
得物App:发热监控的最佳实践
目录
一、背景
二、发热定义
三、指标获取
1. 温度
2. CPU使用率
3. GPU使用率
4. 系统服务使用
5. 线程堆栈
四、监控方案
五、收益
六、未来展望
七、总结
一
背景
相信移动端高度普及的现在,大家或多或少都会存在电量焦虑,拥有过手机发热发烫的糟糕体验。 而发热问题是一个长时间、多场景的指标存在,且涉及到端侧应用层、手机 ROM 厂商系统、外界环境等多方面的影响。如何有效衡量发热场景、定位发热现场、以及归因发热问题成为了端侧应用层发热监控的面前的三座大山。 本文通过得物 Android 端侧现有的一些监控实践,不深入功耗计算场景无法自拔,优先聚焦于发热场景本身,希望能给大家一些参考。
二
发热定义
温 度是最直观能反映发热问题的指标,当前 Android 侧,我们以体感温度 37° 以上作为分界线,向上每 3° 作为一个发热温度区间,区间细分上限温度 49° ,即划分出 37-40,40-43,43-46,46-49,49+ 五个等级。
以手机温度、CPU 使用率作为第一、第二要素来判断用户是否发热的同时,获取其他参数来支撑发热现场情况。
具体指标如下:
手机温度 CPU 使用率、GPU 使用率;
线程堆栈;
系统服务使用频次;
设备前后台、亮灭屏时长;
电量、充电情况;
热缓解发热等级;
系统机型、版本;
....
三
指标获取
温度
-
电池温度
系统 BatteryManger 已经提供了一系列自带的接口和粘性广播获取电池信息。
BatteryManager.EXTRA_TEMPERATURE 广播,获取的温度值是摄氏度为单位的 10 倍数值。
//获取电池温度BatteryManager.EXTRA_TEMPERATURE,华氏温度需要除以10fun getBatteryTempImmediately(context: Context): Float {return try {val batIntent = getBatteryStickyIntent(context) ?: return 0fbatIntent.getIntExtra(BatteryManager.EXTRA_TEMPERATURE, 0) / 10F} catch (e: Exception) {0f}}
private fun getBatteryStickyIntent(context: Context): Intent? {return try {context.registerReceiver(null, IntentFilter(Intent.ACTION_BATTERY_CHANGED))} catch (e: Exception) {null}}
BatteryManager 除支持电池温度的系统广播外,也包含电量、充电状态等额外信息的读取,均定义在 其源码 中。
以下罗列几个值得关注的://BATTERY_PROPERTY_CHARGE_COUNTER 剩余电池容量,单位为微安时//BATTERY_PROPERTY_CURRENT_NOW 瞬时电池电流,单位为微安//BATTERY_PROPERTY_CURRENT_AVERAGE 平均电池电流,单位为微安//BATTERY_PROPERTY_CAPACITY 剩余电池容量,显示为整数百分比//BATTERY_PROPERTY_ENERGY_COUNTER 剩余能量,单位为纳瓦时// EXTRA_BATTERY_LOW 是否认为电量低// EXTRA_HEALTH 电量健康常量的常数// EXTRA_LEVEL 电量值// EXTRA_VOLTAGE 电压// ACTION_CHARGING 进入充电状态// ACTION_DISCHARGING 进入放电状态
-
传感器温度
A ndroid是基于Linux 基础上修改的开源操作系统,同样的在手机系统sys/class/thermal/ 目录下存在以 thermal_zoneX 为代表各传感器的温度分区,以及 cooling_deviceX 为代表风扇或散热器等冷却设备。
以一加 9 为例,共存在 105 个温度传感器 or 温度分区,以及 48 个冷却设备。
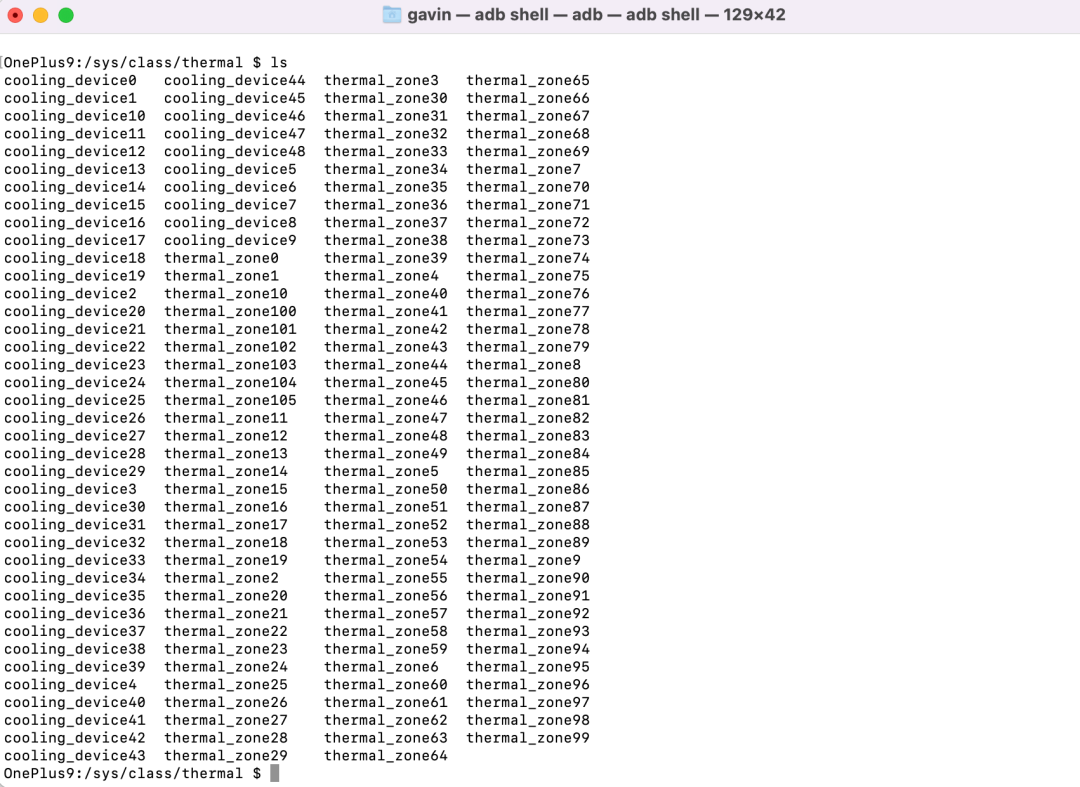
每个温度分区下记录下具体的参数类型,我们重点关注的是 type 文件和 temp 文件,分别记录了该传感器设备的名称,以及当前的传感器温度。以 thermal_zone29 为例,代表了 CPU 第一核心的 第五处理单元的温度值为 33.2 摄氏度。而对单一设备来说分区对应的名称是固定的,从而我们可以通过读取 thermal_zone 文件的方式来记录当前第一个 type 文件名称包含 CPU 的传感器作为 CPU 温度。

-
壳温
Android 10 Google 官方推出了 热缓解框架 ,通过 HAL2.0 框架监听底层硬件传感器(主要为 USB 传感器、Skin 传感器)提供 USB、壳温的热信号等级变更监听, 系统 PowerManager 源码提供了对应发热等级变更的回调和发热等级的获取,共 7 个等级,提供给开发者主动或被动获取。
final PowerManager powerManager = (PowerManager) mContext.getSystemService(Context.POWER_SERVICE);powerManager.addThermalStatusListener(new PowerManager.OnThermalStatusChangedListener() {public void onThermalStatusChanged(int status) {//返回对应的热状态}});
但对于发热等级来说,壳温无疑是最为能够反应手机的发热情况的。可以看到 Android 系统的 API 实际上是提供了 AIDL 接口,可以直接注册 Thermal 变更事件的监听,获取到 Temperature 对象。但由于标识了 Hide API 。常规应用层是无法获取到的,在考虑好 Android 版本兼容性前提下,通过反射代理 ThermalManagerService 方式进行读取。
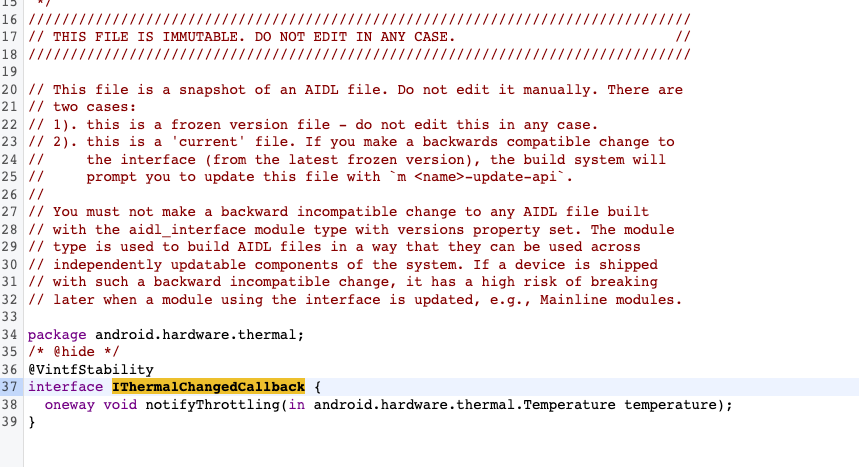
但事与愿违,国内厂商并没有完全适配官方热缓解框架,热状态回调时常不够准确,而是需要单独接入每个厂商的热缓解 SDK 去直接获取到壳温,具体 API 则以各应用厂商的内部接入文档为准。
CPU使用率
CPU 使用率的采集通过读取解析 Proc stat 文件的方式进行计算。
在系统 proc/[pid]/stat 和 /proc/[pid]/task/[tid]/stat 分别记录了对应进程 ID、进程 ID 下的线程 ID 的 CPU 信息。具体的字段描述在此不进行赘述,详见:https://man7.org/linux/man-pages/man5/procfs.5.html。
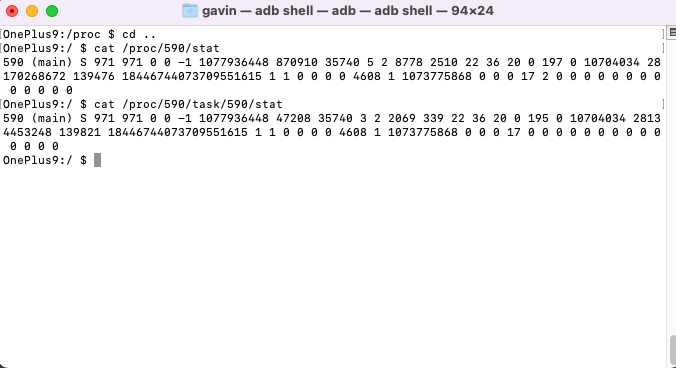
我们重点关注 14.15 位的信息,分别代表进程/线程的用户态运行的时间和内核态运行的时间。

通过解析当前进程的 Stat 文件,以及 Task 目录下所有线程的 Stat 文件,在两次采样周期内(当前设置为 1s)的 utime+stime 之和的差值/采样间隔,即可认为是进线程的 CPU 的使用率。即 进线程 CPU 使用率 = ((utime+stime)-(lastutime+laststime)) / period
GPU使用率
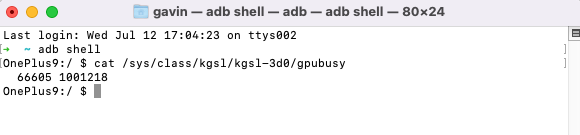
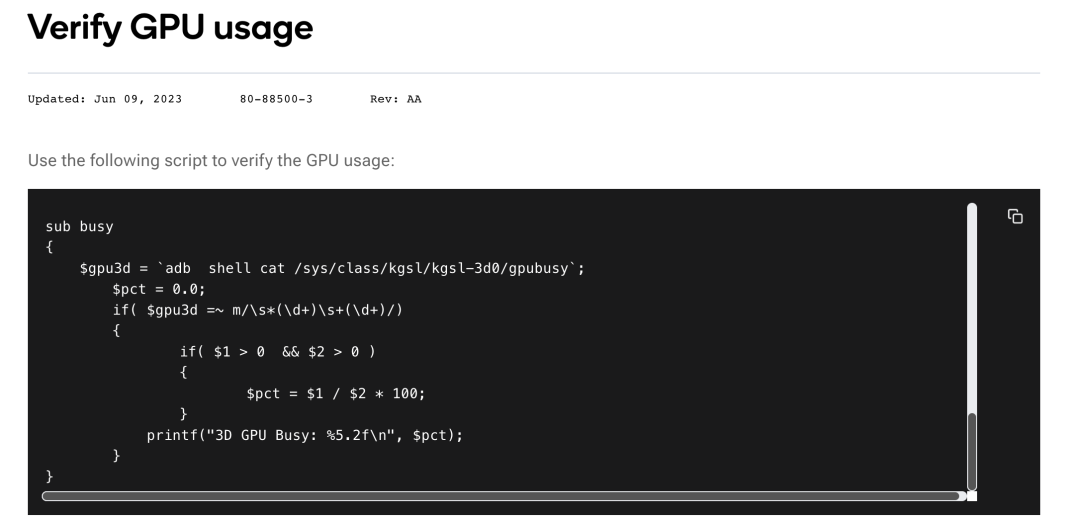
高通芯片的设备,我们可以参考 /sys/class/kgsl/kgsl-3d0/gpubusy 下文件内容,参考 高通官网 的说明。
GPU 的使用率 = (下图)数值 1 / 数值 2 * 100,经过验证与 SnapDragonProfiler 信息采集获取的数值基本一致。
联发科芯片的设备,我们可以直接通过读取 /d/ged/hal/gpu_utilization 下的使用率数值。
同样的通过指定周期(每秒 1 次)的采样间隔,即可获取到每秒的当前 GPU 使用率。
系统服务使用
Android 系统服务包括 Warelock、Alarm、Sensor、Wifi、Net、Location、Bluetooth、Camera等。
与市面上常规的监控手段差异不大,都是通过系统 Hook ServiceManager 的方式,监听系统服务的 Binder 通信,匹配对应的调用方法名,做对应中间层监控的回调记录处理。
熟悉 Android 开发的同学知道 Android 的 Zygote 进程是 Android 系统启动时的第一个进程。在 Zygote Fork 进程中会孵化出系统服务相关的进程 SystemServer,在其核心的 RUN 方法中,会注册启动大量的系统服务,并通过 ServiceManager 进行管理。

故我们可以通过反射代理 ServiceManager 的方式,以 LocationManager 为例进行监听,拦截对应 LocationManager 内对应的方法,记录我们期望获取的数据。
// 获取 ServiceManager 的 Class 对象Class<?> serviceManagerClass = Class.forName("android.os.ServiceManager");// 获取 getService 方法Method getServiceMethod = serviceManagerClass.getDeclaredMethod("getService", String.class);// 通过反射调用 getService 方法获取原始的 IBinder 对象IBinder originalBinder = (IBinder) getServiceMethod.invoke(null, "location");// 创建一个代理对象 ProxyClass<?> iLocationManagerStubClass = Class.forName("android.location.ILocationManager$Stub");Method asInterfaceMethod = iLocationManagerStubClass.getDeclaredMethod("asInterface", IBinder.class);final Object originalLocationManager = asInterfaceMethod.invoke(null, originalBinder);Object proxyLocationManager = Proxy.newProxyInstance(context.getClassLoader(),new Class[]{Class.forName("android.location.ILocationManager")},new InvocationHandler() {public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {// 在这里进行方法的拦截和处理Log.d("LocationManagerProxy", "Intercepted method: " + method.getName());// 执行原始的方法return method.invoke(originalLocationManager, args);}});// 替换原始的 IBinder 对象getServiceMethod.invoke(null, "location", proxyLocationManager);
同理 我们获取在固定采样周期内 各系统服务对应 申请次数、计算间隔时长等 进行记录。
源码 Power_profile 文件中定义了每个系统服务状态下的电流量定义。
我们在需要记录每个元器件在不同状态的工作时间之后,通过以下计算方式,可以得出元器件的发热贡献排行,即:
元器件 电量消耗(发热贡献) ~~ 电流量 * 运行时长 * 电压(一般为固定值,可忽略)

线程堆栈
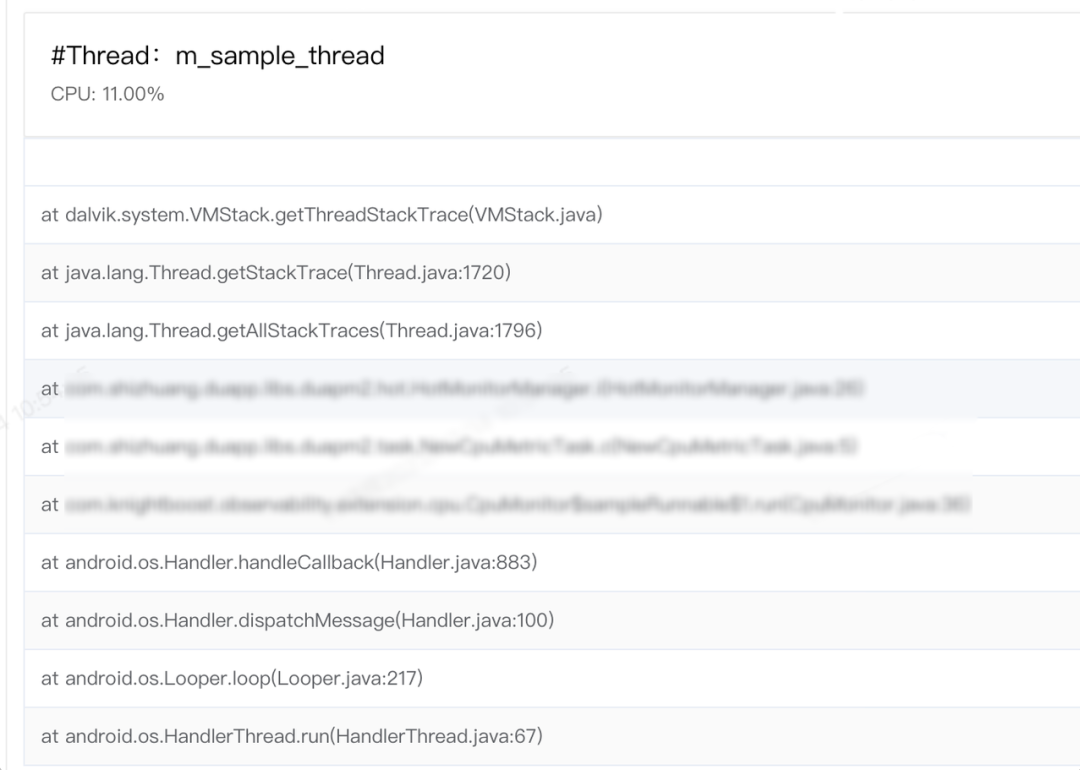
由于发热问题是一个综合性的问题,并不像 Crash 问题一样,在发生现场我们就可以知道是哪个线程触发的。 如果将所有线程的堆栈都进行 Dump 记录的话,得物当前运行时的子线程数量在 200+,全部进行存储的话无疑是不合理的。 问题就转变为 如何较为准确的找到发热代码的线程堆栈?
上文说到 在计算 CPU 使用率的时读取进程下所有线程的 Stat 文件,我们可以获取到子线程的 CPU 使用率,对其使用率进行倒排,筛选超过阈值(当前定义 50% ) 或 占用 Top N 的线程进行存储。由于堆栈频繁采集时机上是有性能折损的,故牺牲了部分的堆栈采样精度和准确性,在温度、CPU 使用率等指标超过阈值定义后,才开始采集 指定下发时间的堆栈信息。
我们还要明确一个概念,线程 Stat 文件的文件名即为线程标识名,Thread.id 是指线程ID。
其两者并不等价,但 Native 方法中给我们提供了对应的方式去建立两者的映射关系。
在 Art Thread.cc 方法中,将 Java 中的 Thread 对象转换成 C++ 中的 Thread 对象,调用 ShortDump 打印线程的相关信息,我们通过字符串匹配到核心的 Tid= 的信息,即可获取到线程的 Tid。
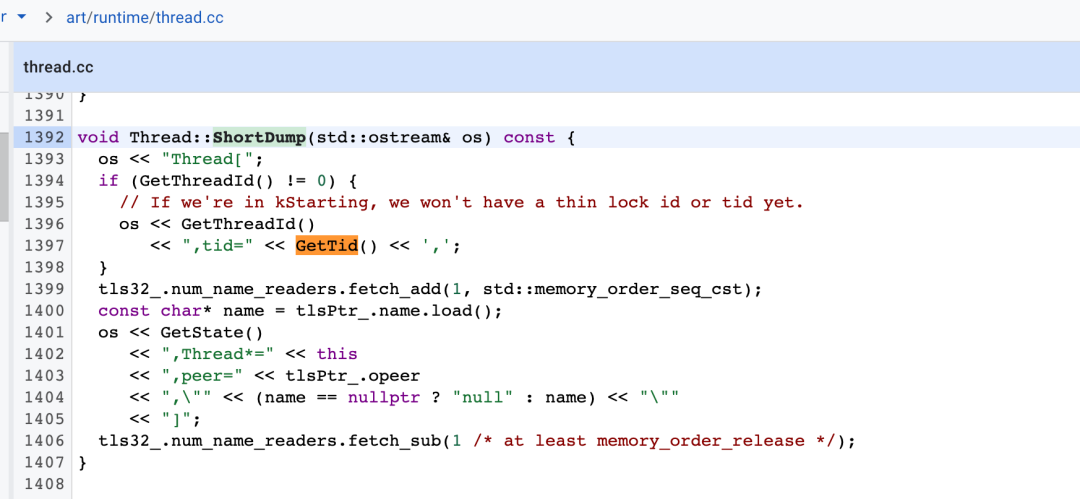
核心代码逻辑如下:
//获取队列中最近一次cpu采样的数据val threadCpuUsageData = cpuProfileStoreQueue.last().threadUsageDataListval hotStacks = mutableListOf<HotStack>()if (threadCpuUsageData != null) {val dataCount = if (threadCpuUsageData.size <= TOP_THREAD_COUNT) {threadCpuUsageData.size} else {TOP_THREAD_COUNT}val traces: MutableMap<Thread, Array<StackTraceElement>> = Thread.getAllStackTraces()//定义tid 和 thread的映射关系mapval tidMap: MutableMap<String, Thread> = mutableMapOf()traces.keys.forEach { thread ->//调用native方法获取到tid信息val tidInfo = hotMonitorListener?.findTidInfoByThread(thread)tidInfo?.let {findTidByTidInfo(tidInfo).let { tid ->if (tid.isNotEmpty()) {tidMap[tid] = thread}}}}//采集topN的发热堆栈for (index in 1..dataCount) {val singleThreadData = threadCpuUsageData[index - 1]val isMainThread = singleThreadData.pid == singleThreadData.tidval thread = tidMap[singleThreadData.tid.toString()]thread?.let { findThread ->traces[findThread]?.let { findStackTrace ->//获取当前的线程堆栈val sb = StringBuilder()for (element in findStackTrace) {sb.append(element.toString()).append("\n")}sb.append("\n")if (findStackTrace.isNotEmpty()) {//是否为主线程//组装hotStackval hotStack = HotStack(//进程idsingleThreadData.pid,singleThreadData.tid,singleThreadData.name,singleThreadData.cpuUseRate,sb.toString(),thread.stateisMainThread)// Log.d("HotMonitor", sb.toString())hotStacks.add(hotStack)}}}
}}
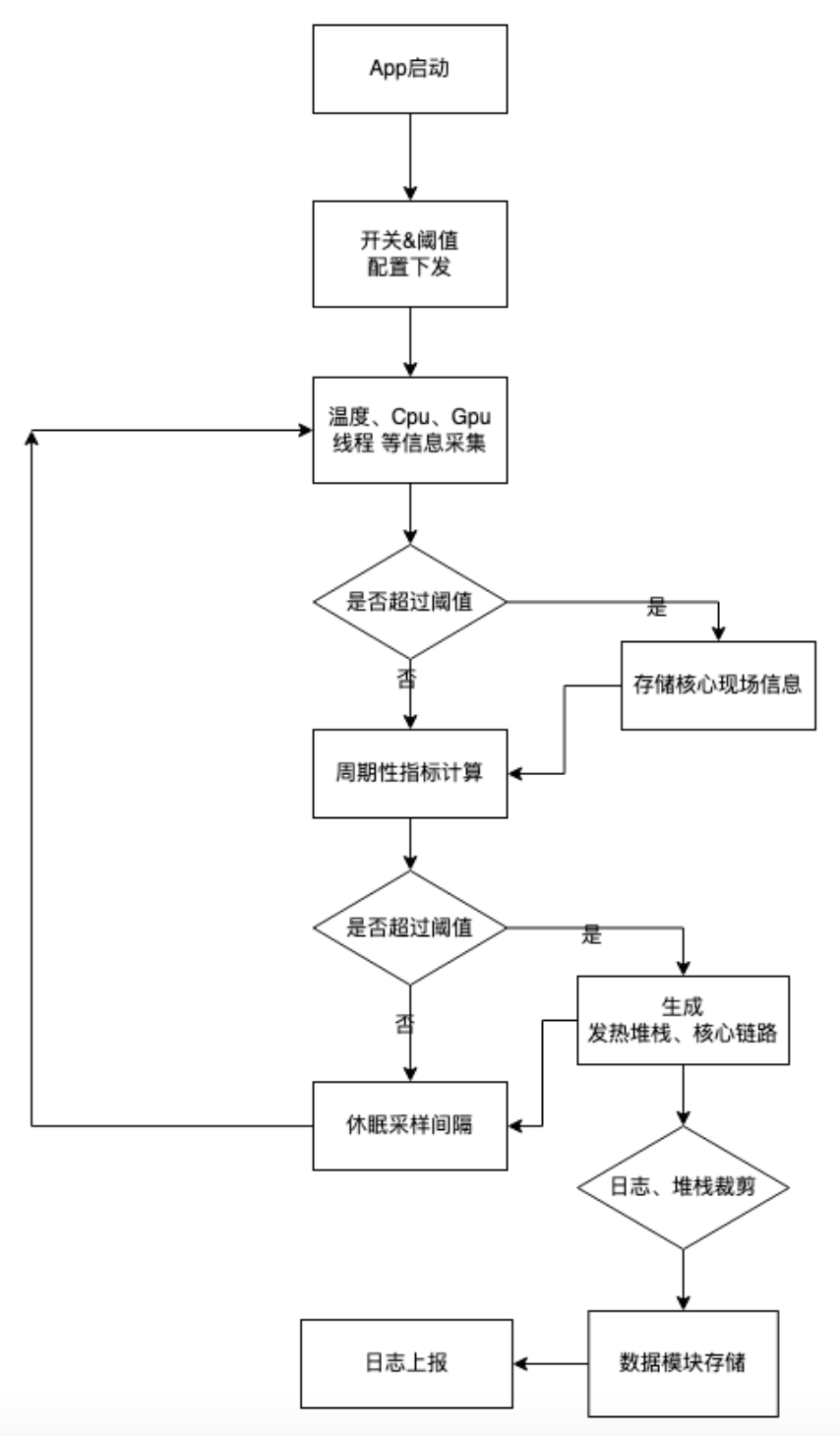
四
监控方案
了解核心指标数据是如何获取的前提下,其实监控方案的核心思路无非就是通过远端 APM 配置中心下发的采样阈值、采样周期、各模块数据开关等限定采样配置,子线程 Handler 定时发消息,采集各个模块的数据进行组装,在合适的时机进行数据上报即可,具体的数据拆解、分析工作则由发热平台进一步处理。
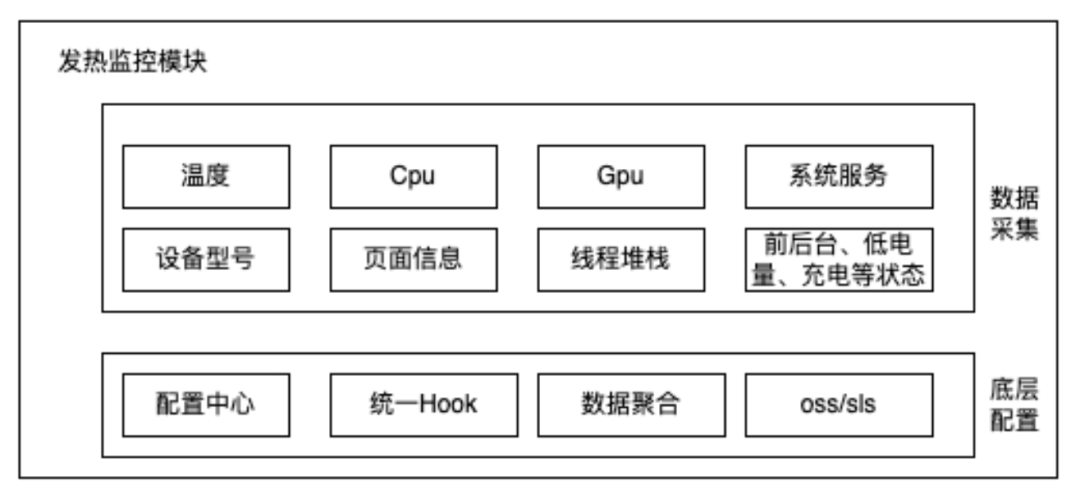
模块整体架构
上报时机
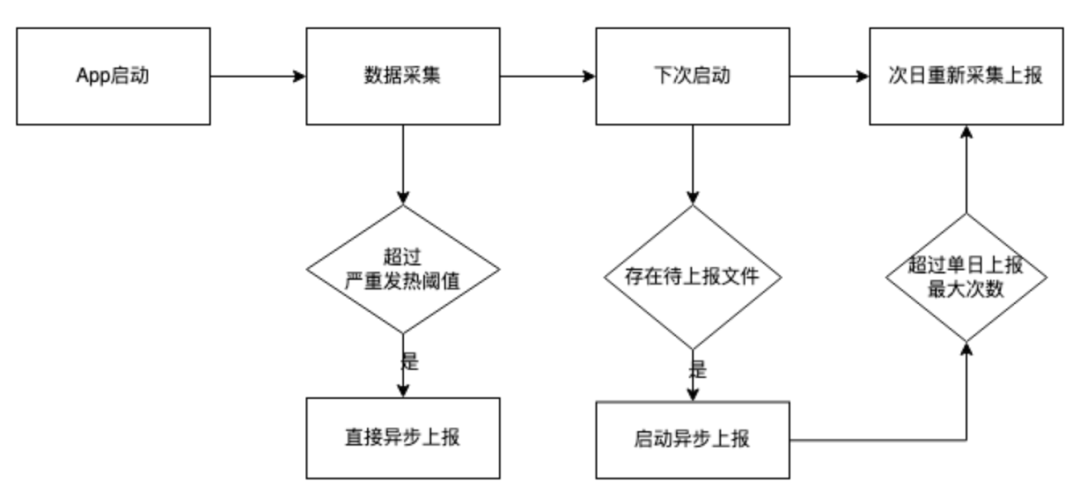
核心采集流程
线上线下区分
由于所有子线程的 CPU 采集、堆栈采集实际上是会对性能有折损的,200+ 的线程的读取耗时整体在 200ms 左右,采样子线程的 CPU 使用率在 10%,考虑到线上用户体验问题,并不能全量开启高频率采样。
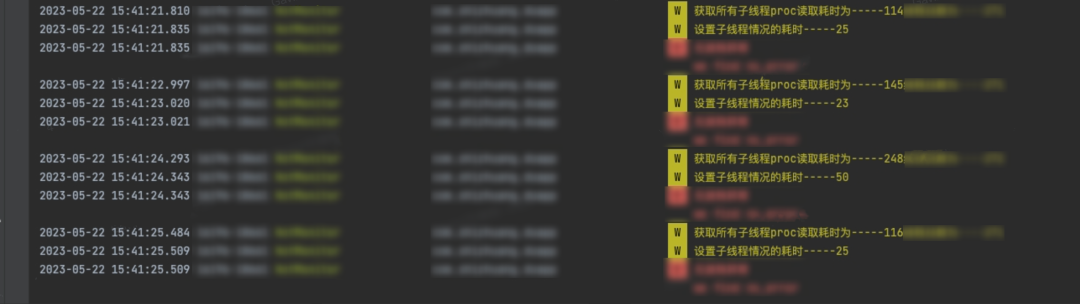
故整体方案来说: 线下场景以重点侧重发现、排查、治理全量问题,上报全量日志,以 CPU、GPU 使用率为第一衡量指标;
线上场景以重点侧重观察整体发热大盘趋势、分析潜在问题场景,上报核心日志,以电池温度为第一衡量指标。
发热平台
在平台侧同学的支持下,发热现场数据经过平台侧进行消费,将核心的发热堆栈经过 Android 堆栈反混淆服务进行聚合,补齐充电状态、主线程 CPU 使用率、问题类型、电池温度等基础字段,平台侧就具备发现、分析、解决的流程化监控推进的能力。
具体的堆栈信息 & 发热信息平台展示 如下:
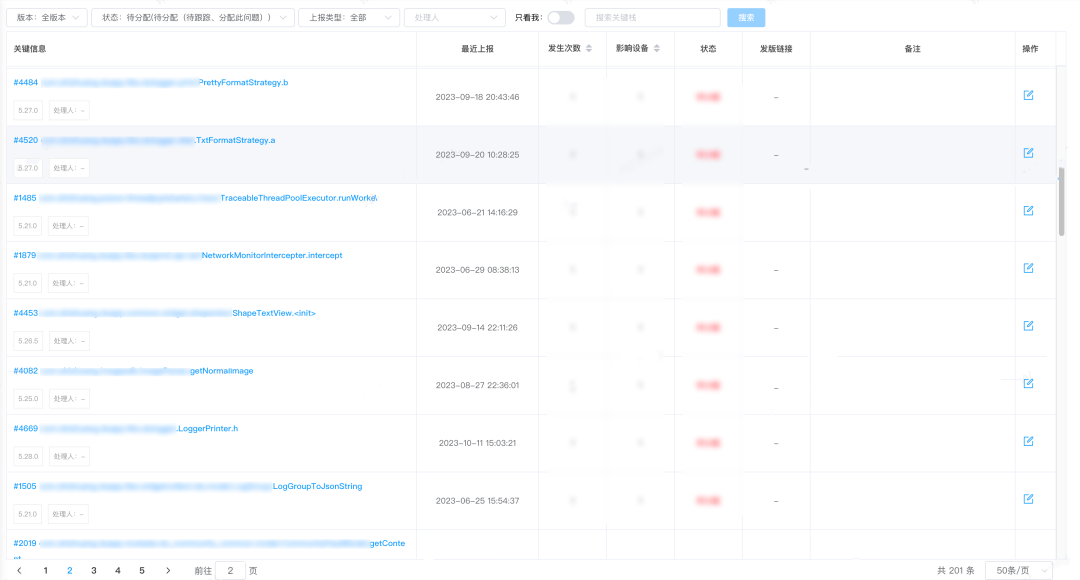
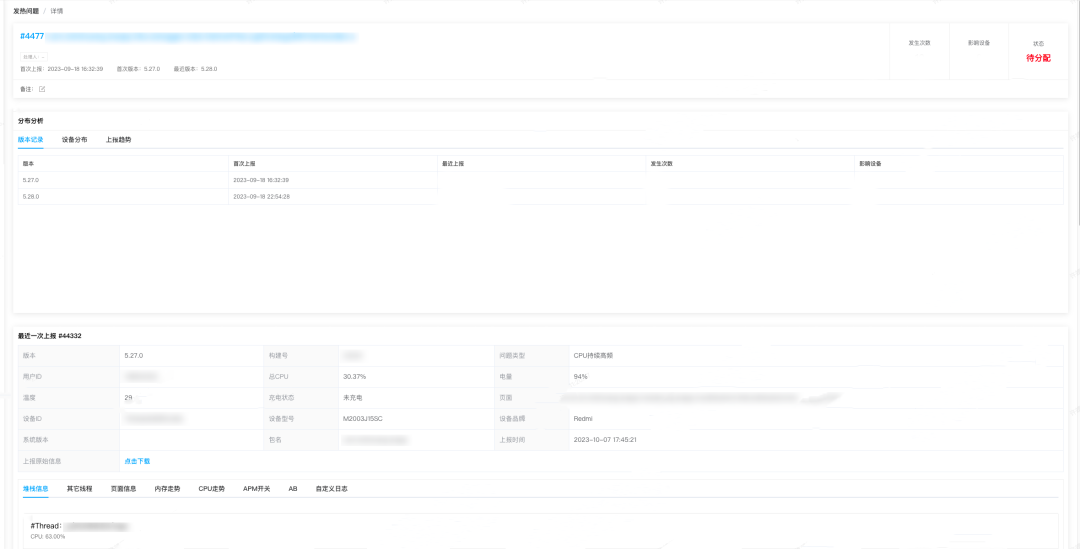
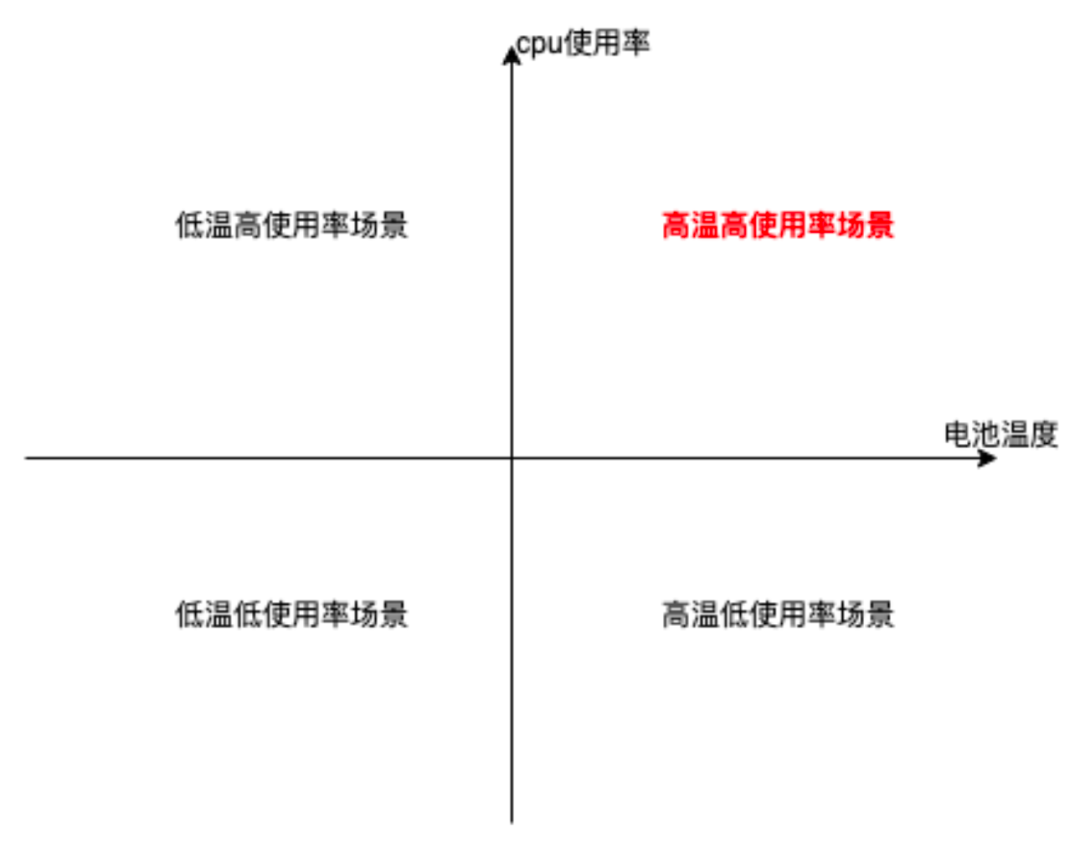
由于电池温度、CPU 使用率是针对运行时发热场景最直观的指标,且我们一期重点关注发热场景的治理,不针对元器件 Hook 等耗电场景进行持续深入分析,故当前得物侧是以电池温度、CPU 使用率为第一第二指标 建立核心的发热问题四象限,优先关注高温、高 CPU 的问题场景。
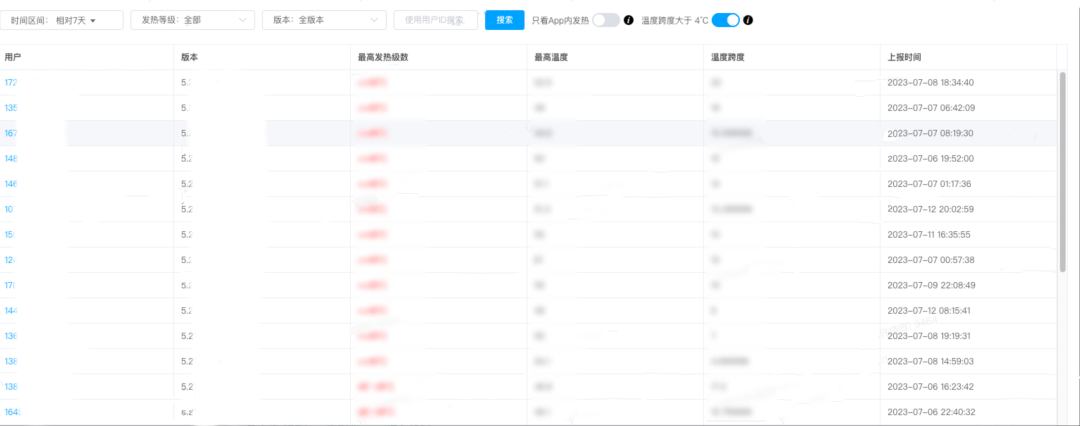
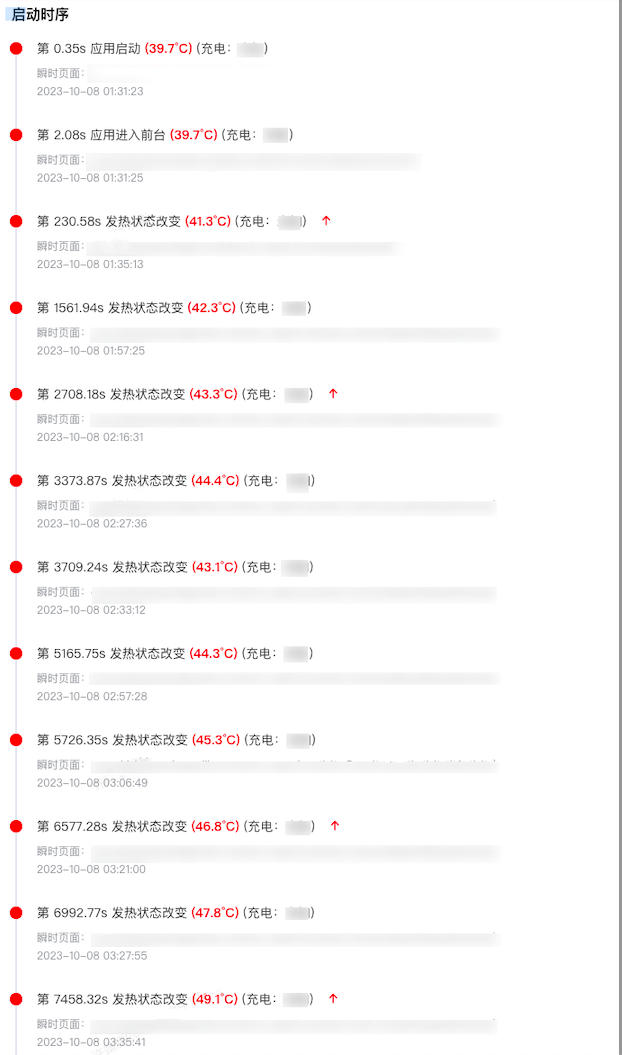
在数据分析过程中,我们遇到了数据上的效率排查效率不够高、问题精度不够准的情况。
-
如何定位是高温场景是发生在 App 内部,且在使用过程中明显上升的?通过过滤从启动开始即高温、后台切换回来即高温的场景,重点关注在 App 内部温度上升的场景。
-
线上的采样后仍旧单日有 6w+ 数据的上报,我们如何筛选出更为核心的数据?当前的做法是定义了温度跨度的概念,优先看在 App 内部温度跨度较大的 Case。
-
线程存在调用 Wait 等方法阻塞的堆栈,消耗内核态的时间分配,但实际不消耗整体 CPU 的误报数据。补充了线程的运行状态和 Proc 文件中记录的 State,方便优先处理 RUNNABLE线程的 CPU 高温高占用问题。
-
手机温度上升作为渐进式的场景,如何实现温度上升场景下的页面精确归因?增加温度采样频率的同时,汇总 CPU 使用率和实时堆栈等瞬时数据作为数据支撑,但考虑到数据体量的情况,数据上报聚合裁剪方式仍在逐步探索更为合理的方式,力求在两者之间找到一个平衡点。
五
收益
Android 端侧发热监控自上线以来,背靠平台侧的支撑,陆续发现了一些问题并联合开发同学做了对应场景的治理优化工作,如:
耗时独立线程任务 接入统一线程池调度管理;
动画执行死循环监测修复;
高 IO 场景的文件读写策略优化;
高并发任务锁粒度优化;
日志库等 Json 解析频繁场景 采用效率更高的序列化方;
系统相机等系统功率过高的采集参数设备分级尝试;
基于 Webgl 的游戏场景 帧率降低和资源及时回收优化运行时内存;
....
这无疑给未来体验工作的场景技术选型、技术实现沉淀了一些有价值的经验,符合对 App 体验追求极致的高标准、高要求。
六
未来展望
手机发热作为渐进式的体验场景,涉及手机硬件、系统服务、软件使用、外界环境多方位因素。对于端侧的排查上来说,当前优先级聚焦于应用层的不合理使用上,对于排查工具链路增强、问题业务归因、低电量、低功耗模式下的动态策略降低、自动化诊断报告等环节仍旧有很多值得深入挖掘的点,例如:
监控/ 工具增强
-
App 浮层分析工具 (CPU\GPU/频率/温度/功耗等信息)
-
借鉴 BatteryHistorian、SnapdragonProfiler、Systrace 等工具,实现自研TeslaLab 能力增强。
业务 归因
-
发热堆栈自动分配
-
调用溯源归因精细化
场景策略、 降级
-
CPU 调频、动态帧率、分辨率降级
-
端内低功耗模式探索
自动化 诊断报告
-
单用户定向自动化分析输出诊断报告
七
总结
在此也只是粗略介绍当前已经做的针对发热治理的一些初步工作,以及对未来发热功耗相关开展的思路,希望能让 App 带来更好的体验,给用户带来更对美好事物的向往的感受。
「点击关注,Carson每天带你学习一个Android知识点。」
最后福利:学习资料赠送
- 福利:本人亲自整理的「Android学习资料」
- 数量:10名
- 参与方式:「点击右下角”在看“并回复截图到公众号,随机抽取」
 点击就能升职、加薪水!
点击就能升职、加薪水! 