
开源版Imagen来了!效果完全碾压Stable Diffusion!
 点蓝色字关注
“机器学习算法工程师
”
点蓝色字关注
“机器学习算法工程师
”
设为 星标 ,干货直达!
真正的开源版Imagen终于来了:DeepFloyd Lab联合StabilityAI(提供算力)开源了新的文生图大模型DeepFloyd IF,它是对Google之前文生图模型Imagen的复现,从效果上也接近甚至超过原版的Imagen。

Imagen的核心采用了一个预训练好的语言模型(T5-XXL Encoder,参数量4.6B)来编码文本,同时训练了3个不同的扩散模型来实现图像的生成,第一个扩散模型(参数量2B)实现64x64图片的生成,而后面两个扩散模型(参数量为600M和400M)分别实现64x64->256x256和256x256->1024x1024的图像超分。
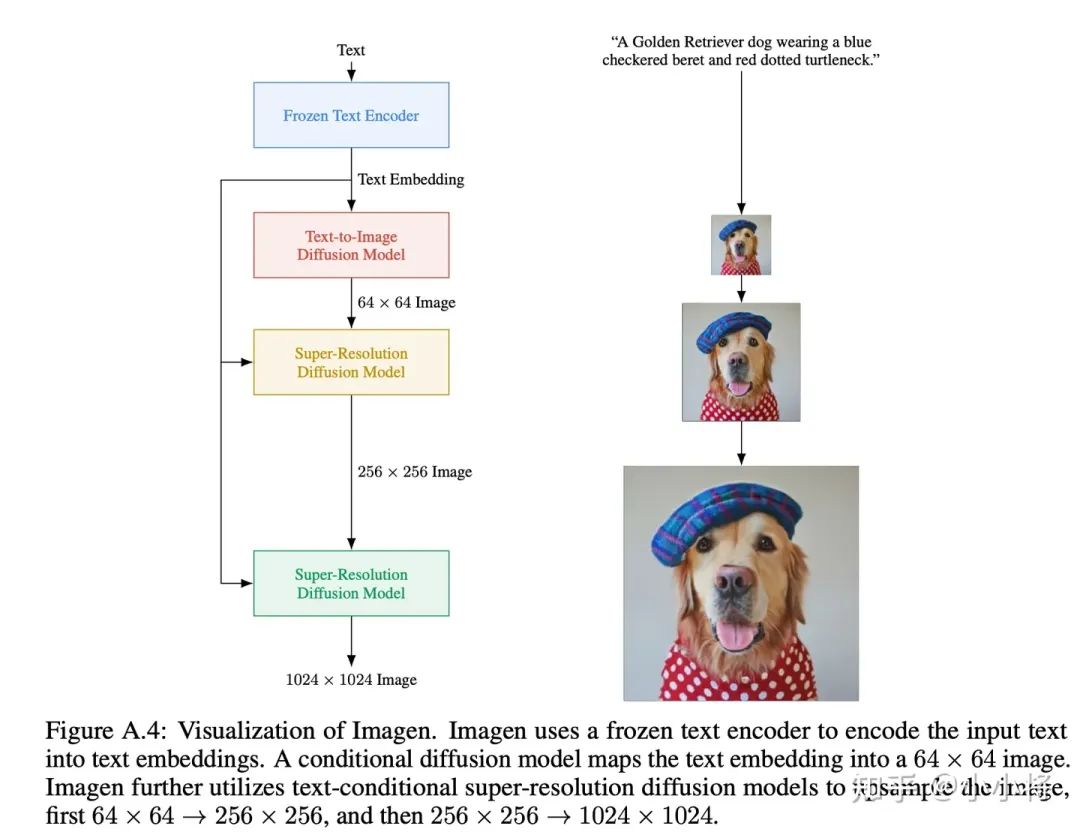
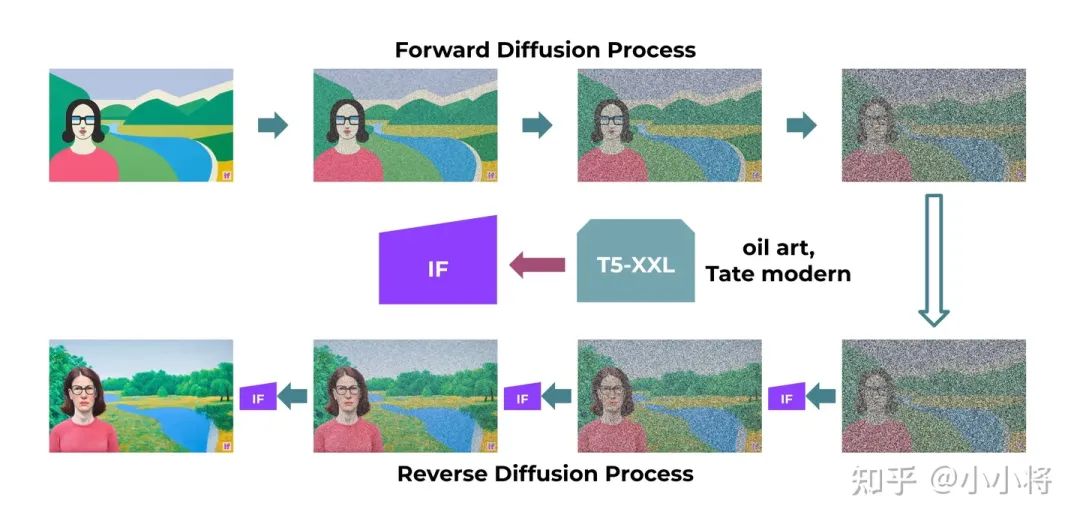
而DeepFloyd IF也基本遵循了Imagen的设计,其模型结构如下所示:
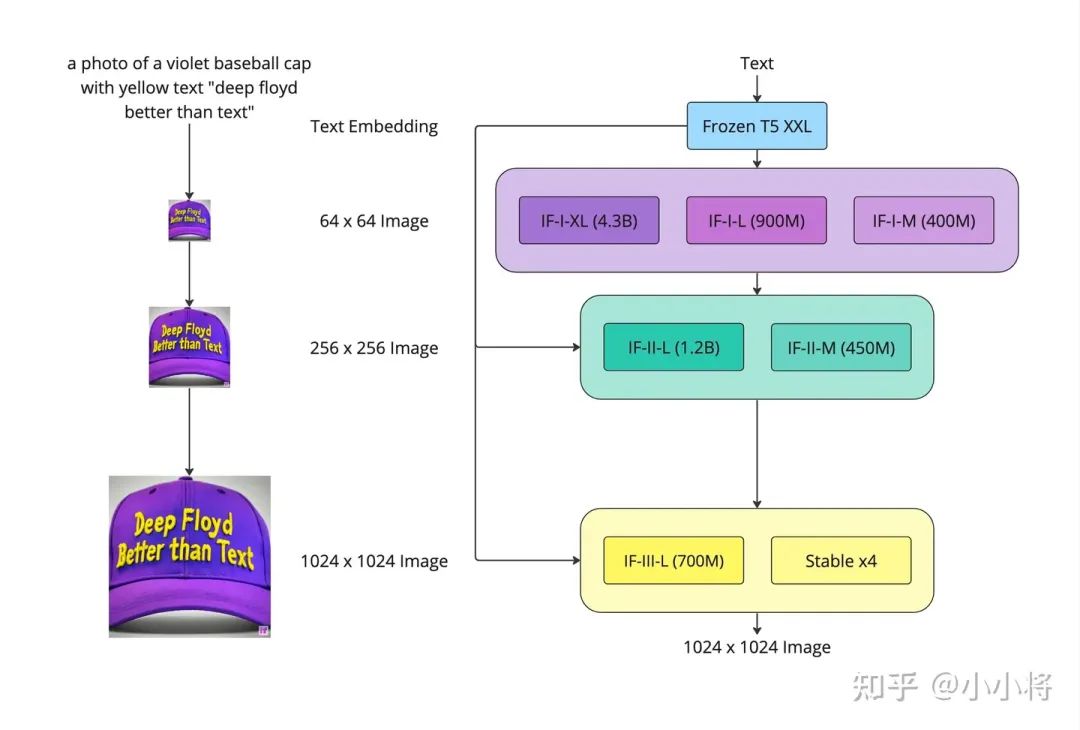
这里也是采用Frozen T5 XXL来提取text embeddings,不过每个阶段的扩散模型都设计了不同的参数量的模型,比如第一阶段64x64模型最大的模型IF-I-XL参数量为4.3B,比Imagen模型的参数量大2倍多。DeepFloyd IF的UNet模型结构基本上和Imagen一样,都是通过cross-attention的方式将text embeddings加入UNet,而且超分模型也都引入了text condition。不过,DeepFloyd IF还额外引入了一个attention pooling从text embeddings中提取一个embedding和UNet的time embedding相加,这相当于起到一个全局text embedding的作用。
Imagen的训练数据量是460M(从互联网上收集)+ 400M(LAION 400M),而DeepFloyd IF的训练数据集是从LAION5B中筛选的1B样本,两者的训练样本差不太多。
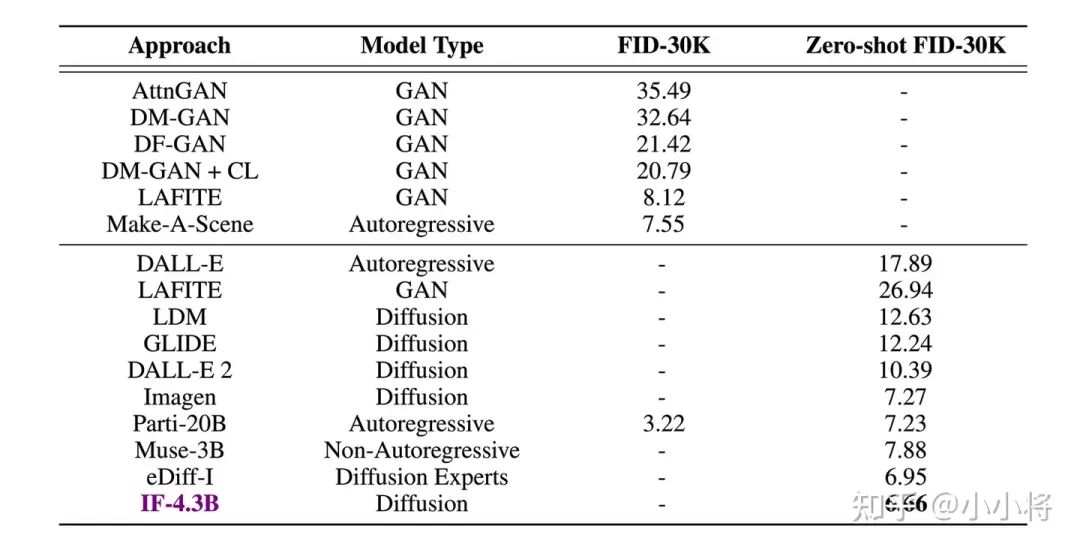
下面是不同大小的DeepFloyd IF模型在COCO数据集上的评测效果,可以看到模型参数越大,FID越低,最大的模型IF-4.3B的FID为6.6。

这个FID结果基本上是超过了目前其它文生图模型:
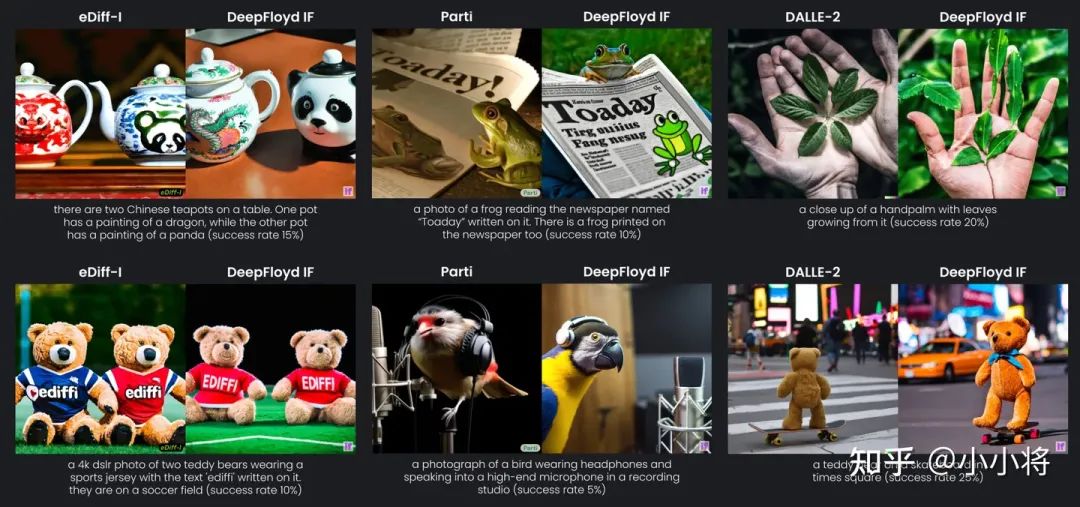
不过FID很多时候并不能很好地反映模型实际的生成效果,我们还是直接看生成图像的直接对比,这里是选取了一些比较难的text prompt和主流的文生图模型(SD 2.1,Muse,Imagen,eDiff-I,Parti,DALLE-2)进行对比,整体看起来DeepFloyd IF模型还是能打的。

下面是DeepFloyd IF模型的一些生成例子(来自Stability AI releases DeepFloyd IF, a powerful text-to-image model that can smartly integrate text into images — Stability AI):


看起来生成的效果还是非常棒的(不过应该是cherry-pick),上述生成图像对应的text prompts分别是:
-
a photo of a full size old rusty sign that says "Deep Floyd Street", photo realism, bokeh, 50mm cine lens, super sharp focus.
-
capybara holding a neon sign with text that reads "capybara podcast", a professional photo of a capybara podcasting, capybara chimera animorph, transformer animal, anamorphic, 8k, 4k, 85 mm, f2.2, photography awards and hyperrealistic, highly detailed, f1.4 lens, 50mm photo, soft light, masterpiece, sharp focus, pretty, hasselblad
-
#practicingfonts trying the word "Floyd" in calligraphy
-
delicious burger painted in the style of starry night
-
film still photograph of redhead bearded Abraham Lincoln look alike starring in a live action documentary about the life of Vincent an Gogh produced by Netflix, 4k
-
renaissance painting of Justin Bieber in the 15th century
-
casual photo of a leaf maple syrup glass container sitting on a wooden table in a log cabin, high depth of field during golden hour as the sunlight shines through the windows, dusty air
-
one piece of fruit that's 'blackberry on the outside', 'orange texture on the inside', cut in half.
-
a strawberry mug filled with white sesame seeds. The mug is floating in a dark chocolate sea.
-
4 bottles of wine next to each other labeled (1,2,3,4)
-
the yellow metal ball on the left is smooth to the touch and cool to the skin, with a faint, metallic scent. The red plastic cylinder in the middle has a rough texture, reminiscent of sandpaper. its bright hue stands out among the other objects. The blue fuzzy triangle on the right is not only soft, but also slightly damp. there are small specks of dirt stuck to it that can be felt when touched
-
three colored wood blocks with the letters (a, b, c)
目前DeepFloyd IF模型已经开源在HugggingFace上:DeepFloyd (DeepFloyd),不过模型实在是太大了,最大的模型IF-4.3B光64x64的模型参数量都接近10B,下载FP16的权重就需要20GB的空间,普通的GPU卡估计也难跑得动。不过HuggingFace上放出了体验空间:IF - a Hugging Face Space by DeepFloyd。这里我选择了一些prompt简单测试了一下(从生成的4个中选择一个最好的),同时也用同样的prompt用SD 2.1(Stable Diffusion 2-1 - a Hugging Face Space by stabilityai)进行生成,第一张图像是IF生成的(1024x1024),而第二张图像是SD 2.1生成的(768x768):
three colored wood blocks with the letters (a, b, c)


1girl, white hair, golden eyes, beautiful eyes, detail, flower meadow, cumulonimbus clouds, lighting, detailed sky, garden


Aerial photo of a beach, the words "what if?" written in the sand.


A photo of girl standing in front of stargate for another dimension made of stone that form a circle.


A face of a woman made completely out of the foliage, twigs, leaves and flowers, side view.


A photo of a corgi dog wearing a wizard hat playing guitar on the top of a mountain.


New York Skyline with Hello World written with fireworks on the sky.


A cloud in the shape of two bunnies playing with a ball. The ball is made of clouds too.


A raccoon wearing formal clothes, wearing a tophat and holding a cane. The raccoon is holding a garbage bag. Oil painting in the style of abstract cubism


A high-contrast photo of a panda riding a horse. The panda is wearing a wizard hat and is reading a book. The horse is standing on a street against a gray concrete wall. Colorful flowers and the word "PEACE" are painted on the wall. Green grass grows from cracks in the street. DSLR photograph. daytime lighting.


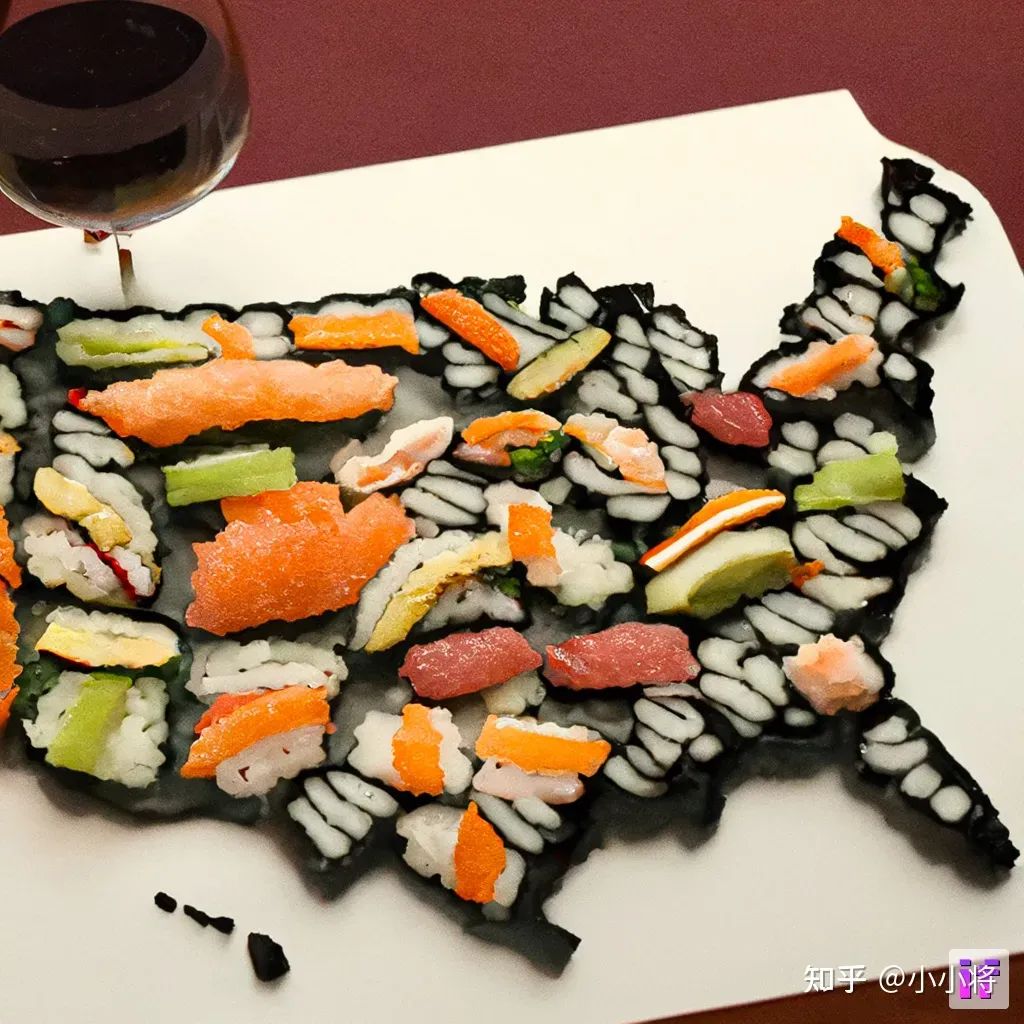
A map of the United States made out of sushi. It is on a table next to a glass of red wine.

A movie scene where A beautiful blonde girl have blue eyes in A ultra detailed Metallic Steampunk Gothic Fantasy Skeleton Latex Filigree mechanical rib cage mounted on the middle of her chest,Her chest cavity is empty except for a glowing mechanical heart,She doesn't wear any visible clothing other than small area in the middle of her chest, some sci - fi cables connecting her heart from above


a beautiful anime girl with red eyes and blue hair on the beach


整体测试下来,DeepFloyd IF模型理解text的能力确实很强,完全碾压SD,但是生成的图像质量和SD一样还是会差一些(完全和Mdj和C站上模型没法比)。特别是在文字生成方面,DeepFloyd IF模型很强,这大概是得益于采用了T5-XXL。

除了文生图,DeepFloyd IF模型还可以像SD一样实现图生图和图像inpainting,这个原理都是一样的。
目前DeepFloyd IF模型也已经集成到了diffusers库,具体见IF,如果使用model cpu offloading,只需要14 GB 显存就可以运行:
from diffusers import DiffusionPipeline
from diffusers.utils import pt_to_pil
import torch
# stage 1
stage_1 = DiffusionPipeline.from_pretrained("DeepFloyd/IF-I-IF-v1.0", variant="fp16", torch_dtype=torch.float16)
stage_1.enable_model_cpu_offload()
# stage 2
stage_2 = DiffusionPipeline.from_pretrained(
"DeepFloyd/IF-II-L-v1.0", text_encoder=None, variant="fp16", torch_dtype=torch.float16
)
stage_2.enable_model_cpu_offload()
# stage 3
safety_modules = {
"feature_extractor": stage_1.feature_extractor,
"safety_checker": stage_1.safety_checker,
"watermarker": stage_1.watermarker,
}
stage_3 = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-x4-upscaler", **safety_modules, torch_dtype=torch.float16
)
stage_3.enable_model_cpu_offload()
prompt = 'a photo of a kangaroo wearing an orange hoodie and blue sunglasses standing in front of the eiffel tower holding a sign that says "very deep learning"'
generator = torch.manual_seed(1)
# text embeds
prompt_embeds, negative_embeds = stage_1.encode_prompt(prompt)
# stage 1
image = stage_1(
prompt_embeds=prompt_embeds, negative_prompt_embeds=negative_embeds, generator=generator, output_type="pt"
).images
pt_to_pil(image)[0].save("./if_stage_I.png")
# stage 2
image = stage_2(
image=image,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_embeds,
generator=generator,
output_type="pt",
).images
pt_to_pil(image)[0].save("./if_stage_II.png")
# stage 3
image = stage_3(prompt=prompt, image=image, noise_level=100, generator=generator).images
image[0].save("./if_stage_III.png")
参考
-
DeepFloyd IF — DeepFloyd
-
GitHub - deep-floyd/IF
-
https://stability.ai/blog/deepfloyd-if-text-to-image-model
-
Text-to-Image Diffusion Models
推荐阅读
使用PyTorch 2.0加速Transformer:训练推理均拿下!
机器学习算法工程师
一个用心的公众号
