
2020年这10大ML、NLP研究最具影响力:为什么?接下来如何发展?
点击上方,选择星标或置顶,每天给你送干货!
去年有哪些机器学习重要进展是你必须关注的?听听 DeepMind 研究科学家怎么说。



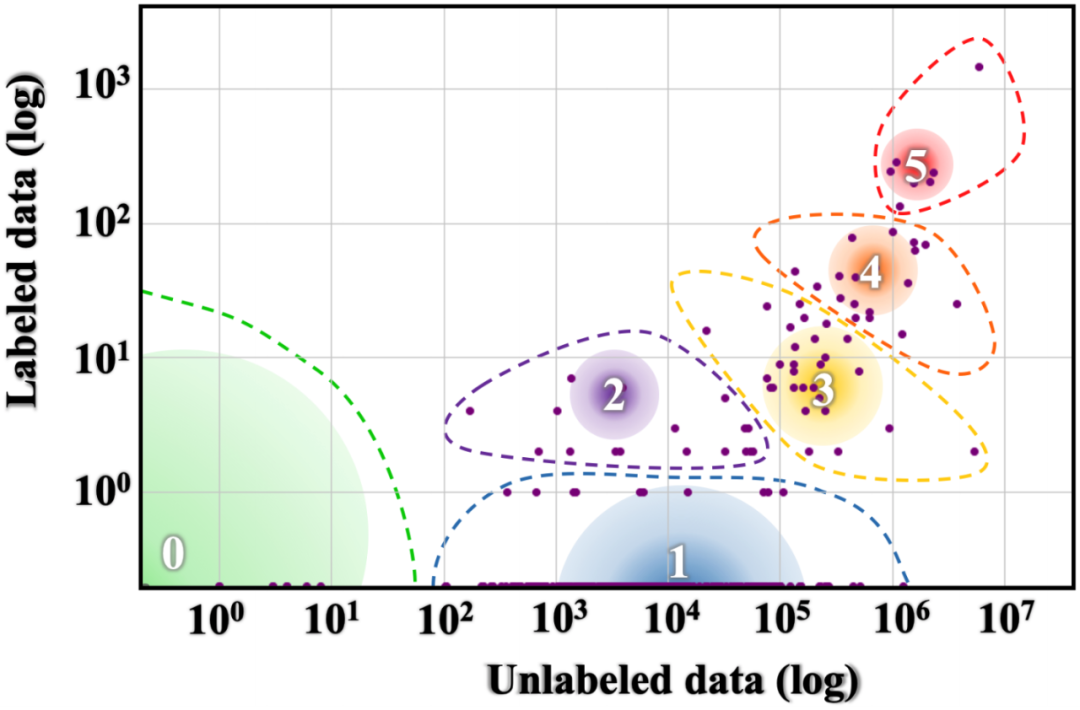
SQuAD: XQuAD (Artetxe et al., 2020), MLQA (Lewis et al., 2020), FQuAD (d'Hoffschmidt et al., 2020);
Natural Questions: TyDiQA (Clark et al., 2020), MKQA (Longpre et al., 2020);
MNLI: OCNLI (Hu et al., 2020), FarsTail (Amirkhani et al., 2020);
the CoNLL-09 dataset: X-SRL (Daza and Frank, 2020);
the CNN/Daily Mail dataset: MLSUM (Scialom et al., 2020)。
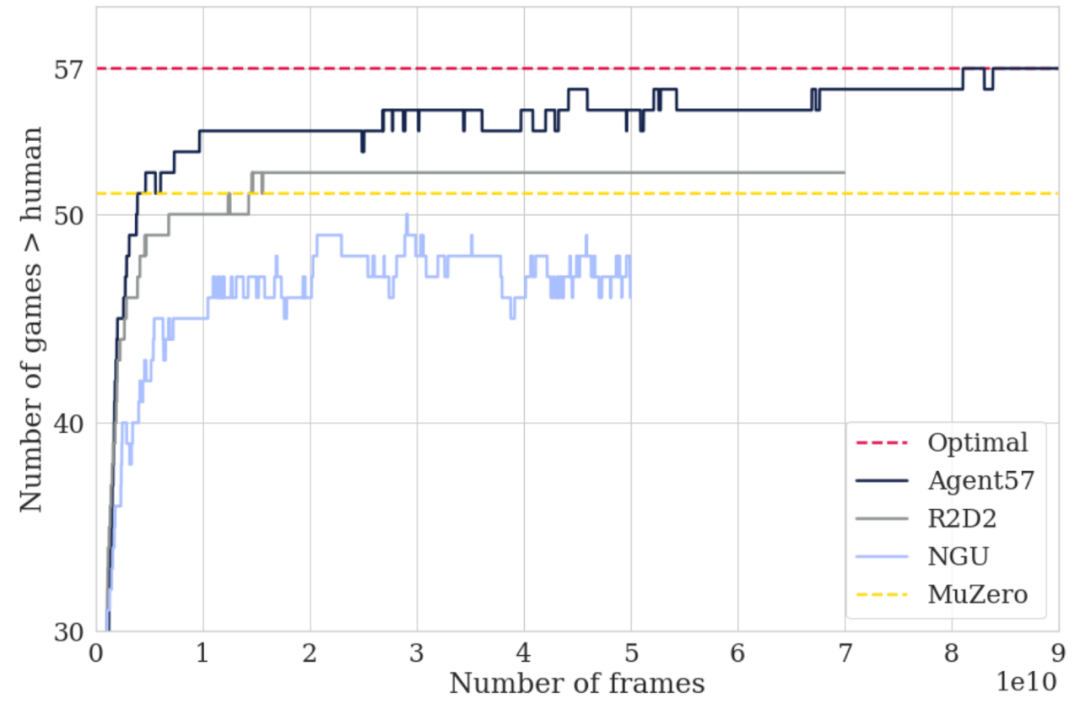
随着经典基准(如 Atari)的基本解决,研究人员可能会寻找更具挑战性的设置来测试他们的算法,如推广到外分布任务、提高样本效率、多任务学习等。
来源:机器之心
整理不易,还望给个在看!
评论