
Pandas爬虫,竟能如此简单!

pandas中的pd.read_html()这个函数,功能非常强大,可以轻松实现抓取Table表格型数据。无需掌握正则表达式或者xpath等工具,短短的几行代码就可以将网页数据抓取下来。
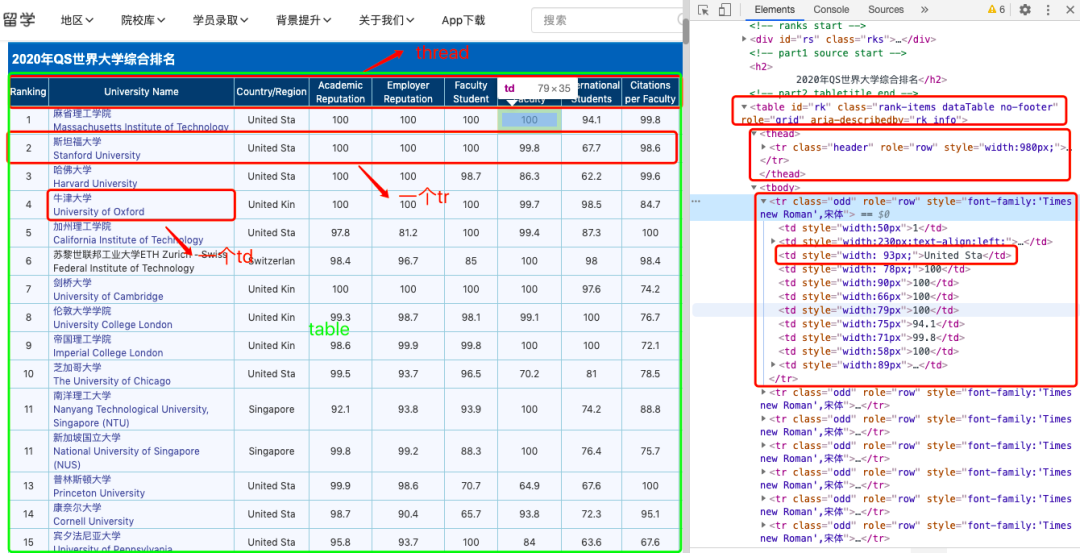
Table表格一般网页结构

针对网页结构类似的表格类型数据,pd.read_html可以将网页上的表格数据都抓取下来,并以DataFrame的形式装在一个list中返回。
三.pd.read_html语法及参数
基本语法
主要参数
1import pandas as pd
2import csv
3url1 = 'http://www.compassedu.hk/qs'
4df1 = pd.read_html(url1)[0] #0表示网页中的第一个Table
5df1.to_csv('世界大学综合排名.csv',index=0)
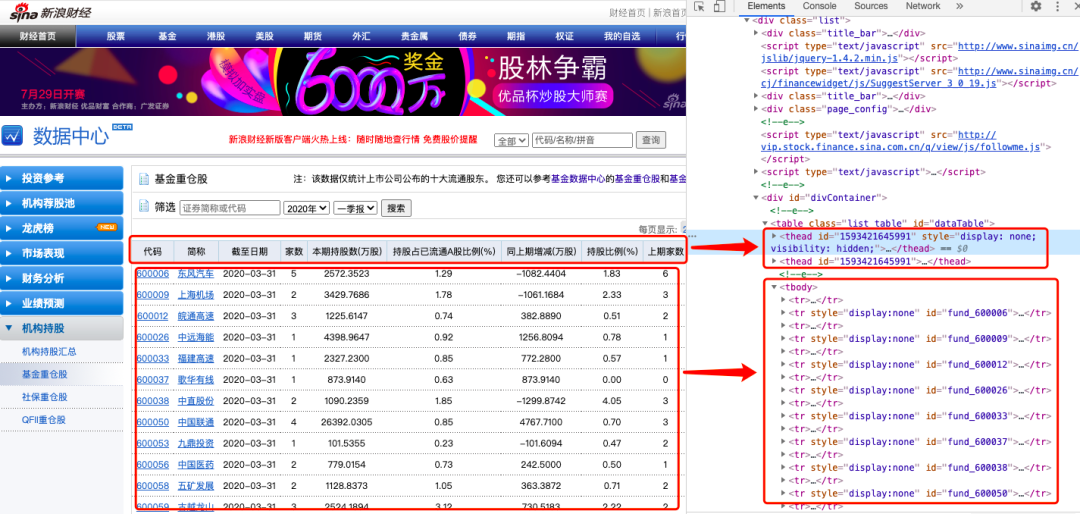
二.案例2:抓取新浪财经基金重仓股数据(6页数据)
1import pandas as pd
2import csv
3df2 = pd.DataFrame()
4for i in range(6):
5 url2 = 'http://vip.stock.finance.sina.com.cn/q/go.php/vComStockHold/kind/jjzc/index.phtml?p={page}'.format(page=i+1)
6 df2 = pd.concat([df2,pd.read_html(url2)[0]])
7 print('第{page}页抓取完成'.format(page = i + 1))
8df2.to_csv('./新浪财经数据.csv',encoding='utf-8',index=0)
没错,8行代码搞定,还是那么简单。如果对翻页爬虫不理解,可查看本公众号历史原创文章「实战|手把手教你用Python爬虫(附详细源码)」,如果对DataFrame合并不理解,可查看本公众号历史原创文章「基础|Pandas常用知识点汇总(四)」。
我们来预览下爬取到的数据:
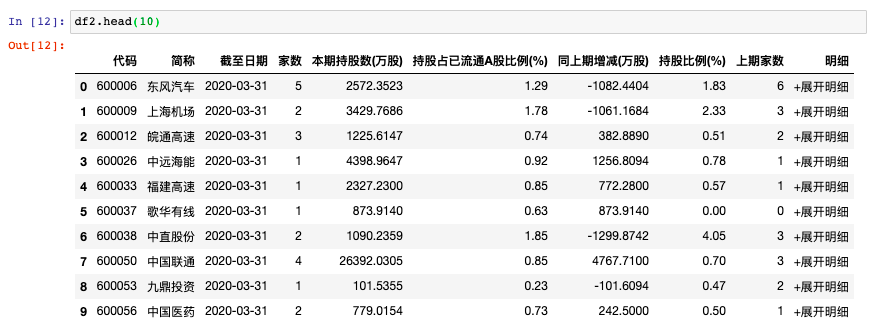
基金重仓股数据
三.案例3:抓取证监会披露的IPO数据(217页数据)
1import pandas as pd
2from pandas import DataFrame
3import csv
4import time
5start = time.time() #计时
6df3 = DataFrame(data=None,columns=['公司名称','披露日期','上市地和板块','披露类型','查看PDF资料']) #添加列名
7for i in range(1,218):
8 url3 ='http://eid.csrc.gov.cn/ipo/infoDisplay.action?pageNo=%s&temp=&temp1=&blockType=byTime'%str(i)
9 df3_1 = pd.read_html(url3,encoding='utf-8')[2] #必须加utf-8,否则乱码
10 df3_2 = df3_1.iloc[1:len(df3_1)-1,0:-1] #过滤掉最后一行和最后一列(NaN列)
11 df3_2.columns=['公司名称','披露日期','上市地和板块','披露类型','查看PDF资料'] #新的df添加列名
12 df3 = pd.concat([df3,df3_2]) #数据合并
13 print('第{page}页抓取完成'.format(page=i))
14df3.to_csv('./上市公司IPO信息.csv', encoding='utf-8',index=0) #保存数据到csv文件
15end = time.time()
16print ('共抓取',len(df3),'家公司,' + '用时',round((end-start)/60,2),'分钟')
这里注意要对抓下来的Table数据进行过滤,主要用到iloc方法,详情可查看本公众号往期原创文章「基础|Pandas常用知识点汇总(三)」。另外,我还加了个程序计时,方便查看爬取速度。
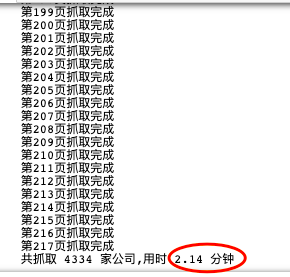
2分钟爬下217页4334条数据,相当nice了。我们来预览下爬取到的数据:
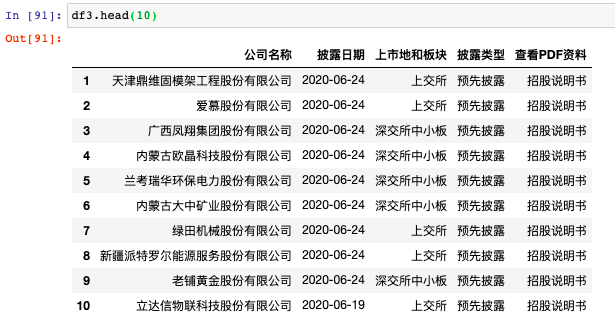
上市公司IPO数据
需要注意的是,并不是所有表格都可以用pd.read_html爬取,有的网站表面上看起来是表格,但在网页源代码中不是table格式,而是list列表格式。这种表格则不适用read_html爬取,得用其他的方法,比如selenium。
相关阅读:
评论