
ElasticSearch 如何使用 ik 进行中文分词?
大家好,我是历小冰。在《为什么 ElasticSearch 比 MySQL 更适合复杂条件搜索》 一文中,我们讲解了 ElasticSearch 如何在数据存储方面支持全文搜索和复杂条件查询,本篇文章则着重分析 ElasticSearch 在全文搜索前如何使用 ik 进行分词,让大家对 ElasticSearch 的全文搜索和 ik 中文分词原理有一个全面且深入的了解。
全文搜索和精确匹配
ElasticSearch 支持对文本类型数据进行全文搜索和精确搜索,但是必须提前为其设置对应的类型:
keyword 类型,存储时不会做分词处理,支持精确查询和分词匹配查询;
text 类型,存储时会进行分词处理,也支持精确查询和分词匹配查询。
比如,创建名为 article 的索引(Index),并为其两个字段(Filed)配置映射(Mapping),文章内容设置为 text 类型,而文章标题设置为 keyword 类型。
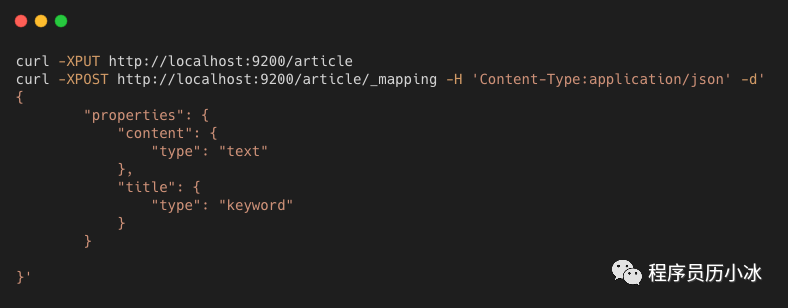
Elasticsearch 在进行存储时,会对文章内容字段进行分词,获取并保存分词后的词元(tokens);对文章标题则是不进行分词处理,直接保存原值。
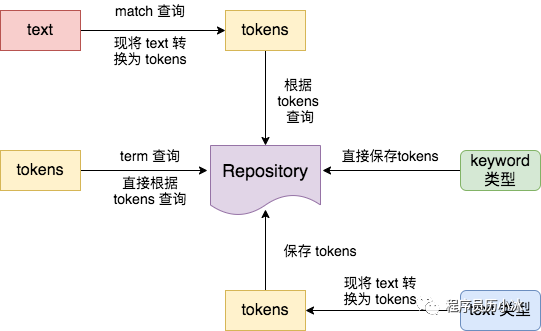
上图的右半边展示了 keyword 和 text 两种类型的不同存储处理过程。而左半边则展示了 ElasticSearch 相对应的两种查询方式:
term 查询,也就是精确查询,不进行分词,而是直接根据输入词进行查询;
match 查询,也就是分词匹配查询,先对输入词进行分词,然后逐个对分词后的词元进行查询。
举个例子,有两篇文章,一篇的标题和内容都是“程序员”,另外一篇的标题和内容都是“程序”,那么二者在 ElasticSearch 中的倒排索引存储如下所示(假设使用特殊分词器)。
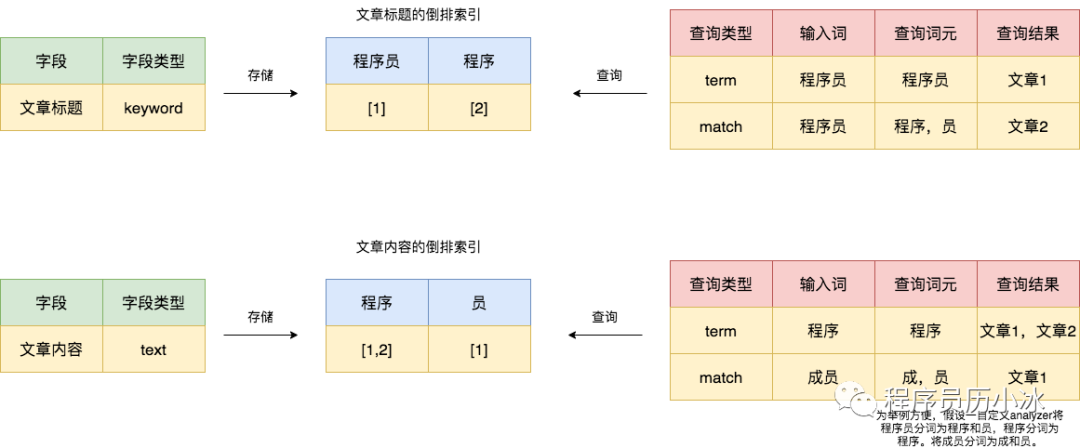
这时,分别使用 term 和 match 查询对两个字段进行查询,就会得出如图右侧的结果。
Analyzer 处理过程
可见,keyword 与 text 类型, term 与 match 查询方式之间不同就在于是否进行了分词。在 ElasticSearch 中将这个分词的过程统称了 Text analysis,也就是将字段从非结构化字符串(text)转化为结构化字符串(keyword)的过程。
Text analysis 不仅仅只进行分词操作,而是包含如下流程:
使用字符过滤器(Character filters),对原始的文本进行一些处理,例如去掉空白字符等;
使用分词器(Tokenizer),对原始的文本进行分词处理,得到一些词元(tokens);
使用词元过滤器(Token filters),对上一步得到的词元继续进行处理,例如改变词元(小写化),删除词元(删除量词)或增加词元(增加同义词),合并同义词等。

ElasticSearch 中处理 Text analysis 的组件被称为 Analyzer。相应地,Analyzer 也由三部分组成,character filters、tokenizers 和 token filters。
Elasticsearch 内置了 3 种字符过滤器、10 种分词器和 31 种词元过滤器。此外,还可以通过插件机制获取第三方实现的相应组件。开发者可以按照自身需求定制 Analyzer 的组成部分。
"analyzer": {"my_analyzer": {"type": "custom","char_filter": [ "html_strip"],"tokenizer": "standard","filter": [ "lowercase",]}}
按照上述配置,my_analyzer 分析器的功能大致如下:
字符过滤器是
html_strip,会去掉 HTML 标记相关的字符;分词器是 ElasticSearch 默认的标准分词器
standard;词元过滤器是小写化
lowercase处理器,将英语单词小写化。
一般来说,Analyzer 中最为重要的就是分词器,分词结果的好坏会直接影响到搜索的准确度和满意度。ElasticSearch 默认的分词器并不是处理中文分词的最优选择,目前业界主要使用 ik 进行中文分词。
ik 分词原理
ik 是目前较为主流的 ElasticSearch 开源中文分词组件,它内置了基础的中文词库和分词算法帮忙开发者快速构建中文分词和搜索功能,它还提供了扩展词库字典和远程字典等功能,方便开发者扩充网络新词或流行语。
ik 提供了三种内置词典,分别是:
main.dic:主词典,包括日常的通用词语,比如程序员和编程等;
quantifier.dic:量词词典,包括日常的量词,比如米、公顷和小时等;
stopword.dic:停用词,主要指英语的停用词,比如 a、such、that 等。
此外,开发者可以通过配置扩展词库字典和远程字典对上述词典进行扩展。

ik 跟随 ElasticSearch 启动时,会将默认词典和扩展词典读取并加载到内存,并使用字典树 tire tree (也叫前缀树)数据结构进行存储,方便后续分词时使用。
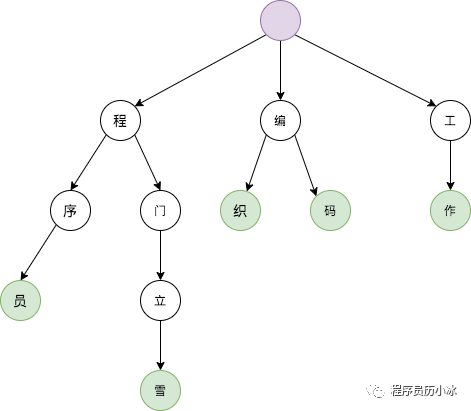
字典树的典型结构如上图所示,每个节点是一个字,从根节点到叶节点,路径上经过的字符连接起来,为该节点对应的词。所以上图中的词包括:程序员、程门立雪、编织、编码和工作。
一、加载字典
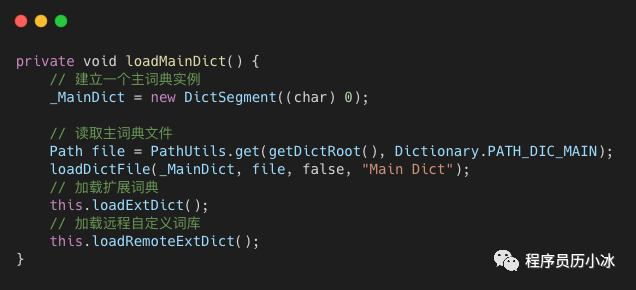
ik 的 Dictionary 单例对象会在初始化时,调用对应的 load 函数读取字典文件,构造三个由 DictSegment 组成的字典树,分别是 MainDict、QuantifierDict 和 StopWords。我们下面就来看一下其主词典的加载和构造过程。loadMainDict 函数较为简单,它会首先创建一个 DictSegment 对象作为字典树的根节点,然后分别去加载默认主字典,扩展主字典和远程主字典来填充字典树。
复制代码
在 loadDictFile 函数执行过程中,会从词典文件读取一行一行的词,交给 DictSegment 的fillSegment 函数处理。
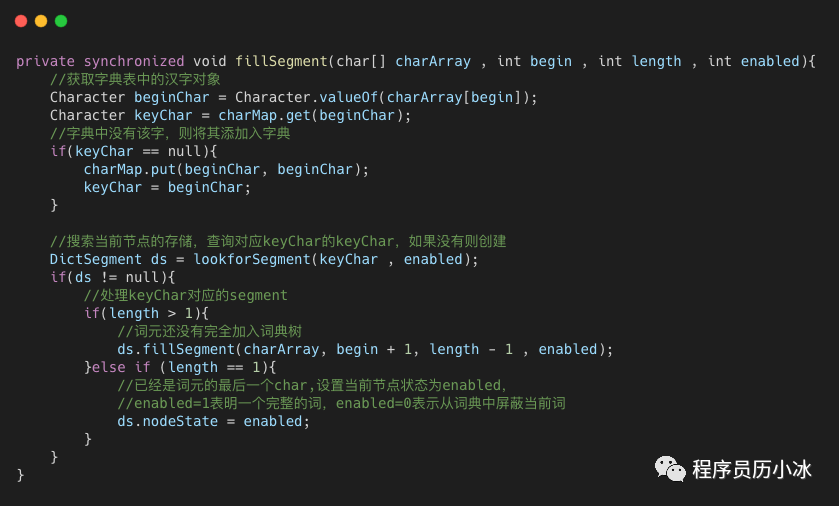
fillSegment 是构建字典树的核心函数,具体实现如下所示,处理逻辑大致有如下几个步骤:
一、按照索引,获取词中的一个字;
二、检查当前节点的子节点中是否有该字,如果没有,则将其加入到
charMap中;三、调用
lookforSegment函数在字典树中寻找代表该字的节点,如果没有则插入一个新的;四、递归调用
fillSegment函数处理下一个字。
ik 初始化过程大致如此,再进一步详细的逻辑大家可以直接去看源码,中间都是中文注释,相对来说较为容易阅读。
二、分词逻辑
ik 中实现了 ElasticSearch 相关的抽象类,来提供自身的分词逻辑实现:
IKAnalyzer继承了Analyzer,用来提供中文分词的分析器;IKTokenizer继承了Tokenizer,用来提供中文分词的分词器,其incrementToken是 ElasticSearch 调用 ik 进行分词的入口函数。
incrementToken 函数会调用 IKSegmenter 的 next方法,来获取分词结果,它是 ik 分词的核心方法。
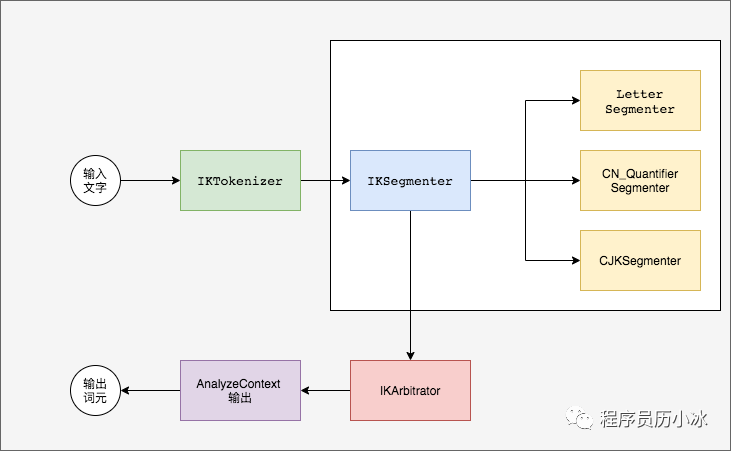
如上图所示,IKSegmenter 中有三个分词器,在进行分词时会遍历词中的所有字,然后将单字按照顺序,让三个分词器进行处理:
LetterSegmenter,英文分词器比较简单,就是把连续的英文字符进行分词;CN_QuantifierSegmenter,中文量词分词器,判断当前的字符是否是数词和量词,会把连起来的数词和量词分成一个词;CJKSegmenter,核心分词器,基于前文的字典树进行分词。
我们只讲解一下 CJKSegmenter 的实现,其 analyze 函数大致分为两个逻辑:
根据单字去字典树中进行查询,如果单字是词,则生成词元;如果是词前缀,则放入到临时命中列表中;
然后根据单字和之前处理时保存的临时命中列表数据一起去字典树中查询,如果命中,则生成词元。
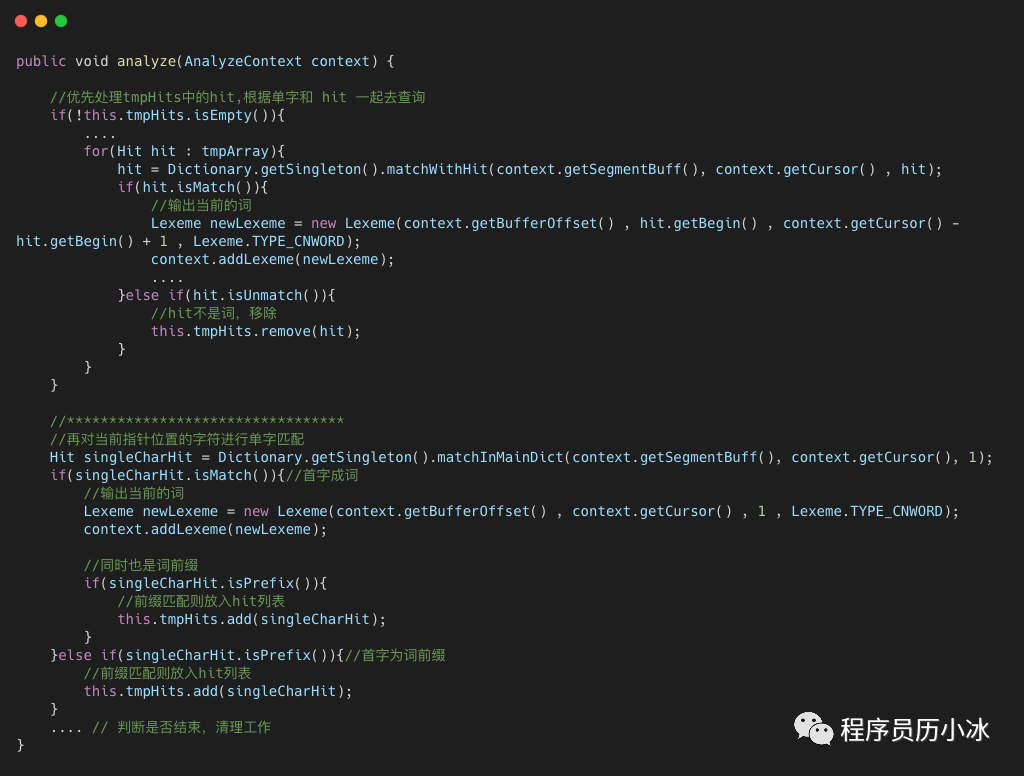
具体的代码逻辑,如上所示。为了方便大家理解,举个例子,比如输入的词是 编码工作:
首先处理
编字;因为当前
tmpHits为空,直接进行单字判断;直接拿
编字去前文示意图的字典树查询(详见matchInMainDict函数),发现能够命中,并且该字不是一个词的结尾,所以将编和其在输入词中的位置生成Hit对象,存储到tmpHits中。
接着处理
码字;因为
tmpHits不为空,所以拿着编对应的Hit对象和码字去字典树中查询(详见matchWithHit函数), 发现命中了编码一词,所以将这个词作为输出词元之一,存入AnalyzeContext;但是因为码已经是叶节点,并没有子节点,表示不是其他词的前缀,所以将对应的Hit对象删除掉;接着拿单字
码去字典树中查询,看单字是否成词,或者构成词的前缀。
依次类推,将所有字处理完。
三、消除歧义和结果输出
通过上述步骤,有时候会生成很多分词结果集合,比如说,程序员爱编程 会被分成 程序员、程序、员、爱 和 编程 五个结果。这也是 ik 的 ik_max_word 模式的输出结果。但是有些场景,开发者希望只有 程序员、爱 和 编程 三个分词结果,这时就需要使用 ik 的 ik_smart 模式,也就是进行消除歧义处理。
ik 使用 IKArbitrator 进行消除歧义处理,主要使用组合遍历的方式进行处理。从上一阶段的分词结果中取出不相交的分词集合,所谓相交,就是其在文本中出现的位置是否重合。比如 程序员、程序 和 员 三个分词结果是相交的,但是 爱 和 编程 是不相交的。所以分歧处理时会将 程序员、程序 和 员 作为一个集合,爱 作为一个集合,编码 作为一个集合,分别进行处理,将集合中按照规则优先级最高的分词结果集选出来,具体规则如下所示:
有效文本长度长优先;
词元个数少优先;
路径跨度大优先;
位置越靠后的优先,因为根据统计学结论,逆向切分概率高于正向切分;
词长越平均优先;
词元位置权重大优先。
根据上述规则,在第一个集合中,程序员 明显要比 程序 和 员 要更符合规则,所以消除歧义的结果就是输出 程序员,而不是 程序 和 员。
最后,对于输入字来说,有些位置可能并不在输出结果中,所以会以单字的方式作为词元直接输出(详见AnalyzeContext 的 outputToResult 函数)。比如 程序员是职业,是 字是不会被分词出来的,但是在最终输出结果时,要将其作为单字输出。
后记
ElasticSearch 和 ik 组合是目前较为主流的中文搜索技术方案,理解其搜索和分词的基础流程和原理,有利于开发者更快地构建中文搜索功能,或基于自身需求,特殊定制搜索分词策略。
-关注我
推荐阅读
AbstractQueuedSynchronizer超详细原理解析