
数据分析入门系列教程-EM实战-划分LOL英雄
作者丨周萝卜
来源丨萝卜大杂烩
今天,我们就通过LOL英雄分类的实战,来进一步体会下 EM 聚类的强大之处。
数据获取
页面分析
前面章节,我们实验所用的数据都是直接获取到的,今天我们通过前面学习的爬虫知识,来手动收集我们需要的英雄数据。
我们的目标网站是:http://cha.17173.com/lol/
首先我们可以看到一个英雄列表页面
然后点击每个英雄,又可以跳转至英雄详情页面,就可以看到英雄的初始属性信息了
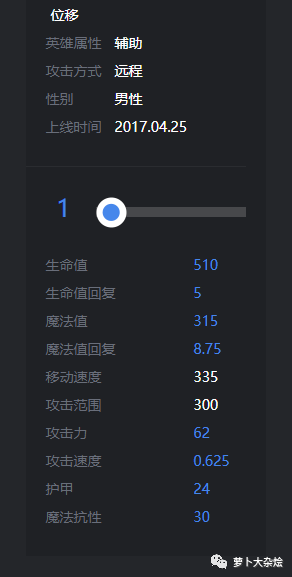
所以我们的爬取流程为:
1.在第一个页面抓取所有英雄所在页面的 url 信息
2.在每个英雄详情页面抓取属性信息
获取英雄所在页面 url
通过分析页面可以知道(如何分析网页,忘记的同学可以查看前面章节),英雄详情页面 url 地址信息保存在一个 class 名为 “games_list” 的 ul 标签中,于是我们可以得到如下的获取信息代码
url = 'http://cha.17173.com/lol/'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'}
url_list = []
res = requests.get(url, headers=headers).text
content = BeautifulSoup(res, "html.parser")
ul = content.find('ul', attrs={'class': "games_list"})
hero_url = ul.find_all('a')
for i in hero_url:
url_list.append(i['href'])
英雄属性抓取
接下来我们就可以通过刚刚获取到的 url 信息,来逐个抓取英雄的属性信息了
base_url = 'http://cha.17173.com'
detail_list = []
for i in url_list[5:]:
print(i)
res = requests.get(base_url + i, headers=headers).content
content = BeautifulSoup(res, "html.parser")
name_box = content.find('h1')
name = name_box.text
# print(name)
hero_attr = content.find('ul', attrs={'class': 'num_li'})
print(hero_attr)
attr_star = hero_attr.find_all('span')
print(attr_star)
live = attr_star[0].text
live_return = attr_star[1].text
magical = attr_star[2].text
magical_return = attr_star[3].text
speed = attr_star[4].text
attach_range = attr_star[5].text
attach_power = attr_star[6].text
attach_speed = attr_star[7].text
armor = attr_star[8].text
magical_armor = attr_star[9].text
detail_list.append([name, live, live_return, magical, magical_return, speed, attach_range, attach_power,
attach_speed, armor, magical_armor])
保存数据到 csv
现在我们已经获得了一个包含属性信息的列表,下一步就是保存进 csv 文件中,以便于后面的分析使用
with open('all_hero_init_attr.csv', 'w', encoding='utf-8') as f:
f.write('英雄名字,生命值,生命值回复,魔法值,魔法值回复,移动速度,攻击范围,攻击力,'
'攻击速度,护甲,魔法抗性\n')
for i in detail_list:
try:
rowcsv = '{},{},{},{},{},{},{},{},{},{},{}'.format(
i[0], i[1], i[2], i[3], i[4], i[5], i[6], i[7], i[8], i[9], i[10]
)
f.write(rowcsv)
f.write('\n')
except:
continue
最后我们得到的数据如下
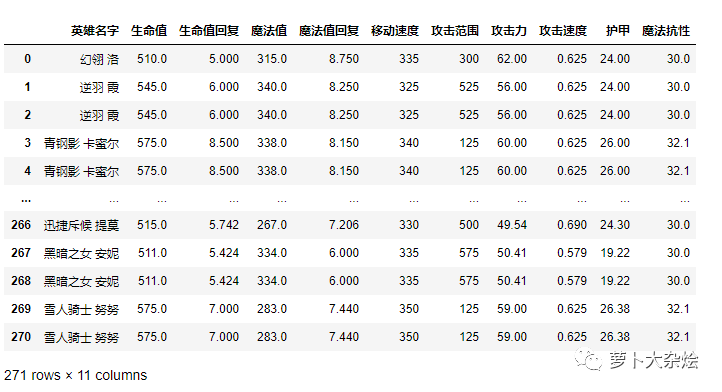
数据处理
接下来进行数据聚类前的数据处理工作
读取数据
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.mixture import GaussianMixture
from sklearn.preprocessing import StandardScaler
from pyecharts.charts import Pie
from collections import Counter
plt.rcParams['font.sans-serif'] = ['SimHei'] # 正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
pd.set_option('display.max_columns', None)
pd.set_option('display.max_rows', None)
data = pd.read_csv('all_hero_init_attr.csv', encoding='gb18030')
查看关联特征
feature = ['英雄名字','生命值','生命值回复','魔法值','魔法值回复','移动速度','攻击范围','攻击力',
'攻击速度','护甲','魔法抗性']
data_init = data[feature]
corr = data_init[feature].corr()
plt.figure(figsize=(14, 14))
sns.heatmap(corr, annot=True)
plt.show()
可以得到如下的热力图,用来分析不同特征之间的关联关系
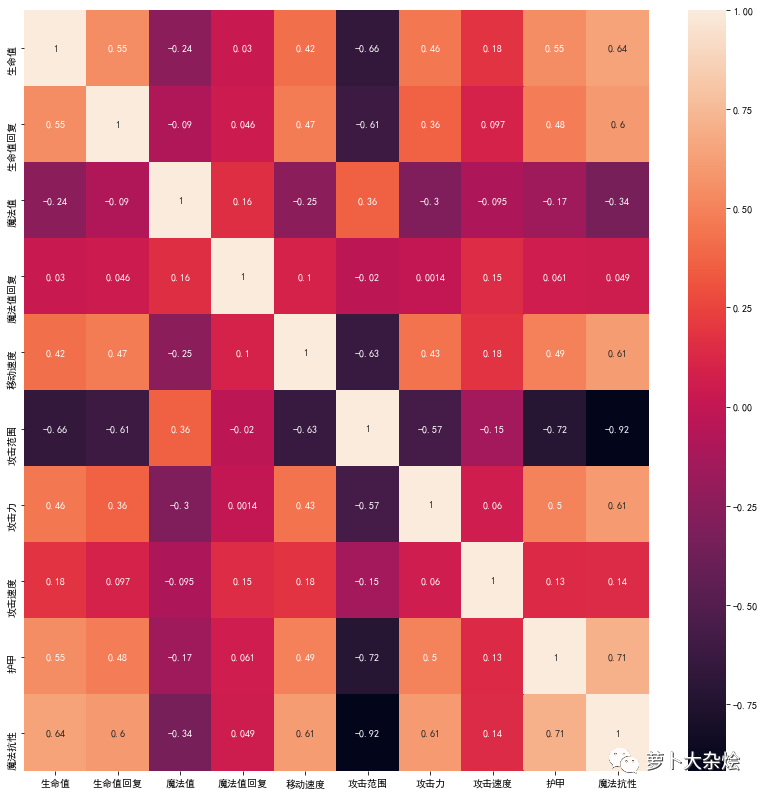
对于关联关系比较强的特征,我们只保留一个,所以可以得到如下的简化特征集
features_remain = ['生命值','生命值回复','魔法值','魔法值回复','移动速度','攻击范围','攻击力',
'攻击速度','护甲','魔法抗性']
data_init = data_init[features_remain]
Sklearn 中的 EM
使用 sklearn 库中的的 EM 聚类算法框架,采用高斯混合模型
from sklearn.mixture import GaussianMixture
一些主要参数意义如下
n_components:混合高斯模型个数,也就是想要的聚类个数,默认为1
covariance_type:协方差类型,包括{‘full’,‘tied’, ‘diag’, ‘spherical’}四种,分别对应完全协方差矩阵(元素都不为零),相同的完全协方差矩阵(HMM会用到),对角协方差矩阵(非对角为零,对角不为零),球面协方差矩阵(非对角为零,对角完全相同,球面特性),默认‘full’ 完全协方差矩阵
max_iter:最大迭代次数,默认100
所以可以构造 GMM 聚类如下:
gmm = GaussianMixture(n_components=20, covariance_type='full')
EM 聚类英雄
下面我们就可以开始给英雄聚类了,首先先对数据进行标准化
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
data_init = ss.fit_transform(data_init)
接下来构建 GMM 聚类模型
gmm = GaussianMixture(n_components=20, covariance_type='full')
gmm.fit(data_init)
获得结果
prediction = gmm.predict(data_init)
再把得到的结果插回入原数据集中
data.insert(0, '分组', prediction)
data.to_csv('all_hero_init_attr_our.csv', index=False, sep=',', encoding='utf-8')
最后再画成饼图
from pyecharts.charts import Pie
from pyecharts import options as opts
df = data[['分组', '英雄名字']] # 获取需要的两列
grouped = df.groupby(['分组']) # 以”分组“列来进行分组
k = []
# 获取分组后的 组和值,保存为字典,放到列表中
for name, group in grouped:
k.append({name: list(group['英雄名字'].values)})
kk = []
for i in k:
for k, v in i.items():
kk.append(v)
length = []
key = []
for i in kk:
key.append(str(i))
length.append(len(i))
pie = Pie()
pie.add("", [list(z) for z in zip(key, length)],
radius=["30%", "75%"],
center=["40%", "50%"],
rosetype="radius")
pie.set_global_opts(
title_opts=opts.TitleOpts(title="英雄聚类分布"),
legend_opts=opts.LegendOpts(
type_="scroll", pos_left="80%", orient="vertical"
),
)
pie.render_notebook()
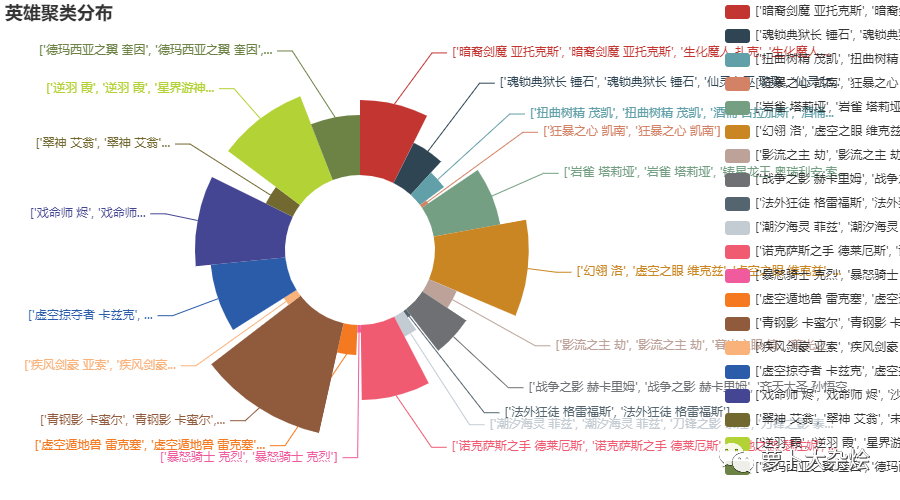
可以看到,分类还是蛮详细的!
总结
今天我们一起完成了聚类LOL英雄的例子,从数据获取、数据清洗到 EM 聚类分析再到最后的可视化处理。从整体流程中可以看出,我们需要经过数据加载,处理,数据探索,特征选择,GMM 聚类和结果展示等环节。
聚类是属于无监督的学习方式,也就是说我们没有实际的结果来进行比对,所以对于聚类的结果分析,通常需要加入更多的人为经验在里面。把我们日常学习工作中的经验应用到聚类的结果中,以此来判断当前的聚类结果是否符合我们的预期。
-End-
最近有一些小伙伴,让我帮忙找一些 面试题 资料,于是我翻遍了收藏的 5T 资料后,汇总整理出来,可以说是程序员面试必备!所有资料都整理到网盘了,欢迎下载!
面试题】即可获取