
还好我又复习,基本上 group by 用法、工作原理、怎么优化之类的都答到点子上。今天也跟大家盘一盘 group by,我将从原理讲到最终优化,给大家聊聊 group by,希望对你有所帮助。
国际惯例,先上思维导图。
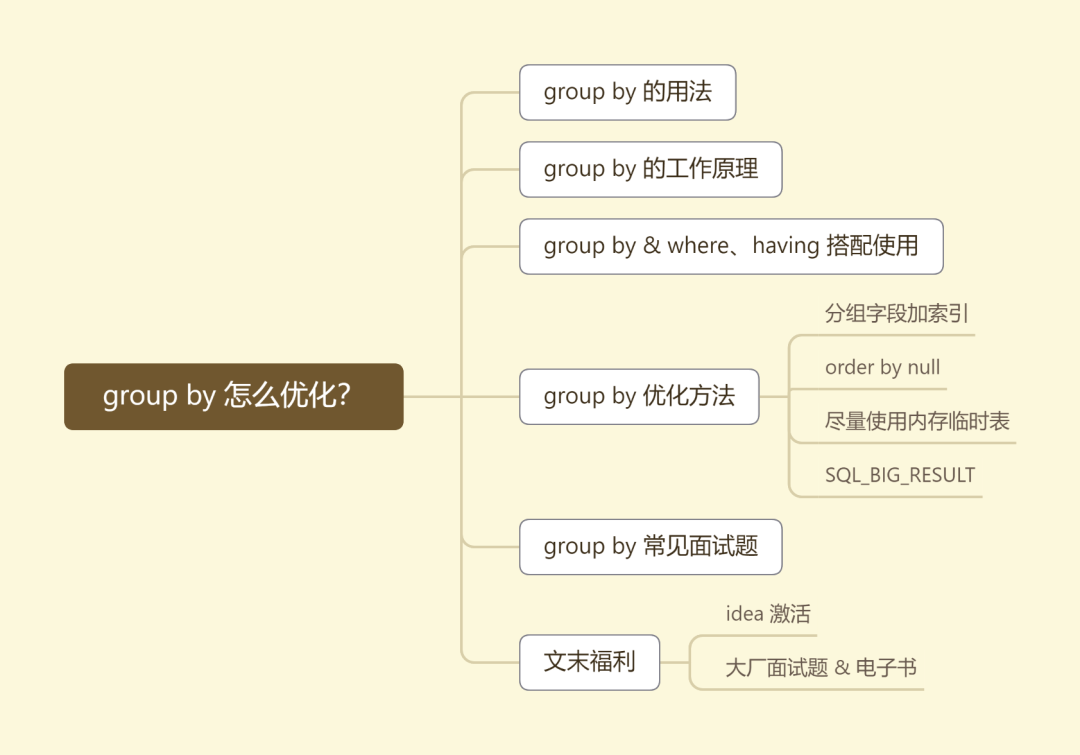
02 一个简单的例子
还是借我们之前讲 order by 时创建的商品订单表来演示。建表语句:
CREATE TABLE `sale_order` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键',
`user_code` varchar(64) NOT NULL COMMENT '用户编号',
`goods_name` varchar(64) NOT NULL COMMENT '商品名称',
`order_date` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '下单时间',
`city` varchar(64) DEFAULT NULL COMMENT '下单城市',
`order_num` int(10) NOT NULL COMMENT '订单数量',
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=10001 DEFAULT CHARSET=utf8 ROW_FORMAT=COMPACT COMMENT='商品订单表';
数据如下,我之前就导入准备好的:
数据准备好了,需求也来了。现在产品要求统计表中每个城市的下单人数,这个需求是不是很简单?sql 语句我们也可以很快给出:
select city, count(*) as num from sale_order group by city;
这条 sql 的结果也很快就出来了:
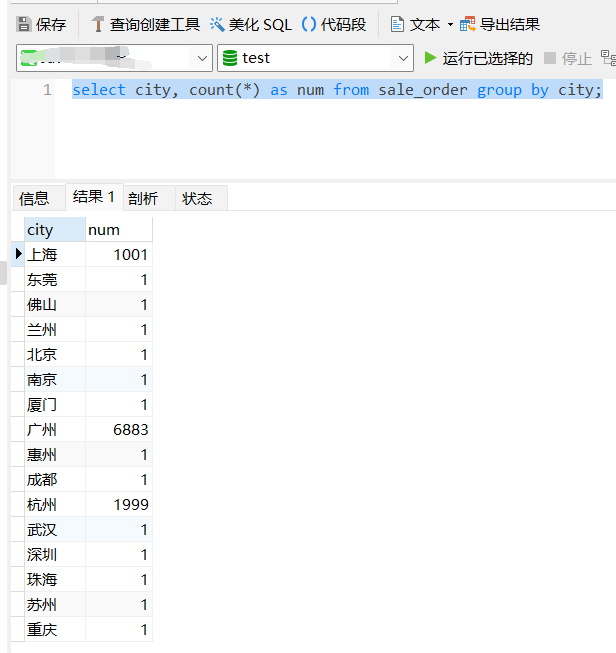
sql 我们会写,结果也很快就出来了。但是原理你知道么?执行流程又是怎样的呢?
03 group by 的原理
3.1 explain 分析
废话不多说,遇事不决 explain。想要知道 sql 的性能咋样,怎么执行的,都要用 explain 分析。想要知道 explain 的每个指标代表啥意思,可以看我之前的文章:《explain 很重要吗?》
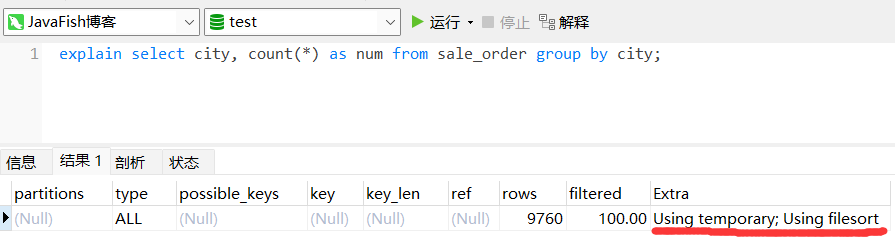
注意到最后一列 Extra ,这列代表的是 sql 执行过程中会做什么?上图中这列有两个值,一个是 Using temporary,一个是 Using filesort。
Using temporary:代表需要用到临时表。OS:这是个啥??? Using filesort:需要排序。OS:挖草,还需要排序???
要想搞明白为什么需要临时表和排序,我们就得分析 group by 的执行流程了。
3.2 执行流程
根据 explain 分析,我们知道执行过程中肯定有创建临时表和排序两个步骤,下面来分析一下:
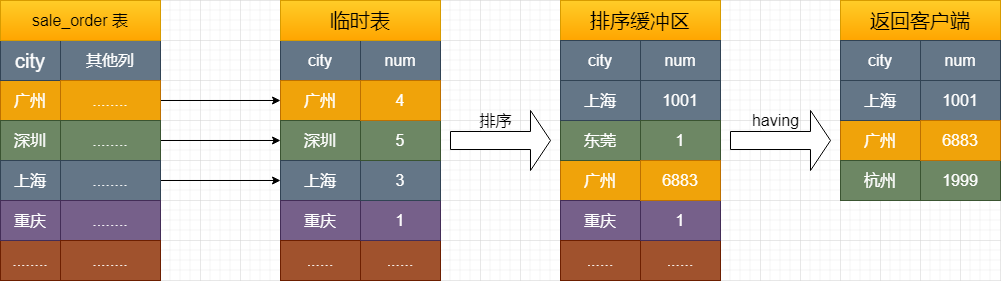
创建内存临时表,表里面有两个字段:city 和 num; 全表扫描 sale_order 表,取出 city = 某城市(比如广州、深圳、上海,囊括你表里涉及到的城市)的记录 临时表没有 city = 某城市的记录,直接插入,并记为 (某城市,1); 临时表里有 city = 某城市的记录,直接更新,把 num 值 +1 重复步骤 2 直至遍历完成,根据 city 字段做排序,然后把结果集返回客户端。
至此整个过程就完事了。我知道这样不直观,所以我又画个图,方便你们理解:
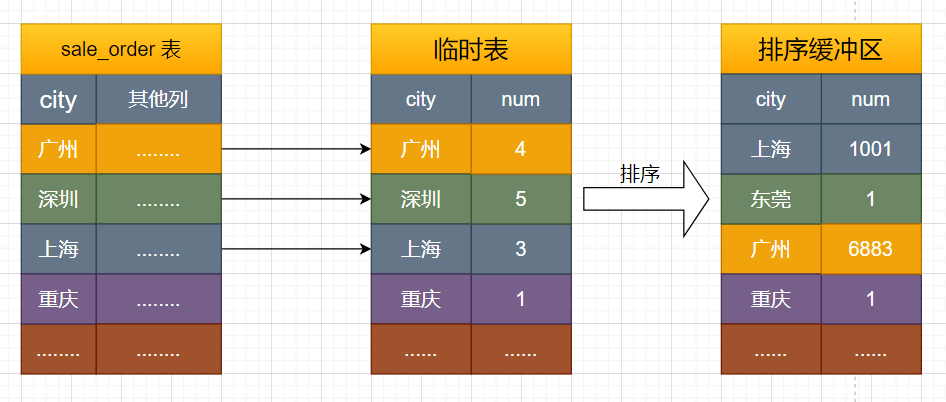
图中最后一步,对内存临时表的排序,具体的细节在之前的 《order by 是怎么排序的?》一文章中已经有过介绍,欢迎点击跳转。同样是非常细节的一个 mysql 关键字,强烈推荐你去看下。
04 group by 中使用 where & having
写到这里,有小伙伴就说了。狗哥你这里描述的只是 group by 的单独执行过程,很简单呀。我也会,如果加上 where 或者 having 或者两者都加上的时候的执行过程是怎样的呢?
4.1 group by + where
现在产品又改需求统计每个城市下的下单人数,且下的订单量要大于 2。OS:mmp,又改
按照惯例,看到 where 我们一般想到怎么优化?没错,加索引嘛。
加索引:
alter table sale_order add index idx_order_num (order_num);
最终语句:
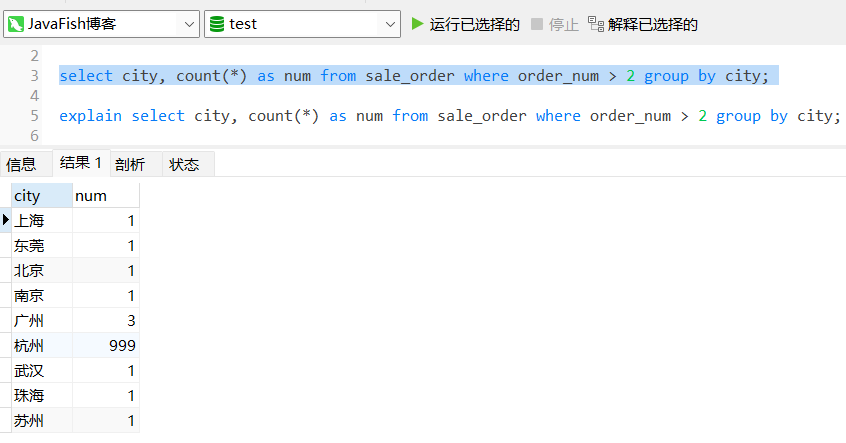
select city, count(*) as num from sale_order where order_num > 2 group by city;
结果:
explain 分析:
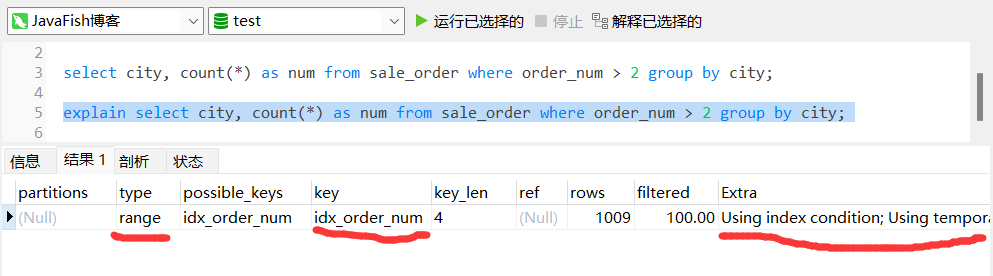
从上图得知,加上索引之后。这条语句命中了索引 idx_order_number,并且此时的 Extra 多了 Using index Condition 的执行计划。type 变成了 range 说明不用全表扫描。
解释下 Using index Condition:会先条件过滤索引,过滤完索引后找到所有符合索引条件的数据行,常见于 where 中有 between > < 等条件的 sql 语句。
它的出现说明这个语句先走索引过滤掉不符合 where 条件的数据,再去统计,然后排序,最后返回客户端。流程如下:
创建内存临时表,表里面有两个字段:city 和 num; 根据索引 idx_order_num 找到大于 2 的数据的主键 ID; 通过主键 ID 取出 city = 某城市(比如广州、深圳、上海,囊括你表里涉及到的城市)的记录; 临时表没有 city = 某城市的记录,直接插入,并记为 (某城市,1); 临时表里有 city = 某城市的记录,直接更新,把 num 值 +1。 重复 2、3 步骤,直至找到所有吗,满足 order_num > 2 的记录。根据 city 字段做排序,然后把结果集返回客户端。
PS:回表的概念我就不说了哈,有兴趣的可以看我之前的《MySQL 索引详解》文章,强烈建议你去看,非常重要的是概念。
4.2 group by + having
现在产品又改需求统计每个城市的下单的人数,且总的下单人数需要在 100 以上。OS:mmp,又改
根据需求很快写出 sql 语句:
select city, count(*) as num from sale_order group by city having num > 100;
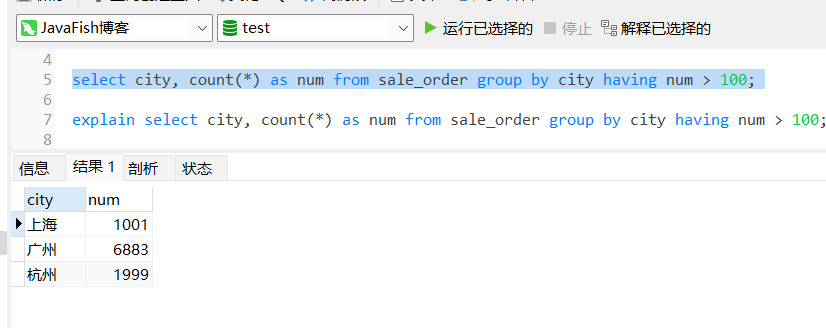
再用 explain 分析一下,得出如下结果:
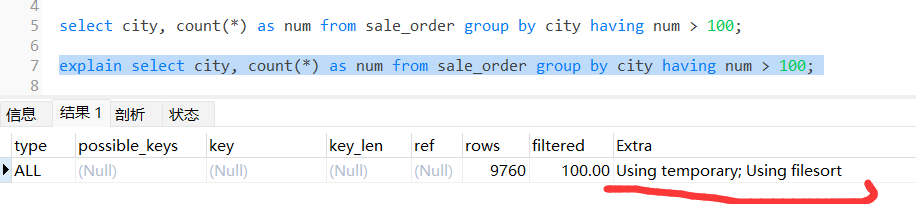
哇草,咋回事?跟没加 having 的执行流程一样的?你没看错,其实 having 不直接参与到执行计划中去,它是对结果集操作的,所以这里的加的 having 跟没加是一样的执行计划。画个图,大概就是这样的:
4.3 group by + where + having
现在产品又改需求统计每个城市的下单超过两单的人数,且总的人数需要在 100 以上。OS:mmmp,又改
按照惯例,我们给 where 条件加上索引:
alter table sale_order add index idx_order_num (order_num);
根据需求很快写出 sql 语句:
select city, count(*) as num from sale_order where order_nunm > 2 group by city having num > 100;
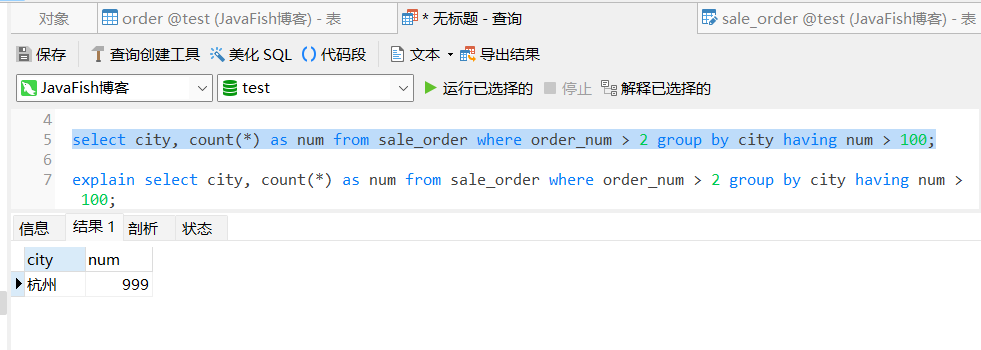
explain 结果:
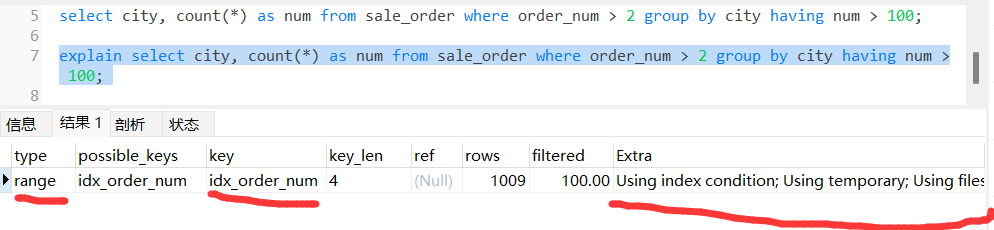
执行流程:
创建内存临时表,表里面有两个字段:city 和 num; 根据索引 idx_order_num 找到大于 2 的数据的主键 ID; 通过主键 ID 取出 city = 某城市(比如广州、深圳、上海,囊括你表里涉及到的城市)的记录; 临时表没有 city = 某城市的记录,直接插入,并记为 (某城市,1); 临时表里有 city = 某城市的记录,直接更新,把 num 值 +1。 重复 2、3 步骤,直至找到所有吗,满足 order_num > 2 的记录。根据 city 字段做排序。 having 对结果集进行过滤,并返回客户端
不难看出这里的执行流程跟 4.1 一样就多了个 having 过滤
05 group by 优化
根据上面的分析,我们知道 group by 是需要创建临时表并且排序的。耗时也应该在这两个步骤,那我们应该从这两个步骤入手优化。
如果分组字段本身就是有序的,我们是不是就不用排序了?或者我们的需求并没有要求排序是不是就可以优化了?如果必须使用临时表,我们是不是可以只用内存临时表呢?如果数据量实在是太大,是不是可以直接用磁盘临时表,而不是发现内存临时表不够大才用它呢?
以上可以总结出四个优化方案:
分组字段加索引 order by null 不排序 尽量使用内存临时表 SQL_BIG_RESULT
5.1 分组字段加索引
select city, count(*) as num from sale_order group by city;
上面的 sql 中,city 没加索引,所以这时的 group by 还是要使用临时表的。那我们可不可以个组合索引 idx_city,结果如下所示:
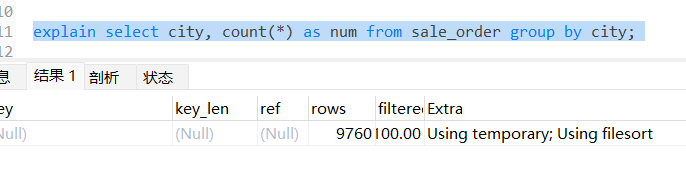
加索引:
alter table sale_order add index idx_city (city);
结果:
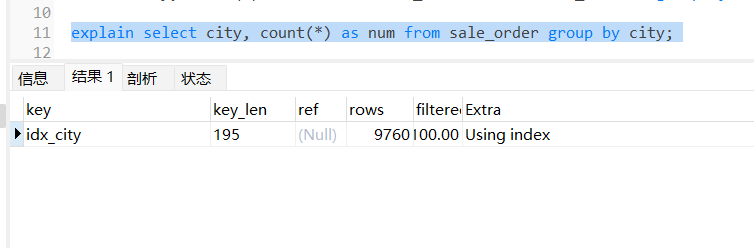
Extra 是不是 Using temporary 和 Using filesort 都没了?所以不用排序也不用临时表啦。那有小伙伴又问了,那我有 where 条件怎么办?那就加组合索引呗:
alter table sale_order add index idx_order_num_city(order_num,city);
但是这种情况只适用于 where 条件是等值的,如果有大于、小于的情况还是避免不了排序和使用临时表。适用情况:
select city, count(*) as num from sale_order where order_num = 2 group by city;
不适用情况:
select city, count(*) as num from sale_order where order_num > 2 group by city;
5.2 order by null 避免排序
如果需求是不用排序,我们就可以这样做。在 sql 末尾加上 order by null
select city, count(*) as num from sale_order where order_num > 2 group by city order by null;
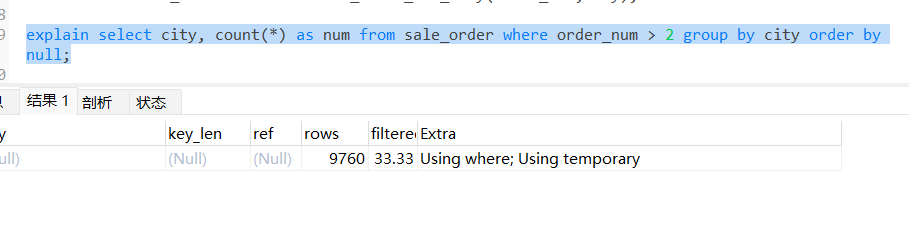
从分析结果看,还是需要使用临时表的。
5.3 尽量使用内存临时表
有些小伙伴可能很懵哈,内存临时表是啥?其实 mysql 临时表分内存临时表和磁盘临时表。但是这里就不展开了,有时间专门写一篇文章介绍。
group by 在执行过程中使用内存临时表还是不够用,那就会使用磁盘临时表。内存临时表的大小是有限制的,mysql 中 tmp_table_size 代表的就是内存临时表的大小,默认是 16M。当然你可以自定义社会中适当大一点,这就要根据实际情况来定了。
比如:可以设置成 32M,也就是 33554432 字节。
set tmp_table_size=33554432;
5.4 SQL_BIG_RESULT
如果数据量实在过大,大到内存临时表都不够用了,这时就转向使用磁盘临时表。而发现不够用再转向这个过程也是很耗时的,那我们有没有一种方法,可以告诉 mysql 从一开始就使用 磁盘临时表呢?
有的,在 group by 语句中加入 SQL_BIG_RESULT 提示 MySQL 优化器直接用磁盘临时表。优化器分析,磁盘临时表是 B+ 树存储,存储效率不如数组来得高。所以直接用数组存储。用法如下:
select SQL_BIG_RESULT city, count(*) as num from sale_order where group by city;
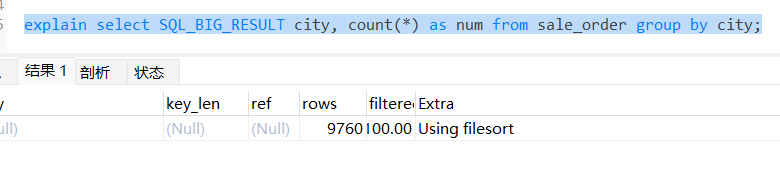
此时的执行过程就不需要创建临时表啦:
初始化 sort_buffer(排序缓冲区),放入 city 字段; 扫描 sale_order 表,取出 city 的值存入 sort_buffer 中; 扫描完成后,对 sort_buffer 的字段 city 做排序(如果 sort_buffer 内存不够用,就会利用磁盘临时文件辅助排序); 排序完成后,就得到了一个有序数组。 根据有序数组,得到数组里面的不同值,以及每个值的出现次数
06 group by 面试题
6.1 group by 一定要配合聚合函数使用吗?
不一定,以下 sql 语句,我用的 MySQL 5.7.13 运行是报错的;但是我司的 MySQL 8.0 版本是没有问题的。
select goods_name, city from sale_order group by city;
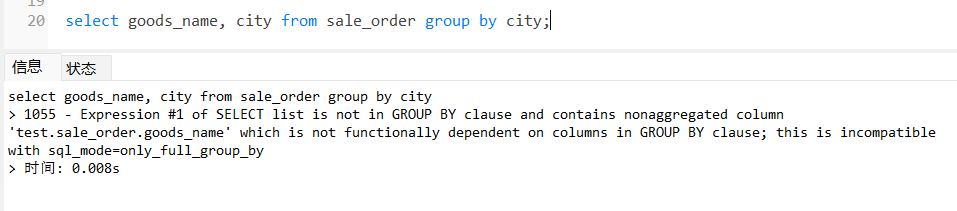
出现这个错误的原因是 mysql 的 sql_mode 开启了 ONLY_FULL_GROUP_BY 模式。查看 sql_mode:
select @@GLOBAL.sql_mode;
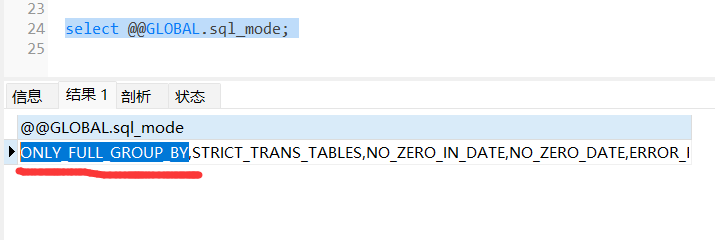
如果想要不做限制的话,直接重新设置 sql_mode 的值,把 ONLY_FULL_GROUP_BY 去掉即可。当然,开启这个要慎重,有可能会造成一些意想不到的错误,一般情况下还是加上这个设置比较稳妥。
6.2 group by 后面的一定要出现在 select 中吗?
不一定,我的就没报错。当然,这个还跟版本有关系。大家可以回去自己实践下。
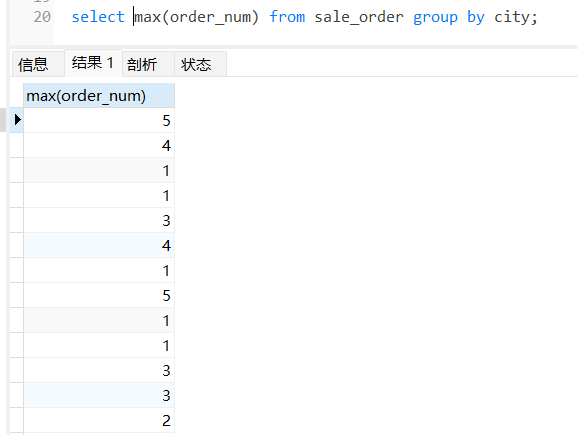
select max(order_num) from sale_order group by city;
6.1 where & having 的区别?
where 用于条件筛选,having 用于分组后筛选 where 条件后面不能跟聚合函数,having 一般配合 group by 或者聚合函数(min、max、avg、count、sum)使用 where 用在 group by 之前,having 用在 group by 之后
07 参考链接
https://time.geekbang.org/column/article/80477?cid=100020801 https://www.cnblogs.com/perfei/p/14677933.html https://cloud.tencent.com/developer/article/1941787 https://blog.csdn.net/ryan007liu/article/details/91441479 https://www.cnblogs.com/muhy/p/10558849.html
08 总结
本文我们聊了 group by 的基本和进阶用法,还用 explain 分析了不同 group by 的执行流程;从上面的分析中知道了 group by 的性能瓶颈是使用临时表和排序,从这两个方面提出了分组字段加索引、order by null、尽量使用内存临时表以及使用 SQL_BIG_RESULT 优化等 4 个优化方案,最后还聊了下 group by 常见的面试题。
完
往期推荐

巨坑!这公司的行为,挺适合清明节!

美国国家安全局是如何入侵你的电脑的?

我滴个乖乖,我复现了Spring的漏洞,害怕!
有道无术,术可成;有术无道,止于术
欢迎大家关注Java之道公众号
好文章,我在看❤️