
AutoFormer:Vision Transformer + NAS 一个较为Solid的工作
Vision Transformer + 网络结构搜索,面向参数高效的Vit设计——Autoformer(ICCV2021)
AutoFormer: Searching Transformers for Visual Recognition
arxiv: https://arxiv.org/abs/2107.00651
repo: https://github.com/microsoft/Cream/tree/main/AutoFormer

解决什么问题?
autformer使用NAS的方法自动去选择transformer设计中的关键参数,比如,网络深度,embedding的维度,MHSA(Multi Head Self Attention)中head的数目 针对不同的场景需求可以直接得到相应的ViT,也就是once-for-all
解决这个问题里面什么关键点,idea是什么
解决上述两个问题,第一个问题的就是设置对应超参搜索空间,第二个问题也是这篇文章的核心贡献,once-for-all的特点则是通过weight entanglement。
文章整体的流程与SPOS[1]类似,不同点在于SPOS采用的weight sharing与Autoformer的weight entanglement之间。对比图见下:
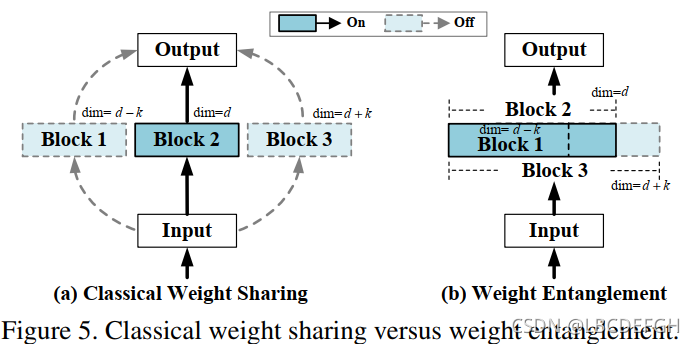
前者同一操作不同超参对应不同分支。而后者同一操作,不同超参对应的参数从子集里拿,不同超参对应的参数训练相互纠缠。
为什么不用weight sharing而去使用weight entanglement
在上面我们讲了不同,但没有讲为什么要用,在这里给出对比图:
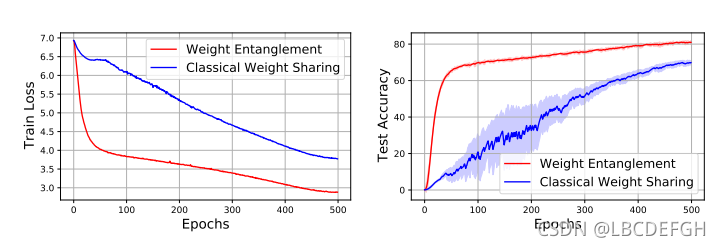
总结下来就是:
训练收敛慢 精度差 weight sharing需要保留所有候选操作的参数,而weight entanglement只需要保留最大超参设置对应的参数
具体实现流程
搜索空间的设计:
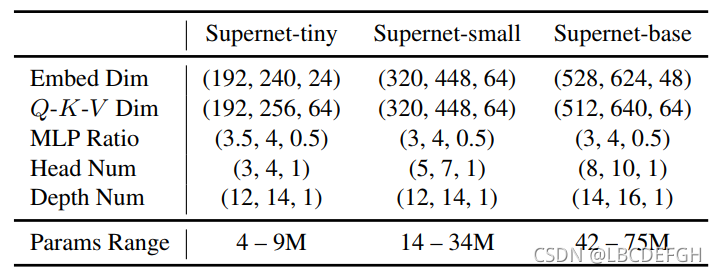
(最小值,最大值,步长),主要针对DeiT-tiny, DeiT-small,DeiT-base三个参数量级。
整体的示意图见下:
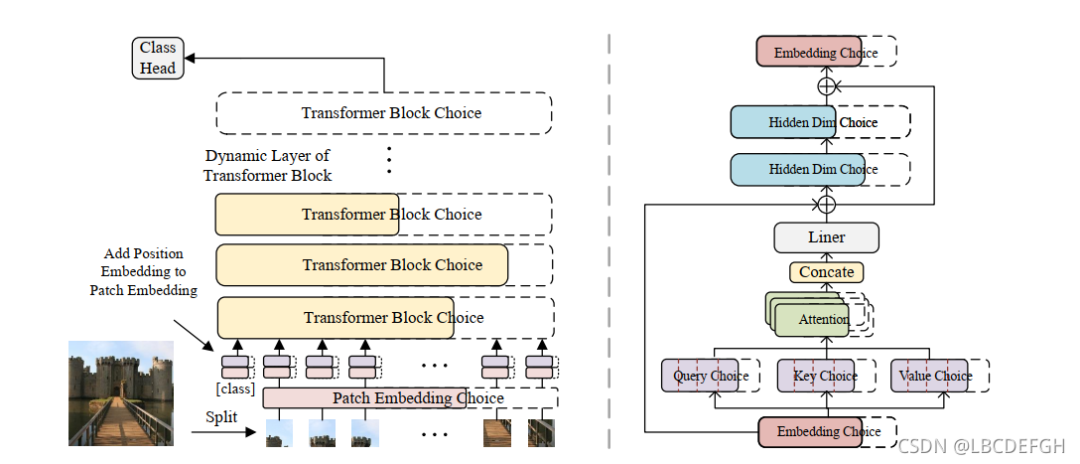
整体的操作流程:
基于weight entanglement训练supernet,在预设置好的搜索空间采样到子网,更新子网的参数,冻结其余的参数不使其更新。 采用进化算法得到参数量最小精度最高的模型。
效果
once-for-all的效果:
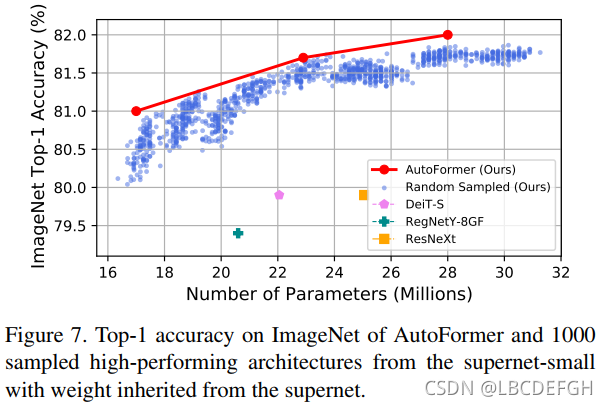
可以看到采样出来的子网直接继承超网的参数就可以有很好的效果
NAS搜索的效果对比:
可以看到在参数量和acc的trade-off上有很好的表现
笔者谈
该文章与2020年的HAT[2]比较相像,都是基于weight entanglement,只不过HAT聚焦于NLP领域,HAT的示意图见下:
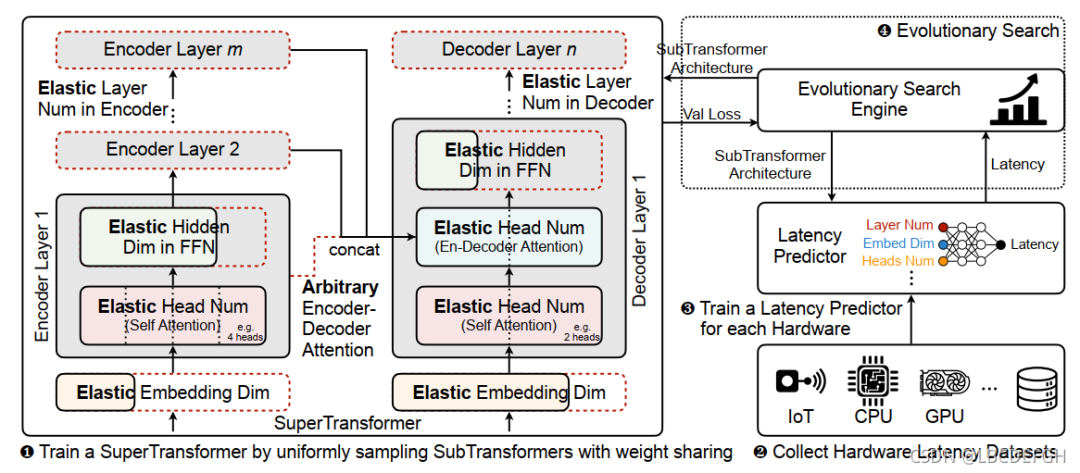
Autoformer claim:

但是该关键性的不同可能来源于Deit较强的训练策略,以及imagenet较大的数据量,至于另外一个不同也只是因为面向不同任务模型结构的不同,不涉及到具体实现以及关键性技术不同。总而言之,autoformer与HAT的不同主要来源于面向任务和数据集不同,关键性技术与思想是一致的。
但不管怎样,Autoformer是ViT+NAS踏出去的一个很solid的工作。
参考文献
[1] Zichao Guo, Xiangyu Zhang, Haoyuan Mu, Wen Heng, Zechun Liu, Yichen Wei, and Jian Sun. Single path one-shot neural architecture search with uniform sampling. ECCV,
[2] Hanrui Wang, Zhanghao Wu, Zhijian Liu, Han Cai, Ligeng Zhu, Chuang Gan, and Song Han. Hat: Hardware-aware transformers for efficient natural language processing. arXiv preprint arXiv:2005.14187, 2020.